













В большинстве финансовых фирм, обработка онлайн транзакций (OLTP) часто основывается на статических или редко обновляемых данных, также называемых справочными данными. Источники справочных данных не всегда требуют возможностей ACID-транзакций, а скорее нуждаются в поддержке быстрых запросов на чтение, часто основанных на простых паттернах доступа к данным, и архитектуре, управляемой событиями, чтобы обеспечить актуальность целевых систем. NoSQL базы данных выступают идеальными кандидатами для удовлетворения этих требований, и облачные платформы, такие как AWS, предлагают управляемые и высокоустойчивые экосистемы данных.
В этой статье я не собираюсь определять, какая NoSQL база данных AWS лучше: понятие лучшей базы данных существует только в контексте конкретной цели. Я расскажу о кодинг-лабе для измерения производительности управляемых NoSQL баз данных AWS, таких как DynamoDB, Cassandra, Redis, и MongoDB.
Тестирование производительности
I will start by defining the performance test case, which will concurrently insert a JSON payload 200 times and then read it 200 times.
JSON Payload
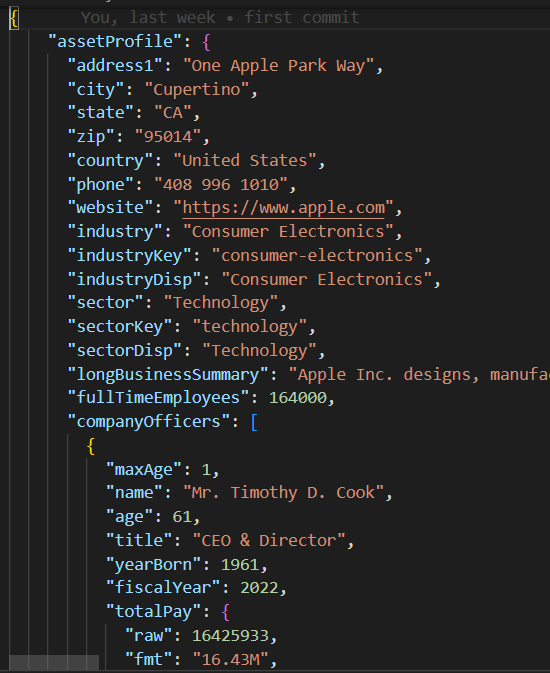
Класс base/parent в base_db.py реализует логику тестового случая, заключающуюся в выполнении 10 параллельных потоков для создания и чтения 200 записей.
#imports
.....
class BaseDB:
def __init__(self, file_name='instrument.json', threads=10, records=20):
...................................
def execute(self):
create_threads = []
for i in range(self.num_threads):
thread = threading.Thread(
target=self.create_records, args=(i,))
create_threads.append(thread)
thread.start()
for thread in create_threads:
thread.join()
read_threads = []
for i in range(self.num_threads):
thread = threading.Thread(target=self.read_records, args=(i,))
read_threads.append(thread)
thread.start()
for thread in read_threads:
thread.join()
self.print_stats()
Каждый поток выполняет процедуру чтения/записи в create_records и read_records соответственно. Обратите внимание, что эти функции не содержат какой-либо специфической логики базы данных, а скорее измеряют производительность каждого выполнения чтения и записи.
def create_records(self, thread_id):
for i in range(1, self.num_records + 1):
key = int(thread_id * 100 + i)
start_time = time.time()
self.create_record(key)
end_time = time.time()
execution_time = end_time - start_time
self.performance_data[key] = {'Create Time': execution_time}
def read_records(self, thread_id):
for key in self.performance_data.keys():
start_time = time.time()
self.read_record(key)
end_time = time.time()
execution_time = end_time - start_time
self.performance_data[key]['Read Time'] = execution_timeПосле выполнения тестового случая функция print_stats выводит метрики выполнения, такие как среднее значение чтения/записи и стандартное отклонение (stdev), которые указывают на производительность и согласованность базы данных при чтении/записи (меньшее значение stdev подразумевает более согласованную производительность выполнения).
def print_stats(self):
if len(self.performance_data) > 0:
# Создание DataFrame Pandas из данных о производительности
df = pd.DataFrame.from_dict(self.performance_data, orient='index')
if not df.empty:
df.sort_index(inplace=True)
# Расчет среднего и стандартного отклонения для каждого столбца
create_mean = statistics.mean(df['Create Time'])
read_mean = statistics.mean(df['Read Time'])
create_stdev = statistics.stdev(df['Create Time'])
read_stdev = statistics.stdev(df['Read Time'])
print("Performance Data:")
print(df)
print(f"Create Time mean: {create_mean}, stdev: {create_stdev}")
print(f"Read Time mean: {read_mean}, stdev: {read_stdev}")
Код NoSQL
В отличие от реляционных баз данных, поддерживающих стандартный SQL, каждая NoSQL база данных имеет свой собственный SDK. Классы тестовых случаев для каждой NoSQL базы данных должны только реализовать конструктор и функции create_record/read_recod , содержащие собственный SDK базы данных для инициализации подключения к базе данных и создания/чтения записей в несколько строк кода.
Тестовый случай DynamoDB
import boto3
from base_db import BaseDB
class DynamoDB (BaseDB):
def __init__(self, file_name='instrument.json', threads=10, records=20):
super().__init__(file_name, threads, records)
dynamodb = boto3.resource('dynamodb', region_name='us-east-1')
table_name = 'Instruments'
self.table = dynamodb.Table(table_name)
def create_record(self, key):
item = {
'key': key,
'data': self.json_data
}
self.table.put_item(Item=item)
def read_record(self, key):
self.table.get_item(Key={'key': key})
if __name__ == "__main__":
DynamoDB().execute()Настройка AWS
Для выполнения этих тестовых случаев производительности в учетной записи AWS необходимо выполнить следующие шаги:
- Создать роль IAM для EC2 с привилегиями доступа к необходимым службам AWS по данным.
- Запустить инстанс EC2 и назначить созданную новую роль IAM.
- Создать экземпляр каждой NoSQL базы данных.
Роль IAM
Таблица DynamoDB
Пространство ключей Cassandra/Таблица

Обратите внимание, что хост и учетные данные базы данных были жестко закодированы и удалены в модулях mongo_db.py и redis_db.py и потребуются обновления соответствующими настройками подключения к базе данных для вашей учетной записи AWS. Для подключения к DynamoDB и Cassandra я решил временно использовать учетные данные сессии Boto3, присвоенные роли IAM db_performnace_iam_role. Этот код будет работать в любой учетной записи AWS в регионе East 1 без каких-либо изменений.
class CassandraDB(BaseDB):
def __init__(self, file_name='instrument.json', threads=10, records=20):
super().__init__(file_name=file_name, threads=threads, records=records)
self.json_data = json.dumps(
self.json_data, cls=DecimalEncoder).encode()
# Конфигурация пространств ключей Cassandra
contact_points = ['cassandra.us-east-1.amazonaws.com']
keyspace_name = 'db_performance'
ssl_context = SSLContext(PROTOCOL_TLSv1_2)
ssl_context.load_verify_locations('sf-class2-root.crt')
ssl_context.verify_mode = CERT_REQUIRED
boto_session = boto3.Session(region_name="us-east-1")
auth_provider = SigV4AuthProvider(session=boto_session)
cluster = Cluster(contact_points, ssl_context=ssl_context, auth_provider=auth_provider,
port=9142)
self.session = cluster.connect(keyspace=keyspace_name)Подключитесь к экземпляру EC2 (я использовал Session Manager) и выполните следующий скрипт Shell для выполнения этих задач:
- Установите Git.
- Установите Pythion3.
- Клонируйте репозиторий GitHub performance_db.
- Установите и активируйте виртуальное окружение Python3.
- Установите сторонние библиотеки/зависимости.
- Выполните каждый тестовый случай.
sudo yum install git
sudo yum install python3
git clone https://github.com/dshilman/db_performance.git
sudo git pull
cd db_performance
python3 -m venv venv
source ./venv/bin/activate
sudo python3 -m pip install -r requirements.txt
cd code
sudo python3 -m dynamo_db
sudo python3 -m cassandra_db
sudo python3 -m redis_db
sudo python3 -m mongo_dbВы должны увидеть следующий вывод для первых двух тестовых случаев:
|
(venv) sh-5.2$ sudo python3 -m dynamo_db Производительность данных: Создание Время Чтение Время 1 0.336909 0.031491 2 0.056884 0.053334 3 0.085881 0.031385 4 0.084940 0.050059 5 0.169012 0.050044 .. … … 916 0.047431 0.041877 917 0.043795 0.024649 918 0.075325 0.035251 919 0.101007 0.068767 920 0.103432 0.037742
[200 строк x 2 столбца] Среднее время создания: 0.0858926808834076, стандартное отклонение: 0.07714510154026173 Среднее время чтения: 0.04880355834960937, стандартное отклонение: 0.028805479258627295 Время выполнения: 11.499964714050293 |
(venv) sh-5.2$ sudo python3 -m cassandra_db Данные о производительности: Создание Время Чтение Время 1 0.024815 0.005986 2 0.008256 0.006927 3 0.008996 0.009810 4 0.005362 0.005892 5 0.010117 0.010308 .. … … 916 0.006234 0.008147 917 0.011564 0.004347 918 0.007857 0.008329 919 0.007260 0.007370 920 0.004654 0.006049
[200 строк x 2 столбца] Среднее время создания: 0.009145524501800537, стандартное отклонение: 0.005201661271831082 Среднее время чтения: 0.007248317003250122, стандартное отклонение: 0.003557610695674452 Время выполнения: 1.6279327869415283 |
Результаты тестов
| DynamoDB | Cassandra | MongoDB | Redis | |
|---|---|---|---|---|
| Create | mean: 0.0859 stdev: 0.0771 |
mean: 0.0091 stdev: 0.0052 |
mean: 0.0292 std: 0.0764 |
mean: 0.0028 stdev: 0.0049 |
| Read | mean: 0.0488 stdev: 0.0288 |
mean: 0.0072 stdev: 0.0036 |
mean: 0.0509 std: 0.0027 |
mean: 0.0012 stdev: 0.0016 |
| Exec Time | 11.45 sec | 1.6279 sec | 10.2608 sec | 0.3465 sec |
Мои наблюдения
- I was blown away by Cassandra’s fast performance. Cassandra support for SQL allows rich access pattern queries and AWS Keyspaces offer cross-region replication.
- I find DynamoDB’s performance disappointing despite the AWS hype about it. You should try to avoid the cross-partition table scan and thus must use an index for each data access pattern. DynamoDB global tables enable cross-region data replication.
- MongoDB обладает очень простым SDK, удобен в использовании и имеет лучшую поддержку типов данных JSON. Вы можете создавать индексы и выполнять сложные запросы по вложенным атрибутам JSON. С появлением новых форматов двоичных данных MongoDB может утратить свою привлекательность.
- Redis демонстрирует удивительно быструю производительность, однако в конце концов это кэш на основе ключ/значение, даже если он поддерживает сложные типы данных. Redis предлагает мощные функции, такие как пайплайнинг и скриптинга, чтобы дальше улучшить производительность запросов, передавая код Redis для выполнения на стороне сервера.
Заключение
Подводя итог, выбор управляемой AWS NoSQL базы данных для платформы ссылочных данных вашего предприятия зависит от ваших конкретных приоритетов. Если производительность и репликация между регионами являются вашим основным вопросом, AWS Cassandra выделяется как очевидный победитель. DynamoDB хорошо интегрируется с другими сервисами AWS, такими как Lambda и Kinesis, и поэтому является отличным вариантом для архитектуры AWS нативных или серверфул. Для приложений, требующих надежной поддержки типов данных JSON, MongoDB занимает лидирующие позиции. Однако, если ваше внимание сосредоточено на быстром поиске или управлении сессиями для обеспечения высокой доступности, Redis оказывается отличным выбором. В конечном итоге решение должно соответствовать уникальным требованиям вашей организации.
Как всегда, вы можете найти код в репозитории GitHub, который был связан ранее в этой статье (см. Задачу #3 для скрипта командной строки выше). Не стесняйтесь обращаться ко мне, если вам нужна помощь в запуске этого кода или с настройкой AWS.
Source:
https://dzone.com/articles/aws-nosql-performance-lab-using-python