













В части 1, мы рассмотрели несколько ключевых тем. Я рекомендую вам прочитать её, так как следующая часть строится на ней.
Для быстрого обзора, в части 1, мы рассмотрели наши данные с общей перспективы и различали данные внутри и снаружи. Мы также обсудили схемы и контракты данных и как они предоставляют средства для переговоров, изменений и эволюции наших потоков со временем. Наконец, мы рассмотрели типы событий Факт (Состояние) и Дельта. События типа Факт лучше подходят для передачи состояния и декомпозиции систем, тогда как события типа Дельта чаще используются для данных внутри, таких как в event sourcing и других тесно связанных случаях использования.
Нормализованные таблицы создают нормализованные потоки
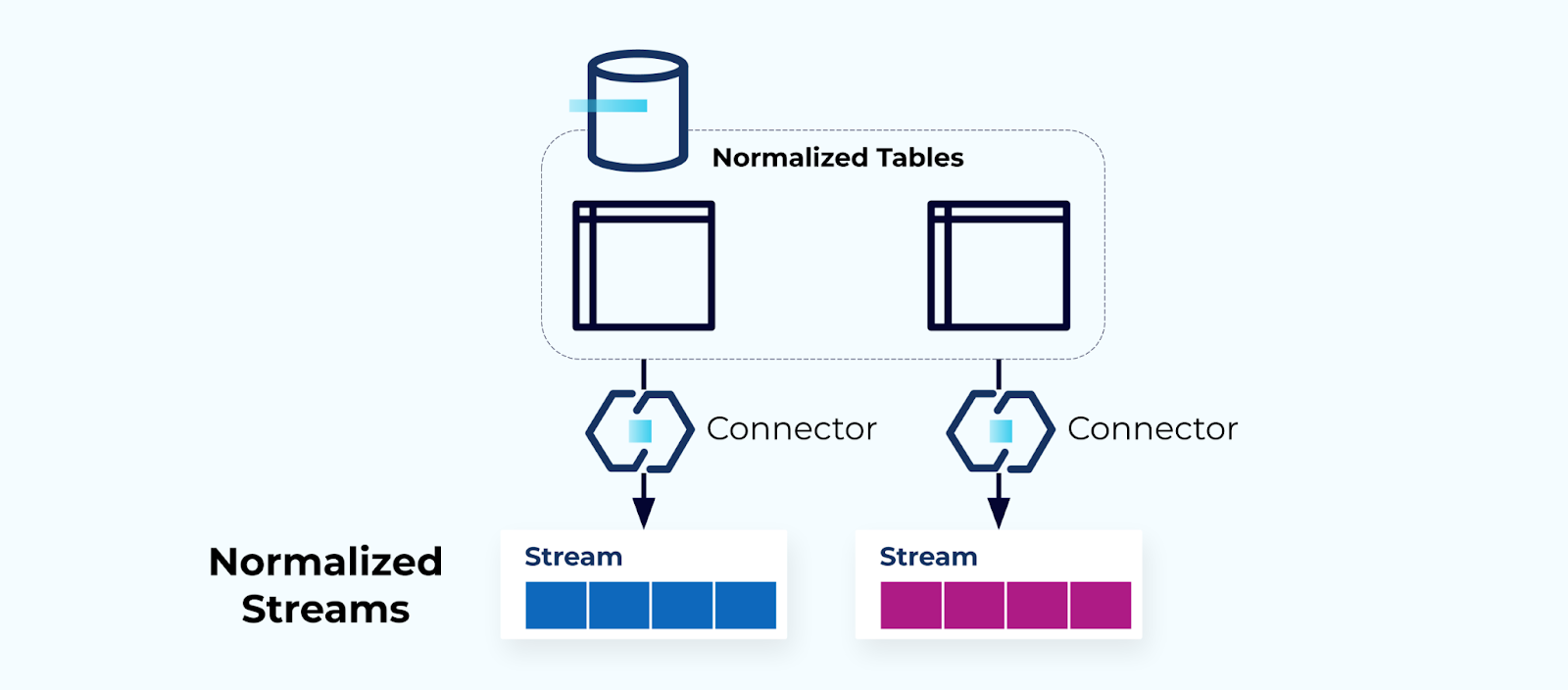
Нормализованные таблицы ведут к нормализованным потокам событий. Коннекторы (например, CDC) извлекают данные directamente из базы данных в зеркальный набор потоков событий. Это не идеально, так как создает сильную связь между внутренними таблицами базы данных и внешними потоками событий.
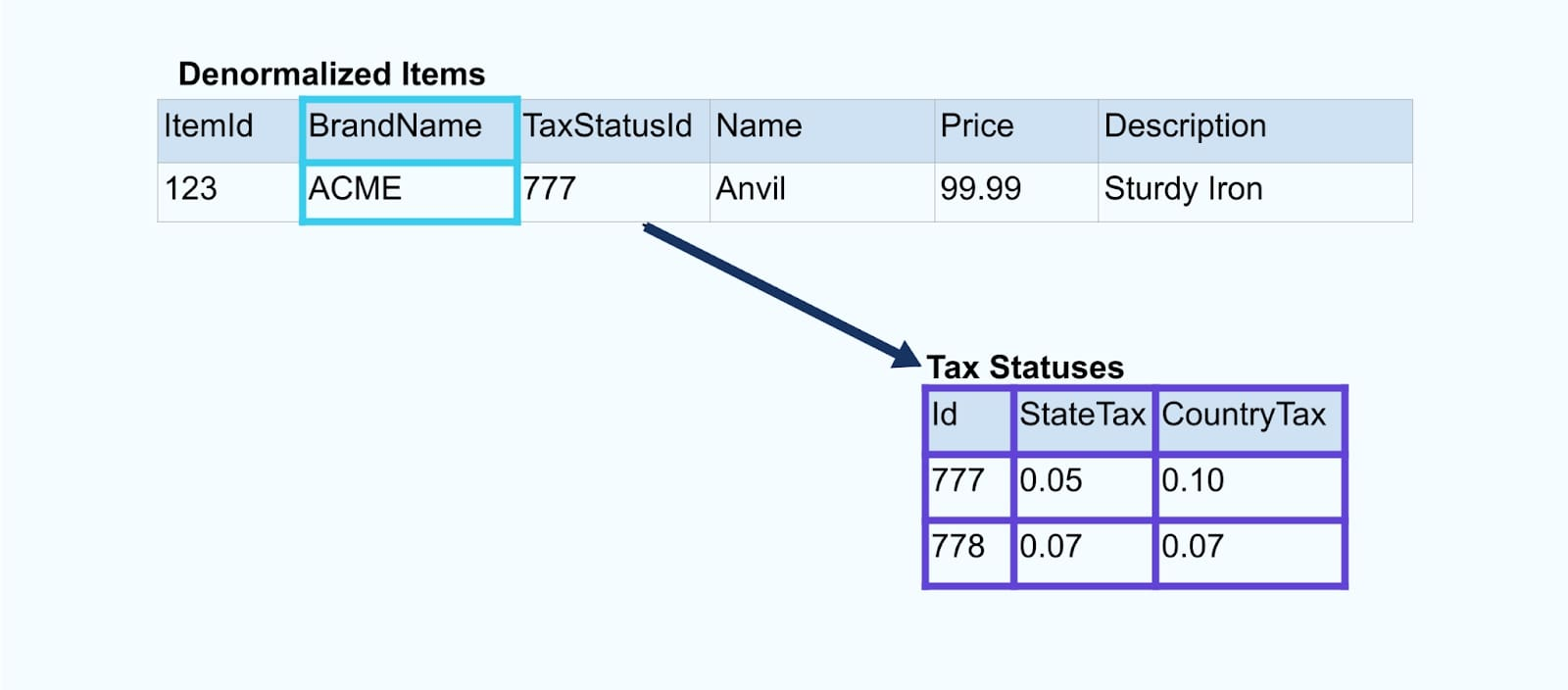
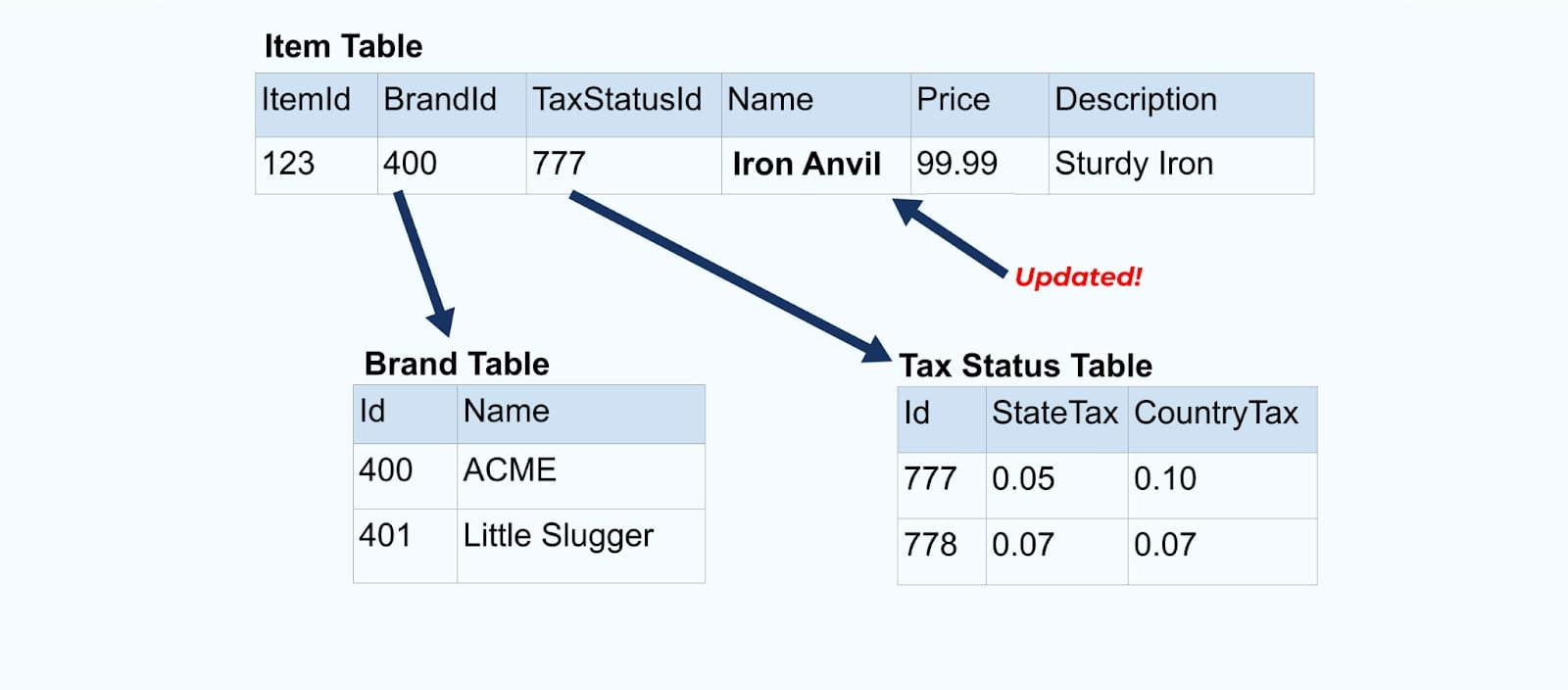
Рассмотрим простой пример электронной коммерции Товар и его связанные Бренд и Налоговый статус таблицы.
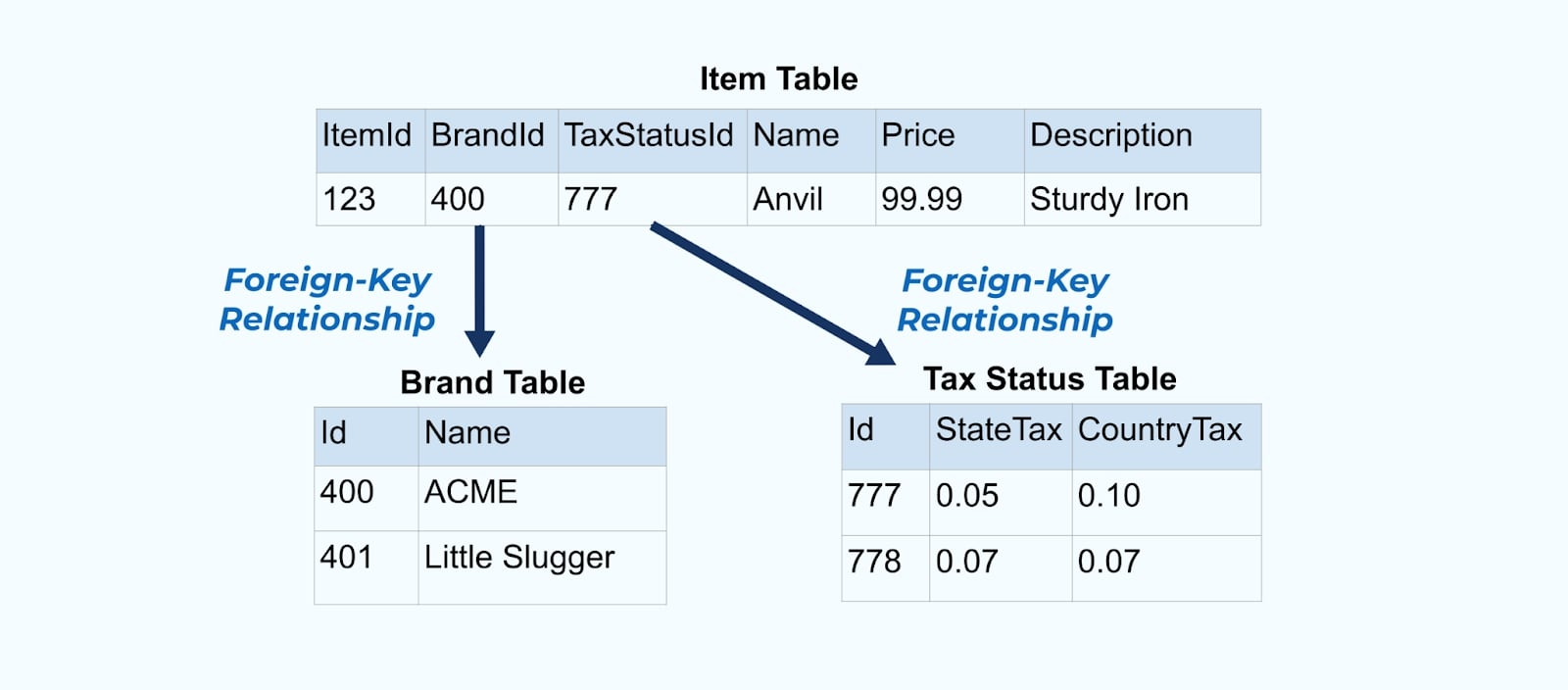
Таблицы Бренд и Налоговый статус связаны с таблицей Товар через отношения внешних ключей. Хотя мы показываем только один товар в таблице, у вас, вероятно, будет тысячи (или миллионы), в зависимости от продаваемых вами продуктов.
Обычно для каждой таблицы настраивается коннектор, извлекается данные из таблицы, компонуется в события и записывается каждая таблица в отдельный поток событий.
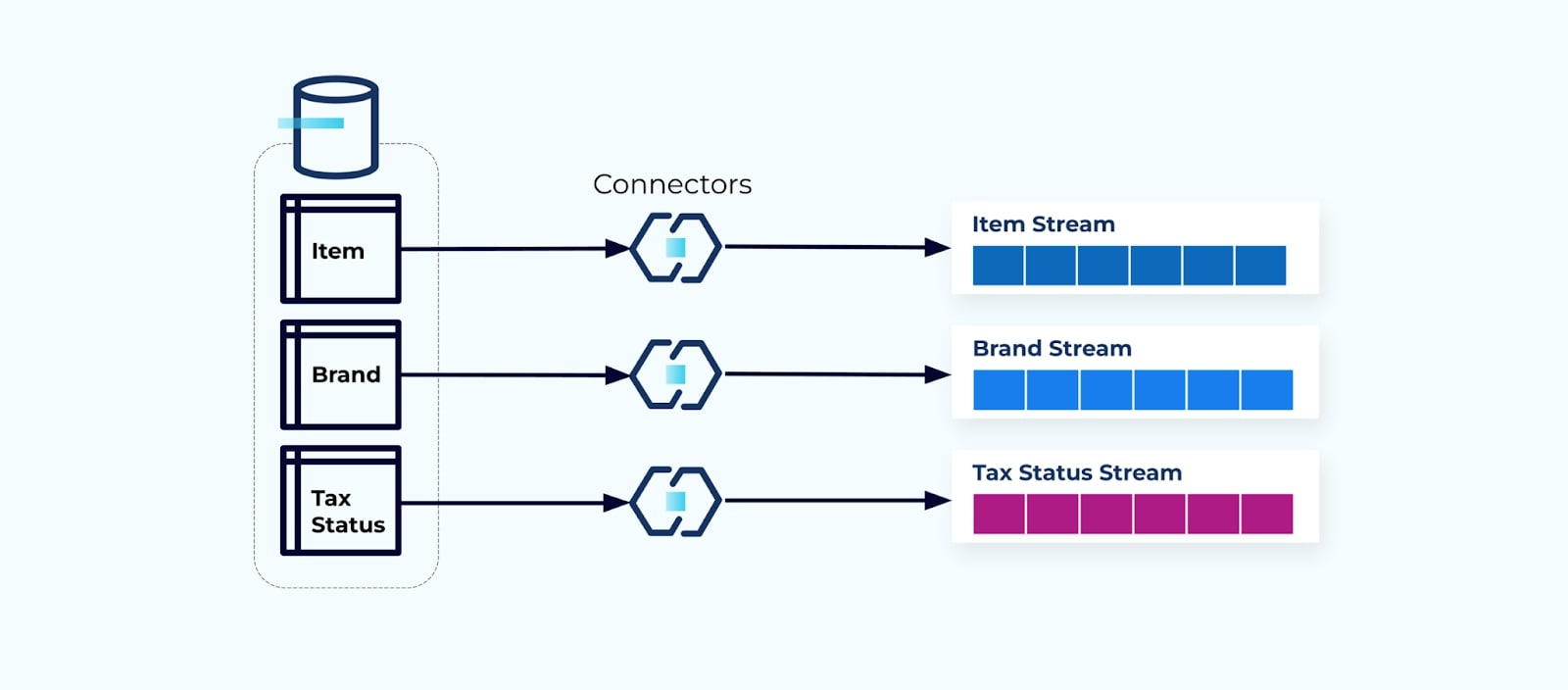
Раскрытие базовых таблиц в базе данных приводит к соответствующему потоку событий для каждой таблицы. Хотя начать таким образом легко, это приводит к множеству проблем, которые можно свести к проблеме связанности или проблеме стоимости . Давайте рассмотрим каждую.
Проблема: Потребители связаны с внутренней моделью
Раскрытие исходной таблицы Элемент как есть вынуждает потребителей напрямую связываться с ней. Изменения в модели данных исходной системы повлияют на下游 потребителей.
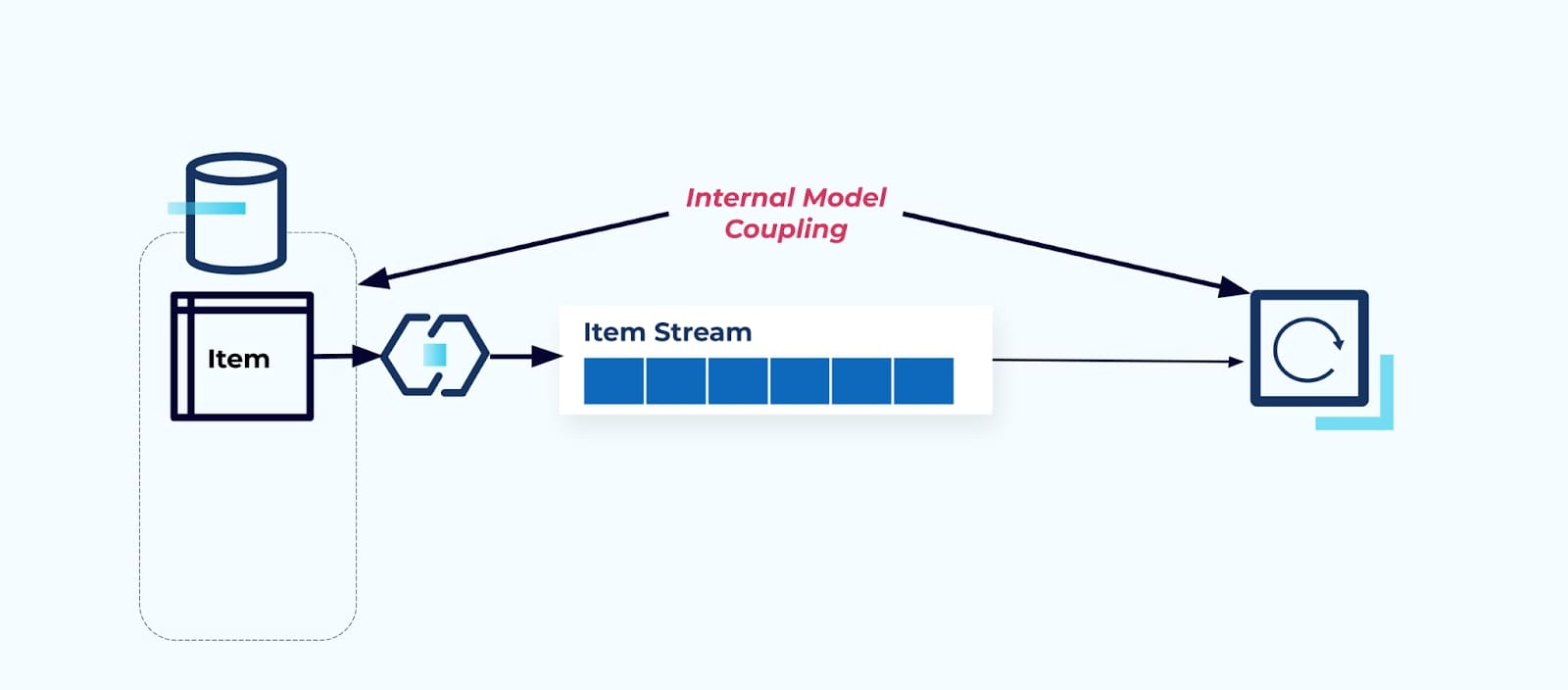
Предположим, мы рефакторим таблицу Элемент, чтобы выделить Цену в отдельную таблицу.
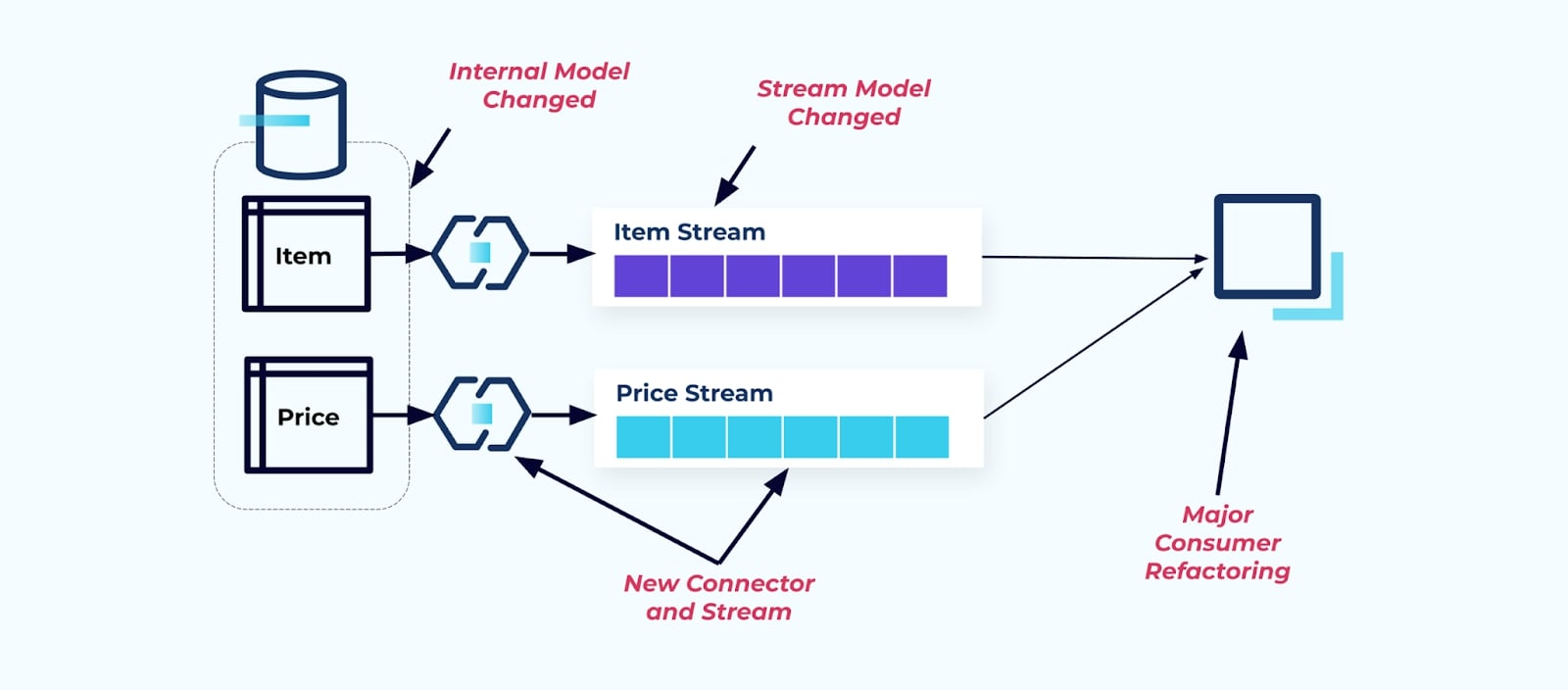
Рефакторинг исходных таблиц приводит к нарушению контракта данных для потока элементов. Потребителю больше не предоставляются те же данные элемента, которые он изначально ожидал. Нам также необходимо создать новый коннектор — новый Price поток — и, наконец, рефакторить нашу логику потребителя , чтобы снова запустить её. Переименование столбцов, изменение значений по умолчанию и изменение типов столбцов являются другими формами разрушительных изменений, введенных из-за тесной связанности внутренней модели данных.
Проблема: Потоковые объединения (обычно) дороги
Реляционные базы данных специально созданы для быстрого и дешевого разрешения объединений. К сожалению, потоковые объединения такими не являются.
Рассмотрим два сервиса, которые хотят получить доступ к Элементу, его Налогу и информации о его Бренде. Если данные уже записаны в соответствующий поток, то каждый потребитель (справа на изображении ниже) будет вынужден вычислять те же объединения для денормализации Item, Brand и Tax.
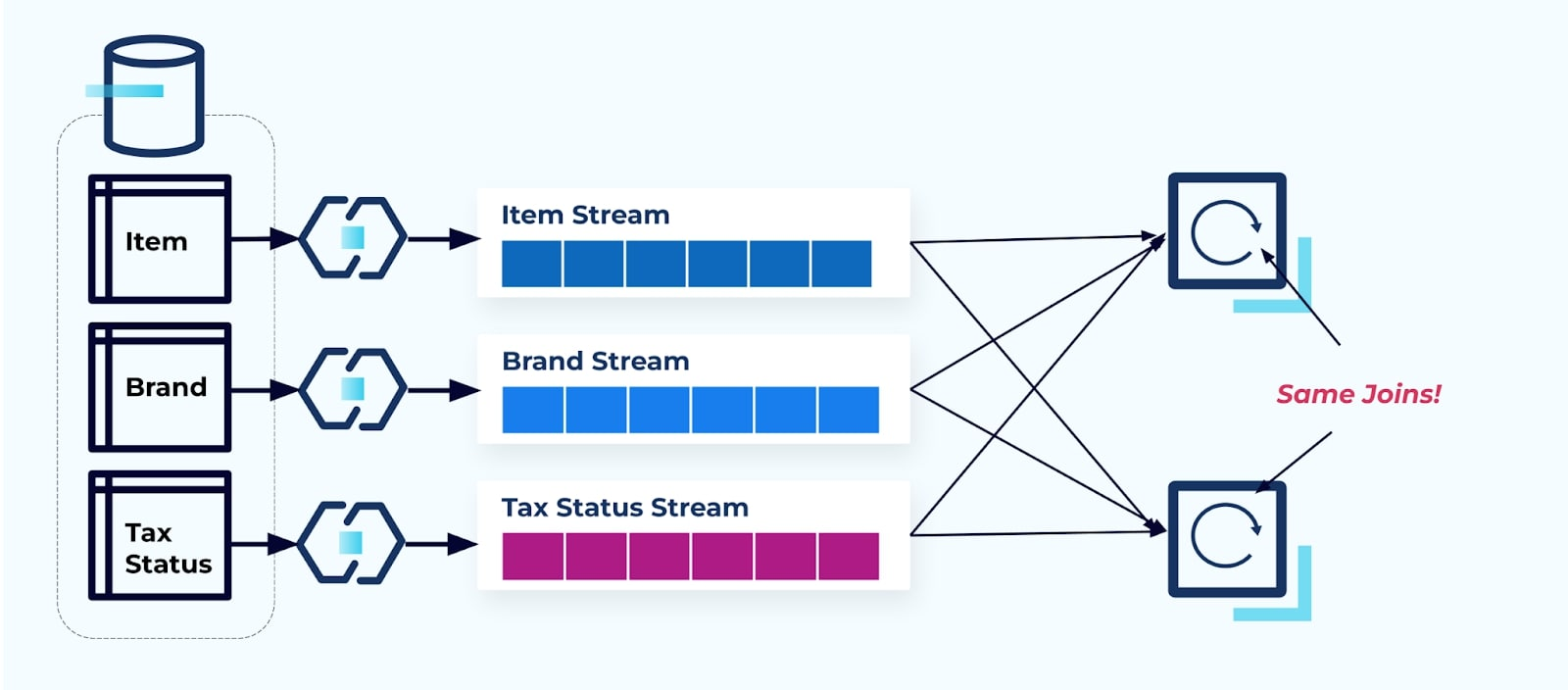
Эта стратегия может повлечь высокие затраты, как в часах разработки на написание приложений, так и в серверных затратах на вычисление объединений. Разрешение потоковых объединений в масштабе может привести к большому перемещению данных, что влечет затраты на вычислительную мощность, сетевые ресурсы и хранение. Кроме того, не все платформы для обработки потоков поддерживают объединения, особенно по внешним ключам. Те, которые поддерживают, такие как Flink, Spark, KSQL или Kafka Streams (например), ограничивают вас подмножеством языков программирования (Java, Scala, Python).
Решение: Лучше всего предоставлять денормализованные данные
Как принцип, делайте потоки событий удобными для использования потребителями. Денормализуйте данные перед тем, как сделать их доступными для потребителей, используя уровень абстракции и создайте явную внешнюю модель договор данных (данные снаружи) для привязки потребителей.
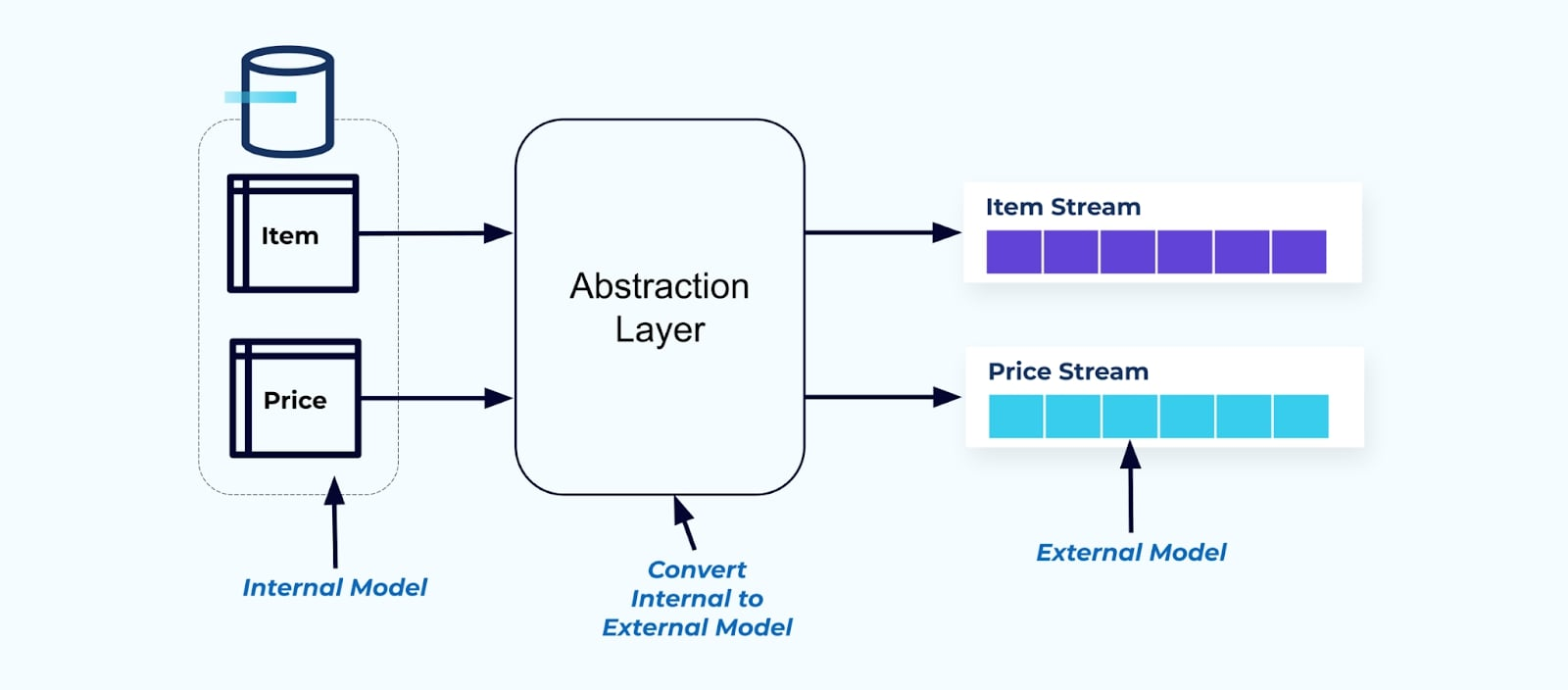
Изменения во внутренней модели остаются изолированными в исходных системах. Потребители получают четко определенный договор данных для привязки. Изменения, внесенные в исходную модель, могут продолжаться беспрепятственно, если исходная система поддерживает договор данных для потребителей.
Но где денормализовать? Два варианта:
- Воссоздавать вне исходной системы с помощью специально созданной службы объединения.
- Во время создания события в исходной системе, используя шаблон Transactional Outbox.
Рассмотрим каждое решение по порядку.
Вариант 1: Денормализация с помощью специально созданной службы объединения
В этом примере потоки слева отражают таблицы, из которых они пришли в базе данных.
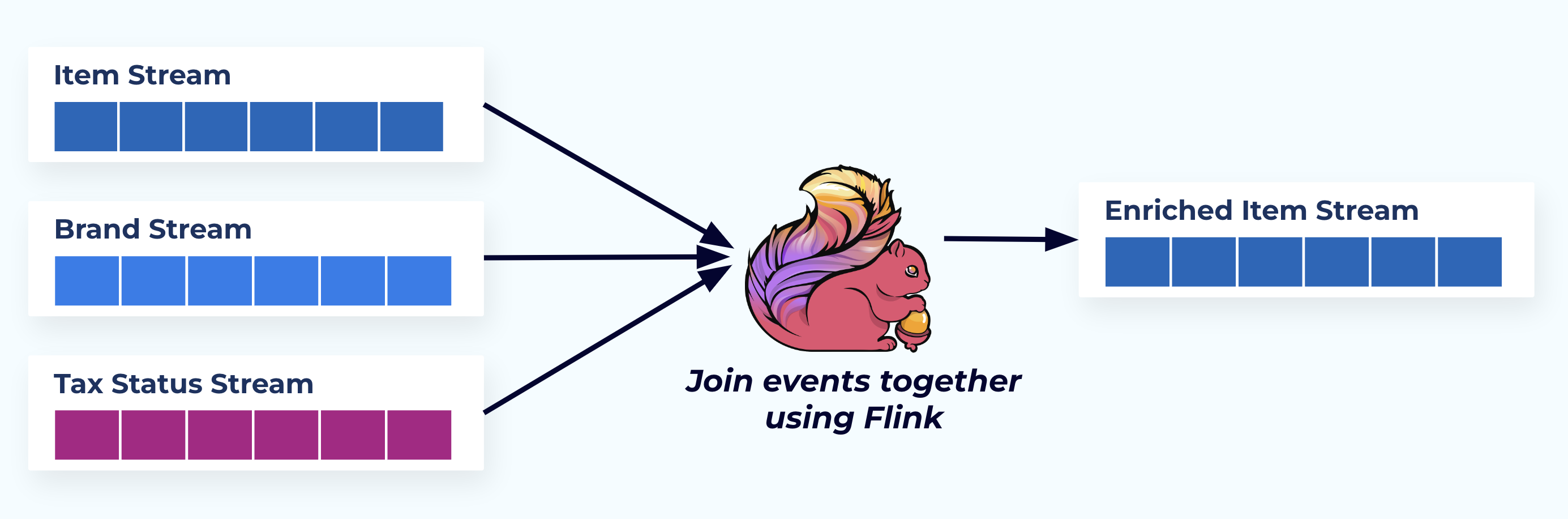
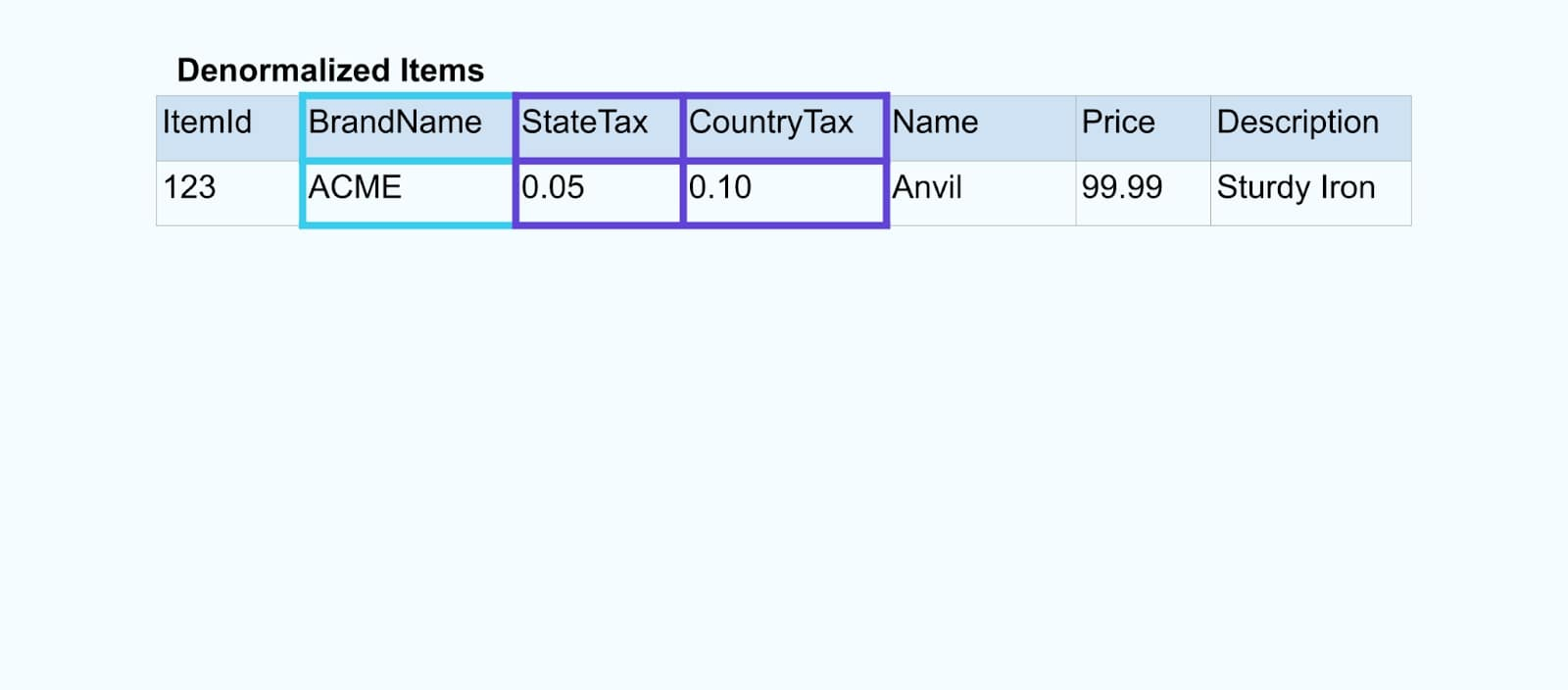
Мы объединяем события с помощью специально разработанного приложения (или потокового SQL-запроса), основанного на отношениях внешних ключей, и emit a single enriched item stream.

Логически, мы разрешаем отношения и сжимаем данные в одну денормализованную строку.
Специально разработанные объединители полагаются на фреймворки потоковой обработки, такие как Apache Kafka Streams и Apache Flink, для разрешения как первичных, так и внешних ключей. Они материализуют потоковые данные в устойчивые внутренние форматы таблиц, что позволяет приложению-объединителю объединять события в любой период – не только те, которые ограничены временным окном.
Объединители, использующие Flink или Kafka Streams, также исключительно масштабируемы — они могут масштабироваться в зависимости от нагрузки и обрабатывать огромные объемы трафика.
Совет: Не включайте никакую бизнес-логику в объединитель. Для успешного применения этого шаблона объединенные данные должны точно представлять источник, просто как денормализованный результат. Пусть потребители вниз по потоку применяют свою собственную бизнес-логику, используя денормализованные данные как единый источник истины.
Если вы не хотите использовать объединитель вниз по потоку, есть другие варианты. Давайте рассмотрим шаблон транзакционного почтового ящика далее.
Вариант 2: Шаблон транзакционного почтового ящика
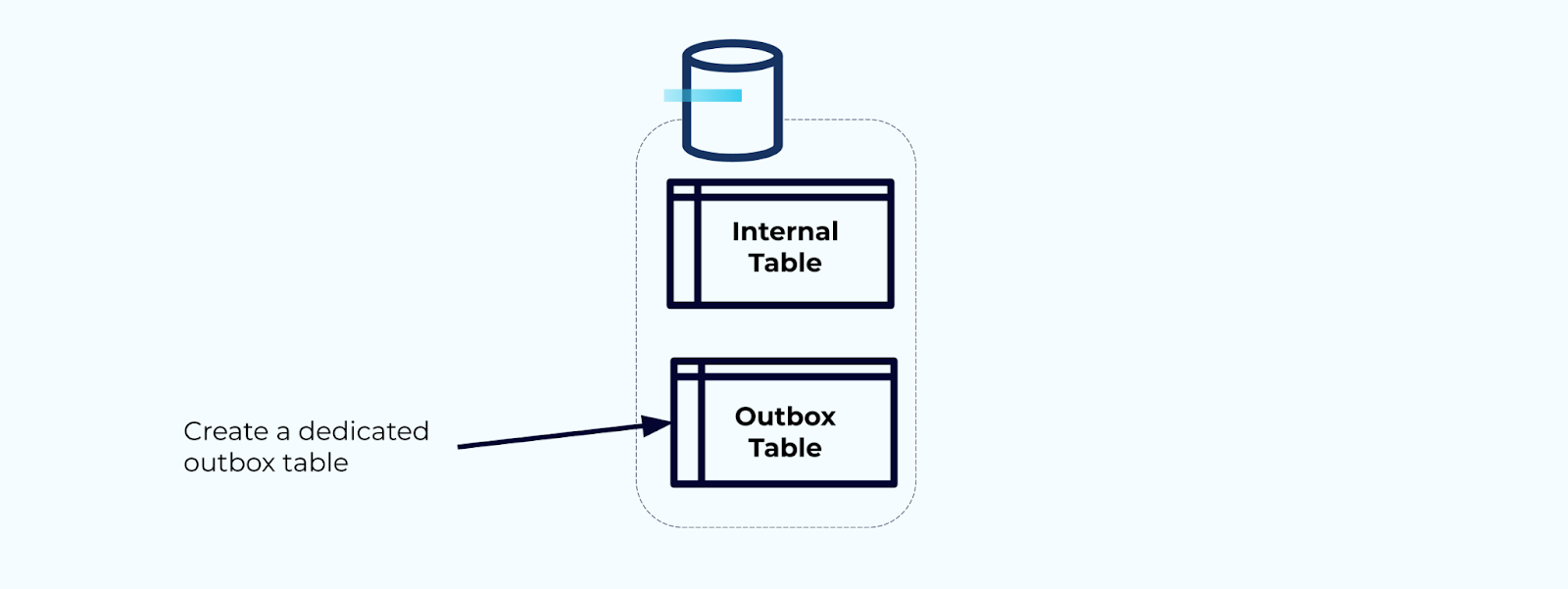
Сначала создайте специализированную таблицу почтового ящика для записи событий в поток.
Во-вторых, оберните все необходимые обновления внутренней таблицы внутри транзакции. Транзакции гарантируют, что любые обновления, сделанные в внутренней таблице, также будут записаны в таблицу исходящей почты.
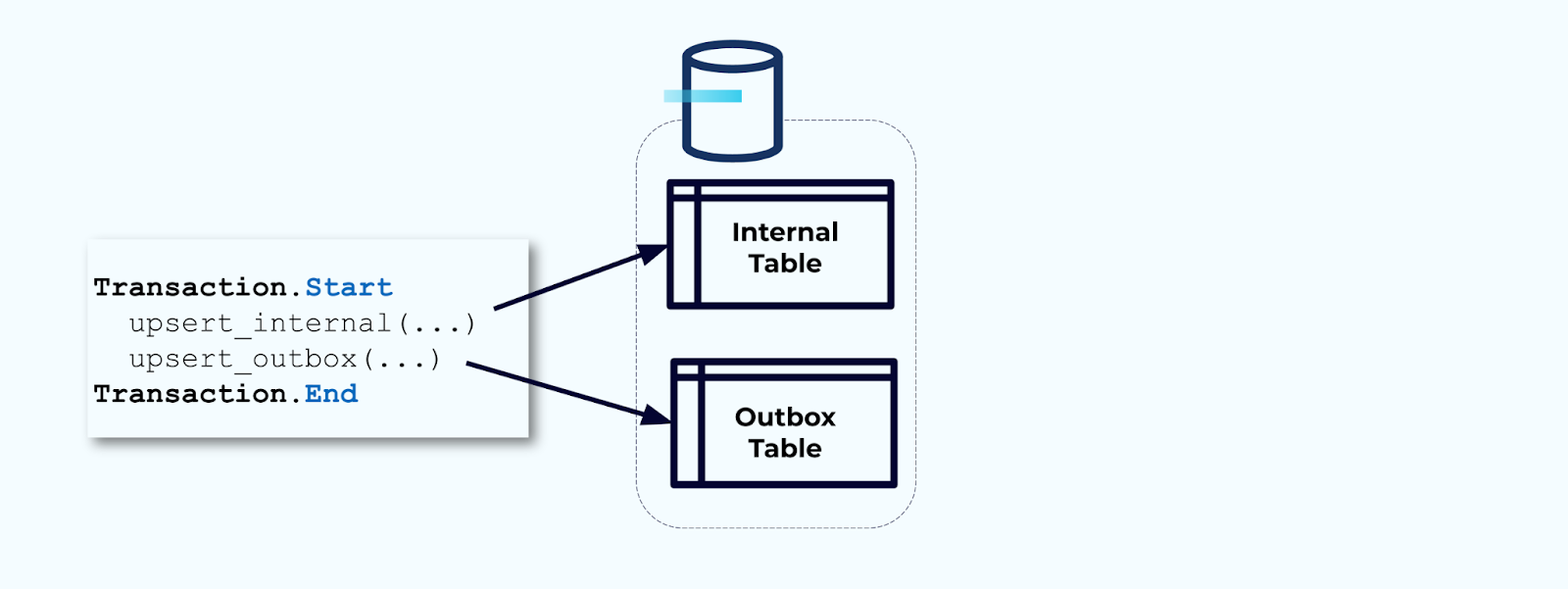
Исходящая почта позволяет изолировать внутреннюю модель данных, так как вы можете объединять и преобразовывать данные перед записью их в исходящую почту. Исходящая почта действует как абстракционный слой между вашими данными внутри и данными снаружи, выполняя роль контракта данных для ваших потребителей.
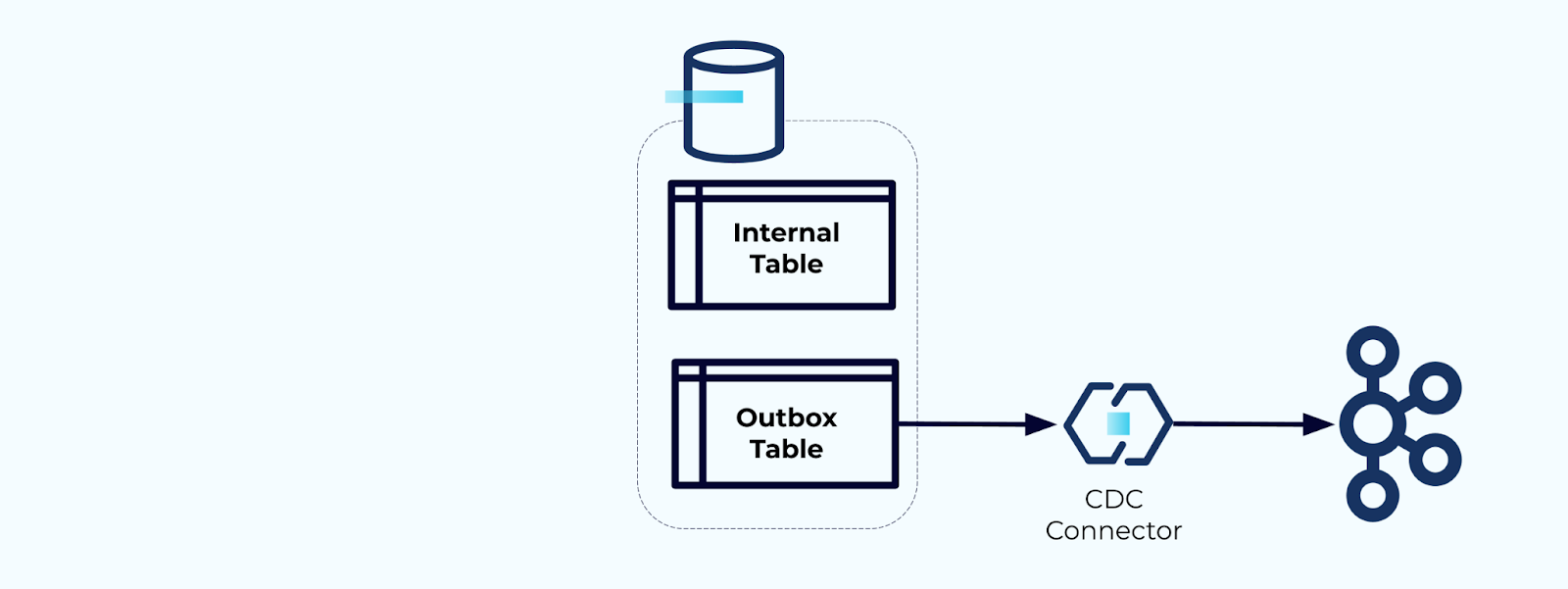
Наконец, вы можете использовать коннектор для получения данных из исходящей почты и передачи их в Kafka.
Вы должны убедиться, что исходящая почта не растет бесконечно — либо удаляйте данные после их захвата CDC, либо периодически с помощью запланированной задачи.
Пример: Денормализация событий отслеживания поведения пользователей
Отслеживание поведения пользователей на ваших веб-страницах и приложениях является распространенным источником нормализованных событий — подумайте о Google Analytics или первых-party внутренних вариантах. Но мы не включаем всю информацию в событие; вместо этого мы ограничиваемся идентификаторами (быстрее, меньше, дешевле), денормализуя после создания фактов.
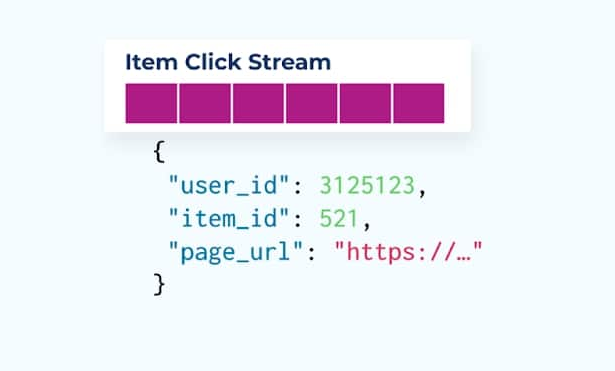
Рассмотрим поток событий кликов по элементам, детализирующих, когда пользователь кликает на элемент при просмотре товаров в электронной коммерции. Обратите внимание, что это событие клика по элементу не содержит более богатой информации о товаре, такой как название, цена и описание, только базовые ids.
Первое, что делают многие потребители потоков кликов, это объединяют его с потоком фактов о товарах. И поскольку вы работаете с множеством событий кликов, вы обнаруживаете, что это приводит к использованию большого объема вычислительных ресурсов. Специально разработанное приложение Flink может объединять клики по товарам с детализированными данными о товарах и передавать их в обогащенный поток кликов по товарам.
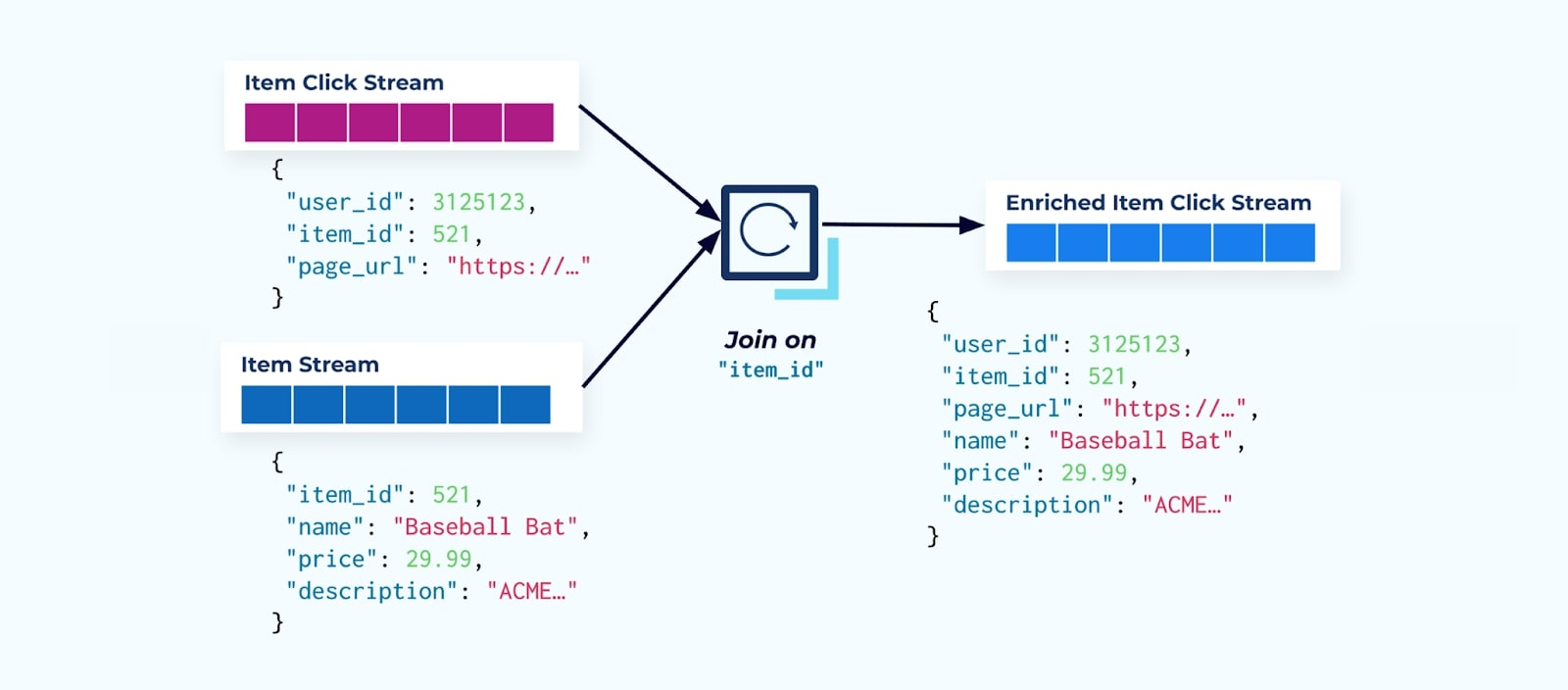
Крупные компании с несколькими подразделениями (и системами) скорее всего будут получать данные из разных источников, и объединение после факта с использованием соединителя потоков является наиболее вероятным исходом.
Размышления о медленно меняющихся измерениях
Мы уже обсуждали вопросы производительности при записи событий, содержащих большие наборы данных (например, большие текстовые блоки) и домены данных, которые часто меняются (например, инвентарь товаров). Теперь мы рассмотрим медленно меняющиеся измерения (SCD), часто обозначаемые через отношение внешнего ключа, так как они могут быть еще одним источником значительных объемов данных.
Вернемся к нашему примеру с товарами. Допустим, у вас есть операция, которая обновляет Таблицу товаров. Мы собираемся переименовать товар из “Наковальня” в “Железная наковальня”.
При обновлении данных в базе данных мы также передаем обновленный товар (скажем, через шаблон outbox), complete with the denormalized tax status and brand table.
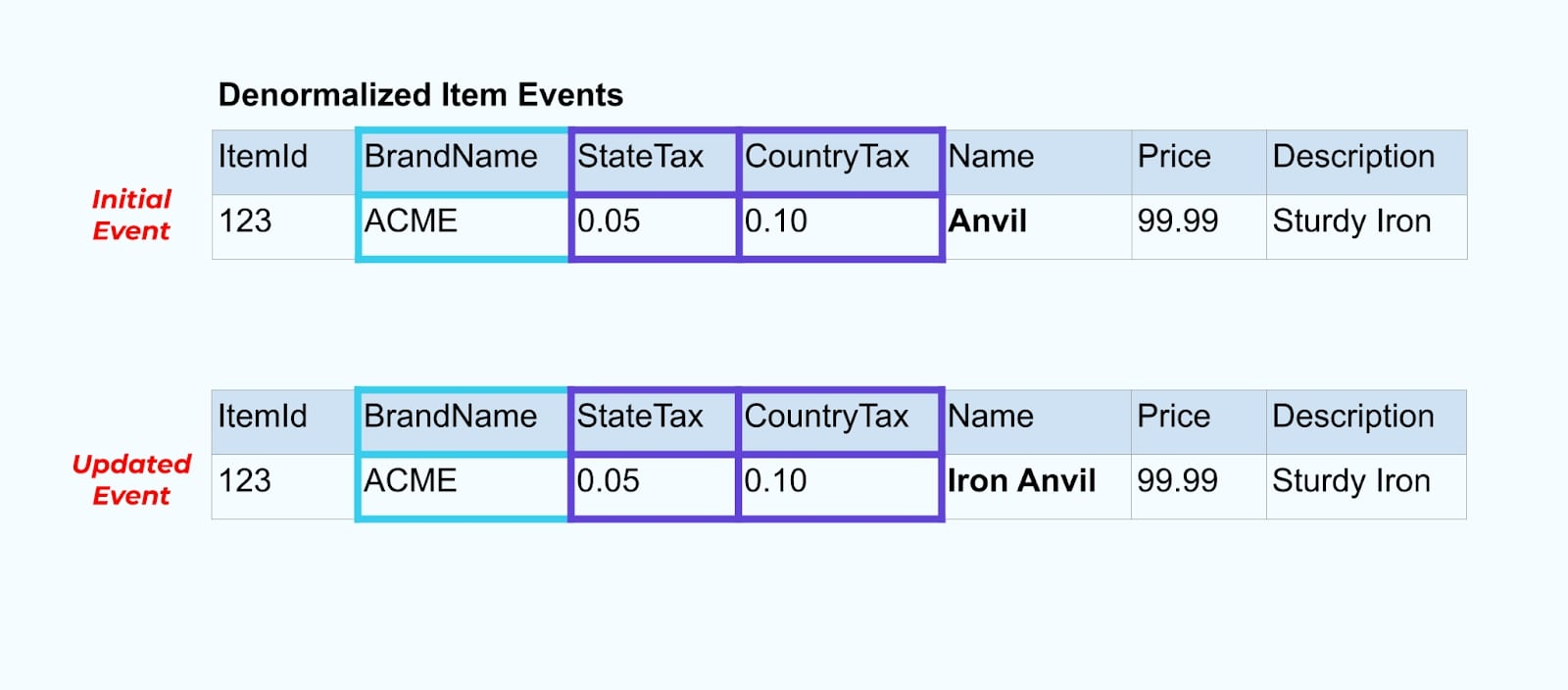
Однако нам также нужно учитывать, что происходит, когда мы изменяем значения в таблицах бренда или налогового статуса. Обновление одного из этих медленно меняющихся измерений может привести к значительно большому числу обновлений для всех затронутых товаров.
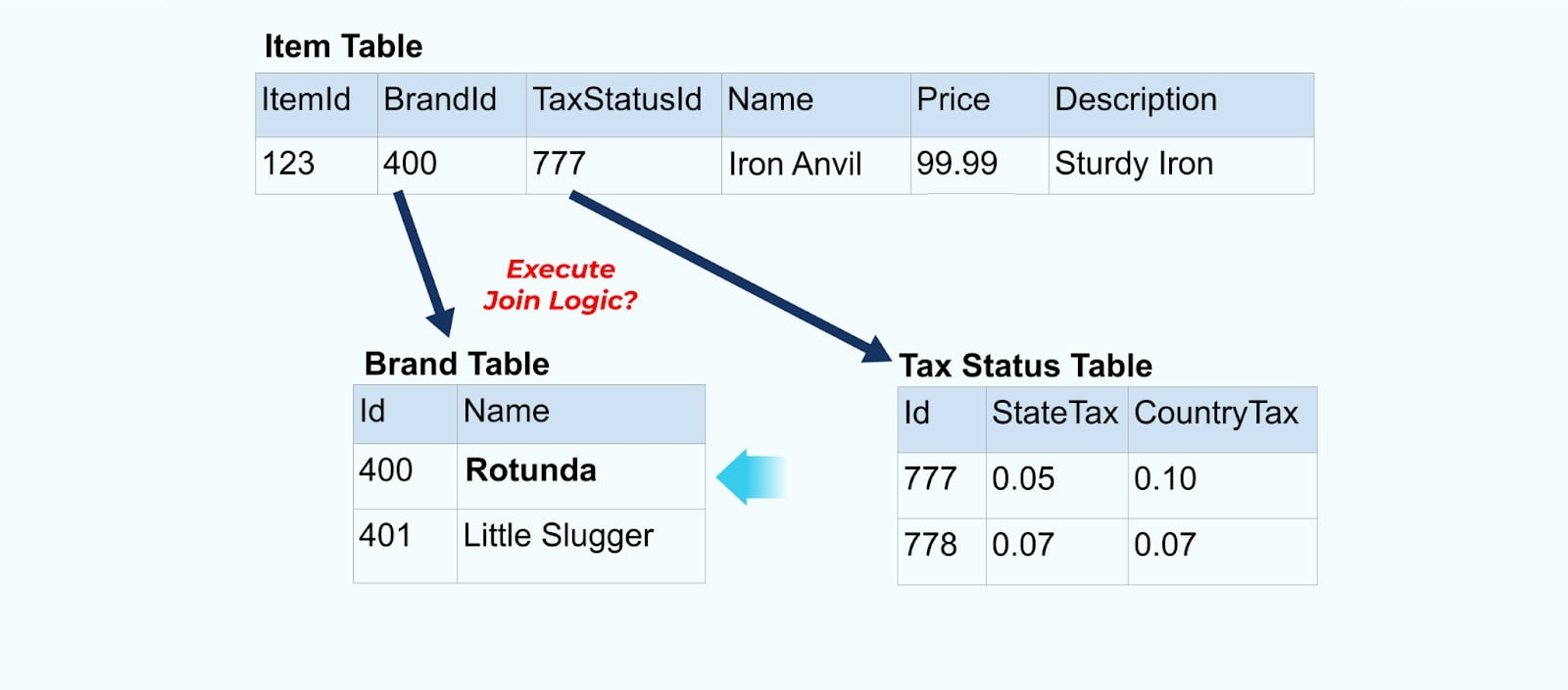
Например, компания ACME проходит ребрендинг и приходит к новому названию бренда, меняя ACME на Rotunda. Мы создаем еще одно событие для ItemId=123.
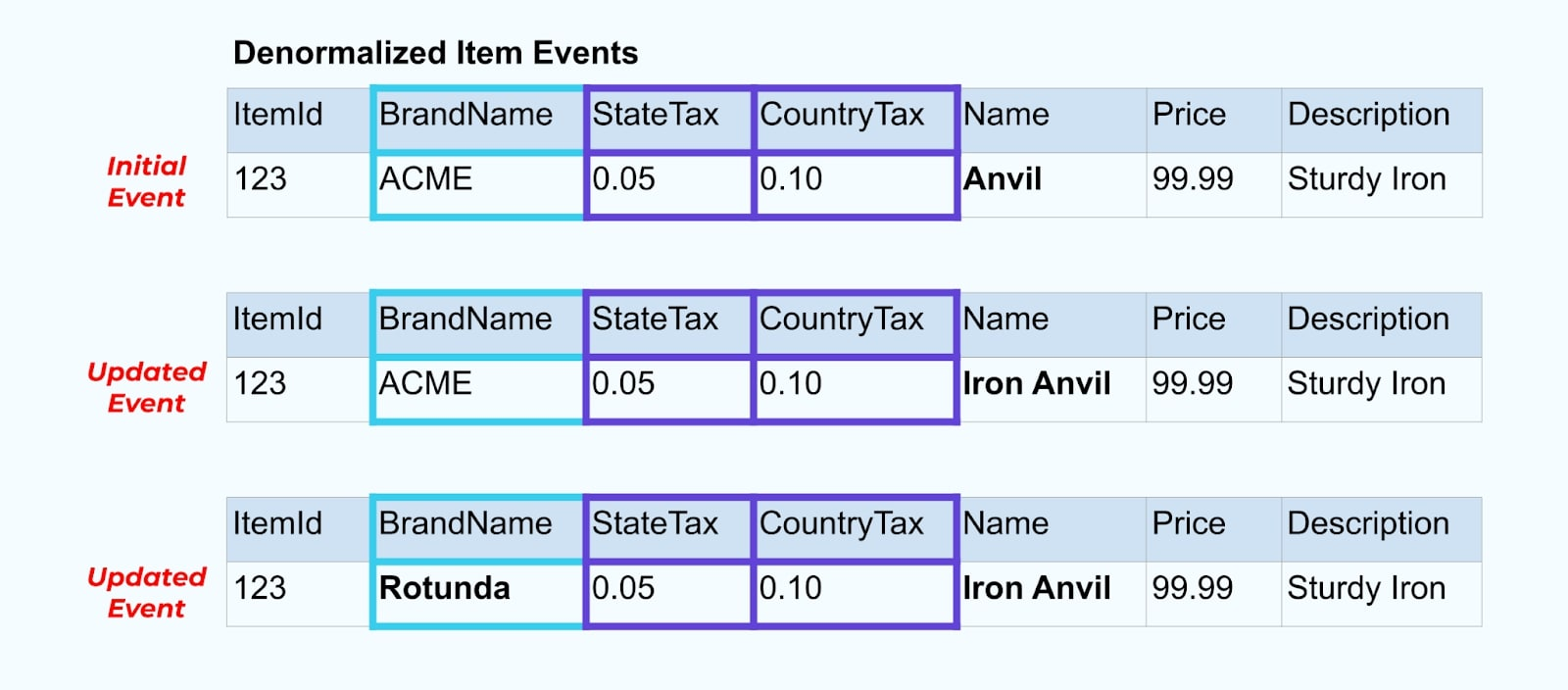
Однако, Rotunda (ранее ACME) вероятно имеет сотни (или тысячи) товаров, которые также обновляются этим изменением, что приводит к соответствующему количеству обновленных событий обогащенных товаров.
При денормализации SCD и связей внешних ключей, учитывайте влияние, которое изменение SCD может оказать на поток событий в целом. Вы можете решить отказаться от денормализации и оставить это на усмотрение потребителя, если изменение SCD приводит к миллионам или миллиардам обновленных событий.
Итог
Денормализация упрощает использование данных потребителями, но требует больше обработки на上游 и тщательного выбора данных для включения. Потребителям может быть легче строить приложения и выбирать из более широкого спектра технологий, включая те, которые не поддерживают потоковые объединения нативно.
Нормализация данных на上游 хорошо работает, когда данные малы и редко обновляются. Большие размеры событий, частые обновления и SCD — все это факторы, на которые стоит обратить внимание при определении, что денормализовать на upstream, а что оставить для потребителей, чтобы они делали это сами.
В конечном итоге, выбор данных для включения в событие и данных для исключения — это баланс между потребностями потребителей, возможностями производителей и уникальными отношениями в модели данных. Но лучшее место для начала — это понимание потребностей ваших потребителей и изоляция внутренней модели данных вашей исходной системы.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2