













Автор выбрал Фонд свободного и открытого исходного кода для получения пожертвования в рамках программы Пиши ради Пожертвований.
Введение
Мониторинг баз данных – это непрерывный процесс систематического отслеживания различных метрик, показывающих, как выполняется база данных. Наблюдая за данными о производительности, вы можете получить ценные знания и выявить возможные узкие места, а также найти дополнительные способы улучшения производительности базы данных. Такие системы часто реализуют уведомления, которые информируют администраторов, когда что-то идет не так. Собранные статистические данные могут быть использованы не только для улучшения конфигурации и рабочего процесса базы данных, но и для клиентских приложений.
Польза использования стека Elastic (ELK stack) для мониторинга вашей управляемой базы данных заключается в его отличной поддержке поиска и возможности быстрого приема новых данных. Он не отличается в обновлении данных, но этот компромисс приемлем для целей мониторинга и ведения журналов, где прошлые данные почти никогда не изменяются. Elasticsearch предлагает мощное средство запросов к данным, которое вы можете использовать через Kibana, чтобы лучше понимать, как база данных справляется с разными временными периодами. Это позволит вам коррелировать нагрузку базы данных с реальными событиями, чтобы получить представление о том, как используется база данных.
В этом руководстве вы будете импортировать метрики базы данных, созданные командой INFO Redis, в Elasticsearch через Logstash. Для этого необходимо настроить Logstash на периодическое выполнение команды, а затем отправку ее вывода в Elasticsearch для немедленного индексирования. Импортированные данные позже могут быть проанализированы и визуализированы в Kibana. К концу руководства у вас будет автоматизированная система, которая будет получать статистику Redis для последующего анализа.
Предварительные требования
- Сервер Ubuntu 18.04 с не менее чем 8 ГБ оперативной памяти, правами root и вторичной учетной записью без прав root. Вы можете настроить это, следуя этому руководству по начальной настройке сервера. В этом руководстве не-администратором является пользователь
sammy. - Java 8 установлен на вашем сервере. Для инструкций по установке посетите Как установить Java с помощью
aptна Ubuntu 18.04 и следуйте командам, описанным в первом шаге. Вам не нужно устанавливать Java Development Kit (JDK). - Nginx установлен на вашем сервере. Для руководства по этому смотрите руководство Как установить Nginx на Ubuntu 18.04.
- Elasticsearch и Kibana установлены на вашем сервере. Завершите первые два шага руководства Как установить Elasticsearch, Logstash и Kibana (Elastic Stack) на Ubuntu 18.04.
- A Redis managed database provisioned from DigitalOcean with connection information available. Make sure that your server’s IP address is on the whitelist. For a guide on creating a Redis database using the DigitalOcean Control Panel, visit the Redis Quickstart guide.
- Redli установлен на вашем сервере в соответствии с руководством Как подключиться к управляемой базе данных на Ubuntu 18.04.
Шаг 1 — Установка и настройка Logstash
В этом разделе вы установите Logstash и настроите его для сбора статистики из вашего кластера базы данных Redis, затем разберете ее для отправки в Elasticsearch для индексации.
Начните с установки Logstash с помощью следующей команды:
Как только Logstash установлен, включите службу для автоматического запуска при загрузке:
Прежде чем настраивать Logstash для сбора статистики, давайте посмотрим, как выглядят сами данные. Чтобы подключиться к вашей базе данных Redis, перейдите в ваш панель управления управляемой базой данных и в разделе Детали соединения выберите Флаги из выпадающего списка:
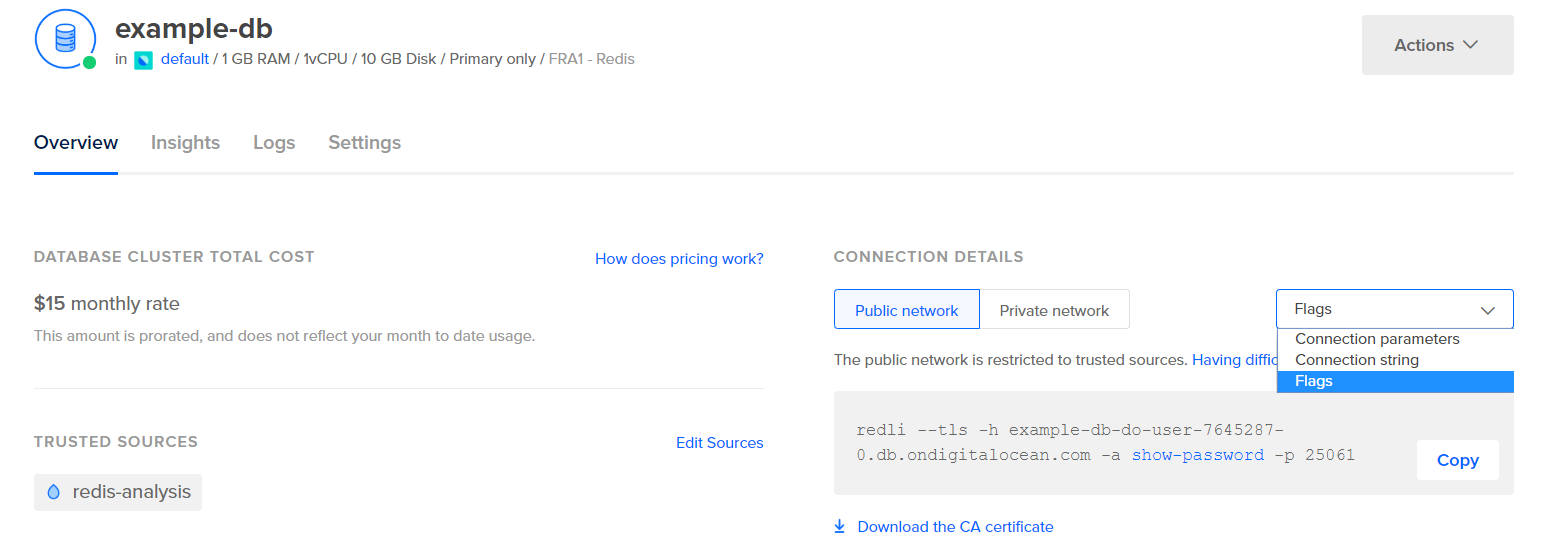
Вы увидите предварительно сконфигурированную команду для клиента Redli, которую вы будете использовать для подключения к вашей базе данных. Нажмите Копировать и выполните следующую команду на вашем сервере, заменив redli_flags_command на скопированную вами команду:
Поскольку вывод этой команды длинный, мы разберем его на части.
В выводе команды info Redis разделы помечены символом #, что означает комментарий. Значения заполняются в форме ключ:значение, что делает их относительно легкими для разбора.
Раздел Server содержит техническую информацию о сборке Redis, такую как его версия и коммит Git, на котором она основана, в то время как раздел Clients предоставляет количество в настоящее время открытых соединений.
Output# Server
redis_version:6.2.6
redis_git_sha1:4f4e829a
redis_git_dirty:1
redis_build_id:5861572cb79aebf3
redis_mode:standalone
os:Linux 5.11.12-300.fc34.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:11.2.1
process_id:79
process_supervised:systemd
run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
tcp_port:25060
server_time_usec:1640878632737564
uptime_in_seconds:1679
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:13488680
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
io_threads_active:0
# Clients
connected_clients:4
cluster_connections:0
maxclients:10032
client_recent_max_input_buffer:24
client_recent_max_output_buffer:0
...
Memory подтверждает, сколько ОЗУ выделено Redis для себя, а также максимальное количество памяти, которое он может использовать. Если он начнет исчерпывать память, он будет освобождать ключи, используя стратегию, указанную в Панели управления (показанной в поле maxmemory_policy в этом выводе).
Output...
# Memory
used_memory:977696
used_memory_human:954.78K
used_memory_rss:9977856
used_memory_rss_human:9.52M
used_memory_peak:977696
used_memory_peak_human:954.78K
used_memory_peak_perc:100.00%
used_memory_overhead:871632
used_memory_startup:810128
used_memory_dataset:106064
used_memory_dataset_perc:63.30%
allocator_allocated:947216
allocator_active:1273856
allocator_resident:3510272
total_system_memory:1017667584
total_system_memory_human:970.52M
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:455081984
maxmemory_human:434.00M
maxmemory_policy:noeviction
allocator_frag_ratio:1.34
allocator_frag_bytes:326640
allocator_rss_ratio:2.76
allocator_rss_bytes:2236416
rss_overhead_ratio:2.84
rss_overhead_bytes:6467584
mem_fragmentation_ratio:11.43
mem_fragmentation_bytes:9104832
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61504
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
...
В разделе Persistence вы можете увидеть последнее время, когда Redis сохранял ключи, которые он хранит на диске, и если это было успешно. В разделе Stats предоставляются числа, связанные с клиентскими и внутрикластерными соединениями, количество раз, когда запрошенный ключ был (или не был) найден, и так далее.
Output...
# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1640876954
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:217088
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0
# Stats
total_connections_received:202
total_commands_processed:2290
instantaneous_ops_per_sec:0
total_net_input_bytes:38034
total_net_output_bytes:1103968
instantaneous_input_kbps:0.01
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:29
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:452
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:0
dump_payload_sanitizations:0
total_reads_processed:2489
total_writes_processed:2290
io_threaded_reads_processed:0
io_threaded_writes_processed:0
...
Глядя на role в разделе Replication, вы узнаете, подключены ли вы к основному или реплицирующему узлу. Остальная часть раздела предоставляет количество в настоящее время подключенных реплик и количество данных, которых не хватает реплике по сравнению с основным. Могут быть дополнительные поля, если экземпляр, к которому вы подключены, является репликой.
Примечание: В проекте Redis в документации и в различных командах используются термины «мастер» и «слейв». DigitalOcean в целом предпочитает альтернативные термины «primary» и «replica». В данном руководстве будут использоваться термины «primary» и «replica», когда это возможно, но обратите внимание, что есть несколько случаев, когда термины «мастер» и «слейв» невозможно избежать.
Output...
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:45088768
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
...
Под CPU вы увидите количество системных (used_cpu_sys) и пользовательских (used_cpu_user) ресурсов ЦП, которые в данный момент потребляет Redis. Раздел Cluster содержит только одно уникальное поле, cluster_enabled, которое служит индикатором запущен ли кластер Redis.
Output...
# CPU
used_cpu_sys:1.617986
used_cpu_user:1.248422
used_cpu_sys_children:0.000000
used_cpu_user_children:0.001459
used_cpu_sys_main_thread:1.567638
used_cpu_user_main_thread:1.218768
# Modules
# Ошибки
# Кластер
cluster_enabled:0
# Keyspace
Logstash будет периодически запускать команду info на вашей базе данных Redis (подобно тому, как вы только что сделали), парсить результаты и отправлять их в Elasticsearch. Затем вы сможете получить к ним доступ из Kibana.
Вы будете хранить конфигурацию для индексации статистики Redis в Elasticsearch в файле с именем redis.conf в каталоге /etc/logstash/conf.d, где Logstash хранит файлы конфигурации. При запуске в качестве службы он автоматически будет выполнять их в фоновом режиме.
Создайте файл redis.conf с помощью вашего любимого редактора (например, nano):
Добавьте следующие строки:
input {
exec {
command => "redis_flags_command info"
interval => 10
type => "redis_info"
}
}
filter {
kv {
value_split => ":"
field_split => "\r\n"
remove_field => [ "command", "message" ]
}
ruby {
code =>
"
event.to_hash.keys.each { |k|
if event.get(k).to_i.to_s == event.get(k) # is integer?
event.set(k, event.get(k).to_i) # convert to integer
end
if event.get(k).to_f.to_s == event.get(k) # is float?
event.set(k, event.get(k).to_f) # convert to float
end
}
puts 'Ruby filter finished'
"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
Не забудьте заменить redis_flags_command командой, указанной в панели управления, которую вы использовали ранее на этом шаге.
Вы определяете input, который является набором фильтров, которые будут запущены на собранных данных, и output, который отправит отфильтрованные данные в Elasticsearch. Вход состоит из команды exec, которая будет выполняться на сервере периодически, после установленного времени interval (выраженного в секундах). Он также определяет параметр type, который определяет тип документа при индексации в Elasticsearch. Блок exec передает объект, содержащий два поля: command и строку message. Поле command будет содержать выполненную команду, а message – ее вывод.
Есть два фильтра, которые будут последовательно выполняться на данных, собранных из ввода. Фильтр kv означает фильтр ключ-значение и встроен в Logstash. Он используется для разбора данных в общем виде ключразделитель_значениязначение и предоставляет параметры для указания, что считается разделителями значения и поля. Разделитель поля относится к строкам, разделяющим данные, отформатированные в общем виде, друг от друга. В случае вывода команды Redis INFO разделитель поля (field_split) – это новая строка, а разделитель значения (value_split) – :. Строки, не соответствующие определенной форме, будут отброшены, включая комментарии.
Для настройки фильтра kv вы передаёте параметру value_split значение :, а параметру field_split – \r\n (обозначающий новую строку). Также вы указываете удалить поля command и message из текущего объекта данных, передав их в remove_field как элементы массива, потому что они содержат данные, которые теперь бесполезны.
Фильтр kv по умолчанию представляет разобранные значения как строковый (текстовый) тип, что вызывает проблемы, поскольку Kibana не может легко обрабатывать строковые типы, даже если на самом деле это число. Для решения этой проблемы вы будете использовать собственный Ruby-код для преобразования строк, содержащих только числа, в числа, где это возможно. Второй фильтр – это блок ruby, который предоставляет параметр code, принимающий строку, содержащую код, который нужно выполнить.
event – это переменная, которую Logstash предоставляет вашему коду, и содержит текущие данные в конвейере фильтров. Как отмечалось ранее, фильтры выполняются один за другим, что означает, что фильтр Ruby получит разобранные данные от фильтра kv. Сам Ruby-код преобразует event в хэш и проходит по ключам, затем проверяет, может ли значение, связанное с ключом, быть представлено как целое число или как число с плавающей точкой (число с десятичной частью). Если это возможно, строковое значение заменяется разобранным числом. По завершении цикла выводится сообщение (Ruby filter finished) для отчёта о выполненном прогрессе.
Выходные данные отправляются в Elasticsearch для индексации. Результирующий документ будет сохранен в индексе redis_info, определенном во входных данных и переданном как параметр в блок вывода.
Сохраните и закройте файл.
Вы установили Logstash с использованием apt и настроили его на периодический запрос статистики из Redis, обработку данных и отправку их на ваш экземпляр Elasticsearch.
Шаг 2 — Проверка конфигурации Logstash
Теперь вы проверите конфигурацию, запустив Logstash, чтобы убедиться, что он правильно извлекает данные.
Logstash поддерживает запуск определенной конфигурации, передавая путь к файлу через параметр -f. Запустите следующую команду, чтобы протестировать вашу новую конфигурацию, созданную на предыдущем шаге:
Это может занять некоторое время, чтобы увидеть результаты, но вскоре вы увидите что-то подобное следующему:
OutputUsing bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
Ruby filter finished
Ruby filter finished
Ruby filter finished
...
Вы увидите сообщение Ruby filter finished, печатающееся с регулярными интервалами (установленными на 10 секунд на предыдущем шаге), что означает, что статистика отправляется в Elasticsearch.
Вы можете выйти из Logstash, нажав CTRL + C на клавиатуре. Как упоминалось ранее, Logstash автоматически запускает все файлы конфигурации, найденные в каталоге /etc/logstash/conf.d, в фоновом режиме при запуске в качестве службы. Запустите следующую команду, чтобы запустить его:
Вы запустили Logstash, чтобы проверить, может ли он подключиться к вашему кластеру Redis и собирать данные. Затем вы исследуете некоторые статистические данные в Kibana.
Шаг 3 — Исследование импортированных данных в Kibana
В этом разделе вы исследуете и визуализируете статистические данные, описывающие производительность вашей базы данных в Kибана.
В вашем веб-браузере перейдите на свой домен, где вы открыли Kibana как часть предварительных требований. Вы увидите стандартную приветственную страницу:
Прежде чем исследовать данные, которые Logstash отправляет в Elasticsearch, вам сначала нужно добавить индекс redis_info в Kibana. Для этого сначала выберите Исследовать самостоятельно на приветственной странице, а затем откройте меню гамбургера в верхнем левом углу. Под Аналитика нажмите на Поиск.
Затем Kibana попросит вас создать новый шаблон индекса:
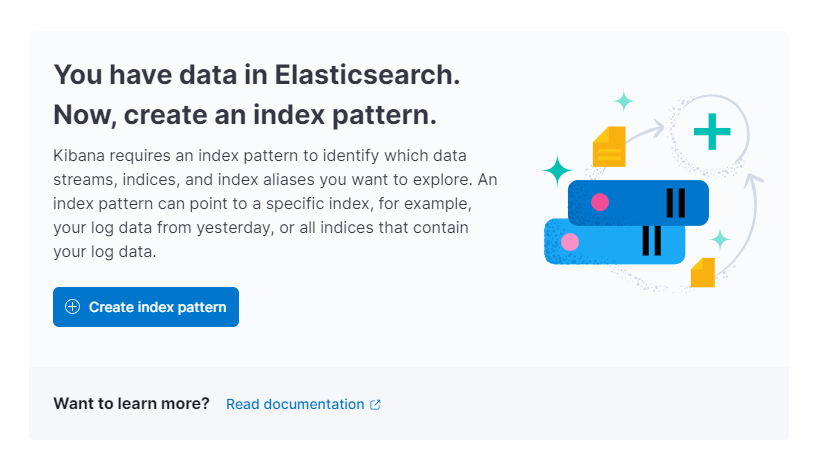
Нажмите Создать шаблон индекса. Вы увидите форму для создания нового Шаблона индекса. Шаблоны индексов в Kибана предоставляют возможность извлекать данные из нескольких индексов Elasticsearch одновременно и могут использоваться для исследования только одного индекса.

Справа в Kibana перечисляются все доступные индексы, такие как redis_info, которые вы настроили для использования Logstash. Введите это в поле текста Name и выберите @timestamp из выпадающего списка как Поле времени. Когда закончите, нажмите кнопку Создать шаблон индекса ниже.
Для создания и просмотра существующих визуализаций откройте гамбургер-меню. В разделе Аналитика выберите Панель инструментов. Когда загрузится, нажмите на Создать визуализацию, чтобы начать создание новой:
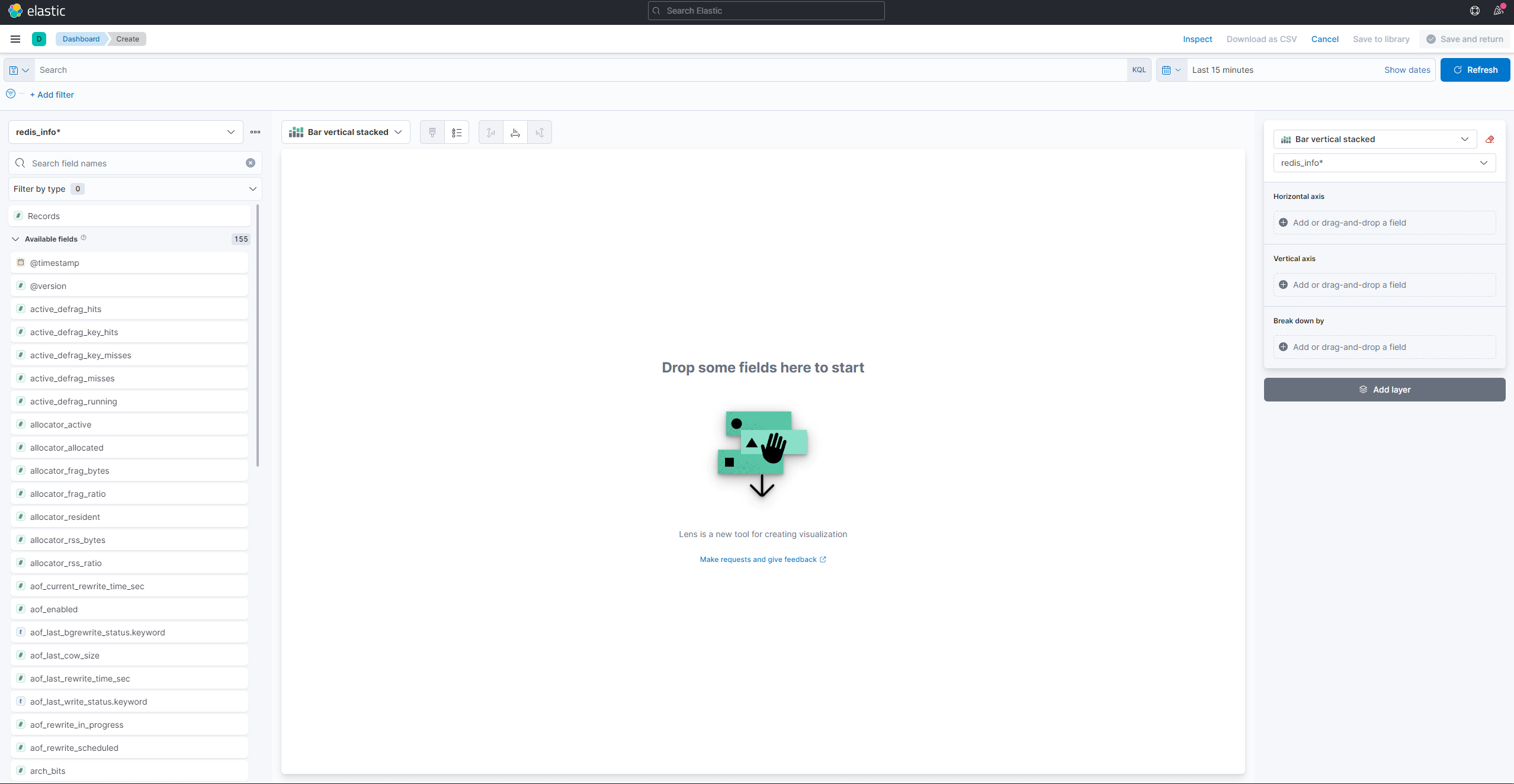
Левая панель предоставляет список значений, которые Kibana может использовать для построения визуализации, которая будет отображаться в центральной части экрана. В верхнем правом углу экрана находится средство выбора диапазона дат. Если визуализация использует поле @timestamp, Kibana будет показывать только данные, принадлежащие временному интервалу, указанному в средстве выбора диапазона.
Из выпадающего списка на главной части страницы выберите Линия в разделе Линия и область. Затем найдите поле used_memory в списке слева и перетащите его в центральную часть. Вы скоро увидите визуализацию линии медианного объема использованной памяти во времени:
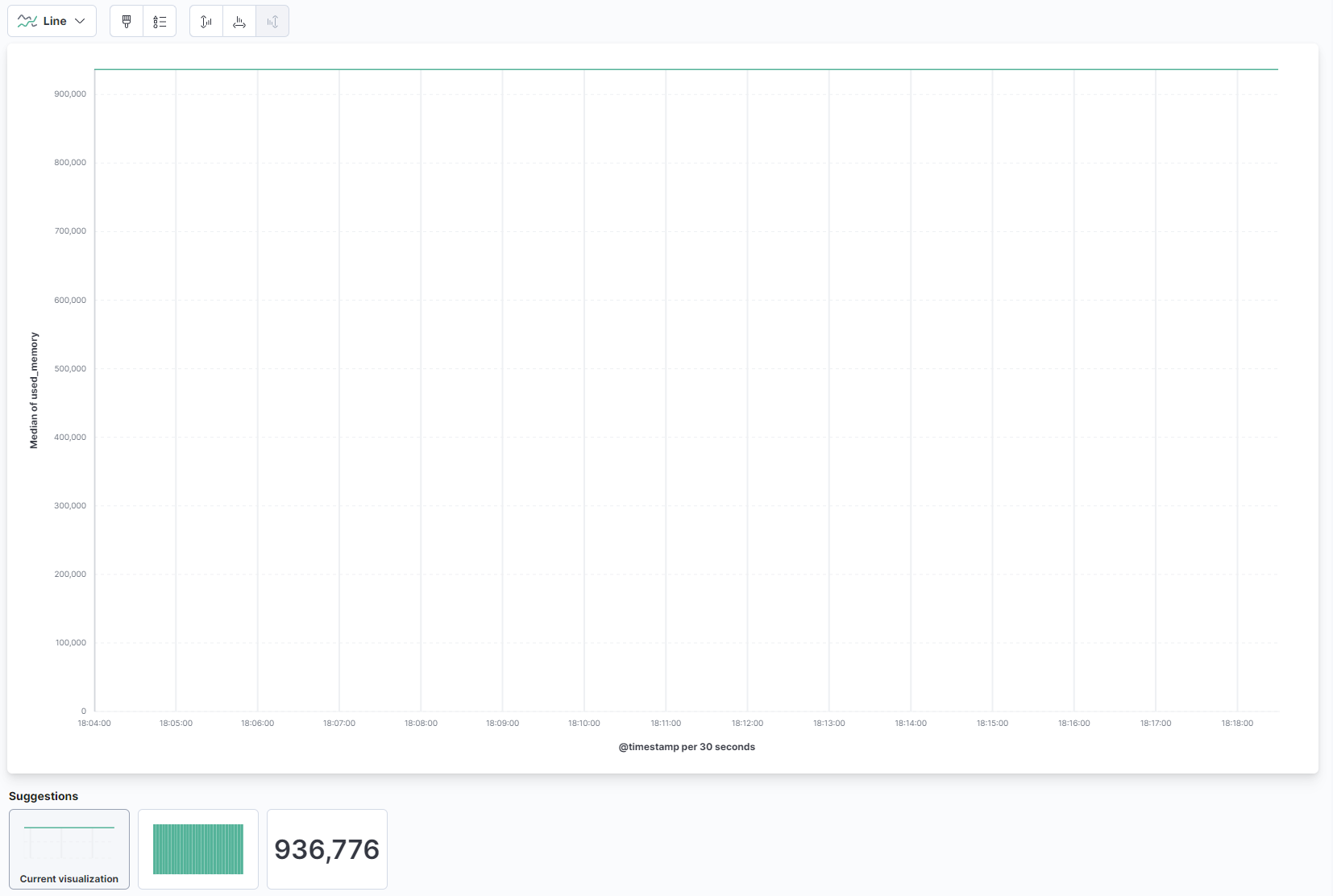
Справа вы можете настроить обработку горизонтальной и вертикальной осей. Там вы можете установить вертикальную ось для отображения средних значений вместо медианы, нажав на показанную ось:
Вы можете выбрать другую функцию или указать свою:
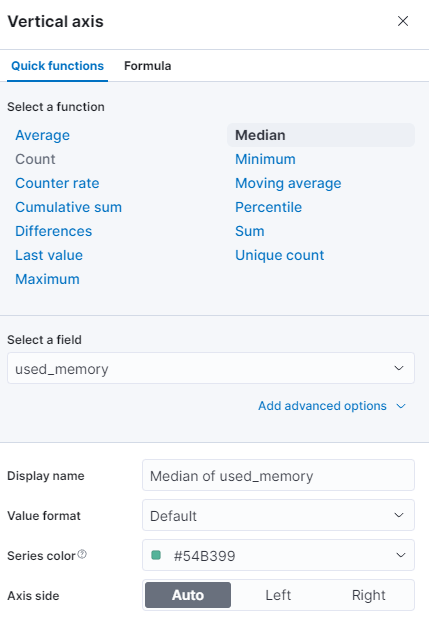
График будет немедленно обновлен с обновленными значениями.
На этом этапе вы визуализировали использование памяти вашей управляемой базы данных Redis с помощью Kibana. Это позволит вам лучше понять, как используется ваша база данных, что поможет вам оптимизировать клиентские приложения, а также саму базу данных.
Заключение
Теперь у вас установлен стек Elastic на вашем сервере и настроен для регулярного сбора статистических данных из вашей управляемой базы данных Redis. Вы можете анализировать и визуализировать данные с помощью Kibana или другого подходящего программного обеспечения, что поможет вам получить ценные инсайты и реальные корреляции о том, как ваша база данных работает.
Для получения дополнительной информации о том, что вы можете сделать с вашей управляемой базой данных Redis, посетите документацию по продукту. Если вы хотите представить статистику базы данных с использованием другого типа визуализации, ознакомьтесь с документацией Kibana для получения дополнительных инструкций.