













Репликация базы данных – это процесс разделения данных на меньшие части, называемые “фрагментами”. Фрагментация обычно вводится, когда возникает необходимость масштабировать записи. В течение жизненного цикла успешного приложения сервер базы данных достигнет максимального количества записей, которые он может выполнить либо на уровне обработки, либо на уровне емкости. Разрезание данных на несколько фрагментов – каждый на своем сервере базы данных – снижает нагрузку на каждый отдельный узел, что эффективно увеличивает емкость записи в целом. Вот что такое репликация базы данных.
Распределенный SQL – это новый способ масштабирования реляционных баз данных с похожей на фрагментацию стратегией, которая полностью автоматизирована и прозрачна для приложений. Распределенные базы данных SQL разработаны с нуля для масштабирования почти линейно. В этой статье вы узнаете основы распределенного SQL и как начать.
Недостатки Репликации Базы Данных
Фрагментация вводит ряд проблем:
- Разделение данных: Решение о том, как разделить данные между несколькими фрагментами, может быть сложной задачей, поскольку требуется найти баланс между близостью данных и равномерным распределением данных для избежания горячих точек.
- Обработка сбоев: Если ключевой узел выходит из строя, и нет достаточного количества фрагментов для переноса нагрузки, как переместить данные на новый узел без простоев?
- Сложность запросов: Код приложения связан с логикой разделения данных, и запросы, требующие данных с нескольких узлов, должны быть повторно объединены.
- Согласованность данных: Обеспечение согласованности данных на нескольких фрагментах может быть сложной задачей, поскольку требует координации обновлений данных на разных фрагментах. Это может быть особенно трудным, когда обновления происходят одновременно, так как может потребоваться разрешение конфликтов между различными записями.
- Эластичная масштабируемость: При увеличении объема данных или количества запросов может потребоваться добавление дополнительных фрагментов в базу данных. Это может быть сложным процессом с неизбежным простоями, требующим ручных процессов для равномерного перемещения данных по всем фрагментам.
Некоторые из этих недостатков могут быть смягчены принятием полиглотного устойчивого состояния (использование различных баз данных для различных рабочих нагрузок), баз данных с встроенными возможностями фрагментирования или прокси-серверами баз данных. Однако, хотя эти инструменты помогают с некоторыми из вызовов базы данных, они имеют ограничения и вводят сложность, которая требует постоянного управления.
Что такое Распределенный SQL?
Распределенный SQL относится к новому поколению реляционных баз данных. Простыми словами, распределенная SQL-база данных — это реляционная база данных с прозрачным шардированием, которая для приложений выглядит как единый логический объект базы данных. Распределенные SQL-базы данных реализованы в виде архитектуры без общих ресурсов и движка хранения, который масштабирует как чтения, так и записи, сохраняя при этом истинную соблюдение ACID и высокую доступность. Распределенные SQL-базы данных обладают масштабируемостью NoSQL-баз данных, которые обрели популярность в 2000-х годах, но не жертвуют согласованностью. Они сохраняют преимущества реляционных баз данных и добавляют совместимость с облаком, обладая устойчивостью к отказам в нескольких регионах.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
Как работает распределенный SQL?
Для понимания того, как работает Distributed SQL, рассмотрим пример с MariaDB Xpand — распределенной SQL базой данных, совместимой с открытым исходным MariaDB базой данных. Xpand функционирует путем разделения данных и индексов между узлами и автоматически выполняет такие задачи, как перебалансировка данных и распределенное выполнение запросов. Запросы выполняются параллельно для минимизации задержек. Данные автоматически реплицируются, чтобы обеспечить отсутствие единого узла отказа. При выходе из строя узла Xpand перераспределяет данные среди оставшихся узлов. То же самое происходит при добавлении нового узла. Компонент под названием ребалансер обеспечивает отсутствие горячих точек — проблемы с ручной фрагментацией базы данных, которая возникает, когда один узел неравномерно должен обрабатывать слишком много транзакций по сравнению с другими узлами, которые иногда могут оставаться бездействующими.
Давайте рассмотрим пример. Предположим, у нас есть экземпляр базы данных с таблицей some_table и определенным количеством строк:
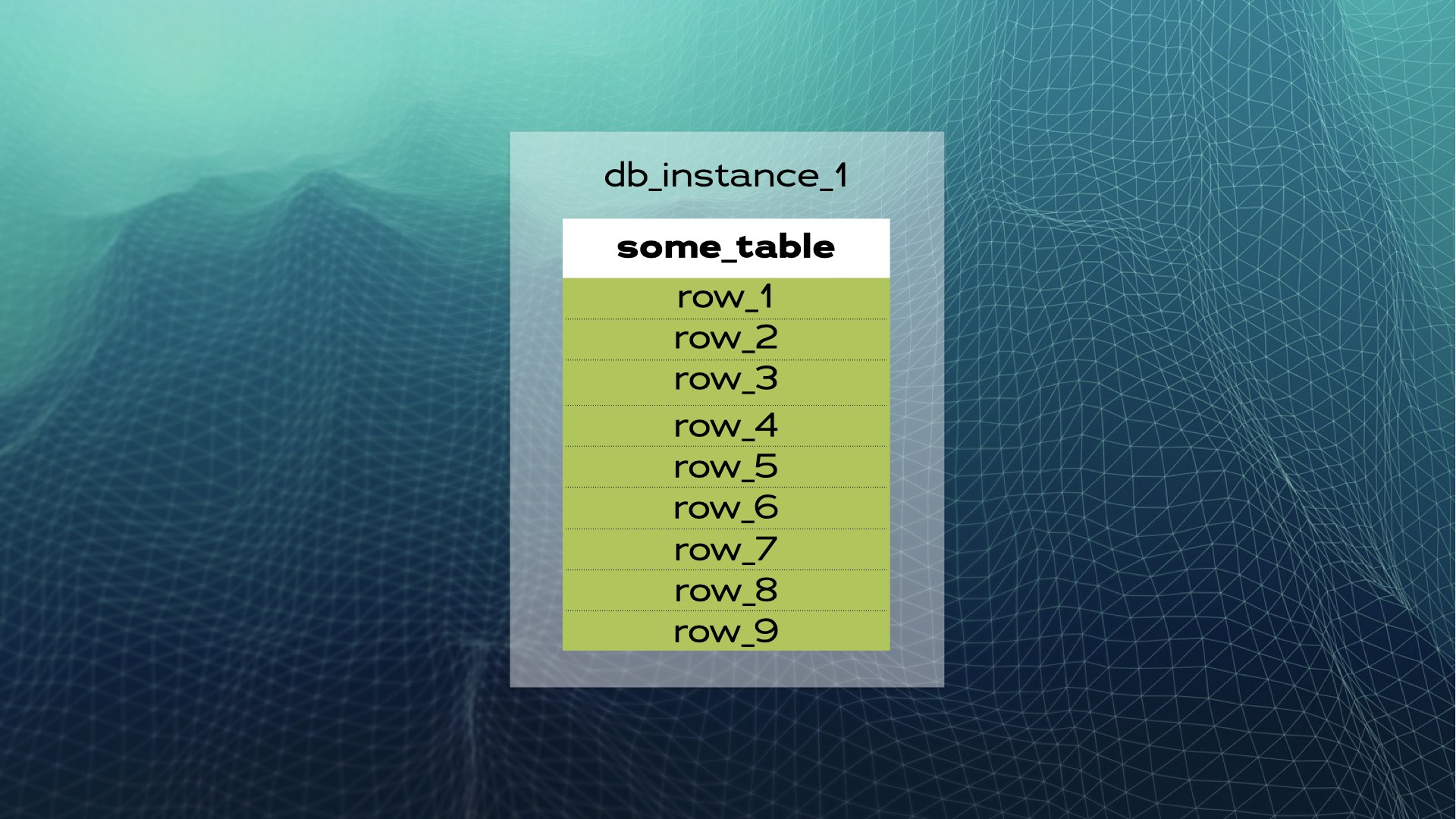
Мы можем разделить данные на три части (фрагмента):

Затем каждую часть данных можно переместить в отдельный экземпляр базы данных:
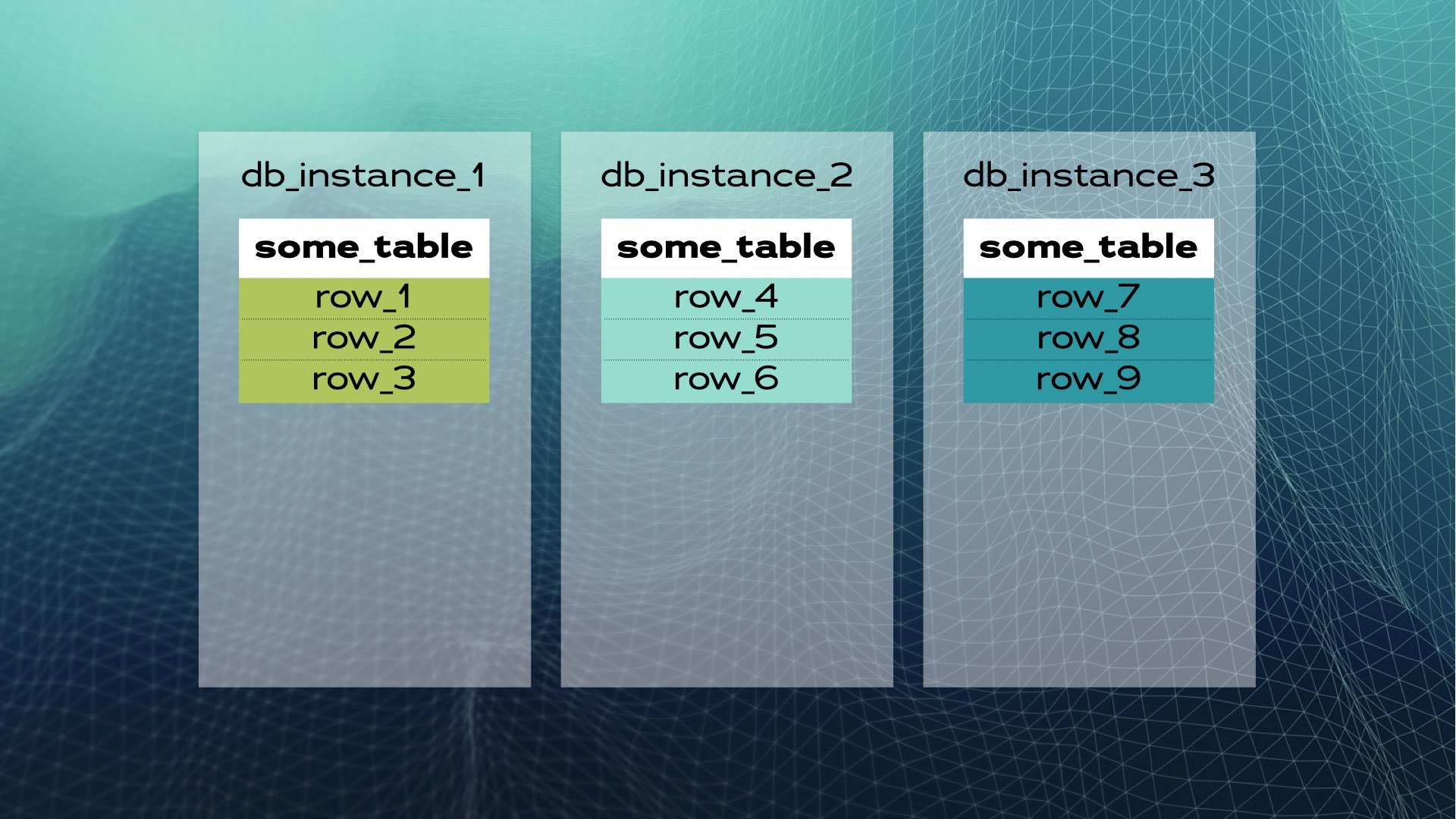
Вот как выглядит ручное разделение базы данных. Распределенный SQL делает это автоматически для вас. В случае Xpand каждый фрагмент называется slice. Строки фрагментируются с использованием хеша подмножества столбцов таблицы. Не только данные фрагментируются, но и индексы также разделяются и распределяются среди узлов (экземпляров базы данных). Более того, для обеспечения высокой доступности, фрагменты реплицируются на других узлах (количество реплик на узел настраивается). Это также происходит автоматически:
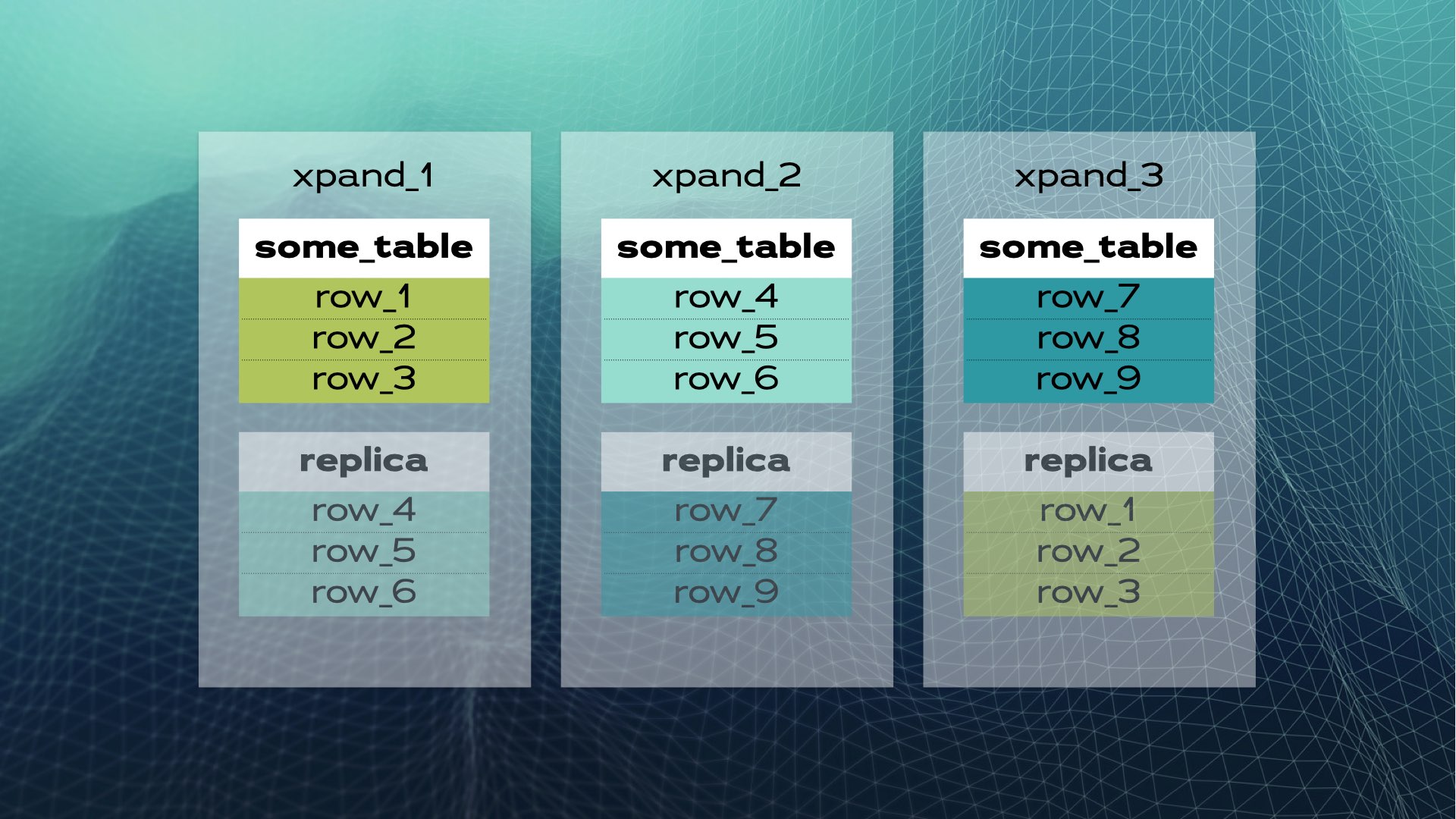
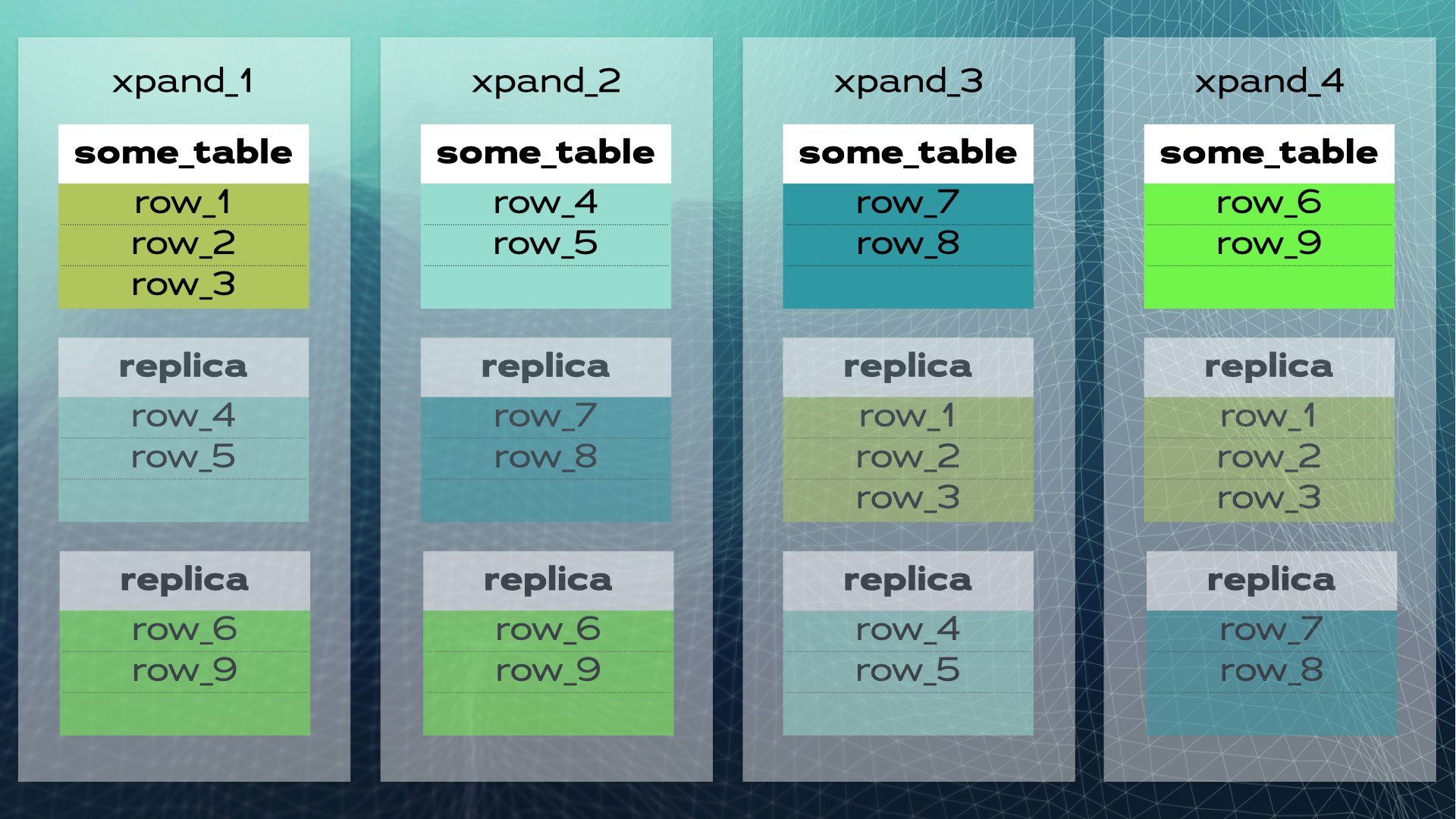
Когда новый узел добавляется в кластер или когда один из узлов выходит из строя, Xpand автоматически перераспределяет данные без необходимости ручной интервенции. Вот что происходит, когда к предыдущему кластеру добавляется узел:

Некоторые строки перемещаются на новый узел для увеличения общей системной емкости. Имейте в виду, что, хотя на диаграмме это не показано, индексы, а также реплики также перемещаются и обновляются соответствующим образом. Чуть более полная картина (с немного другой переменой данных) предыдущего кластера показана на этой диаграмме:
Такое архитектурное решение позволяет достичь практически линейной масштабируемости. Нет необходимости в ручном вмешательстве на уровне приложения. Для приложения кластер выглядит как единый логический сервер базы данных. Приложение просто подключается к базе данных через балансировщик нагрузки (MariaDB MaxScale):
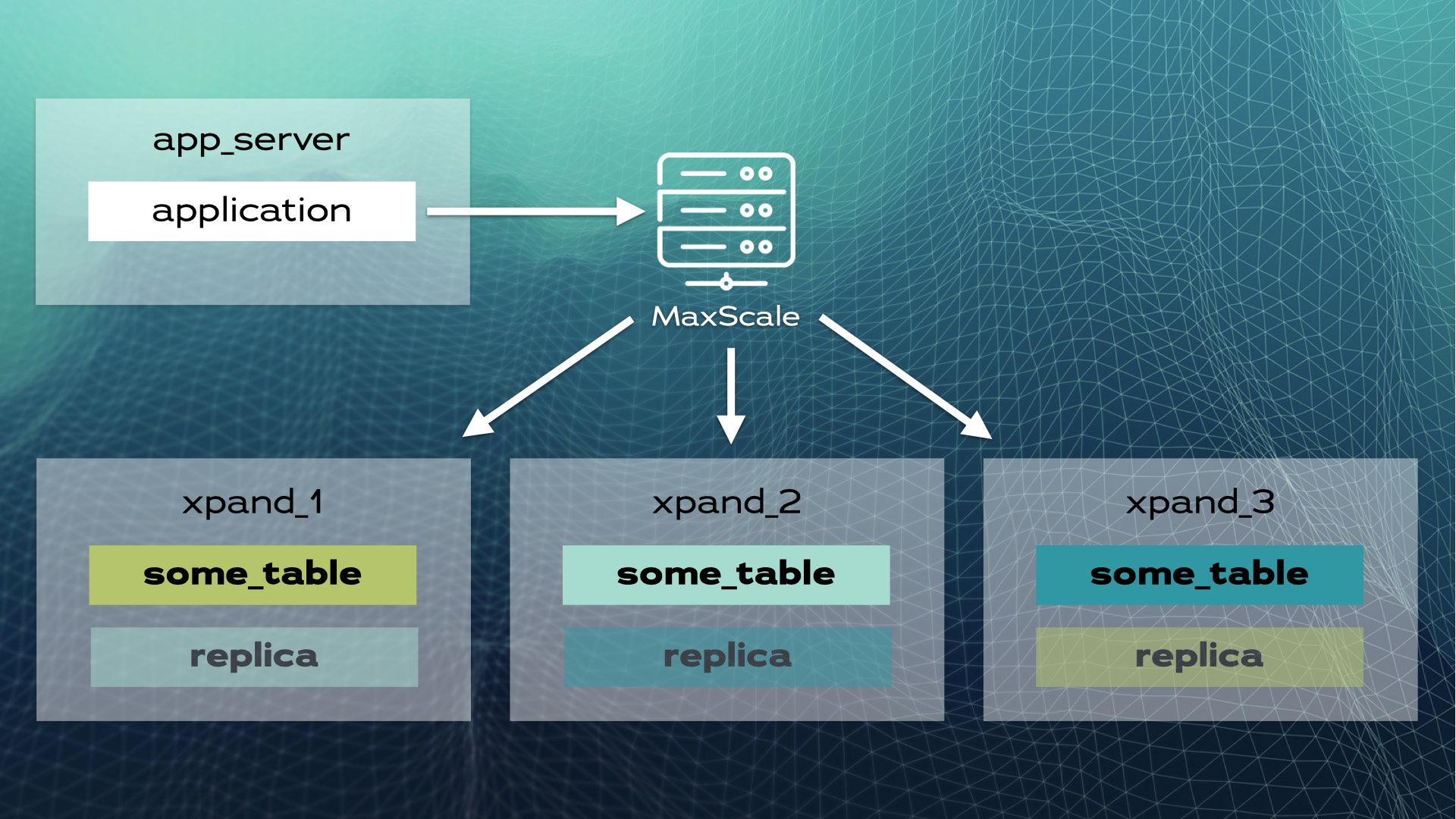
Когда приложение отправляет операцию записи (например, INSERT или UPDATE), вычисляется хеш и отправляется на корректный фрагмент. Несколько записей отправляются параллельно на несколько узлов.
Когда не стоит использовать распределенный SQL
Шардирование базы данных улучшает производительность, но также вводит дополнительные накладные расходы на уровне коммуникации между узлами. Это может привести к снижению производительности, если база данных не настроена правильно или если маршрутизатор запросов не оптимизирован. Распределенный SQL может не быть лучшим вариантом для приложений с менее чем 10 тысячами запросов в секунду или 5 тысячами транзакций в секунду. Также, если ваша база данных состоит в основном из множества маленьких таблиц, то монолитная база данных может работать лучше.
Начало работы с распределенным SQL
Поскольку распределенная SQL-база данных выглядит для приложения как одна логическая база данных, начало работы простая задача. Вам нужно следующее:
- Клиент SQL, такой как DBeaver, DbGate, DataGrip или любое расширение клиента SQL для вашей IDE
- A distributed SQL database
Docker упрощает вторую часть. Например, MariaDB публикует образ Docker mariadb/xpand-single, который позволяет запустить одноузловую базу данных Xpand для оценки, тестирования и разработки.
Чтобы запустить контейнер Xpand, выполните следующую команду:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Смотрите документацию по образам Docker для подробностей.
Примечание: На момент написания этой статьи образ Docker mariadb/xpand-single недоступен для архитектур ARM. На таких архитектурах (например, на машинах Apple с процессорами M1) используйте UTM для создания виртуальной машины (VM) и установки, например, Debian. Присвойте хостнейм и используйте SSH для подключения к VM для установки Docker и создания контейнера MariaDB Xpand.
Подключение к Базе Данных
Подключение к базе данных Xpand аналогично подключению к серверу MariaDB Community или Enterprise. Если у вас установлен инструмент командной строки mariadb, просто выполните следующее:
mariadb -h 127.0.0.1 -u user -pВы можете подключиться к базе данных с помощью GUI для SQL баз данных, таких как DBeaver, DataGrip, или расширения SQL для вашего IDE (например, это для VS Code). Мы будем использовать бесплатный и открытый клиент SQL под названием DbGate. Вы можете скачать DbGate и запустить его как настольное приложение, или, поскольку вы используете Docker, вы можете развернуть его как веб-приложение, которое вы можете получить из любой точки через веб-браузер (аналогично популярному phpMyAdmin). Просто запустите следующую команду:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateКак только контейнер запустится, откройте в браузере http://localhost:3000/. Заполните детали подключения:
Нажмите на Тест и убедитесь, что подключение успешно:

Нажмите на Сохранить и создайте новую базу данных, щелкнув правой кнопкой мыши по подключению в левой панели и выбрав Создать базу данных. Попробуйте создать таблицы или импортировать SQL скрипт. Если вы просто хотите попробовать что-то, Nation или Sakila – хорошие примеры баз данных.
Подключение из Java, JavaScript, Python и C++
Для подключения к Xpand из приложений вы можете использовать MariaDB Connectors. Существует множество возможных комбинаций языков программирования и фреймворков для сохранения данных. Описание этого выходит за рамки данной статьи, но если вы хотите просто начать и увидеть что-то в действии, ознакомьтесь с этой страницей быстрого старта с примерами кода для Java, JavaScript, Python и C++.
Настоящая мощь распределенного SQL
В этой статье мы узнали, как запустить одноузловой Xpand для разработки и тестирования, а не для рабочих нагрузок. Однако настоящая мощь распределенной SQL-базы данных заключается в ее способности масштабировать не только чтение (как в классическом фрагментировании базы данных), но и запись, просто добавляя больше узлов и позволяя ребалансеру оптимально перемещать данные. Хотя возможно развертывание Xpand в многоузловой топологии, самый простой способ использовать его в производстве — через SkySQL.
Если вы хотите узнать больше о распределенном SQL и MariaDB Xpand, вот список полезных ресурсов:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding