













В этой практической лаборатории от ScyllaDB University вы научитесь использовать ScyllaDB CDC source connector для отправки событий изменений на уровне строк в таблицах кластера ScyllaDB на сервер Kafka.
Что такое ScyllaDB CDC?
Подводя итог, Change Data Capture (CDC) — это функция, которая позволяет не только запрашивать текущее состояние таблицы базы данных, но и запрашивать историю всех изменений, внесенных в таблицу. CDC является готовым к производству (GA) начиная с ScyllaDB Enterprise 2021.1.1 и ScyllaDB Open Source 4.3.
В ScyllaDB CDC является необязательным и включается на уровне каждой таблицы. История изменений в таблице с включенным CDC хранится в отдельной ассоциированной таблице.
Вы можете включить CDC при создании или изменении таблицы, используя опцию CDC, например:
CREATE TABLE ks.t (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};ScyllaDB CDC Source Connector
ScyllaDB CDC Source Connector — это исходный коннектор, который отслеживает изменения на уровне строк в таблицах кластера ScyllaDB. Это коннектор Debezium, совместимый с Kafka Connect (с Kafka 2.6.0+). Коннектор считывает журнал CDC для указанных таблиц и создает сообщения Kafka для каждой операции на уровне строк INSERT, UPDATE или DELETE. Коннектор обладает устойчивостью к сбоям, повторяя чтение данных из Scylla в случае неудачи. Он периодически сохраняет текущую позицию в журнале CDC ScyllaDB, используя отслеживание смещений Kafka Connect. Каждое сгенерированное сообщение Kafka содержит информацию о источнике, такую как временная метка и имя таблицы.
Примечание: на момент написания, поддержка типов коллекций (LIST, SET, MAP) и UDTs — столбцов с такими типами — пропущены в сгенерированных сообщениях. Будьте в курсе данного запроса на улучшение и других разработок в проекте на GitHub.
Confluent и Kafka Connect
Confluent представляет собой полнофункциональную платформу для потоковой передачи данных, которая позволяет легко получать, хранить и управлять данными в виде непрерывных, реально-временных потоков. Она расширяет преимущества Apache Kafka за счет функций для предприятий. Confluent упрощает создание современных, управляемых событиями приложений и обеспечивает универсальный конвейер данных, поддерживающий масштабируемость, производительность и надежность.
Kafka Connect — это инструмент для масштабируемой и надежной потоковой передачи данных между Apache Kafka и другими системами данных. Он упрощает определение соединителей, которые перемещают большие объемы данных в и из Kafka. Может поглощать целые базы данных или собирать метрики с серверов приложений в темы Kafka, делая данные доступными для потоковой обработки с низкой задержкой.
Kafka Connect включает два типа соединителей:
- Источник соединителя: Источники соединителей поглощают целые базы данных и передают обновления таблиц в темы Kafka. Источники соединителей также могут собирать метрики с серверов приложений и хранить данные в темах Kafka, делая их доступными для потоковой обработки с низкой задержкой.
- Соединитель-приемник: Соединители-приемники передают данные из тем Kafka в вторичные индексы, такие как Elasticsearch, или в пакетные системы, такие как Hadoop, для офлайн-анализа.
Настройка сервиса с Docker
В этой лаборатории вы будете использовать Docker.
Убедитесь, что ваша среда соответствует следующим предварительным требованиям:
- Docker для Linux, Mac или Windows.
- Примечание: запуск ScyllaDB в Docker рекомендуется только для оценки и тестирования ScyllaDB.
- ScyllaDB с открытым исходным кодом. Для лучшей производительности рекомендуется обычная установка.
- Не менее 8 ГБ ОЗУ для сервисов Kafka и ScyllaDB.
- docker-compose
- Git
Установка и инициация таблицы ScyllaDB
Сначала запустите кластер ScyllaDB из трех узлов и создайте таблицу с поддержкой CDC.
Если вы еще этого не сделали, загрузите пример из git:
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/CDC_Kafka_LabЭто файл docker-compose, который вы будете использовать. Он запускает кластер ScyllaDB из трех узлов:
version: "3"
services:
scylla-node1:
container_name: scylla-node1
image: scylladb/scylla:5.0.0
ports:
- 9042:9042
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node2:
container_name: scylla-node2
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node3:
container_name: scylla-node3
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0Запустите кластер ScyllaDB:
docker-compose -f docker-compose-scylladb.yml up -dПодождите минуту или около того и проверьте, что кластер ScyllaDB запущен и находится в нормальном состоянии:
docker exec scylla-node1 nodetool statusДалее вы будете использовать cqlsh для взаимодействия с ScyllaDB. Создайте пространство ключей, таблицу с поддержкой CDC и вставьте строку в таблицу:
docker exec -ti scylla-node1 cqlsh
CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
exit[guy@fedora cdc_test]$ docker-compose -f docker-compose-scylladb.yml up -d
Creating scylla-node1 ... done
Creating scylla-node2 ... done
Creating scylla-node3 ... done
[guy@fedora cdc_test]$ docker exec scylla-node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Адрес Загрузка Токены Владеет ID хоста Ребро
UN 172.19.0.3 ? 256 ? 4d4eaad4-62a4-485b-9a05-61432516a737 rack1
UN 172.19.0.2 496 KB 256 ? bec834b5-b0de-4d55-b13d-a8aa6800f0b9 rack1
UN 172.19.0.4 ? 256 ? 2788324e-548a-49e2-8337-976897c61238 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
[guy@fedora cdc_test]$ docker exec -ti scylla-node1 cqlsh
Connected to at 172.19.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
cqlsh> CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
cqlsh> INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
cqlsh> exit
[guy@fedora cdc_test]$ Настройка Confluent и конфигурация соединителя
Для запуска сервера Kafka вы будете использовать платформу Confluent, которая предоставляет удобный веб-интерфейс для отслеживания топиков и сообщений. Платформа Confluent предоставляет файл docker-compose.yml для настройки сервисов.
Примечание: это не то, как вы бы использовали Apache Kafka в производстве. Пример полезен только для обучения и разработки. Получите файл:
wget -O docker-compose-confluent.yml https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.3.0-post/cp-all-in-one/docker-compose.ymlДалее загрузите соединитель ScyllaDB CDC:
wget -O scylla-cdc-plugin.jar https://github.com/scylladb/scylla-cdc-source-connector/releases/download/scylla-cdc-source-connector-1.0.1/scylla-cdc-source-connector-1.0.1-jar-with-dependencies.jarДобавьте соединитель CDC ScyllaDB в директорию плагинов сервиса Confluent connect, используя Docker volume, редактируя файл docker-compose-confluent.yml, добавив две строки, как показано ниже, заменив директорию на директорию вашего файла scylla-cdc-plugin.jar.
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
+ volumes:
+ - <directory>/scylla-cdc-plugin.jar:/usr/share/java/kafka/plugins/scylla-cdc-plugin.jar
depends_on:
- broker
- schema-registryЗапустите службы Confluent:
docker-compose -f docker-compose-confluent.yml up -dПодождите минуту или около того, затем перейдите по ссылке http://localhost:9021 для доступа к веб-интерфейсу Confluent.
Добавьте соединитель ScyllaConnector через панель управления Confluent:
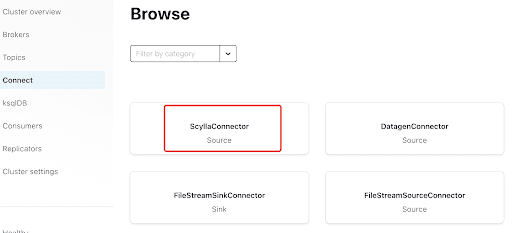
Добавьте соединитель Scylla, нажав на плагин:
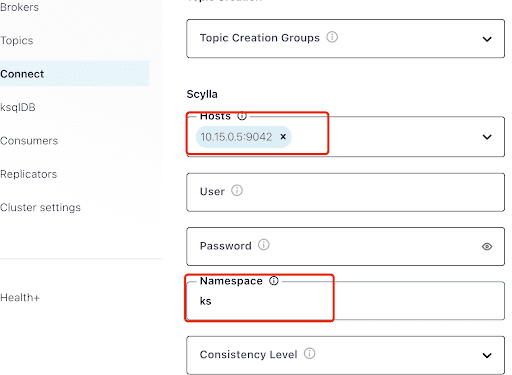
Заполните поле “Хосты” IP-адресом одного из узлов Scylla (вы можете увидеть его в выводе команды nodetool status) и порт 9042, который прослушивает служба ScyllaDB.
Поле “Пространство имен” – это ключевое пространство, которое вы создали ранее в ScyllaDB.
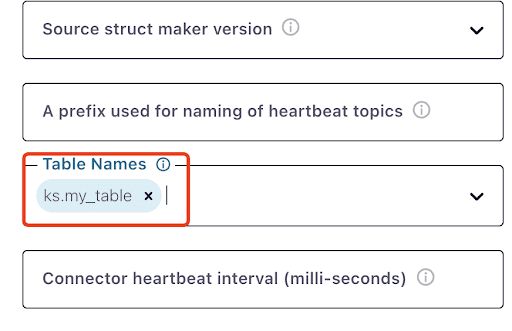
Обратите внимание, что может пройти минута или около того, прежде чем ks.my_table появится:
Проверьте сообщения Kafka
Вы можете видеть, что MyScyllaCluster.ks.my_table – это топик, созданный соединителем CDC ScyllaDB.
Теперь проверьте сообщения Kafka из панели “Топики”:
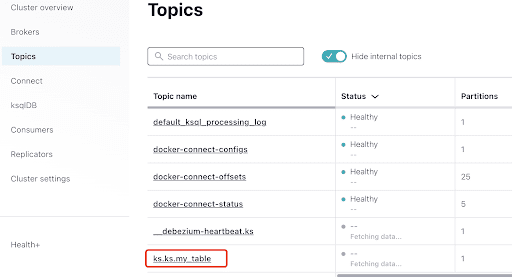
Выберите топик, который соответствует ключевому пространству и имени таблицы, которую вы создали в ScyllaDB:
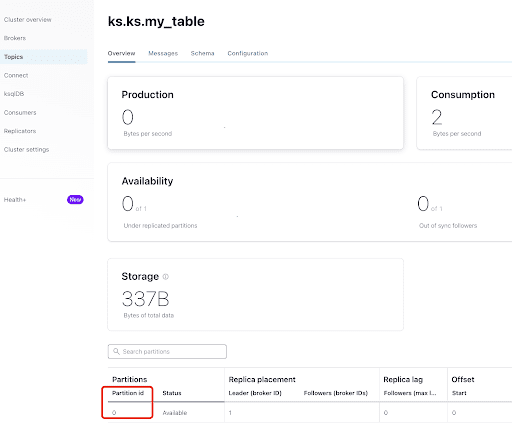
На вкладке “Обзор” вы можете увидеть информацию о топике. Внизу отображается, что этот топик находится на разделе 0.
A partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion. The records in the partitions are each assigned a sequential identifier called the offset, which is unique for each record within the partition. The offset is an incremental and immutable number maintained by Kafka.
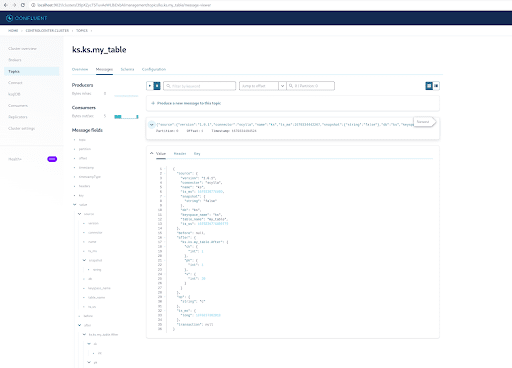
Как вы уже знаете, сообщения CDC ScyllaDB отправляются в топик ks.my_table, а идентификатор раздела топика равен 0. Далее перейдите на вкладку “Сообщения” и введите идентификатор раздела 0 в поле “смещение“:
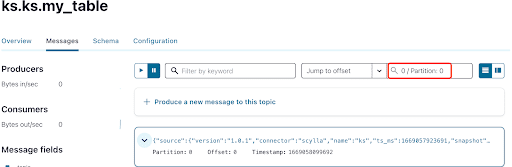
Из вывода сообщений топика Kafka видно, что событие INSERT таблицы ScyllaDB и данные были переданы в сообщения Kafka с помощью источника соединителя Scylla CDC. Нажмите на сообщение, чтобы просмотреть полную информацию о нем:
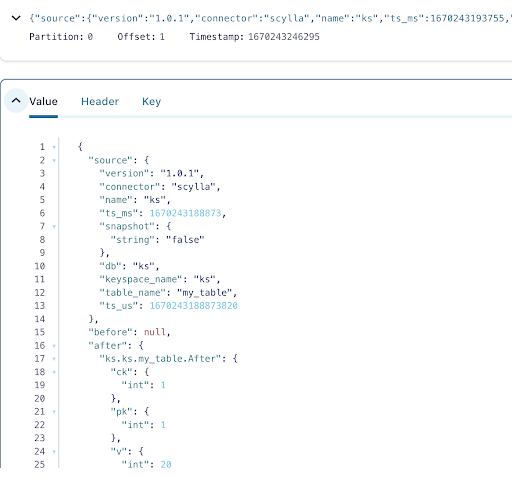
Сообщение содержит имя таблицы и пространство имен ScyllaDB с временем, а также статус данных до и после действия. Поскольку это операция вставки, данные до вставки равны null.
Далее вставьте еще одну строку в таблицу ScyllaDB:
docker exec -ti scylla-node1 cqlsh
INSERT INTO ks.my_table(pk, ck, v) VALUES (200, 50, 70);Теперь в Kafka подождите несколько секунд, и вы сможете увидеть детали нового Сообщения:
Очистка
После завершения работы с этой лабораторией вы можете остановить и удалить контейнеры Docker и образы.
Чтобы просмотреть список всех идентификаторов контейнеров:
docker container ls -aqЗатем вы можете остановить и удалить контейнеры, которыми больше не пользуетесь:
docker stop <ID_or_Name>
docker rm <ID_or_Name>Позже, если вы захотите повторить лабораторию, вы можете следовать инструкциям и использовать docker-compose, как и раньше.
Итог
С помощью источника соединителя CDC, плагина Kafka, совместимого с Kafka Connect, вы можете отслеживать все изменения на уровне строк таблицы ScyllaDB (INSERT, UPDATE или DELETE) и преобразовывать эти события в сообщения Kafka. Затем вы можете использовать данные из других приложений или выполнять с ними любые другие операции с помощью Kafka.
Source:
https://dzone.com/articles/change-data-capture-apache-kafka-and-scylladb