













Логи часто занимают большую часть информационных активов компании. Примерами логов являются деловые логи (например, журналы активности пользователей) и журналы эксплуатации и технического обслуживания серверов, баз данных, сетей или устройств IoT.
Логи являются хранительницей бизнеса. С одной стороны, они предоставляют предупреждения о системных рисках и помогают инженерам быстро определять основные причины при устранении неполадок. С другой стороны, если изменить временной диапазон, можно выявить полезные тенденции и закономерности, не говоря уже о том, что деловые логи являются основой понимания пользователей.
Однако, логи могут быть сложными из-за:
- Их огромного количества. Каждое системное событие или клик пользователя генерирует логи. Компания часто создает десятки миллиардов новых логов в день.
- Их объемности. Логи должны сохраняться. Они могут быть не нужны до тех пор, пока не понадобятся. Таким образом, компания может накопить до ПБ данных логов, многие из которых редко используются, но занимают огромное место на складе.
- Их необходимо быстро загружать и находить. Нахождение целевого лога для устранения неполадок похоже на поиск иголки в стоге сена. Люди стремятся к реальному времени записи логов и реальным ответам на запросы логов.
Теперь вы видите четкую картину того, каким должен быть идеальный системный процесс обработки логов. Он должен поддерживать следующее:
- Высокопроизводительное реальное время введения данных: Он должен быть способен записывать логи массово и делать их видимыми мгновенно.
- Дешевое хранение: Он должен быть способен хранить значительное количество логов без использования слишком много ресурсов.
- Поиск текста в реальном времени: Он должен обеспечивать быстрый поиск текста.
Обычные решения: Elasticsearch и Grafana Loki
В индустрии существуют два распространенных решения для обработки логов, представленные Elasticsearch и Grafana Loki соответственно.
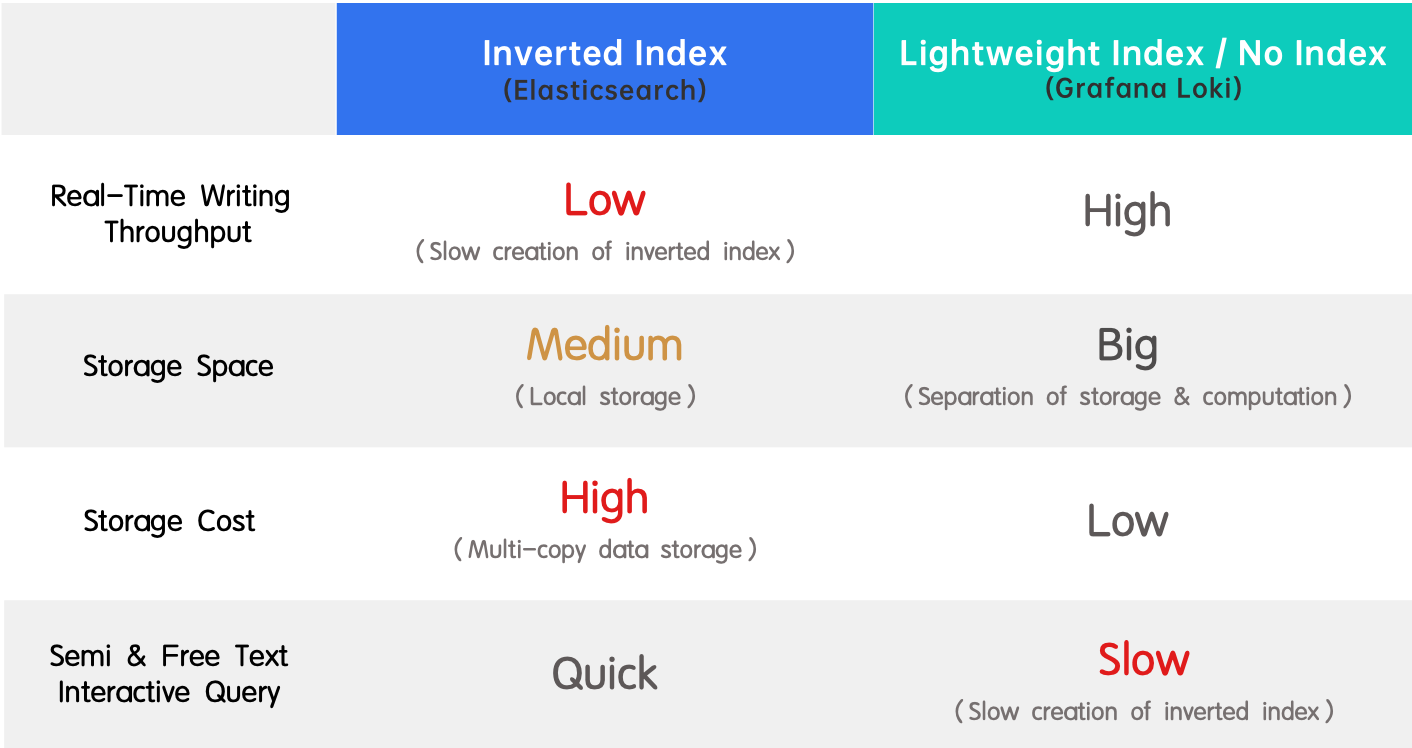
- Инвертированный индекс (Elasticsearch): Он широко используется благодаря поддержке полнотекстового поиска и высокой производительности. Недостатком является низкая пропускная способность при реальном времени записи и большое потребление ресурсов при создании индекса.
- Легковесный индекс / без индекса (Grafana Loki): Это противоположность инвертированному индексу, так как он обладает высокой пропускной способностью при реальной записи и низкой стоимостью хранения, но обеспечивает медленные запросы.
Введение в инвертированный индекс
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
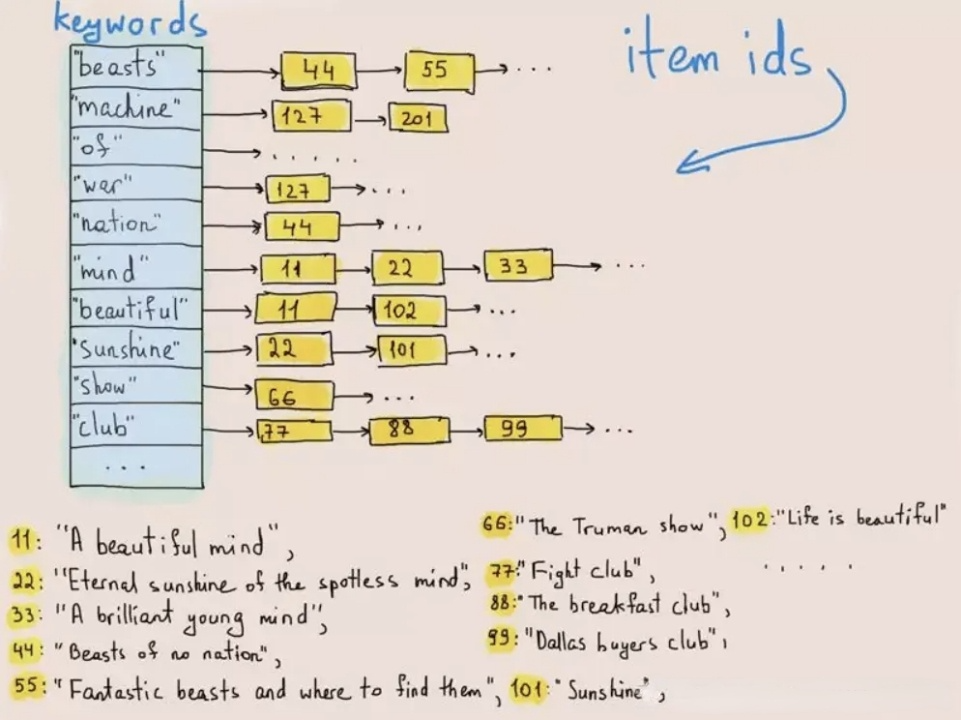
Инвертированное индексирование изначально использовалось для извлечения слов или фраз в текстах. Ниже приводится иллюстрация того, как это работает:
При записи данных система токенизирует тексты в термины и сохраняет эти термины в список постов, который сопоставляет термины с ID строки, где они существуют. При текстовых запросах база данных находит соответствующий ID строки ключевого слова (термина) в списке постов и извлекает целевую строку на основе ID строки. Таким образом, система не должна перебирать весь набор данных, что улучшает скорость запросов на несколько порядков.
В инвертированном индексировании Elasticsearch быстрый доступ достигается ценой скорости записи, пропускной способности записи и места на диске. Почему? Во-первых, токенизация, сортировка словаря и создание инвертированного индекса являются операциями, требующими значительных ресурсов CPU и памяти. Во-вторых, Elasticssearch должен хранить исходные данные, инвертированный индекс и дополнительную копию данных, хранящихся в столбцах для ускорения запросов. Это тройная избыточность.
Но без инвертированного индекса, например, Grafana Loki, ухудшает пользовательский опыт из-за медленных запросов, что является самым большим недостатком для инженеров в анализе логов.
Проще говоря, Elasticsearch и Grafana Loki представляют разные компромиссы между высокой пропускной способностью записи, низкими затратами на хранение и быстрой производительностью запросов. Что если я скажу вам, что есть способ иметь все это? Мы ввели инвертированные индексы в Apache Doris 2.0.0 и оптимизировали их для достижения двукратного ускорения запросов логов по сравнению с Elasticsearch при использовании 1/5 от его места на диске. Учитывая оба фактора, это решение в 10 раз лучше.
Инвертированный индекс в Apache Doris
Как правило, существует два способа реализации индексов: внешний системный индекс или встроенные индексы.
Внешняя индексирующая система: Вы подключаете внешнюю индексирующую систему к вашей базе данных. При вводе данных они импортируются в обе системы. После того, как индексирующая система создает индексы, она удаляет исходные данные в себе. Когда пользователи данных вводят запрос, индексирующая система предоставляет идентификаторы соответствующих данных, а затем база данных ищет целевые данные на основе идентификаторов.
Создание внешней индексирующей системы проще и менее инвазивно для базы данных, но это имеет некоторые раздражающие недостатки:
- Требование записывать данные в две системы может привести к несогласованности данных и избыточному хранению.
- Взаимодействие между базой данных и индексирующей системой приводит к накладным расходам, поэтому при большом объеме целевых данных запрос через две системы может быть медленным.
- Уход за двумя системами утомителен.
В Apache Doris мы выбираем другой путь. Встроенные обратные индексы труднее создавать, но как только это сделано, они быстрее, удобнее для пользователя и без проблем в обслуживании.
В Apache Doris данные организованы следующим образом. Индексы хранятся в регионе Index:
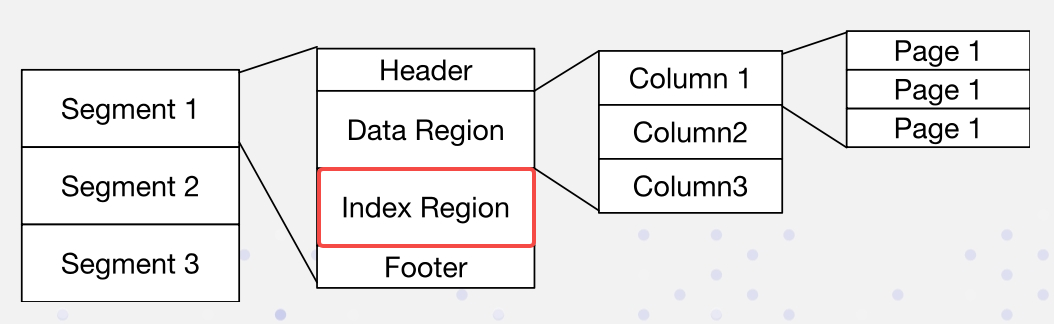
Мы реализуем обратные индексы неинвазивным способом:
- Импорт данных и уплотнение: При записи сегментного файла в Doris также будет записан файл обратного индекса. Путь к файлу индекса определяется идентификатором сегмента и идентификатором индекса. Строки в сегментах соответствуют документам в индексах, так же как RowID и DocID.
- Запрос: Если в условии
whereуказана колонка с инвертированным индексом, система будет искать в файле индекса, возвращать список DocID и преобразовывать список DocID в Bitmap RowID. При фильтрации RowID в Apache Doris будут считываться только целевые строки. Так ускоряются запросы.
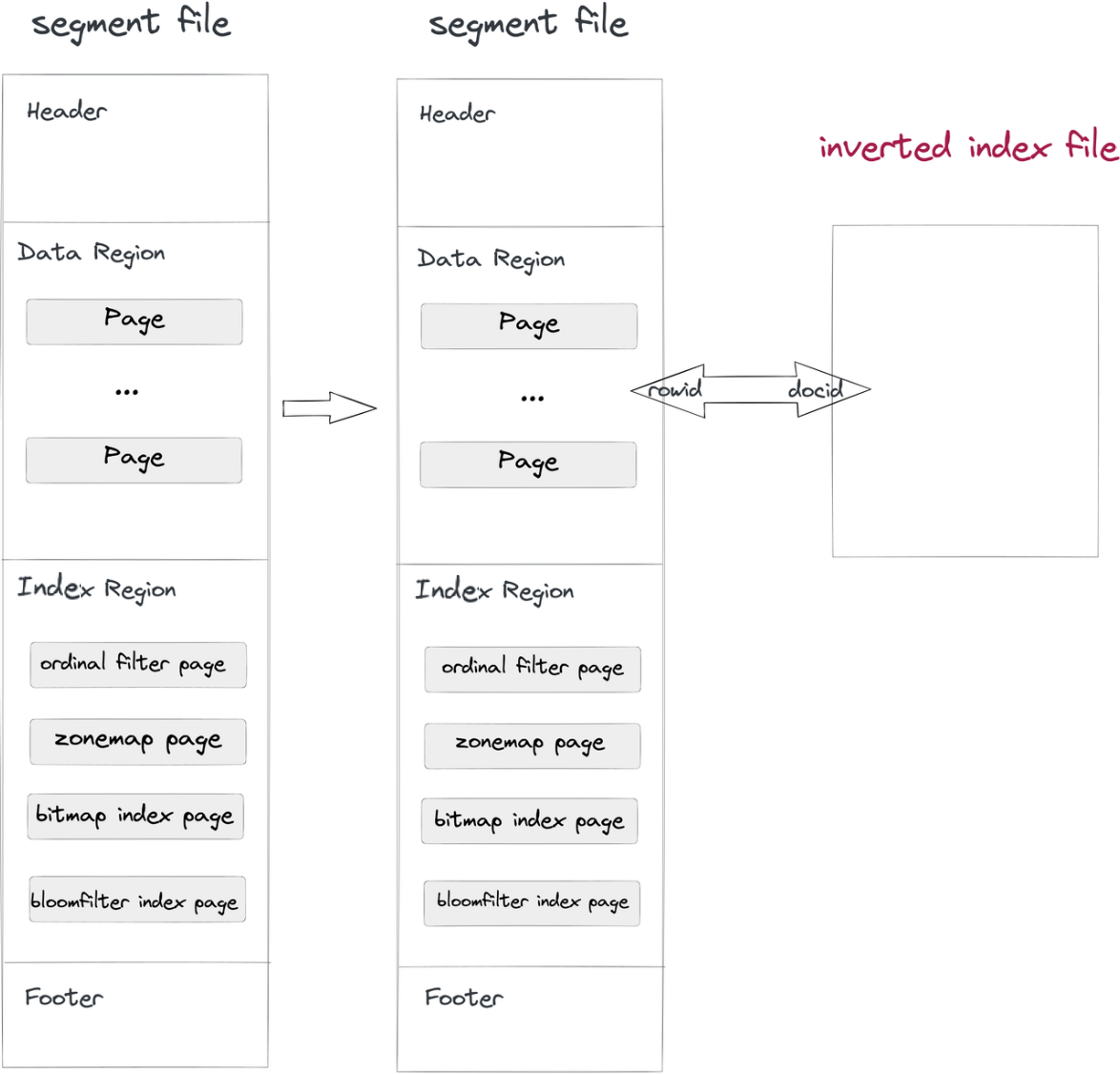
Такой неинвазивный метод отделяет файл индекса от файлов данных, поэтому вы можете вносить любые изменения в инвертированные индексы, не беспокоясь о влиянии на файлы данных или другие индексы.
Оптимизации для Инвертированного Индекса
Общие Оптимизации
C++ Implementation and Vectorization
В отличие от Elasticsearch, который использует Java, Apache Doris реализует модули хранения, движок выполнения запросов и инвертированные индексы на C++. По сравнению с Java, C++ обеспечивает лучшую производительность, позволяет легче векторизовать и не создает нагрузки на сборку мусора JVM. Мы векторизовали каждый шаг инвертированного индексирования в Apache Doris, такие как токенизация, создание индекса и запросы. Для сравнения, в инвертированном индексировании Apache Doris записывает данные со скоростью 20MB/s на ядро, что в четыре раза превышает показатели Elasticsearch (5MB/s).
Столбцовое Хранение и Сжатие
Apache Lucene служит основой для инвертированных индексов в Elasticsearch. Поскольку Lucene изначально создан для поддержки файлового хранения, он хранит данные в строчном формате.
В Apache Doris инвертированные индексы для разных колонок изолированы друг от друга, и файлы инвертированных индексов используют столбцовое хранение для удобства векторизации и сжатия данных.
Используя сжатие Zstandard, Apache Doris достигает коэффициента сжатия от 5:1 до 10:1, более быстрые скорости сжатия и на 50% меньше использование места, чем при сжатии GZIP.
BKD Trees для числовых / дата-временных столбцов
Apache Doris реализует BKD деревья для числовых и дата-временных столбцов. Это не только увеличивает производительность запросов по диапазону, но и является более экономным способом, чем преобразование этих столбцов в строки фиксированной длины. Другие преимущества включают:
- Эффективные запросы по диапазону: Он быстро находит целевой диапазон данных в числовых и дата-временных столбцах.
- Меньше места для хранения: Он объединяет и сжимает соседние блоки данных для снижения затрат на хранение.
- Поддержка многомерных данных: BKD деревья масштабируемы и адаптируются к многомерным типам данных, таким как GEO точки и диапазоны.
Помимо BKD деревьев, мы дополнительно оптимизировали запросы на числовых и дата-временных столбцах.
- Оптимизация для сценариев с низкой кардинальностью: Мы настроили алгоритм сжатия для сценариев с низкой кардинальностью, так что распаковка и десериализация большого количества инвертированных списков потребует меньше ресурсов ЦП.
- Предварительный выбор: Для сценариев с высоким коэффициентом попадания мы применяем предварительный выбор. Если коэффициент попадания превышает определенный порог, Doris пропускает процесс индексации и начинает фильтрацию данных.
Настроенные оптимизации для OLAP
Обычно анализ логов представляет собой простую форму запроса, не требующую продвинутых функций (например, оценки релевантности в Apache Lucene). Основная функция инструмента обработки логов — быстрые запросы и низкие затраты на хранение. Поэтому в Apache Doris мы оптимизировали структуру инвертированного индекса, чтобы удовлетворить потребности OLAP-базы данных.
- При вводе данных мы предотвращаем запись данных несколькими потоками в один и тот же индекс, тем самым избегая накладных расходов, вызванных соревнованием за блокировки.
- Мы отбрасываем файлы прямого индекса и Norm файлы для освобождения места в хранилище и уменьшения накладных расходов на ввод-вывод.
- Мы упрощаем логику вычисления оценки релевантности и ранжирования, чтобы еще больше снизить накладные расходы и повысить производительность.
Учитывая, что логи разбиты по временным диапазонам и исторические логи посещаются реже, мы планируем в будущих версиях Apache Doris предложить более детальный и гибкий контроль над индексами:
- Создание инвертированного индекса для указанного раздела данных: создание индекса для логов за последние семь дней и т.д.
- Удаление инвертированного индекса для указанного раздела данных: удаление индекса для логов старше одного месяца и т.д. (для освобождения места в индексе).
Бенчмаркинг
Мы протестировали Apache Doris на общедоступных наборах данных против Elasticsearch и ClickHouse.
Для справедливого сравнения мы обеспечиваем единообразие условий тестирования, включая инструменты бенчмаркинга, наборы данных и аппаратное обеспечение.
Apache Doris против Elasticsearch
- Инструмент для сравнения: ES Rally, официальный инструмент тестирования для Elasticsearch
- Набор данных: Логи сервера HTTP Чемпионата мира 1998 года (самодостаточный набор данных в ES Rally)
- Размер данных (до сжатия): 32 ГБ, 247 миллионов строк, 134 байта на строку (в среднем)
- Запросы: 11 запросов, включая поиск по ключевым словам, диапазонный запрос, агрегацию и ранжирование; Каждый запрос выполняется последовательно 100 раз.
- Окружение: 3 виртуальных машины в облаке по 16 ядер и 64 ГБ
Результаты Apache Doris:
- Скорость записи: 550 МБ/с,в 4.2 раза выше, чем у Elasticsearch
- Коэффициент сжатия: 10:1
- Использование хранилища: 20% от использования Elasticsearch
- Время отклика: 43% от времени отклика Elasticsearch

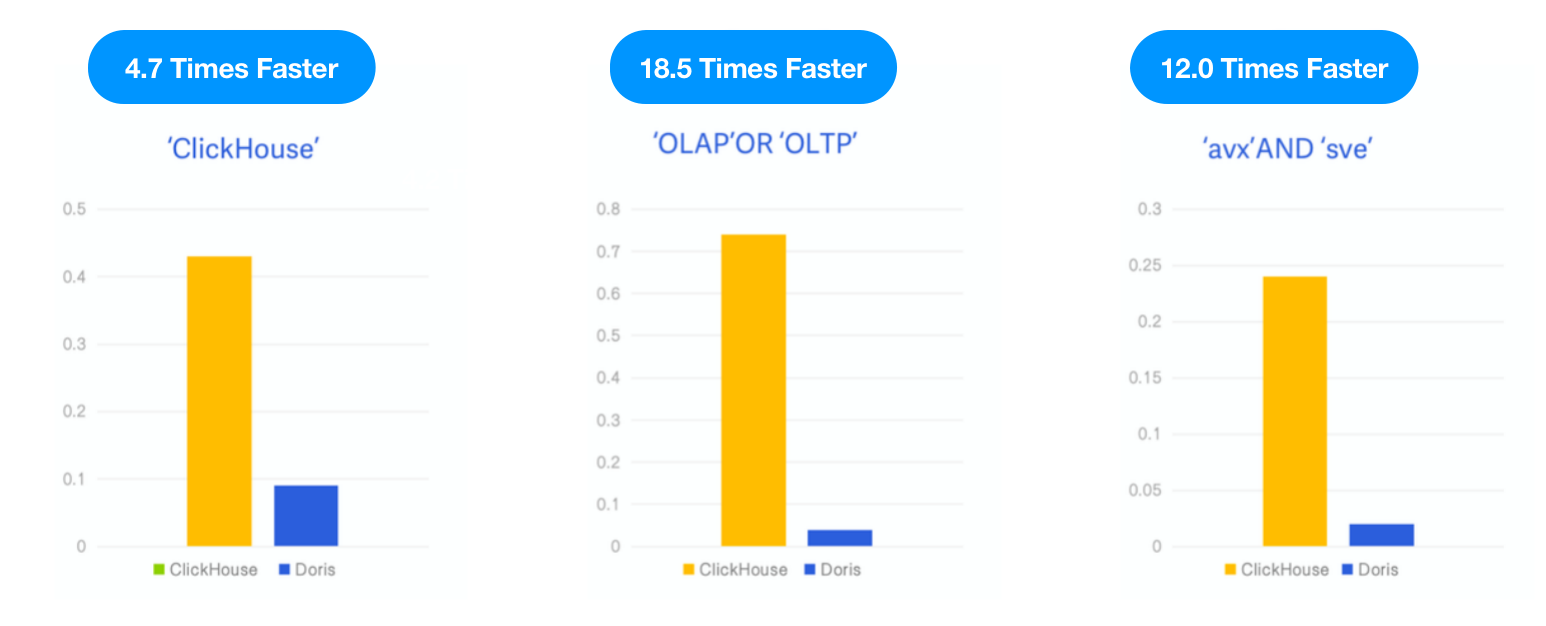
Apache Doris против ClickHouse
Так как ClickHouse представил обратный индекс как экспериментальную функцию в версии v23.1, мы протестировали Apache Doris с тем же набором данных и SQL, как описано в блоге ClickHouse, и сравнили производительность обоих под теми же условиями тестирования, случаем и инструментом.
- Данные: 6.7 ГБ, 28.73 миллиона строк, набор данных Hacker News, формат Parquet
- Запросы: 3 поиска по ключевым словам, подсчет количества вхождений ключевых слов “ClickHouse,” “OLAP,” OR “OLTP,” и “avx” AND “sve”.
- Окружение: 1 виртуальная машина в облаке с 16 ядрами и 64 ГБ
Результат: Apache Doris был в 4,7 раза, 18,5 раз и 12 раз быстрее, чем ClickHouse в трех запросах соответственно.
Использование и пример
- Набор данных: один миллион записей комментариев с Hacker News
Шаг 1: Укажите инвертированный индекс для таблицы данных при создании таблицы.
Параметры:
- INDEX idx_comment (
comment): создать индекс с именем “idx_comment” для столбца “comment” - USING INVERTED: указать инвертированный индекс для таблицы
- PROPERTIES(“parser” = “english”): указать язык токенизации как английский
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(Примечание: Вы можете добавить индекс к существующей таблице через ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). В отличие от интеллектуального индекса и вторичного индекса, создание инвертированного индекса включает только чтение столбца комментариев, поэтому оно может быть намного быстрее.)
Шаг 2: Извлеките слова “OLAP” и “OLTP” в столбце комментариев с MATCH_ALL. Время отклика здесь составляло 1/10 от времени жесткого сопоставления с like. (Разрыв в производительности увеличивается с увеличением объема данных.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
Для получения более подробной информации о функциях и руководства по использованию см. документацию: Инвертированный индекс
Подведение итогов
В общем, то, что обеспечивает в 10 раз более высокую стоимость Apache Doris по сравнению с Elasticsearch, заключается в оптимизациях для инвертированного индексирования, предназначенных для OLAP, поддерживаемых столбцовой хранилищем, массовым параллельным процессингом, векторизированным движком запросов и оптимизатором стоимости Apache Doris.
Хотя мы и гордимся нашей собственной инвертированной индексацией, мы понимаем, что самоизданные бенчмарки могут вызывать споры, поэтому мы открыты для отзывов от любых независимых тестировщиков и хотим увидеть, как Apache Doris работает в реальных случаях.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co