













Наступление Apache Hadoop Distributed File System (HDFS) революционизировало хранение, обработку и анализ данных для предприятий, ускоряя рост больших данных и приводя к трансформационным изменениям в отрасли.
Первоначально Hadoop интегрировал хранилище и вычисления, но появление облачных вычислений привело к разделению этих компонентов. Объектное хранилище возникло как альтернатива HDFS, но имело ограничения. Для дополнения этих ограничений, JuiceFS, открытый исходный код, высокопроизводительная распределенная файловая система, предлагает экономически эффективные решения для данных, интенсивных сценариев, таких как вычисление, анализ и обучение. Решение о принятии разделения хранилища-вычислений зависит от таких факторов, как масштабируемость, производительность, стоимость и совместимость.
В этой статье мы рассмотрим архитектуру Hadoop, обсудим важность и осуществимость разделения хранилища-вычислений и исследуем доступные рыночные решения, выделяя их соответствующие преимущества и недостатки. Наша цель – предоставить информацию и вдохновение для предприятий, проходящих через архитектурную трансформацию разделения хранилища-вычислений.
Архитектурные особенности дизайна Hadoop
Hadoop как универсальная рамка
В 2006 году Hadoop был выпущен как универсальная рамка, состоящая из трех компонентов:
- MapReduce для вычислений
- YARN для планирования ресурсов
- HDFS для распределенного файлового хранилища
 Core components of Hadoop
Core components of HadoopРазнообразные компоненты вычислений
Среди этих трех компонентов, слой вычислений быстро развивался. Изначально существовал только MapReduce, но вскоре отрасль стала свидетелем появления различных фреймворков, таких как Tez и Spark для вычислений, Hive для складирования данных, и движков запросов, таких как Presto и Impala. В сочетании с этими компонентами существует множество инструментов передачи данных, таких как Sqoop.

HDFS Преобладал в Системе Хранения
За примерно десять лет, HDFS, распределенная файловая система, оставалась доминирующей системой хранения. Это был выбор по умолчанию для почти всех компонентов вычислений. Все перечисленные выше компоненты в экосистеме больших данных были разработаны для API HDFS. Некоторые компоненты глубоко используют специфические возможности HDFS. Например:
- HBase использует низкозатратные возможности записи HDFS для своих журналов предзаписи.
- MapReduce и Spark предоставляли функции локальности данных.
Выбор дизайнов этих компонентов больших данных, основанный на API HDFS, создавал потенциальные проблемы для развертывания платформ данных в облаке.
Архитектура Связанного Хранения и Вычислений
На следующей диаграмме показана часть упрощенной архитектуры HDFS, которая сочетает вычисления с хранением.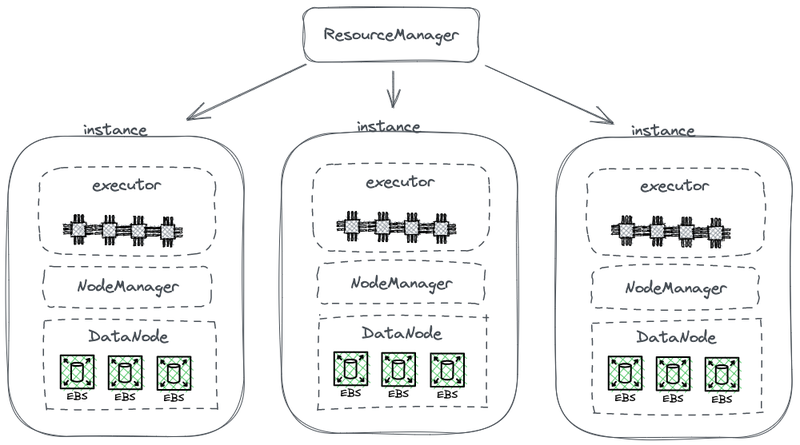
Архитектура Hadoop с объединенным хранением и вычислениями
На этой диаграмме каждый узел выступает в роли HDFS DataNode для хранения данных. Кроме того, YARN развертывает процесс Node Manager на каждом узле. Это позволяет YARN распознать узел как часть управляемых ресурсов для вычислительных задач. Такая архитектура позволяет хранить и вычислять на одном и том же устройстве, и данные могут быть считаны с диска во время вычислений.
Почему Hadoop объединяет хранение и вычисления
Хардоу объединяет хранение и вычисления из-за ограничений сетевого взаимодействия и оборудования на стадии его проектирования.
В 2006 году облачные вычисления находились на начальной стадии развития, и Amazon только выпустила свою первую услугу. В дата-центрах преобладали сетевые карты, работающие на скорости 100 Мбит/с. Диски данных, используемые для работы с большими данными, достигали пропускной способности около 50 МБ/с, что эквивалентно 400 Мбит/с в терминах сетевой пропускной способности.
Рассматривая узел с восемью дисками, работающими на максимальной мощности, для эффективной передачи данных требовалось несколько гигабит в секунду сетевой пропускной способности. К сожалению, максимальная пропускная способность сетевых карт была ограничена 1 Гбит/с. В результате пропускная способность сети на узле была недостаточной для полного использования возможностей всех дисков в узле. В итоге, если вычислительные задачи находились на одном конце сети, а данные находились на узлах данных на другом конце, пропускная способность сети являлась значительным узким местом.
Почему Разъединение Хранилища и Вычислений Необходимо
С 2006 по примерно 2016 год предприятия сталкивались с следующими проблемами:
- Спрос на вычислительную мощность и хранилище в приложениях был несбалансирован, и их темпы роста различались. В то время как объем данных предприятия рос стремительно, потребность в вычислительной мощности не росла так быстро. Эти задачи, разработанные людьми, не умножались экспоненциально в короткий период времени. Однако данные, генерируемые в результате этих задач, накапливались быстро, возможно, экспоненциально. Кроме того, некоторая информация может не быть немедленно полезной для предприятия, но она будет ценна в будущем. Поэтому предприятия тщательно хранят данные для исследования их потенциальной ценности.
- При масштабировании предприятиям приходилось расширять как вычислительные, так и хранилищные ресурсы одновременно, что часто приводило к неэффективному использованию вычислительных мощностей. Жёсткая связь между вычислительными и хранилищными ресурсами в архитектуре аппаратного обеспечения влияла на масштабируемость. Когда потребность в хранилище возрастала, требовалось не только добавлять новые машины, но и обновлять процессоры и память, так как узлы данных в связанной архитектуре отвечали за вычисления. Поэтому машины обычно оснащались хорошо сбалансированным сочетанием вычислительной мощности и хранилища, обеспечивая достаточное хранилище вкупе с сопоставимыми вычислительными возможностями. Однако фактическая потребность в вычислительных ресурсах не росла так быстро, как ожидалось. В результате расширение вычислительных мощностей приводило к значительным потерям для предприятий.
- Сбалансировать вычислительные и хранилищные ресурсы и выбрать подходящие машины стало сложной задачей. Использование ресурсов всего кластера в плане хранилища и ввода/вывода могло быть крайне несбалансированным, и эта дисбаланс усиливался с ростом кластера. Кроме того, приобретение подходящих машин было затруднено, поскольку они должны были сочетать в себе баланс между вычислительными и хранилищными требованиями.
- Поскольку данные могли распределяться неравномерно, было сложно эффективно планировать вычислительные задачи на экземплярах, где находились данные. Стратегия планирования локальности данных может неэффективно справиться с реальными сценариями из-за возможности неравномерного распределения данных. Например, некоторые узлы могут стать локальными горячими точками, требующими больше вычислительных мощностей. В результате, даже если задачи на платформе больших данных планировались на этих узлах-горячих точках, производительность ввода/вывода могла стать ограничивающим фактором.
Почему разъединение хранения и вычислений является осуществимым
Осуществимость разделения хранения и вычислений стала возможной благодаря прогрессу в аппаратном и программном обеспечении между 2006 и 2016 годами. Эти прогрессы включают:
Сетевые карты
Принятие сетевых карт на 10 Гбит широко распространилось, с увеличивающейся доступностью более высоких емкостей, таких как 20 Гбит, 40 Гбит и даже 50 Гбит в центрах обработки данных и облачных средах. В сценариях AI также используются сетевые карты с емкостью 100 ГБ. Это представляет собой значительное увеличение пропускной способности сети более чем в 100 раз.
Диски
Многие предприятия по-прежнему полагаются на решения на основе дисков для хранения в больших кластерах данных. Пропускная способность дисков удвоилась, увеличившись с 50 МБ/с до 100 МБ/с. Экземпляр, оборудованный сетевой картой на 10 Гбит, может поддерживать пиковую пропускную способность около 12 дисков. Этого достаточно для большинства предприятий, и поэтому сетевая передача больше не является узким местом.
Программное обеспечение
Использование эффективных алгоритмов сжатия, таких как Snappy, LZ4 и Zstandard, и столбцовых форматов хранения, таких как Avro, Parquet и Orc, еще больше снизило давление на ввод-вывод. Узкое место в обработке больших данных сместилось от ввода-вывода к производительности CPU.
Как реализовать разделение хранения и вычислений
Первоначальная попытка: независимое развертывание HDFS в облаке
Независимое развертывание HDFS
С 2013 года в отрасли предпринимались попытки разделить хранилище и вычисления. Первоначальный подход довольно прост, заключается в независимом развертывании HDFS без интеграции с вычислительными рабочими узлами. Это решение не вводило никаких новых компонентов в экосистему Hadoop.
Как показано на диаграмме ниже, NodeManager больше не развертывался на DataNodes. Это означало, что вычислительные задачи больше не отправлялись на DataNodes. Хранение стало отдельным кластером, и данные, необходимые для вычислений, передавались по сети, поддерживаемые карты сетевых адаптеров end-to-end 10 Гбит/с. (Обратите внимание, что линии сетевой передачи данных на диаграмме не отмечены.)

Хотя это решение отказалось от локальности данных, самого изобретательного дизайна HDFS, ускоренная скорость сетевого взаимодействия значительно облегчила конфигурацию кластера. Это было продемонстрировано в экспериментах, проведенных Дэвисом, сооснователем Juicedata, и его коллегами во время работы в Facebook в 2013 году. Результаты подтвердили возможность независимого развертывания и управления вычислительными узлами.
Однако этот подход не получил дальнейшего развития. Основная причина – сложности с развертыванием HDFS в облаке.
Сложности с развертыванием HDFS в облаке
Развертывание HDFS в облаке сталкивается со следующими проблемами:
- Механизм мультирепликации HDFS может увеличить расходы предприятий на облаке: В прошлом предприятия использовали обычные диски для построения системы HDFS в своих дата-центрах. Чтобы снизить риск повреждения дисков, HDFS реализовал механизм мультирепликации для обеспечения безопасности и доступности данных. Однако при переносе данных в облако, поставщики облачных услуг предлагают облачные диски, которые уже защищены механизмом мультирепликации. В результате предприятиям необходимо трижды реплицировать данные в облаке, что приводит к значительному увеличению затрат.
- Ограниченный выбор развертывания на обычных дисках: Хотя поставщики облачных услуг предлагают некоторые типы машин с обычными дисками, доступные варианты ограничены. Например, из 100 типов виртуальных машин, доступных в облаке, только 5-10 типов машин поддерживают обычные диски. Этот ограниченный выбор может не удовлетворять специфическим требованиям кластеров предприятий.
- Невозможность использования уникальных преимуществ облака: Развертывание HDFS в облаке требует ручной создания машин, развертывания, обслуживания, мониторинга и операций без удобства эластичного масштабирования и модели оплаты по мере использования. Это ключевые преимущества облачных вычислений. Поэтому развертывание HDFS в облаке при достижении разделения хранения и вычислений непросто.
Ограничения HDFS
У HDFS есть следующие ограничения:
- NameNodes имеют ограниченную масштабируемость: NameNodes в HDFS могут масштабироваться только вертикально и не могут масштабироваться распределенно. Это ограничение накладывает ограничение на количество файлов, которые могут быть управляемы в рамках одного кластера HDFS.
- Хранение более 500 миллионов файлов влечет за собой высокие операционные затраты: На основе нашего опыта, обычно легко управлять и обслуживать HDFS с количеством файлов менее 300 миллионов. Когда количество файлов превышает 500 миллионов, необходимо реализовать механизм HDFS Federation. Однако это приводит к высоким операционным и управленческим затратам.
- Высокое использование ресурсов и большая нагрузка на NameNode влияют на доступность кластера HDFS: Когда NameNode потребляет слишком много ресурсов с высокой нагрузкой, может быть вызван полный сборщик мусора (GC). Это влияет на доступность всего кластера HDFS. Хранение системы может испытывать простои, что делает невозможным чтение данных, и нет возможности вмешаться в процесс GC. Продолжительность заморозки системы не может быть определена. Это была постоянная проблема в кластерах HDFS с высокой нагрузкой.
Общественный облачный сервис + Объектное хранилище
С развитием облачных вычислений, предприятия теперь могут использовать объектное хранилище в качестве альтернативы HDFS. Объектное хранилище специально разработано для хранения больших объемов неструктурированных данных, предлагая архитектуру для легкого загрузки и скачивания данных. Оно обеспечивает высоко масштабируемый объем хранения, гарантируя экономическую эффективность.
Преимущества использования объектного хранилища в качестве замены HDFS
Объектное хранилище приобрело популярность, начиная с AWS и затем было принято другими поставщиками облачных услуг в качестве замены HDFS. Следующие преимущества заслуживают внимания:
- Сервисное ориентирование и готовность к использованию: Объектное хранилище не требует развертывания, мониторинга или задач обслуживания, обеспечивая удобный и дружелюбный опыт пользователя.
- Эластичное масштабирование и оплата по факту использования: предприятия оплачивают хранение объектов в зависимости от их фактического использования, что исключает необходимость планирования емкости. Они могут создать бакет для хранения объектов и хранить столько данных, сколько необходимо, не беспокоясь о ограничениях по емкости хранения.
Недостатки хранения объектов
Однако при использовании хранения объектов для поддержки сложных систем данных, таких как Hadoop, возникают следующие проблемы:
Недостаток #1: Низкая производительность списка файлов
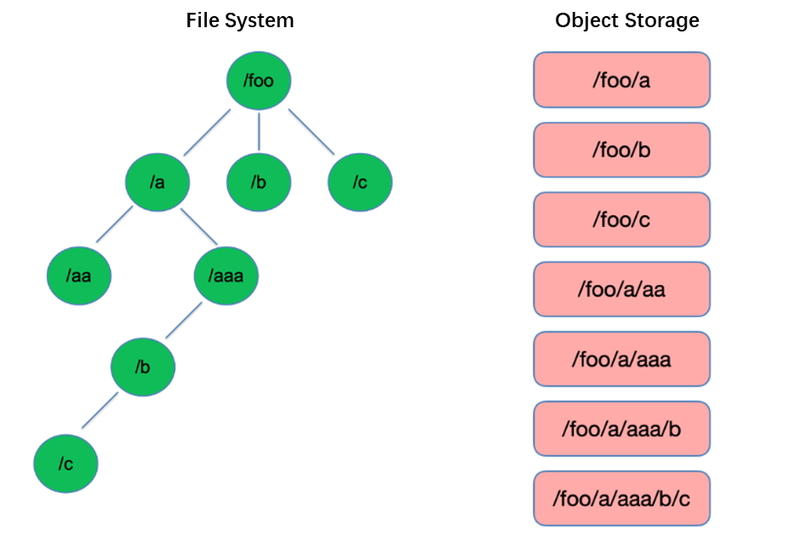
Составление списка является одной из самых базовых операций в файловой системе. Она легковесна и быстра в древовидных структурах, таких как HDFS.
Напротив, хранилище объектов использует плоскую структуру и требует индексирования с ключами (уникальными идентификаторами) для хранения и извлечения тысяч или даже миллиардов объектов. В результате, при выполнении операции List, хранилище объектов может только искать в этом индексе, что приводит к значительно худшей производительности по сравнению с древовидными структурами.
Недостаток #2: Отсутствие атомарной возможности переименования, влияющей на производительность и стабильность задачи
В моделях вычислений извлечения, преобразования, загрузки (ETL) каждый подзадача записывает свои результаты в временную директорию. Когда вся задача завершена, временную директорию можно переименовать в конечное имя директории.
Эти операции переименования являются атомарными и быстрыми в файловых системах, таких как HDFS, и гарантируют транзакции. Однако, поскольку объектное хранилище не имеет встроенной иерархии каталогов, обработка операции переименования представляет собой симулированный процесс, который включает значительное количество внутреннего копирования данных. Этот процесс может быть длительным и не обеспечивает гарантий транзакционности.
Когда пользователи используют объектное хранилище, они обычно используют формат пути из традиционных файловых систем в качестве ключа для объектов, например, “/order/2-22/8/10/detail”. Во время операции переименования необходимо искать все объекты, ключи которых содержат имя каталога, и копировать все объекты, используя новое имя каталога в качестве ключа. Этот процесс включает копирование данных, что приводит к значительно более низкой производительности по сравнению с файловыми системами, возможно, на один или два порядка медленнее.
Кроме того, из-за отсутствия гарантий транзакций существует риск сбоя в процессе, что может привести к неправильным данным. Эти, казалось бы, незначительные различия имеют последствия для производительности и стабильности всего конвейера задач.
Недостаток №3: Механизм последней консистентности влияет на корректность данных и стабильность задач
Например, когда несколько клиентов одновременно создают файлы под одним путем, список файлов, полученный через API List, может не сразу включать все созданные файлы. Требуется время для того, чтобы внутренние системы объектного хранилища достигли консистентности данных. Такой способ доступа часто используется в процессе ETL обработки данных, и последняя консистентность может повлиять на корректность данных и стабильность задач.
Для решения проблемы неспособности хранилища объектов поддерживать сильную согласованность данных, AWS выпустила продукт под названием EMRFS. Его подход заключается в использовании дополнительной базы данных DynamoDB. Например, когда Spark записывает файл, он также одновременно записывает копию списка файлов в DynamoDB. Затем устанавливается механизм непрерывного вызова API List хранилища объектов и сравнения полученных результатов с сохраненными результатами в базе данных до тех пор, пока они не совпадут, после чего результаты возвращаются. Однако стабильность этого механизма недостаточно хороша, так как она может быть подвержена влиянию нагрузки на регион, где находится хранилище объектов, что приводит к непостоянной производительности. Таким образом, это не идеальное решение.
Недостаток #4: Ограниченная совместимость с компонентами Hadoop
HDFS был основным выбором хранения на ранних этапах экосистемы Hadoop, и различные компоненты были разработаны на основе API HDFS. Введение хранилища объектов привело к изменениям в структуре хранения данных и API.
Поставщики облачных услуг должны модифицировать соединители между компонентами и облачным хранилищем объектов, а также исправлять верхние компоненты для обеспечения совместимости. Эта задача налагает значительную нагрузку на поставщиков публичных облачных услуг.
В результате количество поддерживаемых вычислительных компонентов в платформах больших данных, предлагаемых поставщиками публичных облачных услуг, ограничено, обычно включая только несколько версий Spark, Hive и Presto. Это ограничение создает проблемы для переноса платформ больших данных в облако или для пользователей с конкретными требованиями к своему распределению и компонентам.
Для использования мощной производительности объектного хранилища при сохранении надежности файловых систем, предприятия могут применять объектное хранилище + JuiceFS.
Объектное Хранилище + JuiceFS
Когда пользователи хотят выполнять сложные вычисления, анализ и обучение данных на объектном хранилище, одно объектное хранилище может не в полной мере удовлетворять требованиям предприятий. Это ключевая мотивация разработки Juicedata JuiceFS, цель которой – дополнить ограничения объектного хранилища.
JuiceFS – это открытая, высокопроизводительная распределенная файловая система, предназначенная для облака. Вместе с объектным хранилищем, JuiceFS предоставляет экономичные решения для данных, требующих интенсивного использованиясценариевтаких как вычисления, анализ и обучение.
Как работает JuiceFS + Объектное Хранилище
Ниже представлена схема развертывания JuiceFS в кластере Hadoop.
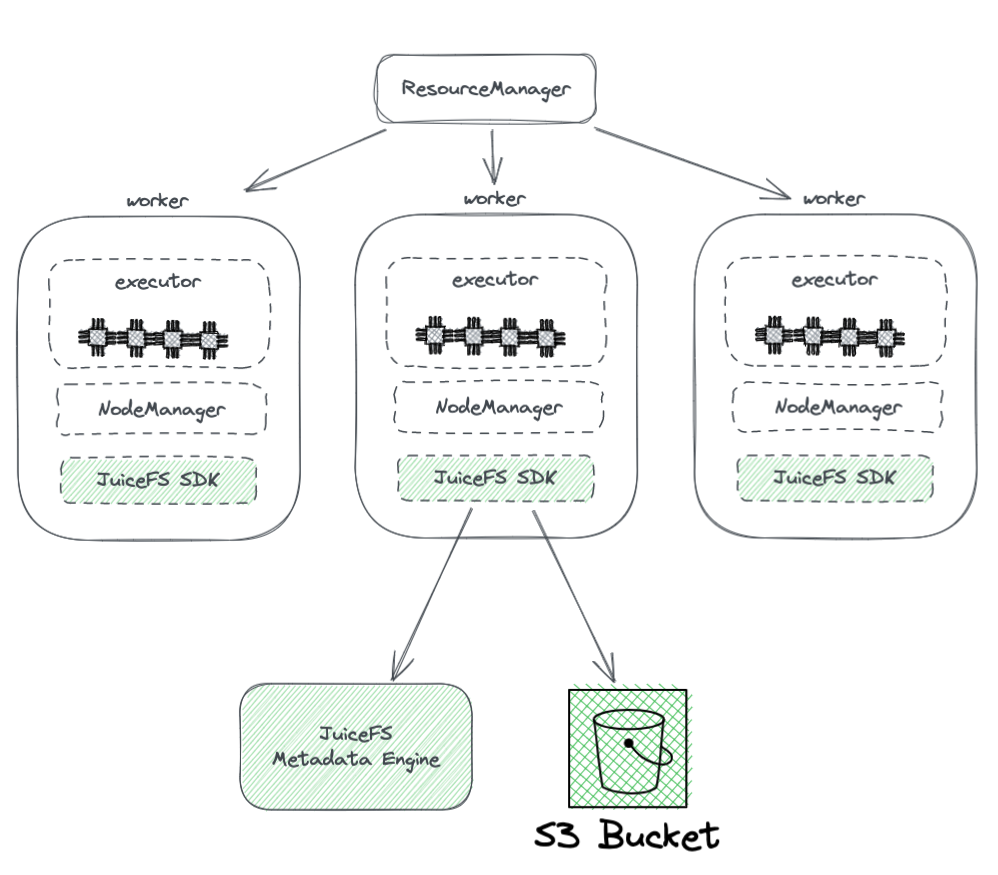
Из схемы мы можем увидеть следующее:
- Все рабочие узлы, управляемые YARN, оснащены SDK JuiceFS для Hadoop, что обеспечивает полную совместимость с HDFS.
- SDK обращается к двум компонентам:
-
Метаданные JuiceFS Engine: Метаданные движок служит аналогом NameNode в HDFS. Он хранит метаинформацию всей файловой системы, включая количество каталогов, имена файлов, разрешения и временные отметки, а также решает проблемы масштабируемости и GC, с которыми сталкивается NameNode в HDFS.
-
Контейнер S3 Bucket: Данные хранятся в контейнере S3 Bucket, который можно рассматривать аналогично DataNode в HDFS. Он может использоваться как большое количество дисков, управляя задачами хранения данных и их репликации.
-
-
JuiceFS состоит из трех компонентов:
- JuiceFS Hadoop SDK
- Metadata Engine
- S3 Bucket
Преимущества Juicefs перед прямым использованием объектного хранилища
JuiceFS предлагает несколько преимуществ по сравнению с прямым использованием объектного хранилища:
- Полная совместимость с HDFS: Это достигается за счет изначального дизайна JuiceFS, полностью поддерживающего POSIX. POSIX API имеет большую покрываемость и сложность, чем HDFS.
- Возможность использования с существующим HDFS и объектным хранилищем: Благодаря дизайну системы Hadoop, JuiceFS может использоваться вместе с существующими системами HDFS и объектного хранилища без необходимости полного замещения. В кластере Hadoop можно настроить несколько файловых систем, что позволяет JuiceFS и HDFS сосуществовать и взаимодействовать. Эта архитектура устраняет необходимость полного замещения существующих кластеров HDFS, что потребовало бы значительных усилий и рисков. Пользователи могут постепенно интегрировать JuiceFS на основе своих потребностей приложений и ситуации в кластере.
- Мощная производительность метаданных: JuiceFS отделяет движок метаданных от S3 и больше не зависит от производительности метаданных S3. Это обеспечивает оптимальную производительность метаданных. При использовании JuiceFS взаимодействия с базовым объектным хранилищем сводятся к основным операциям, таким как Get, Put и Delete. Эта архитектура преодолевает ограничения производительности метаданных объектного хранилища и устраняет проблемы, связанные с eventual consistency.
- Поддержка атомарного переименования: JuiceFS поддерживает атомарные операции переименования благодаря своей независимой системе метаданных. Кэш улучшает производительность доступа к горячим данным и предоставляет функцию локальности данных: с кэшем горячие данные больше не нужно извлекать из объектного хранилища через сеть каждый раз. Более того, JuiceFS реализует специфический API локальности данных для HDFS, что позволяет всем компонентам верхнего уровня, поддерживающим локальность данных, восстановить чувствительность к аффинности данных. Это позволяет YARN отдавать приоритет планированию задач на узлах, где был установлен кэш, что приводит к общей производительности, сравнимой с HDFS с объединенными хранилищем и вычислениями.
- JuiceFS совместим с POSIX, что упрощает интеграцию с приложениями машинного обучения и AI.
Заключение
С развитием требований предприятий и прогрессом технологий архитектура хранения и вычислений претерпела изменения, перейдя от объединения к разделению.
Существует множество подходов к достижению разделения хранения и вычислений, каждый из которых имеет свои преимущества и недостатки. Это варьируется от развертывания HDFS в облаке до использования решений от публичных облачных провайдеров, совместимых с Hadoop, и даже до применения решений вроде объектного хранилища + JuiceFS, подходящих для сложных вычислений и хранения больших данных в облаке.
Для предприятий нет универсального средства, и ключ к успеху заключается в выборе архитектуры, основанном на их конкретных потребностях. Однако независимо от выбора, простота всегда является безопасным вариантом.
О авторе
Rui Su, партнер в Juicedata, с 2017 года является одним из основателей, участвующих в полном развитии продукта JuiceFS, рынка и открытого сообщества. С 16-летним опытом работы в отрасли, он занимал должности в области R&D, менеджера по продукту и основателя в сфере программного обеспечения, интернет-бизнеса и неправительственных организаций.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora