













O atraso na replicação no PostgreSQL ocorre quando as alterações feitas no servidor primário levam tempo para refletir no servidor de réplica. Seja utilizando replicação por streaming ou replicação lógica, o atraso pode afetar o desempenho, a consistência e a disponibilidade do sistema. Esta postagem abrange os tipos de replicação, suas diferenças, causas de atraso, fórmulas matemáticas para estimativa de atraso, técnicas de monitoramento e estratégias para minimizar o atraso na replicação.
Tipos de Replicação no PostgreSQL
Replicação por Streaming
A replicação por streaming envia continuamente as alterações no Log de Gravação Antecipada (WAL) do servidor primário para um ou mais servidores de réplica em tempo quase real. A réplica aplica as alterações sequencialmente à medida que são recebidas. Este método replica todo o banco de dados e garante que as réplicas permaneçam sincronizadas.
Vantagens
- Baixa latência com sincronização quase em tempo real.
- Efficiente para replicação de banco de dados completo.
Desvantagens
- As réplicas são somente leitura, então todas as transações de escrita devem ir para o nó primário.
- Se a conexão de rede falhar, o atraso pode aumentar significativamente.
Replicação Lógica
A replicação lógica transfere alterações de nível de dados em vez de dados de WAL de baixo nível. Ele permite a replicação seletiva, onde apenas tabelas específicas ou partes de um banco de dados são replicadas. A replicação lógica usa um processo de decodificação lógica para converter as alterações de WAL em alterações semelhantes a SQL.
Vantagens
- Permite a replicação seletiva de tabelas ou esquemas específicos.
- Suporta réplicas graváveis com opções de resolução de conflitos.
Desvantagens
- Maior latência devido ao overhead de decodificação lógica.
- Menos eficiente do que a replicação em streaming para grandes conjuntos de dados.
Como ocorre o Atraso na Replicação
O atraso na replicação ocorre quando a taxa na qual as alterações são geradas no servidor primário excede a taxa na qual podem ser processadas e aplicadas ao servidor de réplica. Esse desequilíbrio pode ocorrer devido a vários fatores subjacentes, cada um contribuindo para atrasos na sincronização de dados. As causas mais comuns de atraso na replicação são:
Latência de Rede
A latência de rede refere-se ao tempo que os dados levam para viajar do servidor primário para o servidor de réplica. Segmentos de WAL (Write-Ahead Log) são continuamente transmitidos pela rede durante a replicação em streaming. Mesmos pequenos atrasos na transmissão pela rede podem se acumular, causando atrasos na réplica.
Causas
- Altos tempos de ida e volta de rede (RTT).
- Mais largura de banda para lidar com grandes volumes de dados de WAL.
- Congestionamento de rede ou perda de pacotes.
Se o servidor primário gerar mudanças significativas durante o tráfego de pico, uma rede lenta ou sobrecarregada pode causar um gargalo, impedindo que a réplica receba as alterações do WAL.
Solução
Use conexões de rede de baixa latência e alta largura de banda e ative a compressão do WAL (wal_compression = on) para reduzir o tamanho dos dados durante a transmissão.
Gargalos de I/O
Gargalos de I/O ocorrem quando o disco de um servidor réplica é muito lento para gravar as alterações do WAL que chegam. A replicação em streaming depende da gravação das alterações no disco antes que sejam aplicadas, portanto, quaisquer atrasos no subsistema de I/O podem causar acúmulo de atraso.
Causas
- Discos rígidos lentos ou sobrecarregados (HDDs).
- Throughput de gravação em disco insuficiente.
- Contenção de disco por outros processos.
- Se o servidor réplica usar discos giratórios (HDD) em vez de unidades de estado sólido (SSD), as alterações do WAL podem não ser gravadas rapidamente o suficiente para acompanhar as mudanças de dados, fazendo com que a réplica fique atrás do primário.
Solução
Para otimizar o I/O de disco de uma réplica, use SSDs para velocidades de gravação mais rápidas e isole os processos de replicação de outras tarefas intensivas em disco.
Restrições de CPU/Memória
Os processos de replicação requerem CPU e memória para decodificar, escrever e aplicar mudanças. Se um servidor de réplica não tiver poder de processamento ou memória suficientes, pode ter dificuldade em acompanhar as modificações recebidas, resultando em atraso na replicação.
Causas
- Núcleos de CPU limitados ou processadores lentos.
- Memória insuficiente para buffers WAL.
- Outros processos consomem recursos de CPU ou memória.
- Se a réplica estiver processando transações grandes ou executando consultas junto com a replicação, a CPU pode ficar sobrecarregada, retardando o processo de replicação.
Solução
Alocar mais núcleos de CPU e memória para o servidor de réplica. Aumentar o tamanho dos wal_buffers para melhorar a eficiência no processamento de WAL.
Cargas de Trabalho Intensas no Servidor Primário
O atraso na replicação também pode ocorrer quando o servidor primário gera muitas mudanças muito rapidamente para a réplica lidar. Transações grandes, inserções em massa ou atualizações frequentes podem sobrecarregar a replicação.
Causas
- Importações de dados em massa ou transações grandes.
- Atualizações de alta frequência em tabelas grandes.
- Cargas de trabalho de alta concorrência no primário.
- A carga de transação pode ser muito pesada se o servidor primário processar múltiplas transações grandes simultaneamente, como durante uma importação de dados em massa. O volume de dados do WAL pode exceder o que a réplica pode processar em tempo real, aumentando o atraso.
Solução
Otimizar transações agrupando mais atualizações menores e evitando transações de longa duração. Se a sincronização estrita não for crítica, utilize a replicação assíncrona para reduzir a carga de replicação.
Conflito de Recursos
O conflito de recursos ocorre quando vários processos competem pelos mesmos recursos, como CPU, memória ou E/S de disco. Isso pode acontecer tanto no servidor primário quanto no servidor de réplica e levar a atrasos no processamento de replicação.
Causas
- Outros processos consomem E/S de disco, CPU ou memória.
- Tarefas em segundo plano, como backups ou análises em execução simultânea.
- Conflito de rede entre o tráfego de replicação e outras transferências de dados.
- Se o servidor de réplica também executar backups ou consultas analíticas, a competição por CPU e recursos de disco pode retardar o processo de replicação.
Solução
Isolar cargas de trabalho de replicação de outros processos intensivos em recursos. Agende backups e análises durante horários de menor movimento para evitar interferência na replicação.
Fórmula Matemática para Atraso de Replicação
Utilize a seguinte fórmula para calcular o atraso de replicação:

Na replicação lógica, tempo adicional é consumido pela decodificação lógica:

Monitoramento do Atraso de Replicação
Monitoramento da Replicação em Streaming
A visualização pg_stat_replication pode ser usada para monitorar o atraso na replicação em streaming. Ele fornece insights sobre o estado e a diferença entre os servidores primário e replica.
SELECT application_name, state,
pg_size_pretty(sent_lsn - write_lsn) AS lag_bytes,
sync_state
FROM pg_stat_replication;
sent_lsn: Última localização do WAL enviada para o replica.write_lsn: Última localização do WAL gravada no replica.lag_bytes: A diferença entre os dois indica o atraso.
Monitoramento de Replicação Lógica
Replicação lógica pode ser monitorada usando a visualização pg_stat_subscription.
SELECT subscription_name, active,
pg_size_pretty(pg_current_wal_lsn() - replay_lsn) AS lag_bytes
FROM pg_stat_subscription;
Exemplo: Visualizando o Atraso na Replicação
O trecho de código Python a seguir visualiza o atraso na replicação em streaming e lógica ao longo do tempo.
import matplotlib.pyplot as plt
time = ['12:00', '12:10', '12:20', '12:30', '12:40', '12:50', '13:00']
streaming_lag = [0.5, 0.6, 0.4, 0.7, 1.0, 0.9, 0.6]
logical_lag = [2.0, 2.5, 3.0, 2.8, 3.5, 4.0, 3.2]
plt.plot(time, streaming_lag, label='Streaming Replication Lag', marker='o')
plt.plot(time, logical_lag, label='Logical Replication Lag', marker='s')
plt.xlabel('Time')
plt.ylabel('Lag (seconds)')
plt.title('Replication Lag Over Time')
plt.legend()
plt.grid(True)
# Save the plot as an image file
plt.savefig('replication_lag_plot.png')
print("Plot saved as replication_lag_plot.png")
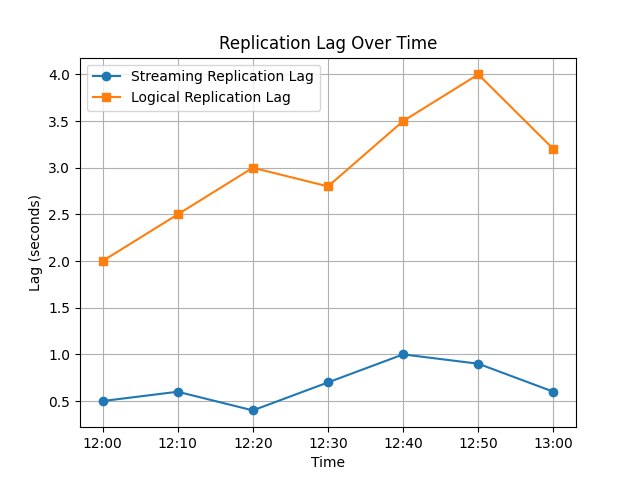
O gráfico resultante compara o desempenho da replicação em streaming e lógica. A replicação lógica tende a ter um atraso mais variável devido ao overhead de decodificação e processamento.
Como Reduzir o Atraso na Replicação
1. Otimizar a Configuração do WAL
- Aumente
wal_bufferspara armazenar mais dados do WAL na memória. - Defina
wal_writer_delaypara um valor mais baixo (por exemplo, 10ms) para escrever os dados do WAL mais rapidamente.
wal_buffers = 64MB
wal_writer_delay = 10ms
2. Melhore o Desempenho da Rede
- Use conexões de rede de baixa latência e alta largura de banda entre o primário e as réplicas.
- Comprima os dados do WAL durante a transmissão para reduzir o tempo de transferência:
wal_compression = on.
3. Utilize Replicação Assíncrona (Quando Possível)
-
A replicação assíncrona reduz o atraso por não esperar pela confirmação das alterações pela réplica, mas introduz um risco de perda de dados.
ALTER SYSTEM SET synchronous_commit = 'off';
4. Ative a Aplicação Paralela na Replicação Lógica
-
O PostgreSQL 14+ permite a aplicação paralela de alterações lógicas, reduzindo o atraso para transações grandes.
ALTER SUBSCRIPTION my_subscription SET (parallel_apply = on);
5. Aloque Mais Recursos para as Réplicas
- Certifique-se de que a réplica tenha CPU e memória suficientes para processar as alterações do WAL rapidamente.
- Use SSDs para E/S de disco mais rápida na réplica.
6. Transações em Lote
-
Agrupe várias atualizações menores em menos transações para minimizar o overhead.
Exemplos do Mundo Real
Redução do Atraso na Replicação em Tempo Real
Uma empresa que executa um cluster PostgreSQL de alto tráfego enfrentou atrasos na replicação durante o horário de pico. Eles reduziram pela metade o atraso na replicação aumentando o wal_buffers para 64MB e reduzindo o wal_writer_delay para 10ms. A mudança para uma conexão de rede de alta velocidade reduziu o atraso para menos de um segundo.
Redução do Atraso na Replicação Lógica
Um sistema com várias assinaturas lógicas experimentou atrasos durante cargas de escrita intensas. Habilitar o aplicativo paralelo no PostgreSQL 14 distribuiu a carga de trabalho entre vários trabalhadores, reduzindo o atraso na replicação de 4 segundos para menos de 1 segundo.
Conclusão
O atraso na replicação é um problema crítico que afeta o desempenho e a consistência dos sistemas PostgreSQL. A replicação em tempo real oferece baixa latência, mas requer a replicação de todo o banco de dados, enquanto a replicação lógica oferece flexibilidade, mas com um overhead maior. O monitoramento regular usando pg_stat_replication e pg_stat_subscription permite aos administradores detectar e mitigar o atraso.
Otimizar as configurações do WAL, melhorar o desempenho da rede, usar aplicações paralelas e alocar recursos suficientes podem reduzir significativamente o atraso. A sintonia adequada garante que as réplicas permaneçam sincronizadas e o sistema mantenha alta disponibilidade e desempenho.
Source:
https://dzone.com/articles/understanding-and-reducing-postgresql-replication-lag