













Были времена, когда мы создавали задания Jenkins исключительно через пользовательский интерфейс. Позже, чтобы справиться с растущей сложностью задач сборки и развертывания, была выдвинута идея использования конвейера в качестве кода. В Jenkins 2.0 команда Jenkins представила Jenkinsfile для реализации конвейера в виде кода. Если вы хотите создать автоматизированный конвейер Jenkins на основе pull request или по веткам Непрерывная Интеграция и Непрерывное Доставление, то Jenkins многоветвевой конвейер — это то, что вам нужно.
Поскольку Jenkins многоветвевой конвейер полностью основан на git и представляет собой конвейер в виде кода, вы можете построить свои рабочие процессы CI/CD. Конвейер как Код (PaaC) упрощает использование преимуществ автоматизации и переносимости облака для вашего Selenium. Вы можете использовать модель многоветвевого конвейера для быстрой и надежной сборки, тестирования, развертывания, мониторинга, отчетности и управления вашими тестами Selenium, и многое другое. В этом руководстве по Jenkins мы рассмотрим, как создать многоветвевой конвейер Jenkins и основные концепции, связанные с настройкой многоветвевого конвейера Jenkins для автоматизации тестирования Selenium.
Давайте начнем.
Что такое Многоветвевой Конвейер Jenkins?
Согласно официальной документации, тип работы многоветвевого конвейера позволяет определить задание, где из одного репозитория git Jenkins обнаружит несколько ветвей и создаст вложенные задания, когда найдет Jenkinsfile.
Из приведенного выше определения можно понять, что Jenkins может сканировать репозиторий Git на предмет наличия Jenkinsfile и создавать задания автоматически. Все, что ему нужно от нас, это детали репозитория Git. В этой статье мы будем использовать пример репозитория GitHub. Наш пример репозитория GitHub содержит пример проекта Spring Boot, который может быть развернут на Tomcat.
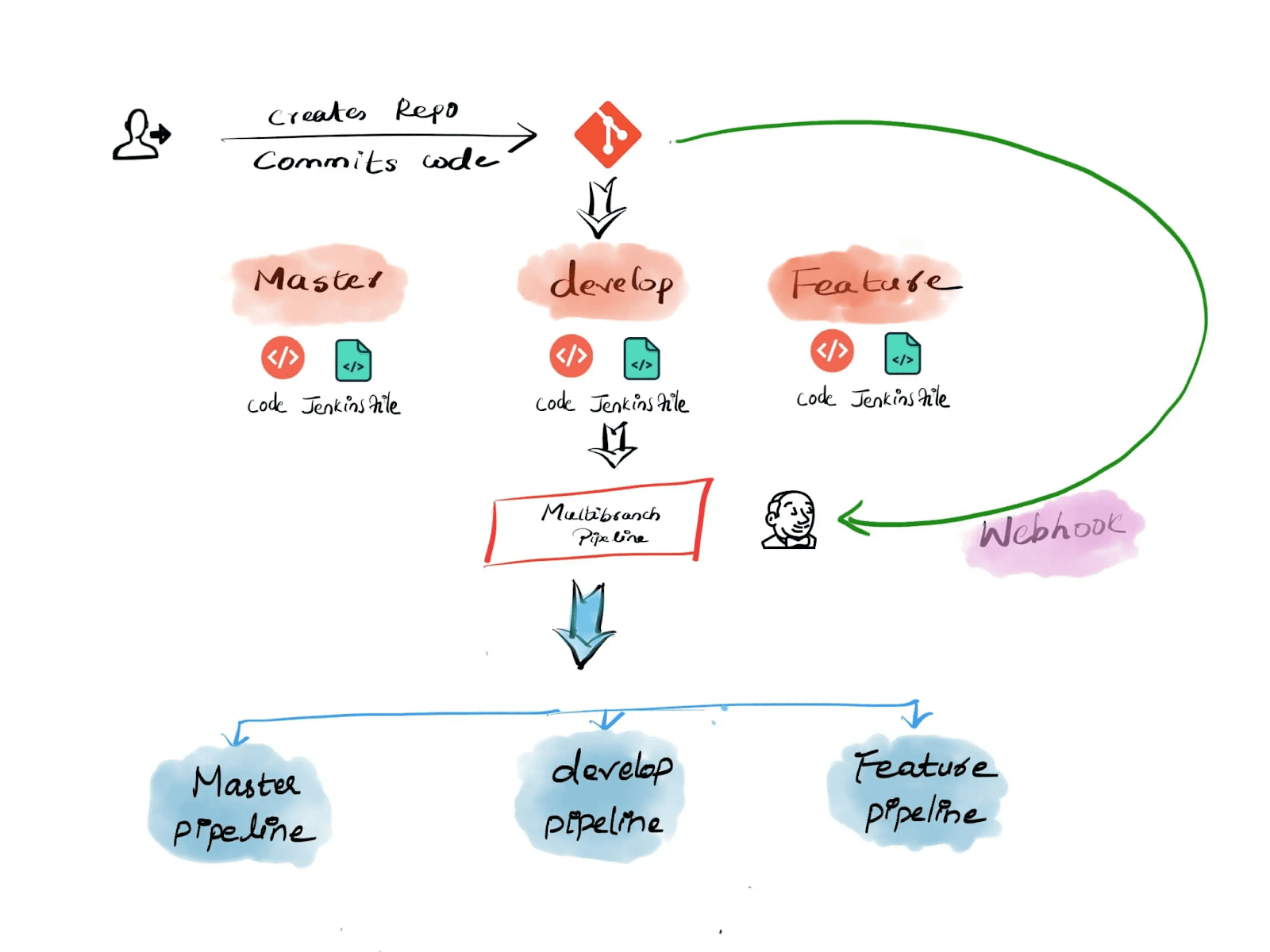
В корневом каталоге проекта находится Jenkinsfile. Мы использовали синтаксис декларативной конвейерной нотации Jenkins для создания этого Jenkinsfile. Если вы новичок в декларативной конвейерной нотации Jenkins, пожалуйста, прочтите нашу подробную статью здесь.
Пример Jenkinsfile
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code"
"""
}
}
}
}В нашем Jenkinsfile мы создали два этапа “Сборка кода” и “Развертывание кода”, каждый из которых настроен на вывод соответствующих сообщений. Теперь у нас есть репозиторий Git с Jenkinsfile, готовый к работе.
Давайте создадим многоветвевой конвейер Jenkins на сервере Jenkins.
Jenkins Pipeline против Multibranch Pipeline
Конвейер Jenkins – это новое слово в мире технологий, но он не подходит для всех. А многоветвевые конвейеры все еще великолепны. В этом разделе руководства по многоветвевому конвейеру Jenkins давайте рассмотрим идеальные случаи использования конвейера Jenkins и многоветвевого конвейера через сравнение конвейера Jenkins и многоветвевого конвейера.
Система конфигурации заданий Jenkins pipeline позволяет настроить конвейер заданий, которые будут выполняться автоматически от вашего имени. Jenkins pipeline может содержать несколько этапов, и каждый этап будет выполняться одним агентом, работающим на одном или нескольких компьютерах. Обычно конвейер создается для конкретной ветки исходного кода. При создании нового задания вы увидите опцию выбора репозитория исходного кода и ветки. Вы также можете создать новый конвейер для нового проекта или нового функционала существующего проекта.
Jenkins pipeline позволяет создать гибкий Jenkinsfile с этапами для сборки. Таким образом, вы можете иметь начальный этап, на котором выполняется линтинг, тестирование и т. д., а затем отдельные этапы для сборки артефактов или их развертывания. Это очень полезно, когда вы хотите выполнить несколько задач в конвейере.
Что делать, если у вас есть только одна задача? Или если все задачи, которые вы хотите выполнить, различаются в зависимости от некоторой конфигурации? Есть ли смысл использовать Jenkins pipeline здесь?
Подход multibranch pipeline может быть более подходящим в этих случаях. Multibranch pipeline позволяет выделить задачи в ветки и объединить их позже. Это очень похоже на работу с ветками в Git.
A multibranch pipeline is a pipeline that has multiple branches. The main advantage of using a multibranch pipeline is to build and deploy multiple branches from a single repository. Having a multibranch pipeline also allows you to have different environments for different branches. However, it is not recommended to use a multibranch pipeline if you do not have a standard branching and CI/CD strategy.
Теперь, когда вы видели сравнение Jenkins pipeline и multibranch pipeline, давайте рассмотрим шаги по созданию Jenkins multibranch pipeline.
Создание Jenkins Multibranch Pipeline
Шаг 1
Откройте домашнюю страницу Jenkins (http://localhost:8080 локально) и нажмите на “New Item” в меню слева.
Шаг 2
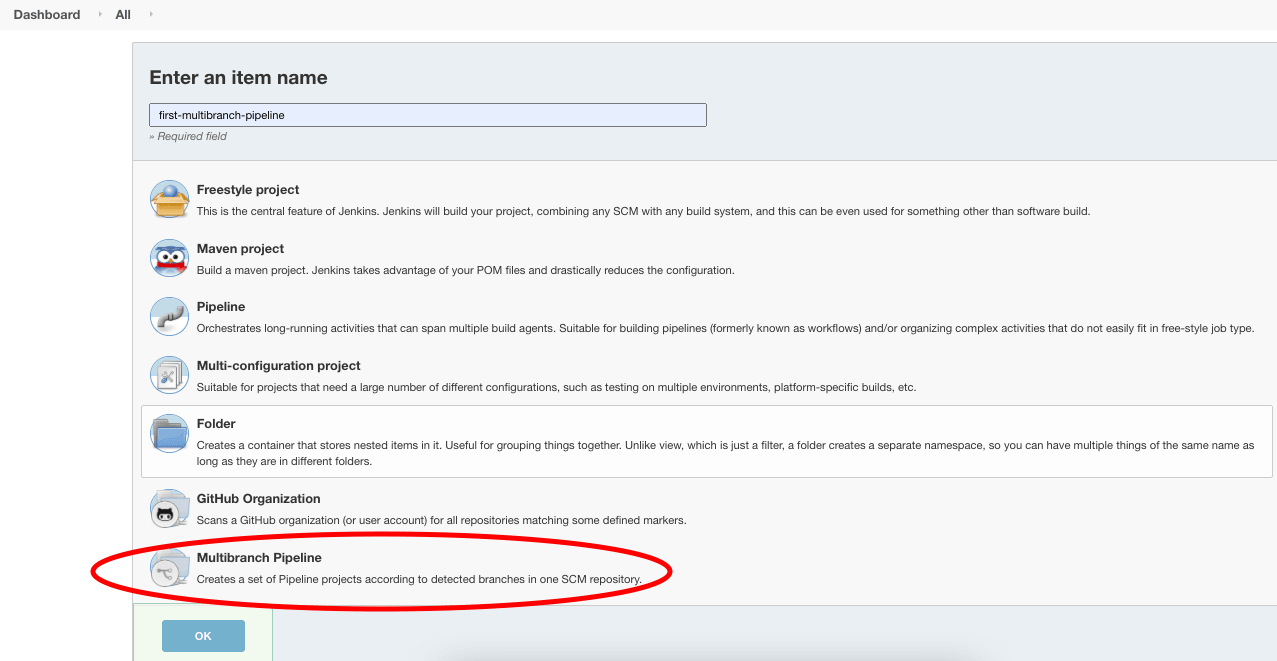
Введите имя задания Jenkins, выберите стиль как “многоветвевой конвейер,” и нажмите “ОК.”
Шаг 3
На странице “Настройка” нам нужно настроить только одно: источник репозитория Git.
Прокрутите вниз до раздела “Источники веток” и нажмите на выпадающее меню “Добавить источник”.
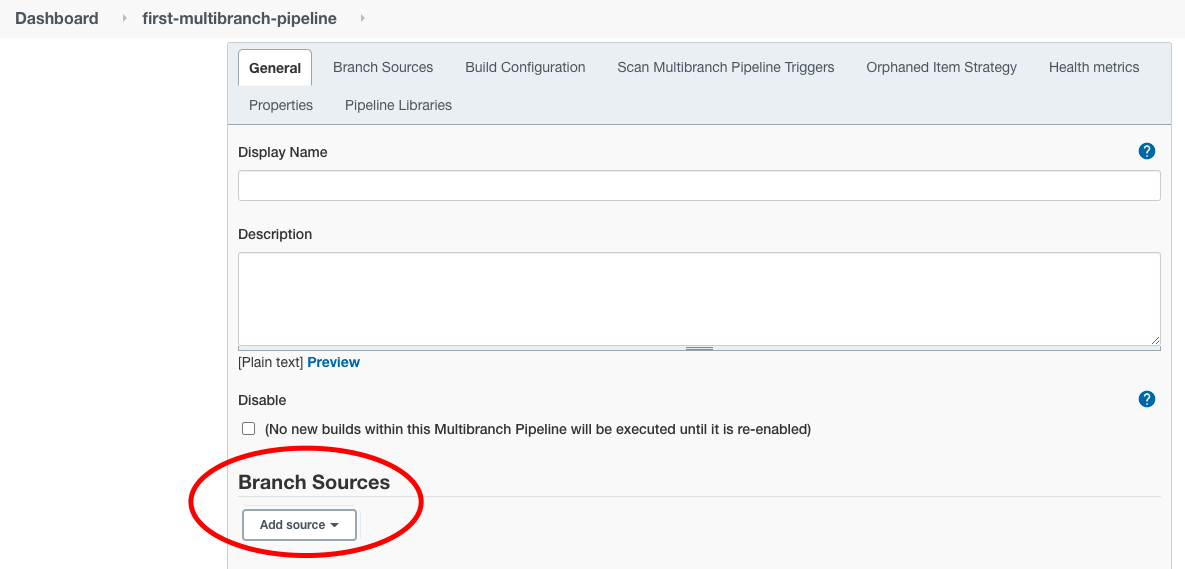
Выберите “GitHub” в качестве источника, так как наш образец репозитория GitHub размещен там.
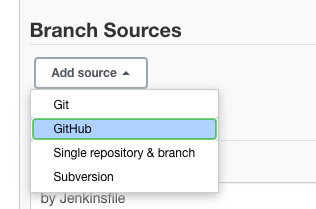
Шаг 4
Введите URL-адрес HTTPS репозитория как https://github.com/iamvickyav/spring-boot-h2-war-tomcat.git и нажмите на “Проверить.”
Так как наш репозиторий GitHub размещен как публичный репозиторий, нам не нужно настраивать учетные данные для доступа к нему. Для корпоративных/приватных репозиториев может потребоваться настройка учетных данных для доступа.

Сообщение “Учетные данные в порядке” означает успешное соединение между сервером Jenkins и репозиторием Git.
Шаг 5
Оставьте остальные разделы конфигурации такими, какие они есть, и нажмите кнопку “Сохранить” внизу.
При сохранении Jenkins автоматически выполнит следующие шаги:
Сканирование репозитория
- Сканирование настроенного репозитория Git.
- Поиск списка доступных веток в репозитории Git.
- Выбор веток, которые содержат Jenkinsfile.
Выполнение сборки
- Запустить сборку для каждой из веток, найденных на предыдущем шаге, с использованием указанных шагов в Jenkinsfile.
Из раздела “Журнал сканирования репозитория” мы можем понять, что произошло во время шага сканирования репозитория.
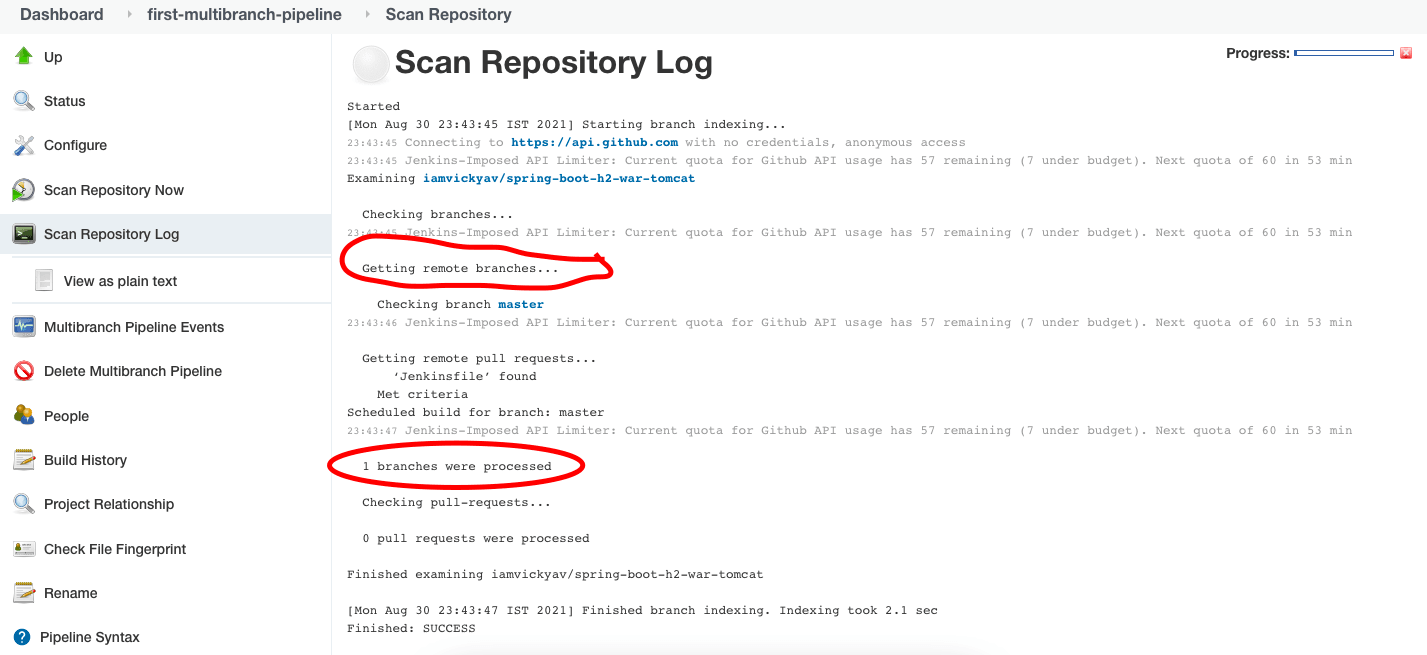
Так как у нас в репозитории git имеется только основная ветка, Журнал сканирования репозитория говорит “одна ветка была обработана”.
После завершения сканирования Jenkins создаст и запустит задание сборки для каждой обработанной ветки отдельно.
В нашем случае у нас была только одна ветка под названием master. Следовательно, сборка будет запущена только для нашей основной ветки. Мы можем проверить это, нажав на “Статус” в левой части меню.
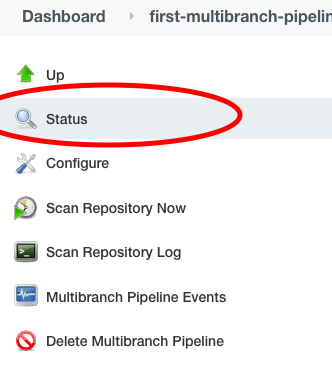
Мы можем увидеть задание сборки для основной ветки в разделе статуса.
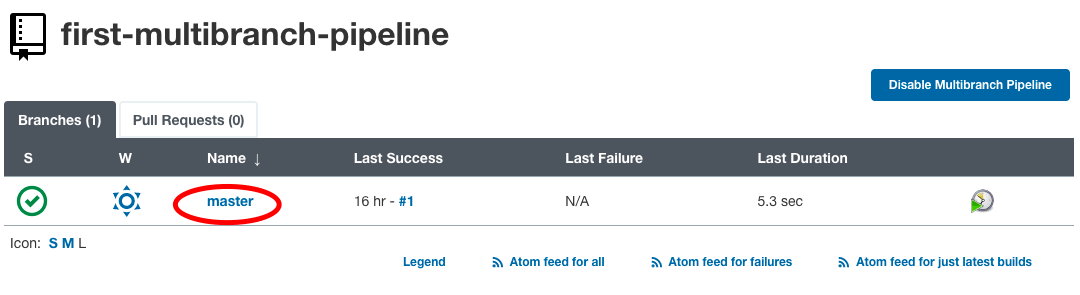
Нажмите на название ветки, чтобы увидеть лог задания сборки и статус.
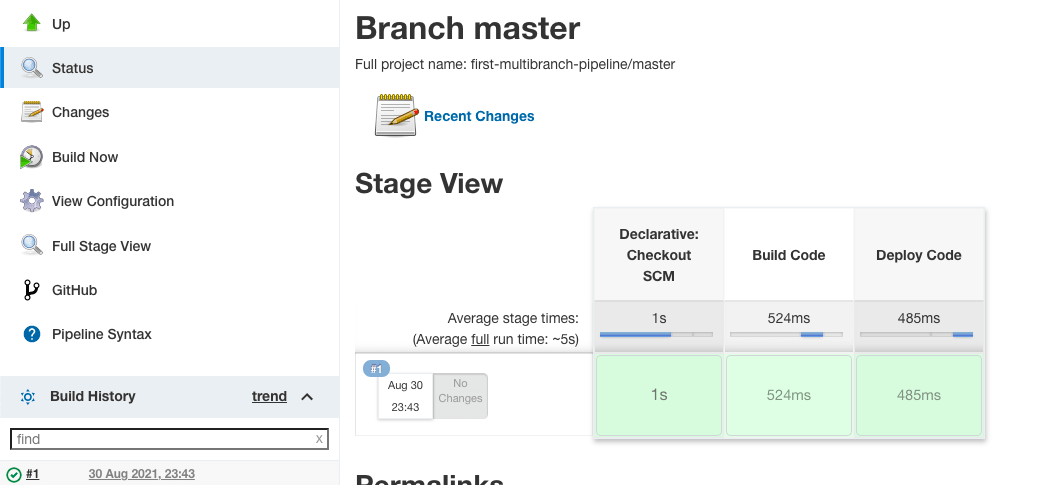
“Просмотр этапов” дает визуальное представление о том, сколько времени занял каждый этап выполнения и статус задания сборки.
Доступ к логам выполнения задания сборки
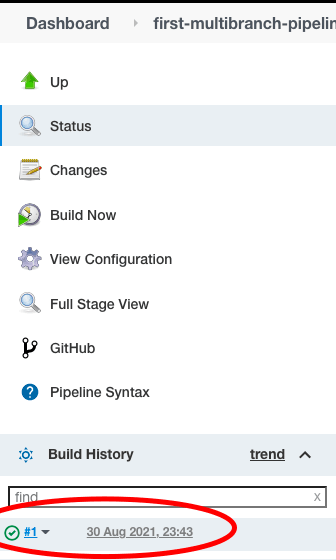
Шаг 1
Нажмите на “Номер сборки” в разделе “История сборок“.
Шаг 2
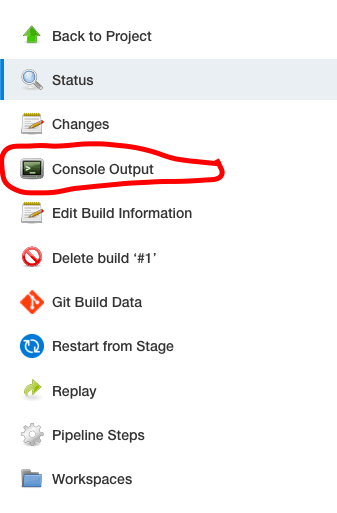
Затем выберите “Консольный вывод” в левой части меню, чтобы увидеть логи.
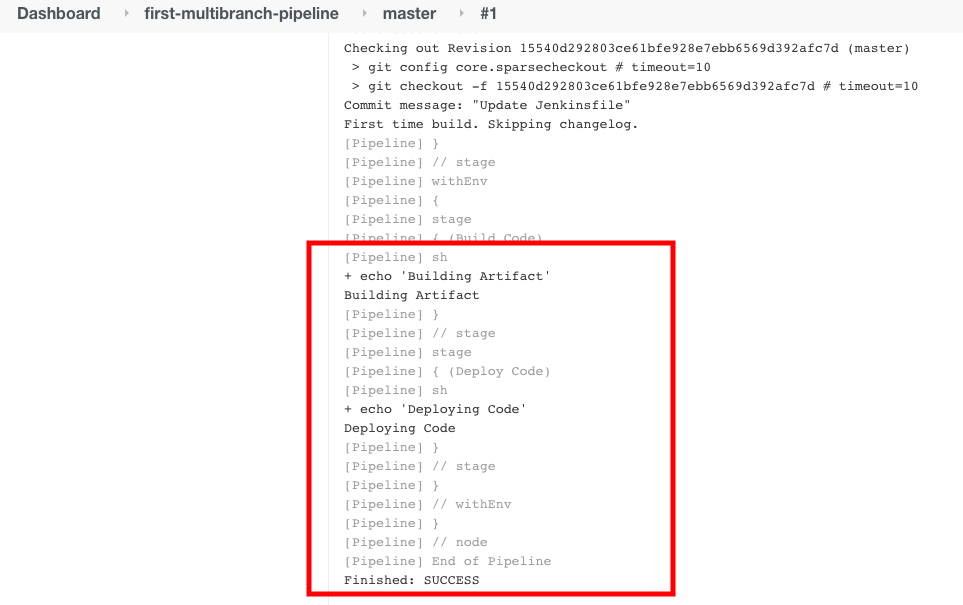
Что произойдет, если у нас в репозитории Git будет более одной ветки? Давайте проверим это сейчас.
В репозитории Git создается новая ветка под названием “разработка“.
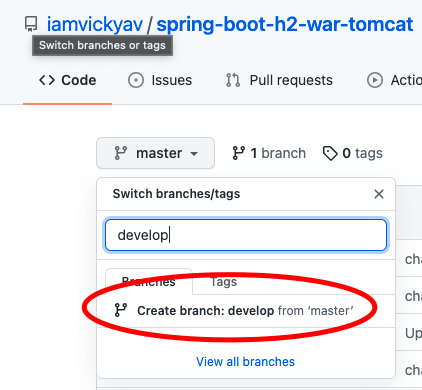
Для различения сборки ветки “разработка“, мы внесли небольшие изменения в команды echo в Jenkinsfile.
Jenkinsfile в Master Branch
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code"
"""
}
}
}
}Jenkinsfile в Develop Branch
pipeline {
agent any
stages {
stage('Build Code') {
steps {
sh """
echo "Building Artifact from Develop Branch"
"""
}
}
stage('Deploy Code') {
steps {
sh """
echo "Deploying Code from Develop Branch"
"""
}
}
}
}Теперь у нас есть два Jenkinsfile в двух разных ветках. Давайте повторно запустим сканирование репозитория в Jenkins, чтобы увидеть поведение.
Мы видим, что новая ветка (ветка разработки) была обнаружена Jenkins. Таким образом, была создана новая задача отдельно для ветки разработки.
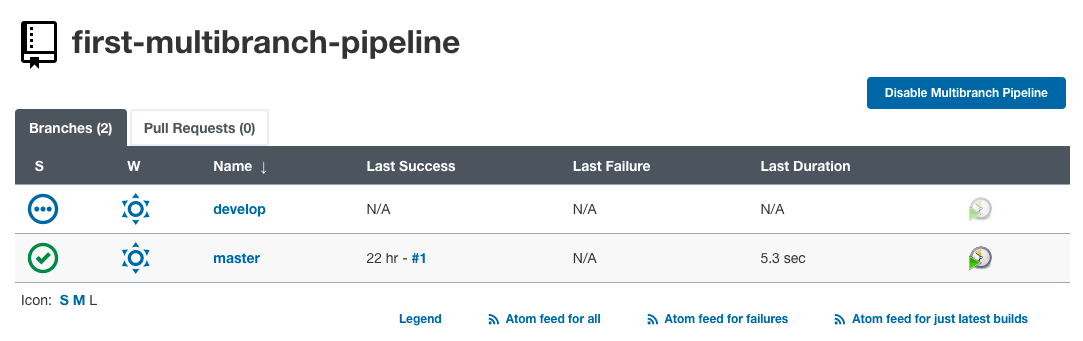
Нажав на “разработка“, мы можем увидеть лог сборки задачи для ветки разработки.
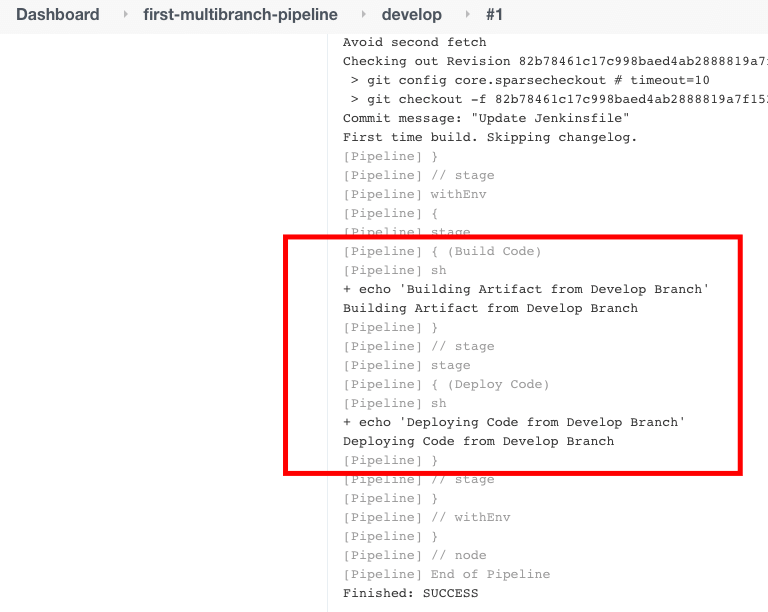
В предыдущем примере мы сохраняли разные содержимое для Jenkinsfile в ветках master и develop. Но так мы делаем это не в реальных приложениях. Мы используем блоки when внутри блока stage для проверки ветки.
Вот пример с объединенными шагами для master и develop веток. Это же содержимое будет размещено в обоих Jenkinsfile ветки master и develop.
pipeline {
agent any
stages {
stage('Master Branch Deploy Code') {
when {
branch 'master'
}
steps {
sh """
echo "Building Artifact from Master branch"
"""
sh """
echo "Deploying Code from Master branch"
"""
}
}
stage('Develop Branch Deploy Code') {
when {
branch 'develop'
}
steps {
sh """
echo "Building Artifact from Develop branch"
"""
sh """
echo "Deploying Code from Develop branch"
"""
}
}
}
}Шаг 3
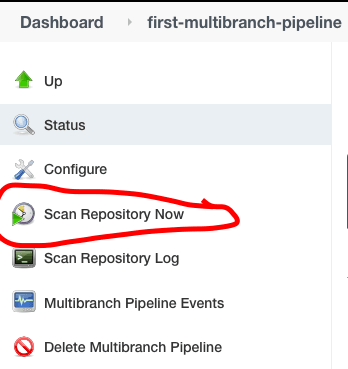
Нажмите на “Сканировать Репозиторий” в меню слева, чтобы Jenkins обнаружил новые изменения из репозитория Git.
К этому времени вы могли заметить, что мы используем сканирование репозитория каждый раз, когда хотим, чтобы Jenkins обнаружил изменения из репозитория.
Как насчет автоматизации этого шага?
Периодический триггер для сканирования многоветвевой конвейерной сборки Jenkins
Шаг 1
Нажмите “Настроить” в меню слева.
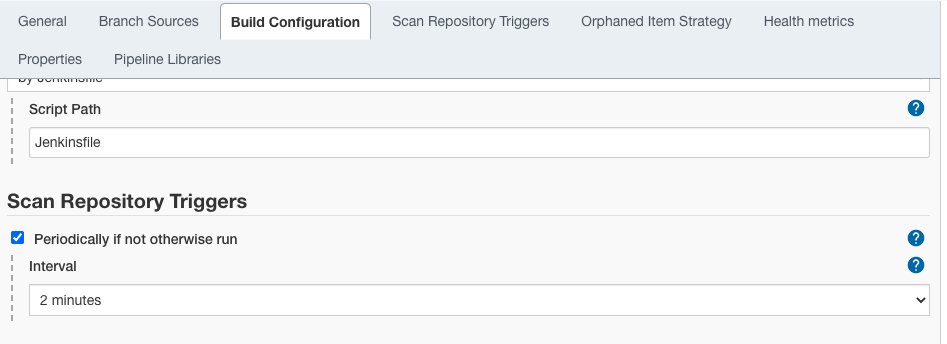
Шаг 2
Прокрутите вниз до раздела “Сканирование триггеров репозитория” и включите флажок “Периодически, если не запущено иначе” и выберите интервал времени для периодического запуска сканирования (в нашем примере – каждые две минуты).
Шаг 3
Нажмите на кнопку “Сохранить“.
С этого момента Jenkins будет сканировать репозиторий каждые две минуты. Если обнаружится новый коммит в любой из ветвей, Jenkins запустит новый рабочий процесс сборки для этой конкретной ветви с использованием Jenkinsfile.
Ниже приведен “Журнал сканирования репозитория“, который ясно показывает запуск сканирования каждые две минуты.

Реальные случаи использования многоветвевого конвейера Jenkins
Ниже приведены несколько сценариев, где многоветвевой конвейер Jenkins может быть полезен:
- Любой новый коммит в основной ветви должен автоматически развертываться на сервере.
- Если разработчик пытается создать Pull Request (PR) для разработки ветви, то:
- Код должен успешно собраться без ошибок компиляции.
- Код должен иметь минимальный охват тестами в 80%.
- Код должен пройти тест качества кода SONAR.
- Если разработчики пытаются отправить код в ветку, отличную от основной или разработки, код должен успешно скомпилироваться. Если нет, отправьте уведомление по электронной почте.
Вот пример Jenkinsfile, охватывающий некоторые из вышеупомянутых случаев использования:
pipeline {
agent any
tools {
maven 'MAVEN_PATH'
jdk 'jdk8'
}
stages {
stage("Tools initialization") {
steps {
sh "mvn --version"
sh "java -version"
}
}
stage("Checkout Code") {
steps {
checkout scm
}
}
stage("Check Code Health") {
when {
not {
anyOf {
branch 'master';
branch 'develop'
}
}
}
steps {
sh "mvn clean compile"
}
}
stage("Run Test cases") {
when {
branch 'develop';
}
steps {
sh "mvn clean test"
}
}
stage("Check Code coverage") {
when {
branch 'develop'
}
steps {
jacoco(
execPattern: '**/target/**.exec',
classPattern: '**/target/classes',
sourcePattern: '**/src',
inclusionPattern: 'com/iamvickyav/**',
changeBuildStatus: true,
minimumInstructionCoverage: '30',
maximumInstructionCoverage: '80')
}
}
stage("Build and Deploy Code") {
when {
branch 'master'
}
steps {
sh "mvn tomcat7:deploy"
}
}
}
}Мы добавили этот новый Jenkinsfile в ветки master и develop, чтобы он мог быть обнаружен Jenkins multibranch при следующем сканировании репозитория.
Автоматическое тестирование Selenium с использованием Jenkins Multibranch Pipeline
Предположим, мы пишем автоматические тестовые случаи для веб-сайта. Каждый раз, когда новый тестовый случай коммитится в ветке, мы хотим запускать их и убедиться, что они выполняются как ожидается.
Запуск автоматических тестовых случаев на каждой комбинации браузера и операционной системы является кошмаром для любого разработчика. Вот где мощная инфраструктура автоматического тестирования LambdaTest может оказаться полезной.
Используя сеть Selenium LambdaTest, вы можете максимально увеличить охват браузеров.
В этом разделе мы рассмотрим, как использовать инфраструктуру тестирования LambdaTest с помощью Jenkins multibranch pipeline. Для демонстрации мы разместили образец приложения Todo здесь — LambdaTest ToDo App. Автоматические тестовые случаи, написанные с использованием Cucumber, коммитились в образце репозитория.
Из Jenkins мы хотим запустить эти тестовые случаи на платформе LambdaTest. Запуск тестовых случаев в LambdaTest требует имени пользователя и accessToken. Зарегистрируйтесь на платформе LambdaTest бесплатно, чтобы получить свои учетные данные.
Настройка переменных окружения
Когда запускается тестовый случай, он будет искать имя пользователя LambdaTest (LT_USERNAME) и пароль (LT_ACCESS_KEY) в переменных окружения. Поэтому нам нужно настроить их заранее.
Чтобы избежать хранения их в исходном коде, мы настроили их как секреты в Jenkins и загрузили переменные окружения из них:
environment {
LAMBDATEST_CRED = credentials('Lambda-Test-Credentials-For-multibranch')
LT_USERNAME = "$LAMBDATEST_CRED_USR"
LT_ACCESS_KEY = "$LAMBDATEST_CRED_PSW"
}Вот наш окончательный Jenkinsfile:
pipeline {
agent any
tools {
maven 'MAVEN_PATH'
jdk 'jdk8'
}
stages {
stage("Tools initialization") {
steps {
sh "mvn --version"
sh "java -version"
}
}
stage("Checkout Code") {
steps {
checkout scm
}
}
stage("Check Code Health") {
when {
not {
anyOf {
branch 'master';
branch 'develop'
}
}
}
steps {
sh "mvn clean compile"
}
}
stage("Run Test cases in LambdaTest") {
when {
branch 'develop';
}
environment {
LAMBDATEST_CRED = credentials('Lambda-Test-Credentials-For-multibranch')
LT_USERNAME = "$LAMBDATEST_CRED_USR"
LT_ACCESS_KEY = "$LAMBDATEST_CRED_PSW"
}
steps {
sh "mvn test"
}
}
}
}Теперь мы создадим новый “Job” в Jenkins в качестве многоветвевой конвейерной системы, следуя инструкциям, указанным в предыдущих разделах. Укажем на примерный репозиторий.
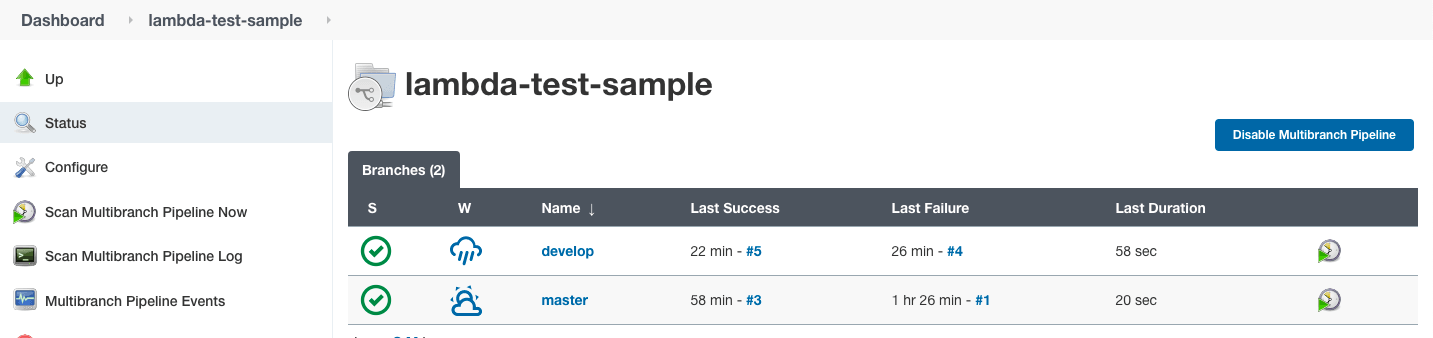
После успешного выполнения сборки посетите панель автоматизации LambdaTest, чтобы получить журналы тестов.
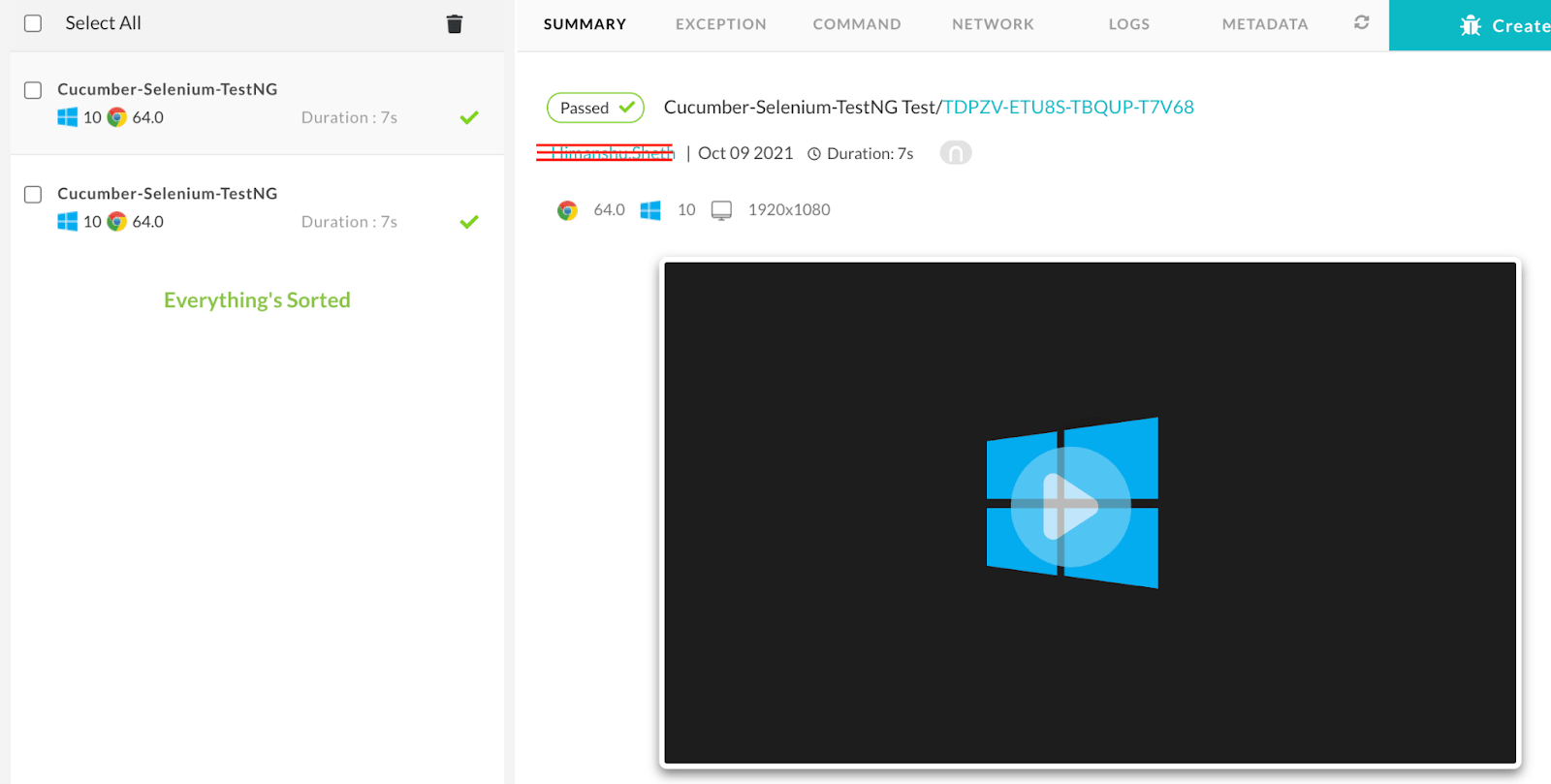
Заключение
Таким образом, мы узнали, как создать многоветвевой конвейер Jenkins, как настроить в нем репозиторий git, различные шаги сборки для разных ветвей, использование периодического автосканирования репозитория Jenkins и использование мощной инфраструктуры автоматических тестов LambdaTest для автоматизации наших CI/CD сборок. Надеюсь, вам была полезна эта статья. Пожалуйста, поделитесь своим мнением в разделе комментариев.
Source:
https://dzone.com/articles/how-to-create-jenkins-multibranch-pipeline