













Что такое Elasticsearch?
Elasticsearch — это распределённый движок поиска и аналитики с открытым исходным кодом, построенный на базе библиотеки Apache Lucene. Elasticsearch также предлагает векторный поиск и генерацию с дополненной извлечением (RAG), что позволяет бесшовно поддерживать современные приложения ИИ. Приложения могут хранить структурированные и неструктурированные данные в Elasticsearch, с определённой схемой или без неё, отправляя JSON полезные нагрузки в кластер Elasticsearch.
Архитектура Elasticsearch
С нуля основные компоненты кластера Elasticsearch включают в себя:
Документ
Документ — это самая маленькая запись информации, хранящаяся в Elasticsearch, и представлена в формате JSON. Документ состоит из нескольких полей (пар ключ-значение) различных типов и может иметь предопределённую схему или быть без схемы, выводя типы данных для любых новых полей, которые индексируются.
Индекс
Индекс — это логическая коллекция документов с одинаковой схемой, идентифицируемая по имени индекса.
Шард
Индексы Elasticsearch разбиваются на управляемые единицы, называемые шардом, которые представляют собой коллекцию документов. Шарды являются основной единицей поиска и дублируются на нескольких узлах для обеспечения избыточности и устойчивости к сбоям.
Узел
Узел — это независимый экземпляр Elasticsearch, который управляет коллекцией шардов, принадлежащих одному или нескольким индексам. Узлы могут иметь различные роли, такие как узел данных, мастер-узел и узел обработки данных.
Кластер
Кластер Elasticsearch — это коллекция взаимосвязанных узлов. Все узлы в кластере могут обрабатывать запросы от клиентов и взаимодействовать друг с другом. Каждый узел в кластере владеет подмножеством шардов, принадлежащих индексу.
Архитектура запросов
Следующая архитектурная диаграмма описывает поток поискового запроса:

- Пользователь или приложение формирует поисковый запрос. Запрос может быть обработан любым узлом в кластере. Узел, который обрабатывает запрос, является «координирующим» узлом.
- Координирующий узел рассылает запрос всем участвующим шартам и их репликам.
- Каждый шард выполняет запрос локально и возвращает легкий набор результатов координирующему узлу.
- Координирующий узел объединяет полученные результаты. Это конец фазы «запроса». Фаза запроса определяет основные документы, которые формируют результат поиска, но полный документ все еще нужно извлечь.
- Координирующий узел отправляет запросы на извлечение к принадлежащим шартам, которые обогащают документы в наборе результатов.
- Обогащенные документы возвращаются координирующему узлу.
- Полный набор результатов поиска, отсортированный и обогащенный, возвращается вызывающему.
Архитектура индексации
На следующей диаграмме архитектуры показана последовательность выполнения запроса на индексацию:
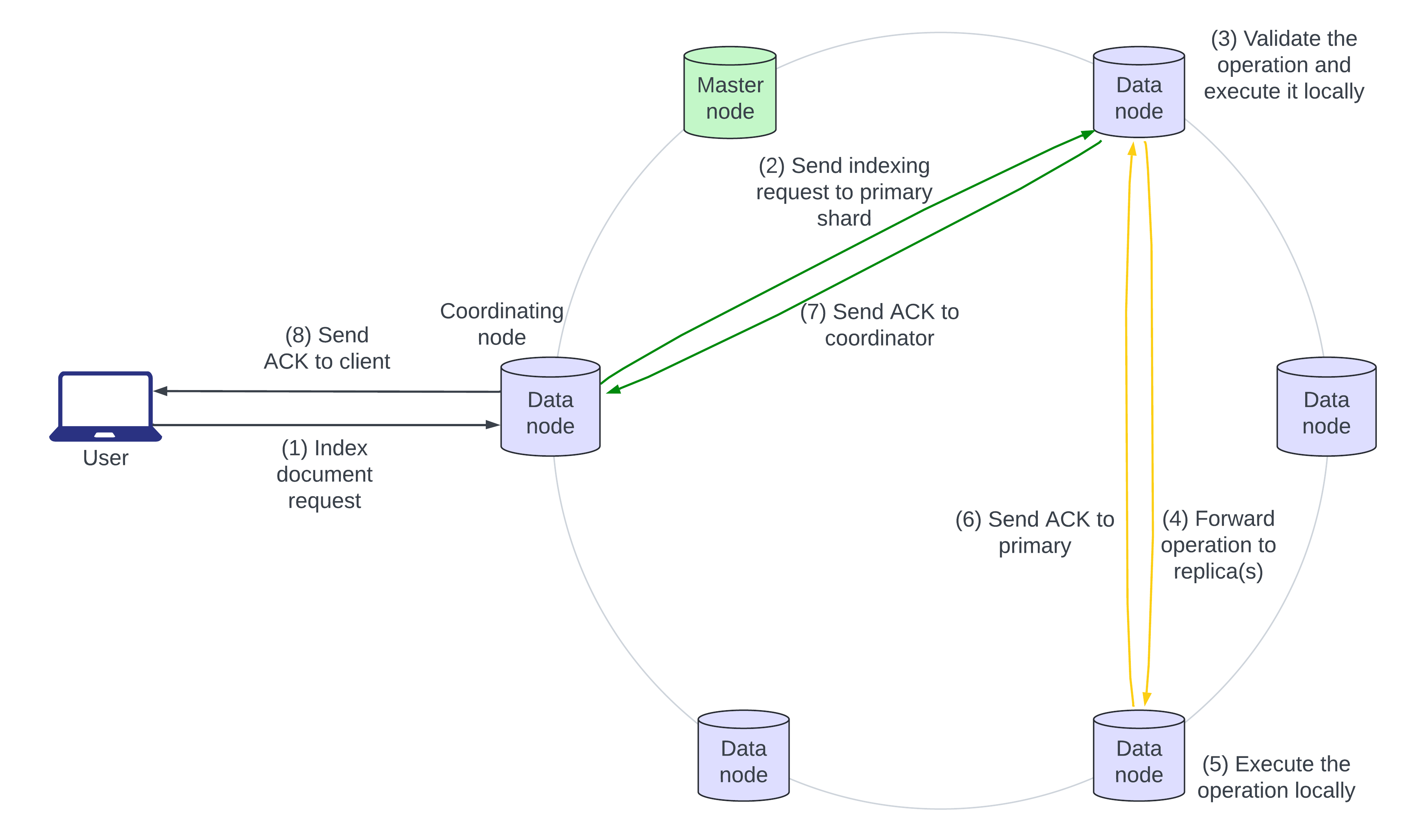
- Пользователь отправляет JSON-документ для индексации в Elasticsearch. Если документ уже существует, добавляются новые поля, а существующие поля перезаписываются. Узел, который первым получает запрос, является “координирующим” узлом.
- Координирующий узел определяет первичный шар входящего документа, обычно на основе идентификатора документа, и передает запрос узлу данных, которому принадлежит первичный шар.
- Первичный шар проверяет операцию и выполняет ее локально.
- Затем первичный шар передает операцию всем своим репликам параллельно.
- Реплики шаров применяют операцию локально на своих узлах.
- Шаги 6, 7 и 8 показывают подтверждение записи, перемещающееся от реплики шара к первичному шару, к координирующему узлу и к вызывающему.
Заключение
В этой статье описаны различные компоненты кластера Elasticsearch: документы, индексы, шары и узлы. Также рассматривается жизненный цикл запроса на поиск и запроса на индексацию. Его гибкая архитектура облегчает добавление и удаление узлов при масштабировании кластера. Совместно с функциями, такими как индексация без схемы и поддержка функций поиска по искусственному интеллекту, это делает Elasticsearch де-факто стандартом для организаций, которым требуется эффективное хранение, поиск и анализ больших объемов данных в реальном времени.
Source:
https://dzone.com/articles/elasticsearch-query-and-indexing-architecture