













Возникновение агентического ИИ вызвало волнение вокруг агентов, которые автономно выполняют задачи, делают рекомендации и осуществляют сложные рабочие процессы, сочетая ИИ с традиционным вычислительным процессом. Однако создание таких агентов в реальных, ориентированных на продукт средах представляет собой вызовы, выходящие за рамки самого ИИ.
Без тщательной архитектуры зависимости между компонентами могут создавать узкие места, ограничивать масштабируемость и усложнять обслуживание по мере развития системы. Решение заключается в разделении рабочих процессов, где агенты, инфраструктура и другие компоненты взаимодействуют плавно без жестких зависимостей.
Этот вид гибкой, масштабируемой интеграции требует общего “языка” для обмена данными – надежной архитектуры, ориентированной на события (EDA), работающей на основе потоков событий. Организуя приложения вокруг событий, агенты могут работать в отзывчивой, разделенной системе, где каждая часть выполняет свою работу независимо. Команды могут свободно выбирать технологии, управлять потребностями в масштабировании отдельно и поддерживать четкие границы между компонентами, обеспечивая истинную гибкость.
Чтобы проверить эти принципы, я разработал PodPrep AI, ИИ-поддерживаемого исследовательского помощника, который помогает мне подготовиться к интервью для подкастов Software Engineering Daily и Software Huddle. В этом посте я рассмотрю дизайн и архитектуру PodPrep AI, показывая, как EDA и потоки данных в реальном времени обеспечивают эффективную агентическую систему.
Примечание: Если вы хотите просто посмотреть код, перейдите в мой репозиторий на GitHub здесь.
Почему архитектура, ориентированная на события, важна для ИИ?
В реальных приложениях искусственного интеллекта тесно связанный монолитный дизайн не выдерживает испытания. Хотя доказательства концепции или демонстрации часто используют единую систему для упрощения, такой подход быстро становится непрактичным в производстве, особенно в распределенных средах. Тесно связанные системы создают узкие места, ограничивают масштабируемость и замедляют итерацию — все это критические проблемы, которые необходимо избегать по мере роста AI-решений.
Рассмотрим типичного AI-агента.
Он может потребовать извлечения данных из нескольких источников, обработки инженерии запросов и рабочих процессов RAG, а также взаимодействия непосредственно с различными инструментами для выполнения детерминированных рабочих процессов. Требуемая оркестрация сложна, с зависимостями от нескольких систем. И если агенту необходимо взаимодействовать с другими агентами, сложность только возрастает. Без гибкой архитектуры эти зависимости делают масштабирование и модификацию почти невозможными.

В производстве различные команды обычно управляют различными частями стека: MLOps и инженерия данных управляют конвейером RAG, data science выбирает модели, а разработчики приложений создают интерфейс и бэкэнд. Тесно связанная настройка заставляет эти команды зависеть друг от друга, что замедляет доставку и делает масштабирование сложным. Идеально, слои приложения не должны нуждаться в понимании внутренностей AI; они должны просто потреблять результаты по мере необходимости.
Кроме того, приложения искусственного интеллекта не могут работать изолированно. Для получения реальной ценности идеи искусственного интеллекта должны без проблем передаваться по платформам данных клиентов (CDP), CRM-системам, аналитике и другим инструментам. Взаимодействие с клиентами должно вызывать обновления в реальном времени, непосредственно поступая в другие инструменты для действий и анализа. Без единого подхода интеграция идей через различные платформы становится патчворком, который сложно управлять и невозможно масштабировать.
AI, основанный на EDA, решает эти проблемы, создавая “центральную нервную систему” для данных. С EDA приложения передают события вместо зависимости от цепочек команд. Это отделяет компоненты, позволяя данным асинхронно передаваться туда, где это необходимо, обеспечивая каждой команде независимую работу. EDA способствует беспрепятственной интеграции данных, масштабируемому росту и устойчивости, что делает его мощным фундаментом для современных систем, основанных на искусственном интеллекте.
Проектирование масштабируемого исследовательского агента на основе искусственного интеллекта
За последние два года я вел сотни подкастов на Software Engineering Daily, Software Huddle и Partially Redacted.
Для подготовки к каждому подкасту я провожу глубокий исследовательский процесс, составляя краткое содержание подкаста, которое содержит мои мысли, информацию о госте и теме, а также ряд потенциальных вопросов. Для составления этого краткого содержания я обычно изучаю информацию о госте и компании, в которой он работает, слушаю другие подкасты, в которых он мог появиться, читаю блоги, которые он написал, и изучаю основную тему, которую мы будем обсуждать.
Я пытаюсь вставить связи с другими подкастами, которые я вел, или собственным опытом, связанным с темой или схожими темами. Весь этот процесс требует значительного времени и усилий. У крупных подкастов есть специальные исследователи и ассистенты, которые выполняют эту работу для ведущего. У меня здесь нет такой операции. Мне приходится делать все это самому.
Для решения этой проблемы я хотел создать агента, который мог бы делать эту работу за меня. На высоком уровне агент будет выглядеть примерно так, как на изображении ниже.

Я предоставляю базовые материалы, такие как имя гостя, компанию, темы, на которые я хочу сосредоточиться, некоторые ссылки, такие как блоги и существующие подкасты, после чего происходит некоторая магия и мое исследование завершено.
Эта простая идея привела меня к созданию PodPrep AI, моего исследовательского ассистента на основе искусственного интеллекта, который стоит мне лишь токены.
Остальная часть этой статьи обсуждает дизайн PodPrep AI, начиная с пользовательского интерфейса.
Создание пользовательского интерфейса агента
Я разработал интерфейс агента как веб-приложение, где я могу легко вводить исходные материалы для исследовательского процесса. Это включает имя гостя, их компанию, тему интервью, любой дополнительный контекст и ссылки на соответствующие блоги, веб-сайты и предыдущие интервью в подкастах.
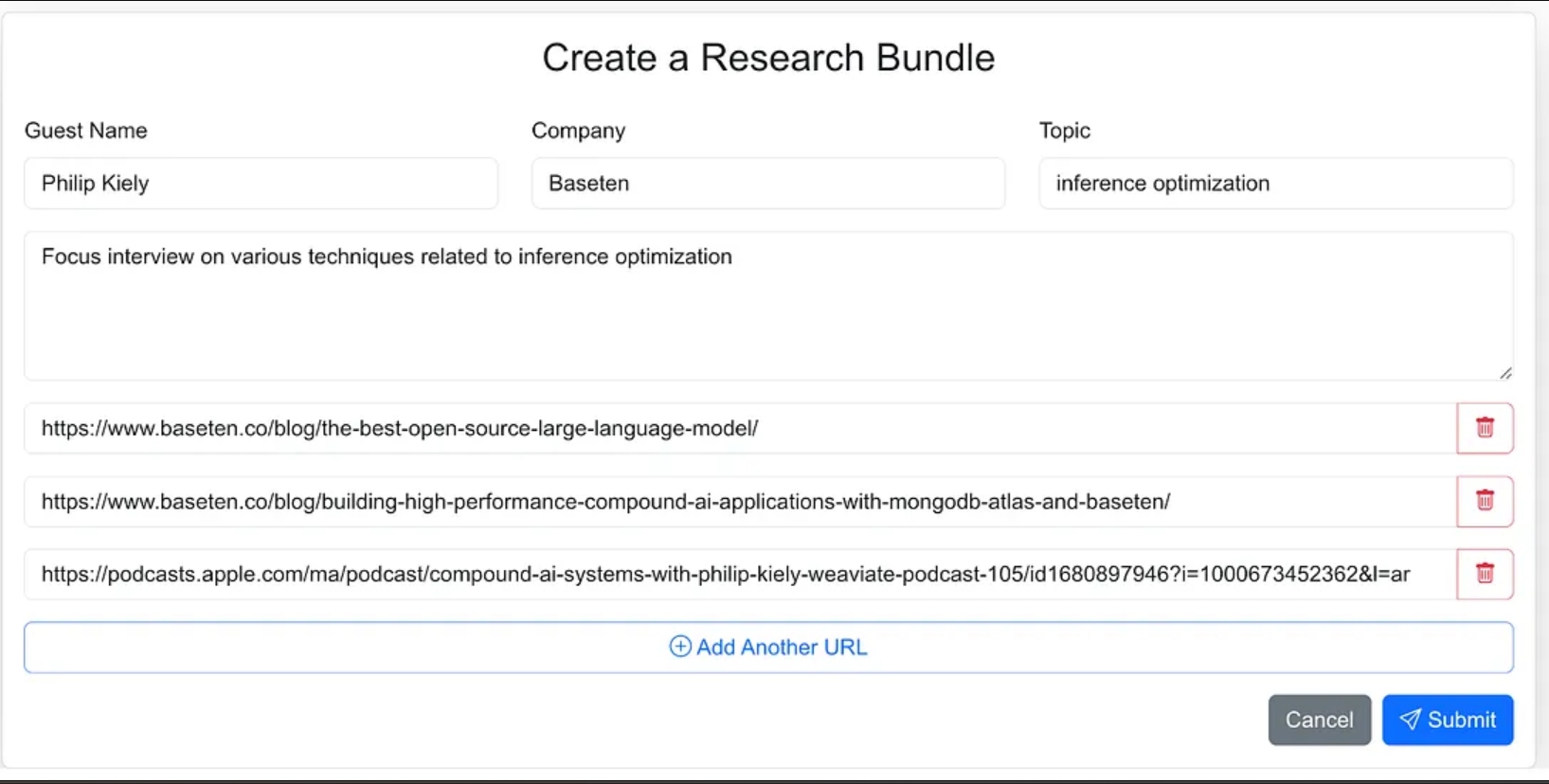
Я мог бы дать агенту меньше указаний и в рамках рабочего процесса агента заставить его искать исходные материалы, но для версии 1.0 я решил предоставить исходные URL-адреса.
Веб-приложение является стандартным трехуровневым приложением, построенным с использованием Next.js и MongoDB в качестве базы данных приложения. Оно не знает ничего об ИИ. Оно просто позволяет пользователю вводить новые исследовательские пакеты, которые находятся в состоянии обработки, пока агентный процесс не завершит рабочий процесс и не заполнит исследовательский бриф в базе данных приложения.
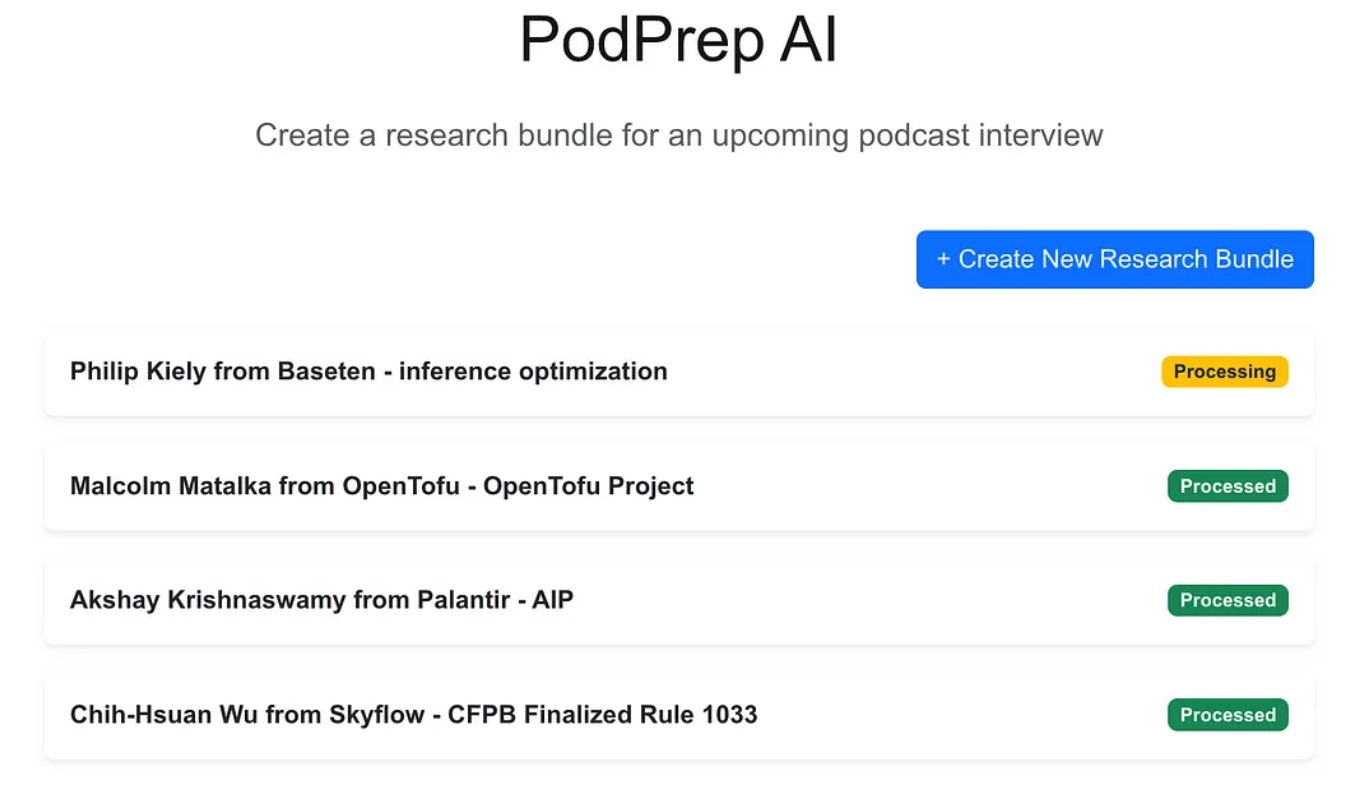
После завершения магии ИИ я могу получить доступ к документу брифа для записи, как показано ниже.

Создание агентного рабочего процесса
Для версии 1.0 я хотел иметь возможность выполнять три основных действия для создания исследовательского брифа:
- Для любого URL веб-сайта, блога или подкаста извлечь текст или резюме, разбить текст на разумные части, сгенерировать эмбеддинги и сохранить векторное представление.
- Для всего текста, извлеченного из исследовательских исходных URL, выделить самые интересные вопросы и сохранить их.
- Сгенерировать исследовательский бриф подкаста, комбинируя наиболее релевантный контекст на основе эмбеддингов, лучших ранее заданных вопросов и любой другой информации, которая была частью входного пакета.
Изображение ниже показывает архитектуру от веб-приложения до агентного рабочего процесса.
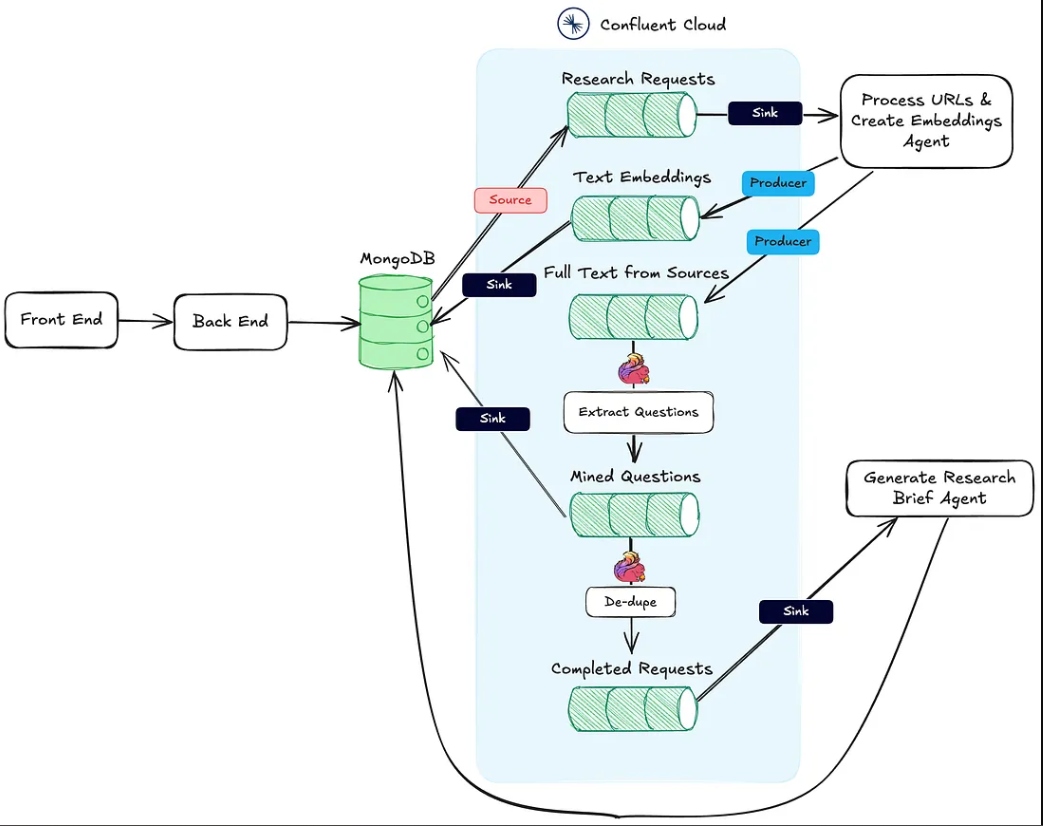
Действие #1, упомянутое выше, поддерживается HTTP-эндпоинтом Process URLs & Create Embeddings Agent.
Действие #2 выполняется с использованием Flink и встроенной поддержки модели ИИ в Confluent Cloud.
Наконец, действие №3 выполняется агентом Генерация исследовательского брифа, который также является конечной точкой HTTP и вызывается после завершения первых двух действий.
В следующих разделах я подробно обсуждаю каждое из этих действий.
Агент обработки URL и создания векторных вложений
Этот агент отвечает за извлечение текста из источников исследований по URL и за обработку векторных вложений. Ниже приведен общий процесс того, что происходит за кулисами для обработки исследовательских материалов.

Как только пакет исследований создается пользователем и сохраняется в MongoDB, соединитель источника MongoDB генерирует сообщения в теме Kafka под названием research-requests. Это и запускает агентский рабочий процесс.
Каждый POST-запрос к конечной точке HTTP содержит URL-адреса из запроса на исследование и первичный ключ в коллекции пакетов исследований MongoDB.
Агент проходит по каждому URL, и если это не подкаст Apple, он извлекает полный HTML-код страницы. Поскольку я не знаю структуру страницы, я не могу полагаться на библиотеки парсинга HTML для поиска соответствующего текста. Вместо этого я отправляю текст страницы в модель gpt-4o-mini с температурой ноль, используя приведенный ниже запрос, чтобы получить то, что мне нужно.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
Для подкастов мне нужно сделать немного больше работы.
Обратная разработка URL подкастов Apple
Чтобы извлечь данные из эпизодов подкастов, сначала нам нужно конвертировать аудио в текст с помощью модели Whisper. Но прежде чем мы сможем это сделать, нам нужно найти фактический MP3-файл для каждого эпизода подкаста, скачать его и разбить на части по 25 МБ или меньше (максимальный размер для Whisper).
Вызов заключается в том, что Apple не предоставляет прямую ссылку на MP3 для своих подкаст-эпизодов. Однако MP3-файл доступен в оригинальной ленте RSS подкаста, и мы можем программно найти эту ленту, используя идентификатор подкаста Apple.
Например, в приведенном ниже URL числовая часть после /id является уникальным идентификатором подкаста Apple:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
Используя API Apple, мы можем найти идентификатор подкаста и получить JSON-ответ, содержащий URL ленты RSS:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
После получения XML-ленты RSS мы ищем в ней конкретный эпизод. Поскольку у нас есть только URL эпизода от Apple (а не фактическое название), мы используем идентификатор из URL для нахождения эпизода в ленте и получения его URL MP3.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
Теперь, имея текст из блоговых постов, веб-сайтов и доступные MP3, агент использует рекурсивный разделитель текста по символам LangChain для разделения текста на фрагменты и генерации вложений из этих фрагментов. Фрагменты публикуются в теме text-embeddings и направляются в MongoDB.
- Примечание: Я решил использовать MongoDB как мою прикладную базу данных и векторную базу данных. Однако из-за подхода EDA, который я выбрал, они могут легко быть отдельными системами, и это просто вопрос замены коннектора для направления из темы Text Embeddings.
Помимо создания и публикации вложений, агент также публикует текст из источников в тему под названием full-text-from-sources. Публикация в эту тему запускает действие #2.
Извлечение вопросов с помощью Flink и OpenAI
Apache Flink – это фреймворк обработки потоков данных с открытым исходным кодом, созданный для обработки больших объемов данных в реальном времени, идеально подходит для приложений с высокой пропускной способностью и низкой задержкой. Совмещая Flink с Confluent, мы можем интегрировать модели языковых моделей, такие как GPT от OpenAI, непосредственно в рабочие процессы потоковых данных. Эта интеграция обеспечивает рабочие процессы RAG в реальном времени, гарантируя, что процесс извлечения вопросов работает с самыми свежими доступными данными.
Наличие исходного текста источника в потоке также позволяет нам впоследствии внедрить новые рабочие процессы, использующие те же данные, улучшая процесс генерации кратких исследований или отправляя их в нижележащие службы, такие как хранилище данных. Эта гибкая настройка позволяет нам добавлять дополнительные функции искусственного интеллекта и не-ИИ со временем, не перестраивая основной конвейер.
В PodPrep AI я использую Flink для извлечения вопросов из текста, полученного из URL-адресов источников.
Настройка Flink для вызова LLM включает настройку подключения через интерфейс командной строки Confluent. Ниже приведен пример команды для настройки подключения к OpenAI, хотя доступны и другие варианты.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
Как только соединение установлено, я могу создать модель как в Cloud Console, так и в Flink SQL shell. Для извлечения вопросов я настраиваю модель соответствующим образом.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
С моделью готовой, я использую встроенную функцию Flink ml_predict, чтобы генерировать вопросы из исходного материала, записывая вывод в поток с именем mined-questions, который синхронизируется с MongoDB для дальнейшего использования.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink также помогает отслеживать, когда все исследовательские материалы были обработаны, инициируя создание исследовательского брифа. Это осуществляется путем записи в поток completed-requests, как только URL в mined-questions совпадают с теми, что в потоке полных текстов.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
Когда сообщения записываются в completed-requests, уникальный идентификатор для исследовательского пакета отправляется агенту Генерации Исследовательского Брифа.
Агент Генерации Исследовательского Брифа
Этот агент берет все наиболее релевантные доступные исследовательские материалы и использует LLM для создания исследовательского брифа. Ниже представлен общий поток событий, происходящих для создания исследовательского брифа.

Схема потока для агента Генерации Исследовательского Брифа
Давайте разберем некоторые из этих шагов. Чтобы составить подсказку для LLM, я комбинирую извлеченные вопросы, тему, имя гостя, название компании, системную подсказку для руководства и контекст, сохраненный в векторной базе данных, который наиболее семантически похож на тему подкаста.
Поскольку набор исследований содержит ограниченную контекстную информацию, сложно напрямую извлечь наиболее релевантный контекст из векторного хранилища. Для решения этой проблемы я использую LLM для создания поискового запроса для нахождения наилучшего соответствия контента, как показано на узле “Создать поисковый запрос” на диаграмме.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
Используя запрос, созданный LLM, я создаю вложение и осуществляю поиск в MongoDB через векторный индекс, фильтруя по bundleId, чтобы ограничить поиск материалами, относящимися к конкретному подкасту.
Обнаружив наилучшую контекстную информацию, я создаю подсказку и генерирую краткий обзор исследования, сохраняя результат в MongoDB для отображения веб-приложением.
Важные заметки по реализации
Я написал как фронтенд-приложение для PodPrep AI, так и агентов на JavaScript, но в реальном сценарии агент, вероятно, использовал бы другой язык, например, Python. Кроме того, для упрощения, агенты Process URLs & Create Embeddings Agent и Generate Research Brief Agent находятся в одном проекте, работающем на одном веб-сервере. В реальной производственной системе они могли бы быть серверными функциями, работающими независимо.
Заключительные мысли
Построение PodPrep AI подчеркивает, как архитектура, ориентированная на события, позволяет реальным приложениям искусственного интеллекта масштабироваться и плавно адаптироваться. С помощью Flink и Confluent я создал систему, которая обрабатывает данные в реальном времени, обеспечивая работу рабочего процесса, управляемого искусственным интеллектом, без жестких зависимостей. Такой разобщенный подход позволяет компонентам работать независимо друг от друга, но оставаться связанными через потоки событий — это важно для сложных распределенных приложений, в которых различные команды управляют различными частями стека.
В сегодняшней среде, основанной на искусственном интеллекте, доступ к свежим данным в реальном времени через различные системы является важным. EDA служит “центральной нервной системой” для данных, обеспечивая безшовную интеграцию и гибкость при масштабировании системы.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink