













Введение
Как и в любой другой среде, данные в кластере Kubernetes могут быть подвержены риску потери. Чтобы предотвратить серьезные проблемы, важно иметь план восстановления данных под рукой. Простой и эффективный способ сделать это – создать резервные копии, обеспечивая безопасность ваших данных в случае неожиданных событий. Резервные копии могут запускаться единожды или по расписанию. Хорошей практикой является наличие запланированных резервных копий, чтобы убедиться, что у вас есть последняя версия резервной копии, к которой легко можно вернуться при необходимости.
Velero – это инструмент с открытым исходным кодом, разработанный для резервного копирования и восстановления операций для кластеров Kubernetes. Он идеально подходит для случаев восстановления после катастрофы, а также для создания снимков состояния вашего приложения перед выполнением операций системы на вашем кластере, таких как обновления. Дополнительные сведения по этой теме можно найти на официальной странице Как работает Velero.
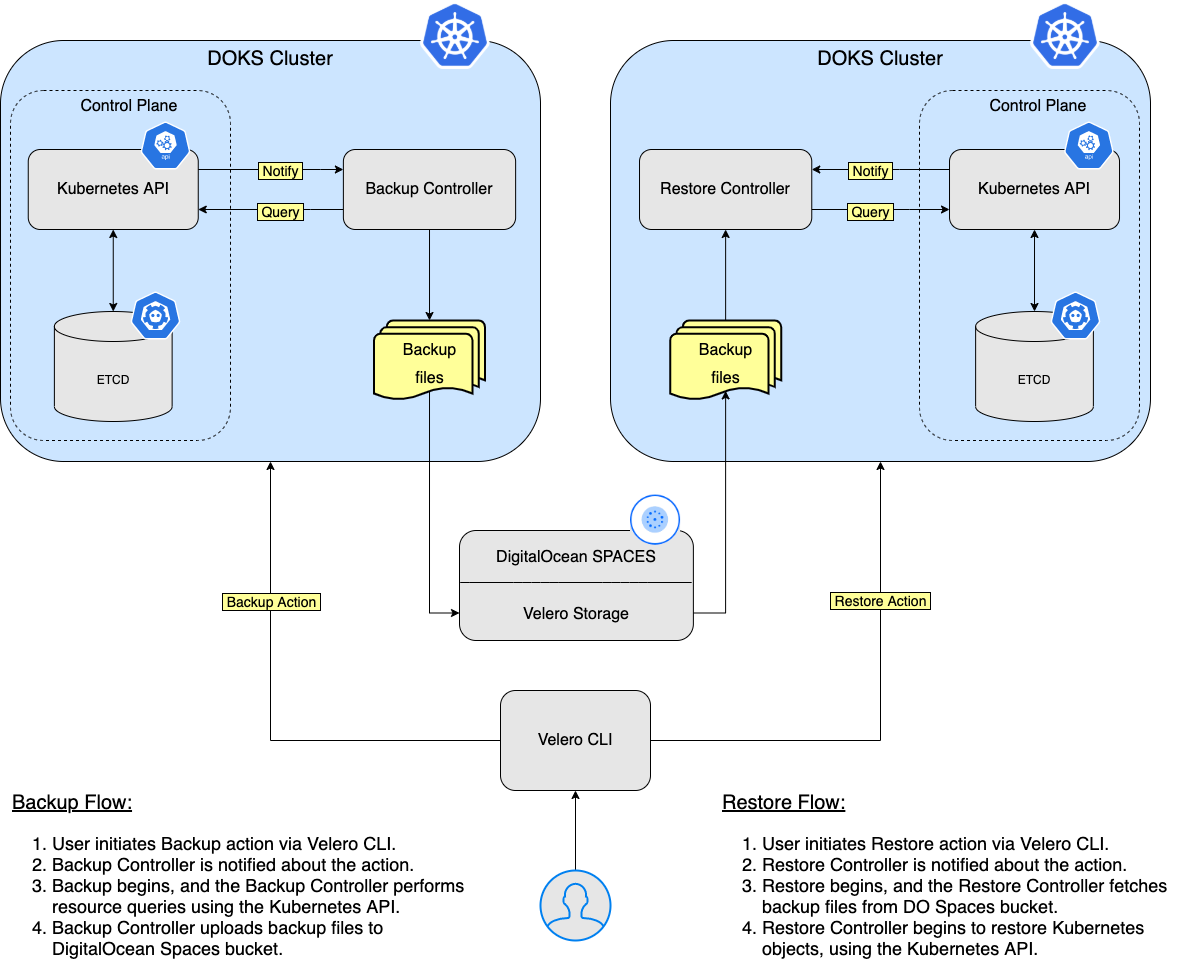
В этом руководстве вы узнаете, как развернуть Velero на свой кластер Kubernetes, создавать резервные копии и восстанавливаться из резервной копии в случае возникновения проблем. Вы можете создавать резервные копии всего кластера или выбрать пространство имен или селектор меток, чтобы создать резервную копию кластера.
Содержание
- Предварительные требования
- Шаг 1 – Установка Velero с использованием Helm
- Шаг 2 – Пример резервного копирования и восстановления пространства имен
- Шаг 3 – Пример резервного копирования и восстановления всего кластера
- Шаг 4 – Запланированные резервные копии
- Шаг 5 – Удаление резервных копий
Предварительные требования
Для завершения этого руководства вам понадобятся следующие компоненты:
- A DO Spaces Bucket and access keys. Save the access and secret keys in a safe place for later use.
- A DigitalOcean API token for Velero to use.
- A Git client, to clone the Starter Kit repository.
- Helm для управления релизами и обновления Velero.
- Doctl для взаимодействия с API DigitalOcean.
- Kubectl для взаимодействия с Kubernetes.
- Клиент Velero для управления резервными копиями Velero.
Шаг 1 – Установка Velero с использованием Helm
На этом этапе вы развернете Velero и все необходимые компоненты, чтобы он мог выполнять резервное копирование ресурсов вашего кластера Kubernetes (включая PV). Резервные данные будут сохранены в бакете DO Spaces, созданном ранее в разделе Предварительные требования.
Сначала клонируйте репозиторий Git Starter Kit и перейдите в каталог вашей локальной копии:
Затем добавьте репозиторий Helm и выведите список доступных диаграмм:
Вывод будет похож на следующий:
NAME CHART VERSION APP VERSION DESCRIPTION
vmware-tanzu/velero 2.29.7 1.8.1 A Helm chart for velero
Интересующей нас диаграммой является vmware-tanzu/velero, которая установит Velero в кластер. Пожалуйста, посетите страницу диаграммы Velero для получения более подробной информации о ней.
Затем откройте и проверьте файл значений Helm для Velero, предоставленный в репозитории Starter Kit, используя редактор на ваш выбор (желательно с поддержкой проверки YAML).
Затем, замените соответствующим образом заполнители <> для вашего бакета Velero в DO Spaces (например, имя, регион и секреты). Убедитесь, что также предоставили свой токен API DigitalOcean (DIGITALOCEAN_TOKEN).
Наконец, установите Velero, используя helm:
A specific version of the Velero Helm chart is used. In this case 2.29.7 is picked, which maps to the 1.8.1 version of the application (see the output from Step 2.). It’s a good practice in general to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
Теперь проверьте развертывание Velero, запустив следующую команду:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
velero velero 1 2022-06-09 08:38:24.868664 +0300 EEST deployed velero-2.29.7 1.8.1
Вывод будет похож на следующий (столбец STATUS должен отображать deployed):
Затем убедитесь, что Velero работает:
NAME READY UP-TO-DATE AVAILABLE AGE
velero 1/1 1 1 67s
Выходные данные выглядят примерно следующим образом (поды развертывания должны быть в состоянии Ready):
Если вас интересует более подробное изучение, вы можете просмотреть серверные компоненты Velero:
- Исследуйте страницы справки по CLI Velero, чтобы увидеть доступные команды и подкоманды. Вы можете получить справку для каждой, используя флаг
--help: - Список всех доступных команд для
Velero:
Список опций команды backup для Velero:
Velero использует несколько CRD (определений пользовательских ресурсов), чтобы представлять свои ресурсы, такие как резервные копии, расписания резервного копирования и т. д. Вы узнаете об этом на следующих этапах учебного пособия, вместе с некоторыми базовыми примерами.
Шаг 2 – Пример резервного копирования и восстановления пространства имен
В этом шаге вы узнаете, как выполнить одноразовое резервное копирование для всего пространства имён из вашего кластера DOKS, а затем восстановить его, убедившись, что все ресурсы воссозданы. Вопросом является пространство имён ambassador.
Создание Резервной Копии Пространства Имён Ambassador
Сначала инициируйте резервное копирование:
Затем проверьте, что резервная копия была создана:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 29d default <none>
Вывод выглядит аналогично:
Затем, спустя несколько моментов, вы можете её проверить:
Name: ambassador-backup
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
...
- Вывод выглядит аналогично:
- Ищите строку
Phase. Она должна говоритьCompleted. - Также проверьте, чтобы ошибок не было отмечено.
Создан новый объект резервного копирования Kubernetes:
~ kubectl get backup/ambassador-backup -n velero -o yaml
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
velero.io/source-cluster-k8s-gitversion: v1.21.2
velero.io/source-cluster-k8s-major-version: "1"
velero.io/source-cluster-k8s-minor-version: "21"
...
Наконец, посмотрите на корзину DO Spaces и проверьте, есть ли там новая папка с именем backups, которая содержит созданные активы для вашей ambassador-backup:
Удаление пространства имен и ресурсов Ambassador
Сначала симулируйте катастрофу, намеренно удалив пространство имен ambassador:
Затем проверьте, было ли удалено пространство имен (список пространств имен не должен печатать ambassador):
Наконец, убедитесь, что конечная точка службы echo и quote недоступна. Обратитесь к Создание бэкенд-служб Ambassador Edge Stack относительно используемых в учебнике Starter Kit бэкенд-приложений. Вы можете использовать curl для тестирования (или можете использовать веб-браузер):
Восстановление резервной копии пространства имен Ambassador
Восстановите ambassador-backup:
Важно: При удалении пространства имён ambassador также будет удален ресурс балансировщика нагрузки, связанный с сервисом ambassador. Поэтому, когда вы восстанавливаете службу ambassador, балансировщик нагрузки будет воссоздан DigitalOcean. Проблема здесь в том, что вы получите НОВЫЙ IP-адрес для вашего балансировщика нагрузки, поэтому вам нужно будет настроить записи A records, чтобы направить трафик на домены, размещенные на кластере.
Проверка восстановления пространства имён Ambassador
Чтобы проверить восстановление пространства имён ambassador, проверьте строку Phase из вывода команды восстановления ambassador-backup. Она должна указывать Completed (также обратите внимание на раздел Предупреждения – он сообщает, если что-то пошло не так):
Затем проверьте, что все ресурсы были восстановлены для пространства имён ambassador. Ищите поды, сервисы и развёртывания ambassador.
NAME READY STATUS RESTARTS AGE
pod/ambassador-5bdc64f9f6-9qnz6 1/1 Running 0 18h
pod/ambassador-5bdc64f9f6-twgxb 1/1 Running 0 18h
pod/ambassador-agent-bcdd8ccc8-8pcwg 1/1 Running 0 18h
pod/ambassador-redis-64b7c668b9-jzxb5 1/1 Running 0 18h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ambassador LoadBalancer 10.245.74.214 159.89.215.200 80:32091/TCP,443:31423/TCP 18h
service/ambassador-admin ClusterIP 10.245.204.189 <none> 8877/TCP,8005/TCP 18h
service/ambassador-redis ClusterIP 10.245.180.25 <none> 6379/TCP 18h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ambassador 2/2 2 2 18h
deployment.apps/ambassador-agent 1/1 1 1 18h
deployment.apps/ambassador-redis 1/1 1 1 18h
NAME DESIRED CURRENT READY AGE
replicaset.apps/ambassador-5bdc64f9f6 2 2 2 18h
replicaset.apps/ambassador-agent-bcdd8ccc8 1 1 1 18h
replicaset.apps/ambassador-redis-64b7c668b9 1 1 1 18h
Вывод выглядит примерно так:
Получить хосты ambassador:
NAME HOSTNAME STATE PHASE COMPLETED PHASE PENDING AGE
echo-host echo.starter-kit.online Ready 11m
quote-host quote.starter-kit.online Ready 11m
Вывод выглядит примерно так:
СОСТОЯНИЕ должно быть Готов, а столбец ИМЯ ХОСТА должен указывать на полностью определенное имя хоста.
Получить сопоставления ambassador:
NAME SOURCE HOST SOURCE PREFIX DEST SERVICE STATE REASON
ambassador-devportal /documentation/ 127.0.0.1:8500
ambassador-devportal-api /openapi/ 127.0.0.1:8500
ambassador-devportal-assets /documentation/(assets|styles)/(.*)(.css) 127.0.0.1:8500
ambassador-devportal-demo /docs/ 127.0.0.1:8500
echo-backend echo.starter-kit.online /echo/ echo.backend
quote-backend quote.starter-kit.online /quote/ quote.backend
Вывод похож на (обратите внимание на echo-backend, который сопоставлен с хостом echo.starter-kit.online и префиксом источника /echo/, а также на quote-backend):
Наконец, после переконфигурирования вашего балансировщика нагрузки и настроек домена DigitalOcean, пожалуйста, убедитесь, что конечная точка служб echo и quote бэкэнда – UP. См. Создание бэкэнд-служб Ambassador Edge Stack.
На следующем этапе вы симулируете катастрофу, намеренно удаляя свой кластер DOKS.
Шаг 3 – Пример резервного копирования и восстановления всего кластера
На этом этапе вы симулируете сценарий восстановления после катастрофы. Весь кластер DOKS будет удален, а затем восстановлен из предыдущей резервной копии.
Создание резервной копии кластера DOKS
Сначала создайте резервную копию всего кластера DOKS:
Затем проверьте, что резервная копия была создана и не сообщает об ошибках. Следующая команда перечисляет все доступные резервные копии:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
all-cluster-backup Completed 0 0 2021-08-25 19:43:03 +0300 EEST 29d default <none>
Вывод выглядит аналогично:
Наконец, проверьте состояние резервной копии и журналы (убедитесь, что ошибок не сообщается):
Важно: Всякий раз, когда вы уничтожаете кластер DOKS, не указывая флаг --dangerous для команды doctl, а затем восстанавливаете его, тот же балансировщик нагрузки с тем же IP-адресом воссоздается. Это означает, что вам не нужно обновлять ваши DNS-записи A DigitalOcean.
Однако, когда применяется флаг --dangerous к команде doctl, существующий балансировщик нагрузки будет уничтожен, и новый балансировщик нагрузки с новым внешним IP будет создан при восстановлении вашего контроллера входа. Поэтому, пожалуйста, убедитесь, что обновили ваши DNS-записи A DigitalOcean соответствующим образом.
Сначала удалите весь кластер DOKS (убедитесь, что заменили заполнители <> соответствующим образом).
Чтобы удалить кластер Kubernetes, не уничтожая связанный балансировщик нагрузки, выполните:
Или чтобы удалить кластер Kubernetes вместе с ассоциированным балансировщиком нагрузки:
Затем воссоздайте кластер, как описано в Настройте Kubernetes DigitalOcean. Важно убедиться, что количество узлов нового кластера DOKS равно или больше оригинального.
Затем установите Velero CLI и Server, как описано в разделе Предварительные требования и Шаг 1 – Установка Velero с использованием Helm соответственно. Важно использовать тот же номер версии Helm Chart.
Наконец, восстановите все, выполнив следующую команду:
Проверка состояния приложений кластера DOKS
Сначала проверьте строку Phase вывода команды all-cluster-backup restore describe. (Замените соответствующие заполнители <>). Она должна указывать Completed.
Теперь проверьте все ресурсы кластера, запустив:
Теперь бэкенд-приложения должны также реагировать на HTTP-запросы. Пожалуйста, обратитесь к Создание бэкенд-сервисов Ambassador Edge Stack относительно используемых бэкенд-приложений в учебнике Starter Kit.
В следующем шаге вы узнаете, как выполнять запланированные (или автоматические) резервные копии для приложений вашего кластера DOKS.
Шаг 4 – Запланированные резервные копии
Автоматическое выполнение резервных копий по расписанию – это действительно полезная функция. Она позволяет откатиться во времени и восстановить систему до предыдущего рабочего состояния, если что-то пойдет не так.
Создание запланированной резервной копии – очень простой процесс. Ниже приведен пример для интервала 1 минута (выбрано пространство имен kube-system).
Сначала создайте расписание:
schedule="*/1 * * * *"
Поддерживается также формат cronjob для Linux:
Затем убедитесь, что расписание было создано:
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
kube-system-minute-backup Enabled 2021-08-26 12:37:44 +0300 EEST @every 1m 720h0m0s 32s ago <none>
Вывод похож на следующий:
Затем проверьте все резервные копии через минуту или около того:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
kube-system-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:20 +0300 EEST 29d default <none>
kube-system-minute-backup-20210826093744 Completed 0 0 2021-08-26 12:37:44 +0300 EEST 29d default <none>
Вывод похож на следующий:
Проверка состояния запланированной резервной копии
Сначала проверьте строку Phase одной из резервных копий (пожалуйста, замените соответствующим образом заполнители <>). Она должна указывать Завершено.
Наконец, обратите внимание на возможные ошибки и предупреждения в вышеуказанном выводе, чтобы проверить, не произошло ли что-то не так.
Восстановление запланированного резервного копирования
Чтобы восстановить резервные копии минутой ранее, пожалуйста, следуйте тем же шагам, которые вы узнали на предыдущих этапах этого руководства. Это хороший способ потренироваться и протестировать ваше накопленное опыт.
На следующем этапе вы узнаете, как вручную или автоматически удалить определенные резервные копии, созданные вами со временем.
Шаг 5 – Удаление резервных копий
Если вам не нужны более старые резервные копии, вы можете освободить некоторые ресурсы как на кластере Kubernetes, так и в хранилище DO Spaces Velero.
Вручную удаление резервной копии
Сначала выберите резервную копию за одну минуту, например, и выполните следующую команду (замените заполнители <> соответственно):
Теперь проверьте, что его нет в выводе команды velero backup get. Он также должен быть удален из бакета DO Spaces.
Затем вы удалите несколько резервных копий одновременно, используя selector. Подкоманда velero backup delete предоставляет флаг под названием --selector. Он позволяет удалять несколько резервных копий одновременно на основе меток Kubernetes. Те же правила применяются, что и для Выбора меток Kubernetes.
Сначала перечислите доступные резервные копии:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 23d default <none>
backend-minute-backup-20210826094116 Completed 0 0 2021-08-26 12:41:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826094016 Completed 0 0 2021-08-26 12:40:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093816 Completed 0 0 2021-08-26 12:38:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093716 Completed 0 0 2021-08-26 12:37:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093616 Completed 0 0 2021-08-26 12:36:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093509 Completed 0 0 2021-08-26 12:35:09 +0300 EEST 24d default <none>
Вывод выглядит примерно так:
Затем скажите, что хотите удалить все ресурсы с именем backend-minute-backup-*. Выберите резервную копию из списка и проверьте метки:
Name: backend-minute-backup-20210826094116
Namespace: velero
Labels: velero.io/schedule-name=backend-minute-backup
velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: backend
Excluded: <none>
...
Вывод выглядит примерно так (обратите внимание на значение метки velero.io/schedule-name):
Затем вы можете удалить все резервные копии, которые соответствуют значению backend-minute-backup метки velero.io/schedule-name:
Наконец, проверьте, что все ресурсы с именем backend-minute-backup-* исчезли из вывода команды velero backup get, а также из бакета DO Spaces.
Автоматическое удаление резервных копий по TTL
- При создании резервной копии вы можете указать TTL (время жизни) с помощью флага
--ttl. Если Velero обнаруживает, что существующий ресурс резервной копии истек, он удаляет: - Ресурс
Backup - Файл резервной копии из объекта хранения в облаке
storage - Все снимки
PersistentVolume
Все связанные Restores
Флаг TTL позволяет пользователю указать период хранения резервной копии со значением, указанным в часах, минутах и секундах в форме --ttl 24h0m0s. Если не указано, будет применено значение TTL по умолчанию – 30 дней.
Сначала создайте резервную копию ambassador с использованием значения TTL 3 минуты:
Затем проверьте резервную копию ambassador:
Name: ambassador-backup-3min-ttl
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
Resources:
Included: *
Excluded: <none>
Cluster-scoped: auto
Label selector: <none>
Storage Location: default
Velero-Native Snapshot PVs: auto
TTL: 3m0s
...
A new folder should be created in the DO Spaces Velero bucket as well, named ambassador-backup-3min-ttl.
Выходные данные будут похожи на следующие (обратите внимание на раздел Namespaces -> Included – он должен отображать ambassador, а поле TTL установлено в 3ms0):
Наконец, через три минуты или около того резервная копия и связанные ресурсы должны быть автоматически удалены. Вы можете проверить, что объект резервной копии был уничтожен с помощью: velero backup describe ambassador-backup-3min-ttl. Он должен завершиться ошибкой, указывающей на то, что резервная копия больше не существует. Соответствующая папка ambassador-backup-3min-ttl из ведра Velero DO Spaces также будет удалена.