













Каждая организация, работающая на основе данных, имеет операционные и аналитические нагрузки. Появляется подход “лучшая из breeds”, который использует различные платформы данных, включая потоковые данные, озера данных, хранилища данных и решения lakehouse, а также облачные услуги. Открытый формат таблицы, такой как Apache Iceberg, является важным в корпоративной архитектуре для обеспечения надежного управления данными и их обмена, бесшовной эволюции схемы, эффективной обработки больших объемов данных и экономически эффективного хранения, предоставляя при этом сильную поддержку транзакций ACID и запросов с возможностью путешествия во времени.
Эта статья рассматривает рыночные тренды; adopцию форматов таблиц, таких как Iceberg, Hudi, Paimon, Delta Lake и XTable; а также стратегию продуктов некоторых из ведущих vendors платформ данных, таких как Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka/Flink), Amazon Athena и Google BigQuery.
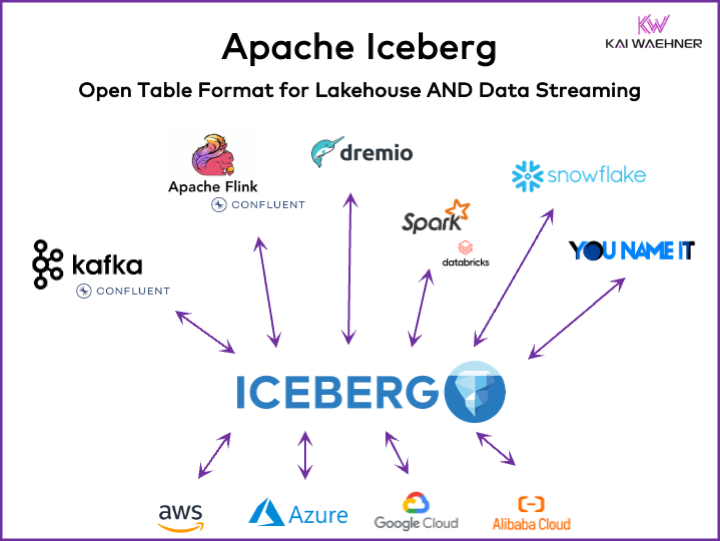
Что такое открытый формат таблицы для платформы данных?
Открытый формат таблицы помогает поддерживать целостность данных, оптимизировать производительность запросов и обеспечивать четкое понимание хранящихся в платформе данных.
Открытый формат таблицы для платформ данных обычно включает в себя хорошо определенную структуру с конкретными компонентами, которые обеспечивают организацию, доступность и легкую��询 данных. Типичный формат таблицы содержит имя таблицы, имена столбцов, типы данных,.primary и внешние ключи, индексы и ограничения.
Это не новая концепция. Ваш любимый десятилетний database — как Oracle, IBM DB2 (даже на mainframe) или PostgreSQL — использует те же принципы. Однако требования и вызовы изменились немного для облачных хранилищ данных, данных озер и lakehouses в отношении масштабируемости, производительности и возможностей запросов.
Преимущества формата “Lakehouse Table”, как Apache Iceberg
Каждая часть организации становится управляемой данными. В результате появляются обширные наборы данных, обмен данными с данными продуктов между бизнес-юнитами и новые требования для обработки данных в gần реальном времени.
Apache Iceberg предоставляет множество преимуществ для корпоративной архитектуры:
- Единое хранилище: Данные хранятся один раз (поступающие из различных источников данных), что снижает затраты и сложность
- Interoperability: Доступ без усилий интеграции с любым аналитическим двигателем
- Все данные: Объединение операционных и аналитических нагрузок (транзакционные системы, big data logs/IoT/clickstream, мобильные API, интерфейсы third-party B2B и т.д.)
- Независимость от поставщика: Работа с любым любимым аналитическим двигателем (не важно, если он в реальном времени, batch или API-ориентированный)
Apache Hudi и Delta Lake предоставляют те же характеристики. Хотя Delta Lake в основном управляется Databricks как единственным поставщиком.
Формат таблицы и интерфейс каталога
Важно понять, что обсуждения о Apache Iceberg или аналогичных фреймворках formats таблиц включают два концепта: формат таблицы и интерфейс каталога! Как конечный пользователь технологии, вам нужны оба!
Проект Apache Iceberg реализует формат, но предоставляет только спецификацию (но не реализацию) для каталога:
- Формат таблицы определяет, как данные организованы, хранятся и управляются внутри таблицы.
- Интерфейс каталога управляет метаданными таблиц и предоставляет абстрактный слой для доступа к таблицам в хранилище данных.
Документация Apache Iceberg подробно рассматривает концепции на основе этой схемы:
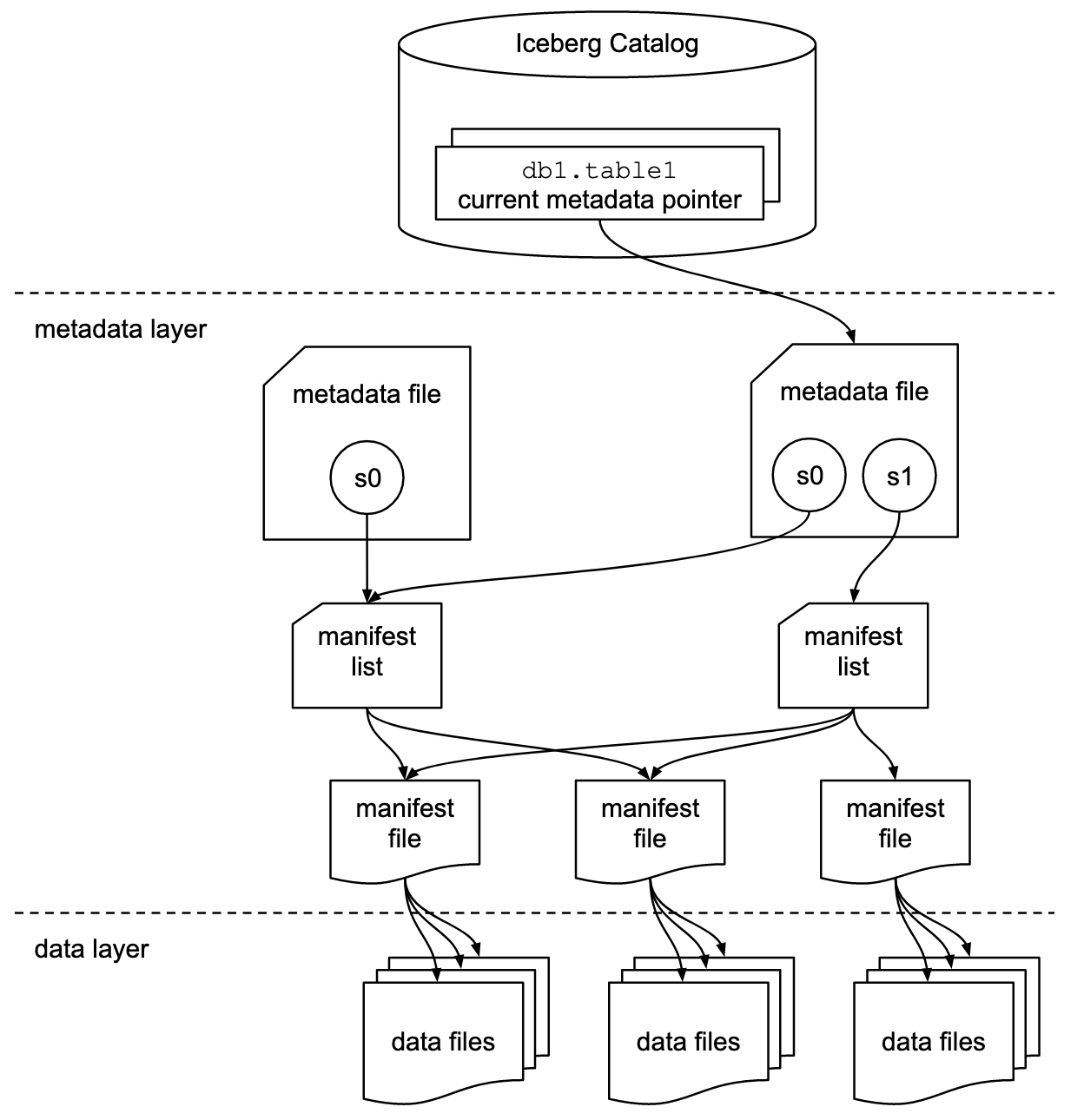
Организации используют различные реализации интерфейса каталога Iceberg. Каждая из них интегрируется с различными метаданными хранилищами и сервисами. Основные реализации включают:
- Каталог Hadoop: Использует Hadoop Distributed File System (HDFS) или другие兼容имые файловые системы для хранения метаданных. Подходит для сред, уже использующих Hadoop.
- Каталог Hive: Интегрируется с Apache Hive Metastore для управления метаданными таблиц. Идеален для пользователей, использующих Hive для управления своими метаданными.
- Каталог AWS Glue: Использует AWS Glue Data Catalog для хранения метаданных. Предназначен для пользователей, работающих в экосистеме AWS.
- Каталог REST: Предоставляет RESTful интерфейс для операций с каталогом через HTTP. Позволяет интегрировать с пользовательскими или сторонними сервисами метаданных.
- Каталог Nessie: Использует проект Nessie, который предоставляет опыт, аналогичный Git, для управления данными.
Рост популярности и принятие Apache Iceberg мотивируют многих vendors платформ данных implementовать собственный каталог Iceberg. Я обсуждаю несколько стратегий в разделе ниже о стратегиях платформ данных и облачных провайдеров, включая Polaris от Snowflake, Unity от Databricks и Tableflow от Confluent.
Поддержка Iceberg первого класса против коннектора Iceberg
请注意, поддержка Apache Iceberg (или Hudi/Delta Lake) означает гораздо больше, чем просто предоставление коннектора и интеграции с форматом таблиц через API. Вендоры и облачные сервисы отличаются наличием таких передовых функций, как автоматическое отображение между форматами данных, критические SLA, возможность путешествия во времени, интуитивно понятные интерфейсы и т.д.
Давайте рассмотрим пример: интеграция между Apache Kafka и Iceberg. Already были реализованы различные Kafka Connect connectors. Однако вот преимущества использования интеграции первого класса с Iceberg (например, Confluent’s Tableflow) по сравнению с использованием только Kafka Connect connector:
- Нет конфигурации коннектора
- Нет потребления через коннектор
- Встроенное обслуживание (компактирование, сбор мусора, управление снимками)
- Автоматическая эволюция схемы
- Синхронизация внешнего сервиса каталога
- Более простые операции (в полностью управляемом решении SaaS, это безсерверное решение, не требующее масштабирования или управления со стороны末端 пользователя)
Аналогичные преимущества применяются и к другим платформам данных, а также к потенциальной первоклассной интеграции по сравнению с предоставлением простых коннекторов.
Открытый формат таблицы для Data Lake/Lakehouse с использованием Apache Iceberg, Apache Hudi и Delta Lake
Общая цель рамок формата таблицы, таких как Apache Iceberg, Apache Hudi и Delta Lake, заключается в улучшении функциональности и надежности данных湖泊 за счет решения типичных задач, связанных с управлением大规模 данными. Эти рамки помогают:
- Улучшить управление данными
- Обеспечить более легкое управление процессами摄入ения, хранения и retrieval данных в data lakes.
- Поддерживать эффективную организацию и хранение данных, обеспечивая лучшую производительность и масштабируемость.
- Обеспечить согласованность данных
- Предоставлять механизмы для транзакций ACID, обеспечивая, что данные останутся согласованными и надежными даже во время одновременных операций чтения и записи.
- Поддерживать изоляцию снимков, позволяя пользователям видеть согласованное состояние данных в любой момент времени.
- Поддержка эволюции схемы
- Позволяет вносить изменения в структуру данных (например, добавлять, переименовывать или удалять столбцы), не нарушая существующие данные или требуя сложных миграций.
- Оптимизация производительности запросов
- Реализация avanzados индексирования и стратегий partitioning для улучшения скорости и эффективности запросов к данным.
- Обеспечение эффективного управления метаданными для обработки больших наборов данных и сложных запросов.
- Улучшение управления данными
- Предоставление инструментов для лучшего отслеживания и управления наследственностью данных, версий и аудита, что критически важно для поддержания качества данных и соответствия.
Обращаясь к этим целям, фреймворки формата таблиц, такие как Apache Iceberg, Apache Hudi и Delta Lake помогают организациям создавать более надежные, масштабируемые и стабильные озера данных и лейкхаусы. Инженеры данных, дата-ученые и бизнес-аналитики используют аналитические, AI/ML или инструменты отчетности/визуализации на основе формата таблиц для управления и анализа больших объемов данных.
Сравнение Apache Iceberg, Hudi, Paimon и Delta Lake
Я не буду проводить сравнение фреймворков формата таблиц Apache Iceberg, Apache Hudi, Apache Paimon и Delta Lake здесь. Многие эксперты уже писали об этом. Каждый фреймворк формата таблиц имеет уникальные сильные стороны и преимущества. Но обновления требуются каждый месяц из-за быстрого развития и инноваций, добавляющих новые улучшения и возможности в эти фреймворки.
Вот краткое резюме того, что я вижу в различных блогах о четырех вариантах:
- Apache Iceberg: Превосходит в эволюции схем и разделов, эффективном управлении метаданными и широкой совместимости с различными движками обработки данных.
- Apache Hudi: Лучше всего подходит для потоковой передачи данных в реальном времени и обновлений, с сильными возможностями захвата изменений данных и версионирования данных.
- Apache Paimon: Формат озера, который позволяет создавать архитектуру реального времени lakehouse с Flink и Spark для потоковых и пакетных операций.
- Delta Lake: Обеспечивает надежные ACID-транзакции, принудительное соблюдение схем и функции временного путешествия, что делает его идеальным для поддержания качества и целостности данных.
Ключевая точка принятия решения может заключаться в том, что Delta Lake не поддерживается широкой сообществом, как Iceberg и Hudi, а в основном одной компанией Databricks.
Apache XTable как interoperable cross-table framework, поддерживающий Iceberg, Hudi и Delta Lake
У пользователей есть множество вариантов. XTable, formerly known as OneTable, это еще одна инкубируемая таблица frameworks под лицензией Apache open-source, обеспечивающая без缝 interoperate cross-table между Apache Hudi, Delta Lake и Apache Iceberg.
Apache XTable:
- Предоставляет cross-table omnidirectional interoperability между formatami lakehouse.
- Не является новым или отдельным форматом. Apache XTable предоставляет абстракции и инструменты для перевода метаданных формата таблицы lakehouse.
Возможно, Apache XTable является ответом на предоставление вариантов для конкретных платформ данных и облачных провайдеров, сохраняя при этом простую интеграцию и interoperability.
Но будьте осторожны: обертка поверх различных технологий не является панацеей. Мы видели это χρόνια назад, когда появился Apache Beam. Apache Beam — это open-source unified модель и набор языковых SDK для определения и выполнения рабочих процессов ввода и обработки данных. Он поддерживает различные stream processing engines, такие как Flink, Spark и Samza. Основным драйвером за Apache Beam является Google, который позволяет migrirovat’ рабочие процессы в Google Cloud Dataflow. Однако ограничения огромны, так как такая обертка должна найти наименьшее общее кратное поддерживаемых функций. И основное преимущество большинства фреймворков — это 20%, которые не вписываются в такую обертку. Поэтому, например, Kafka Streams не поддерживает Apache Beam, так как это потребовало бы слишком много ограничений в дизайне.
Принятие рынка форматами таблиц
Во-первых, мы все еще находимся на早期 этапах. Мы все еще на уровне инновационного толчка в терминах цикла Гartner Hype, подходя к пику раздутых ожиданий. Большинство организаций еще только оценивают, но еще не внедряют эти форматы таблиц в production по всей организации.
Вернемся к прошлому: Войны контейнеров между Kubernetes и Mesosphere и Cloud Foundry
Дебаты вокруг Apache Iceberg напоминают мне о войнах контейнеров несколько лет назад. Термин “Войны контейнеров” refers к конкуренции и соперничеству между различными контейнерными технологиями и платформами в области разработок программного обеспечения и ИТ-инфраструктуры.
Три конкурирующие технологии были Kubernetes, Mesosphere и Cloud Foundry. Вот как это шло:

Cloud Foundry и Mesosphere были среди первых, но Kubernetes все же выиграл битву. Почему? Я никогда не понимал всех технических деталей и различий. В конце концов, если три фреймворка довольно похожи, все дело в:
- принятии сообществом
- верном времени выхода новых функций
- хорошем маркетинге
- удаче
- и нескольких других факторах
Но для программной индустрии хорошо иметь один ведущий开源-фреймворк для создания решений и бизнес-моделей вместо трех конкурирующих.
Настоящее время: Войны форматов таблиц Apache Iceberg vs. Hudi vs. Delta Lake
Конечно, Google Trends не является статистическим доказательством или сложным исследованием. Но я часто использовал его в прошлом в качестве интуитивно понятного, простого и бесплатного инструмента для анализа рыночных трендов. Поэтому я также использовал этот инструмент, чтобы увидеть, совпадают ли поисковые запросы в Google с моим личным опытом принятия рынка Apache Iceberg, Hudi и Delta Lake (Apache XTable пока слишком мал, чтобы быть добавленным):
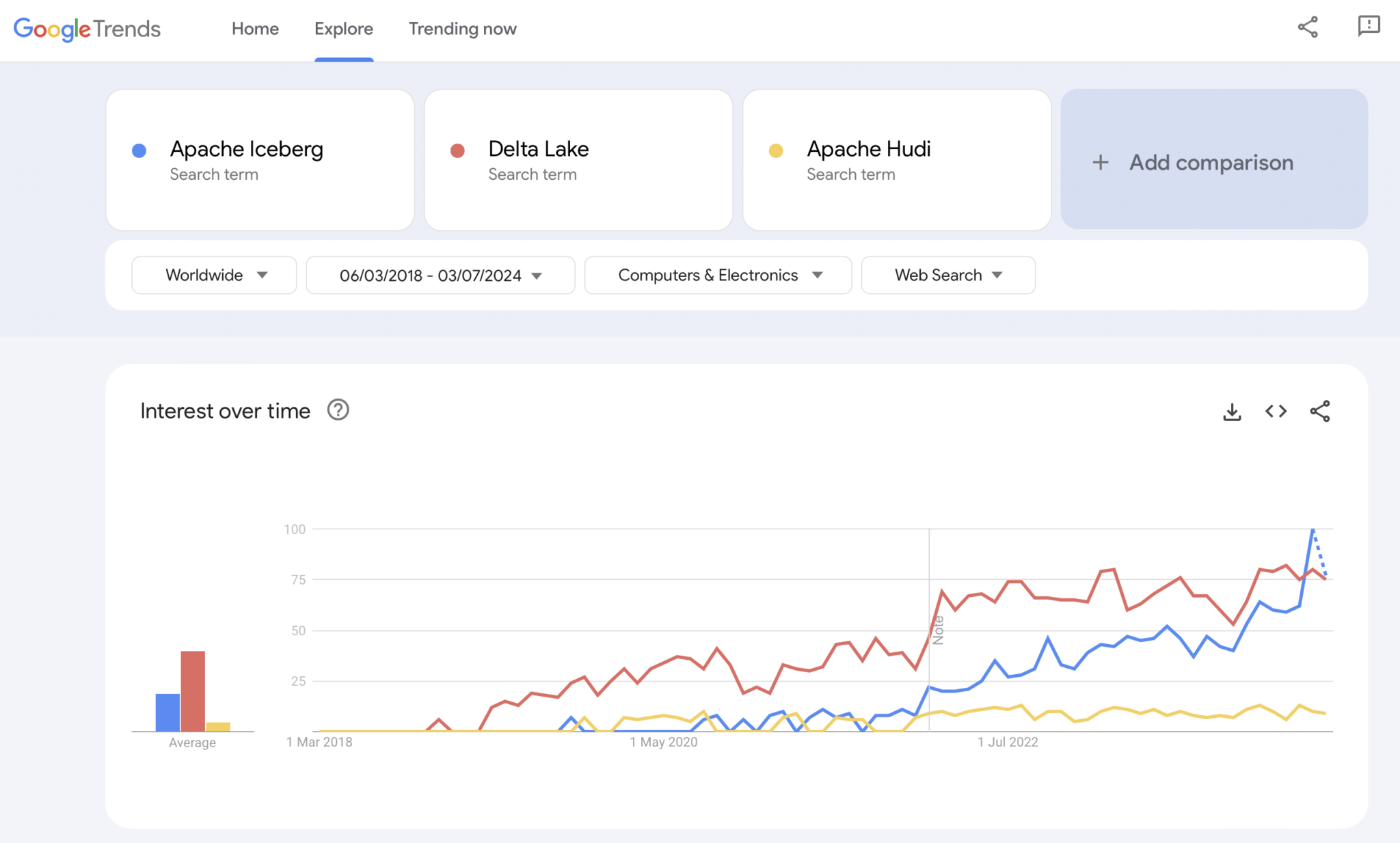
Мы явно видим аналогичный паттерн, как и в войнах контейнеров несколько лет назад. Я не имею представления, куда это идет. И если какая-то технология победит, или если фреймворки differentiate достаточно, чтобы доказать, что нет универсального решения, будущее нам покажет.
Мое личное мнение? Я думаю, что Apache Iceberg победит в этой гонке. Почему? Я не могу спорить ни с какими техническими理由ами. Я просто вижу, что越来越多的 клиентов из всех отраслей все больше и больше говорят о нем. И все больше и больше поставщиков начинают его поддерживать. Но посмотрим. Я на самом деле неzero кто победит. Однако, как и в войнах контейнеров, я думаю, что хорошо иметь единый стандарт и поставщики differentiate с функциями вокруг него, как это происходит с Kubernetes.
Но, помня об этом, давайте рассмотрим текущую стратегию ведущих платформ данных и облачных провайдеров относительно поддержки формата таблицы в своих платформах и облачных сервисах.
Стратегии поставщиков данных и облачных провайдеров для Apache Iceberg
Я не буду делать никаких спекуляций в этом разделе. Эволюция framework’ов формата таблиц происходит быстро, и стратегии поставщиков также быстро меняются. Пожалуйста, обратитесь к веб-сайтам поставщиков для получения последней информации. Но вот статус-кво о стратегиях данных платформ и облачных провайдеров относительно поддержки и интеграции Apache Iceberg.
- Snowflake:
- Поддерживает Apache Iceberg уже довольно давно
- Регулярно добавляет лучшую интеграцию и новые функции
- Внутренние и внешние варианты хранения (с компромиссами), такие как хранилище Snowflake или Amazon S3
- Объявил Polaris, открытый каталог реализации для Iceberg, с обязательством поддерживать community-driven, vendor-agnostic bi-directional integration
- Databricks:
- Фокусируется на Delta Lake как на формате таблицы и (теперь开源) Unity как каталоге
- Приобрела Tabular, ведущую компанию за Apache Iceberg
- Неясная стратегияfuture поддержки открытого интерфейса Iceberg (в обоих направлениях) или только для подачи данных в свою платформу lakehouse и технологии, такие как Delta Lake и Unity Catalog
- Confluent:
- Встраивает Apache Iceberg в качестве первого класса в свою платформу потоковой обработки данных (продукт называется Tableflow)
- Переводит тему Kafka и связанную метаданными схемы (то есть договор данных) в таблицу Iceberg
- Двунаправленная интеграция между операционными и аналитическими нагрузками
- Аналитика с嵌入式 безсерверным Flink и его унифицированным API для пакетной и потоковой обработки или обмен данными с third-party аналитическими двигателями, такими как Snowflake, Databricks или Amazon Athena
- Больше платформ данных и open-source аналитических двигателей:
- Список технологий и облачных сервисов, поддерживающих Iceberg, растет каждый месяц
- Несколько примеров: Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst, используя Trino (ранее PrestoSQL), Cloudera, используя Impala, Imply, используя Apache Druid, Fivetran
- Поставщики облачных услуг (AWS, Azure, Google Cloud, Alibaba):
- Разные стратегии и интеграции, но все облачные провайдеры увеличивают поддержку Iceberg среди своих сервисов в наши дни, например:
- Объектное хранилище: Amazon S3, Azure Data Lake Storage (ALDS), Google Cloud Storage
- Каталоги: Специфичные для облака, такие как AWS Glue Catalog, или независимые от поставщика, такие как Project Nessie или Hive Catalog
- Аналитика: Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
- Разные стратегии и интеграции, но все облачные провайдеры увеличивают поддержку Iceberg среди своих сервисов в наши дни, например:
Shift Left Architecture With Kafka, Flink, and Iceberg to Unify Operational and Analytical Workloads
Архитектура shift left перемещает обработку данных ближе к источнику данных, используя технологии потоковой обработки данных в реальном времени, такие как Apache Kafka и Flink, для обработки данных в движении сразу после их поступления. Этот подход снижает задержку и улучшает согласованность и качество данных.
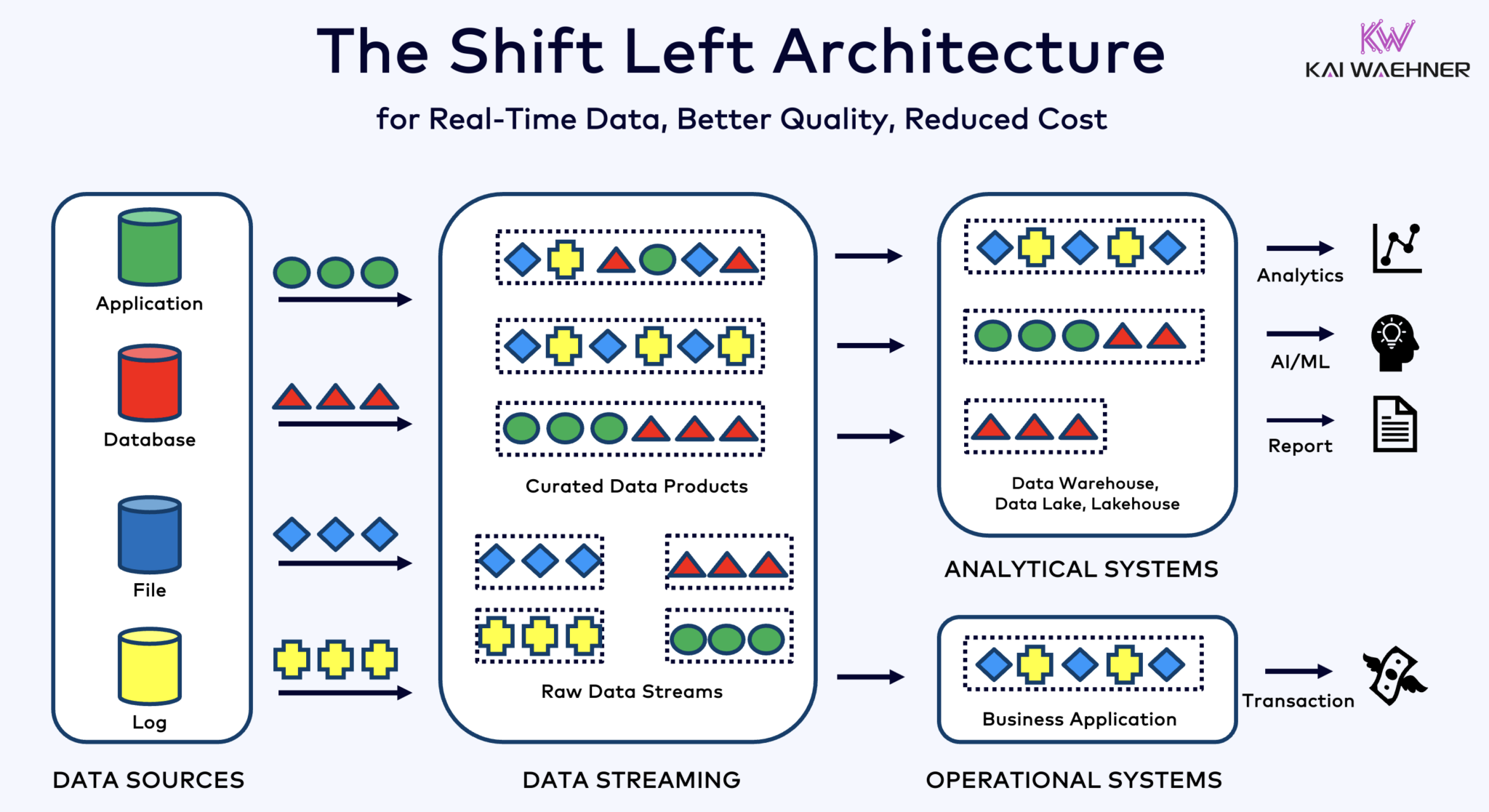
В отличие от ETL и ELT, которые involve batch processing с данными, хранящимися в покое, архитектура shift left enables реальное время capture и преобразование данных. Она aligns с концепцией zero-ETL, делая данные немедленно可用ными. Но в contrast к zero-ETL, перенос обработки данных на левую сторону корпоративной архитектуры избегает сложной, трудно поддерживаемой спагетти-архитектуры с множеством точечно-точечных подключений.
Shift left архитектура также снижает потребность в обратном ETL, обеспечивая данные являются operabelnymi в реальном времени как для операционных, так и для аналитических систем. В целом, данная архитектура enhances свежесть данных, снижает затраты и ускоряет время выхода на рынок для данных, управляемых приложений. Узнайте больше о этом концепте в моей статье в блоге о “Shift Left Архитектура.”
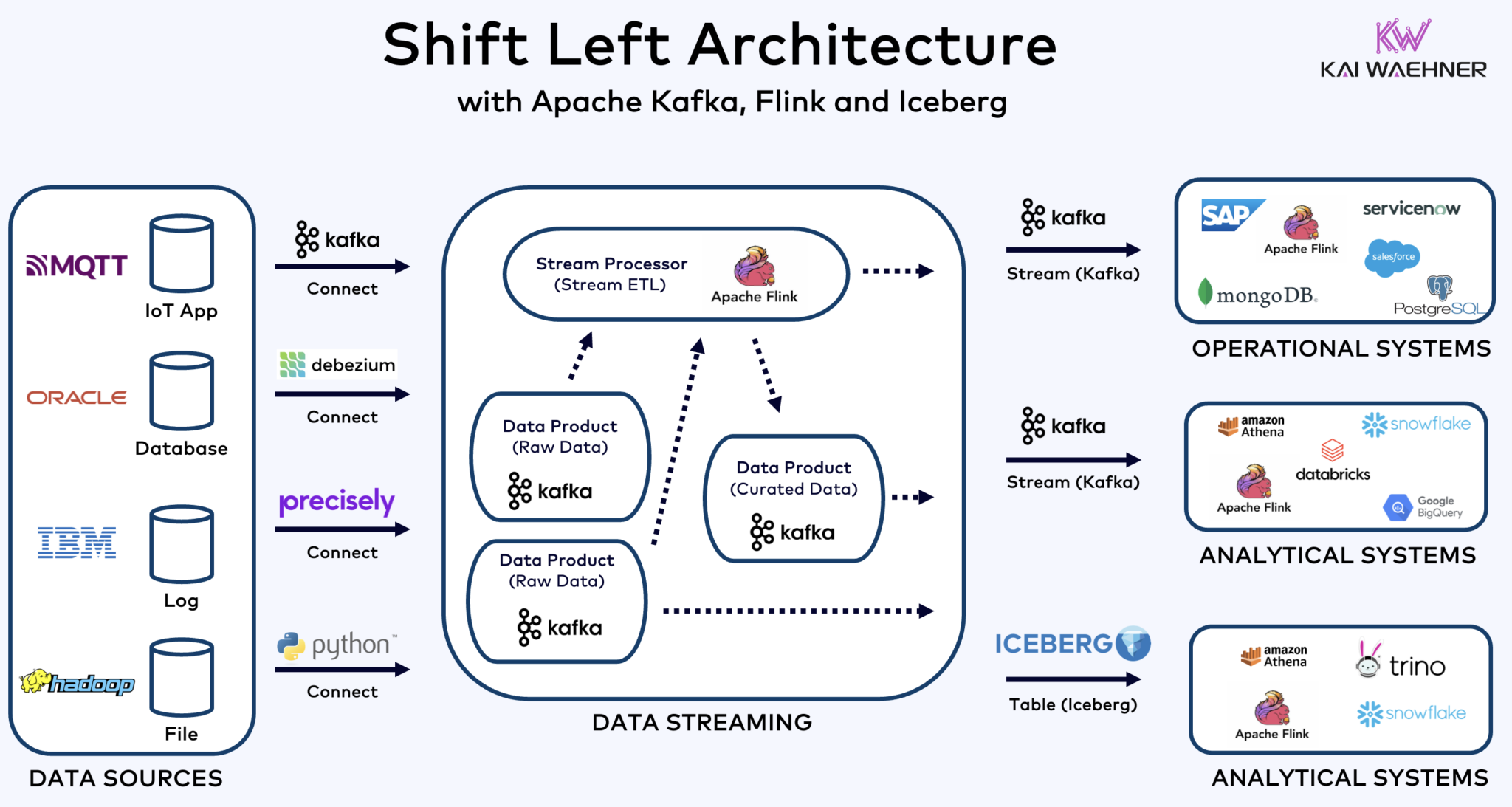
Apache Iceberg как Открытый Формат Таблицы и Каталог для Бесшовного Обмена Данными Across Аналитических Движков
Открытый формат таблицы и каталог introduces огромные преимущества в корпоративной архитектуре:
- Interoperability
- Свобода выбора аналитических движков
- Более быстрое время выхода на рынок
- Снижение затрат
Apache Iceberg似乎是跨供应商 и облачных провайдеров де-факто стандартом. Однако, он все еще находится на ранней стадии и competing и обертывающие технологии, такие как Apache Hudi, Apache Paimon, Delta Lake и Apache XTable, также пытаются набрать momentum.
Айсберг и другие открытые форматы таблиц не просто巨大胜利 для единого хранения и интеграции с множеством аналитических/данных/ИИ/ML платформ, таких как Snowflake, Databricks, Google BigQuery и другие, но также и для объединения операционных и аналитических нагрузок использованием потоковой передачи данных с технологиями, такими как Apache Kafka и Flink. Shift left архитектура является значительным преимуществом для уменьшения усилий, улучшения качества и согласованности данных, и возможности реального времени вместо批处理 приложений и инсайтов.
Наконец, если вы все еще задаетесь вопросом, какие различия между потоковой передачей данных и хранилищами данных (и как они дополняют друг друга), посмотрите это десяти минутное видео:
Какова ваша стратегия формата таблиц? Какие технологии и облачные сервисы вы используете? Давайте свяжемся на LinkedIn и обсудим это!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming