













O que é JPA Hibernate?
Hibernate é uma das bibliotecas de Mapeamento Objeto-Relacional (ORM) mais populares para aplicações Java e Spring. Ajuda os desenvolvedores a se conectarem e trabalharem com bancos de dados relacionais a partir de aplicações Java sem a necessidade de escrever consultas SQL. A biblioteca implementa a especificação JPA (Java Persistence API) e fornece várias funcionalidades adicionais que ajudam a desenvolver a persistência nas aplicações de forma mais rápida e fácil.
Cache no JPA Hibernate
Uma das funcionalidades legais suportadas por Hibernate é a cache. Hibernate suporta dois níveis de cache — L1 e L2. O cache L1 está habilitado por padrão e funciona dentro do escopo de uma aplicação, portanto, não pode ser compartilhado entre múltiplas threads. Por exemplo, se você tem uma aplicação de microsserviço escalada que lê e escreve em uma tabela em uma configuração de banco de dados relacional, este cache L1 é mantido individualmente dentro de cada um desses contêineres onde o microsserviço está rodando.
O cache L2 é uma interface pluggable externa, através da qual podemos armazenar dados acessados com frequência em um provedor de cache externo via Hibernate. Neste caso, o cache é mantido fora da sessão e pode ser compartilhado através da pilha de microsserviços (no exemplo acima).
Hibernate suporta o cache L2 com a maioria dos provedores de cache populares como Redis, Ignite, NCache, etc.
O que é NCache?
NCache é um dos provedores de cache distribuído mais populares disponíveis no mercado. Oferece várias funcionalidades e suporte para integração com pilhas de programação populares como .NET, Java, etc.
NCache está disponível em várias versões — de código aberto, profissional e empresarial — e você pode escolher entre elas com base nas funcionalidades que oferecem.
Integrando NCache com Hibernate
O NCache suporta integração com Hibernate como Cache L2 e também para cache de consultas. Ao utilizar um cluster de cache distribuído externo, podemos garantir que entidades acessadas com frequência sejam armazenadas em cache e utilizadas em microserviços em um ambiente escalado sem colocar carga desnecessária na camada de banco de dados. Desta forma, as chamadas ao banco de dados são mantidas ao mínimo possível, e o desempenho do aplicativo é otimizado também.
Para começar, vamos adicionar os pacotes necessários ao nosso projeto Spring Boot. Para demonstrar, vou utilizar um JPA Repository que usa Hibernate ORM para trabalhar com o banco de dados relacional — configuração do MySQL.
As dependências no meu arquivo pom.xml ficam assim:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>Meu JPARepository lê e escreve em uma tabela chamada books no meu banco de dados MySQL. O repositório e a entidade se parecem com o seguinte:
package com.myjpa.helloapp.repositories;
import com.myjpa.helloapp.models.entities.Book;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BookRepository extends JpaRepository<Book, Integer> {}
package com.myjpa.helloapp.models.entities;
import jakarta.persistence.*;
import java.util.Date;
import org.hibernate.annotations.CreationTimestamp;
@Entity(name = "Book")
@Table(name = "Book")
public class Book {
@Id @GeneratedValue(strategy = GenerationType.AUTO) private int bookId;
@Column(name = "book_name") private String bookName;
@Column(name = "isbn") private String isbn;
@CreationTimestamp @Column(name = "created_date") private Date createdDate;
public Book() {}
public Book(String bookName, String isbn) {
this.bookName = bookName;
this.isbn = isbn;
}
public int getBookId() {
return bookId;
}
public String getBookName() {
return bookName;
}
public String getIsbn() {
return isbn;
}
public Date getCreatedDate() {
return createdDate;
}
}A BookService interacts with this repository and exposes GET and INSERT functionalities.
package com.myjpa.helloapp.services;
import com.myjpa.helloapp.models.entities.Book;
import com.myjpa.helloapp.repositories.BookRepository;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class BookService {
@Autowired
private BookRepository repository;
public int createNew(String bookName, String isbn) {
var book = new Book(bookName, isbn);
// salvar a entidade
repository.save(book);
// confirmar as alterações
repository.flush();
// retornar o id gerado
var bookId = book.getBookId();
return bookId;
}
public Book findBook(int id) {
var entity = repository.findById(id);
if (entity.isPresent()) {
return entity.get();
}
return null;
}
}Enquanto este setup funciona perfeitamente bem, não adicionamos nenhum cache a ele. Vamos ver como podemos integrar o caching ao Hibernate com o NCache como provedor.
Cache de Nível 2 com NCache
Para Integrar NCache com Hibernate, adicionaremos mais duas dependências ao nosso projeto. Estas são mostradas abaixo:
<dependency>
<groupId>com.alachisoft.ncache</groupId>
<artifactId>ncache-hibernate</artifactId>
<version>5.3.2</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-jcache</artifactId>
<version>6.4.2.Final</version>
</dependency>Também adicionaremos um arquivo Hibernate.cfg.xml onde configuraremos o cache de segundo nível e os detalhes abaixo:
<hibernate-configuration>
<session-factory>
<property name="hibernate.cache.use_second_level_cache">true</property>
<property name="hibernate.cache.region.factory_class">JCacheRegionFactory</property>
<property name="hibernate.javax.cache.provider" >com.alachisoft.ncache.hibernate.jcache.HibernateNCacheCachingProvider</property>
<property name="ncache.application_id">booksapi</property>
</session-factory>
</hibernate-configuration>No topo da entidade Book, adicionaremos uma anotação que definirá o status de cache para a entidade:
@Entity(name = "Book")
@Table(name = "Book")
@Cache(region = "demoCache", usage = CacheConcurrencyStrategy.READ_WRITE)
public class Book {}I’m indicating that my entities will be cached under the region demoCache, which is basically my cache cluster name.
I’d also place my client.nconf and config.nconf files, which contain information about the cache cluster and its network details in the root directory of my project.
O arquivo client.nconf se parece com o abaixo:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Client configuration file is used by client to connect to out-proc caches.
Light weight client also uses this configuration file to connect to the remote caches.
This file is automatically generated each time a new cache/cluster is created or
cache/cluster configuration settings are applied.
-->
<configuration>
<ncache-server connection-retries="5" retry-connection-delay="0" retry-interval="1"
command-retries="3" command-retry-interval="0.1" client-request-timeout="90"
connection-timeout="5" port="9800" local-server-ip="192.168.0.108" enable-keep-alive="False"
keep-alive-interval="0" />
<cache id="demoCache" client-cache-id="" client-cache-syncmode="optimistic"
skip-client-cache-if-unavailable="False" reconnect-client-cache-interval="10"
default-readthru-provider="" default-writethru-provider="" load-balance="True"
enable-client-logs="True" log-level="info">
<server name="192.168.0.108" />
</cache>
</configuration>Quando executo meu aplicativo com esta configuração e faço uma operação GET para um único livro, o Hibernate procura a entidade no cluster NCache e retorna a entidade em cache; se não estiver presente, mostra um cache miss.
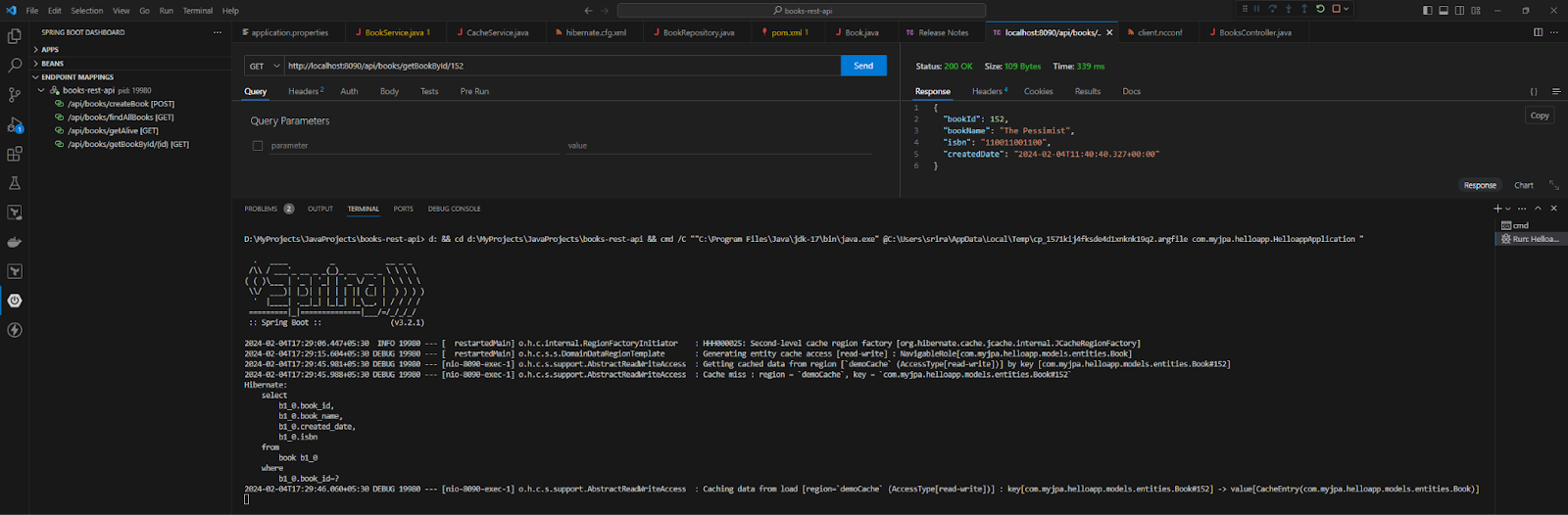
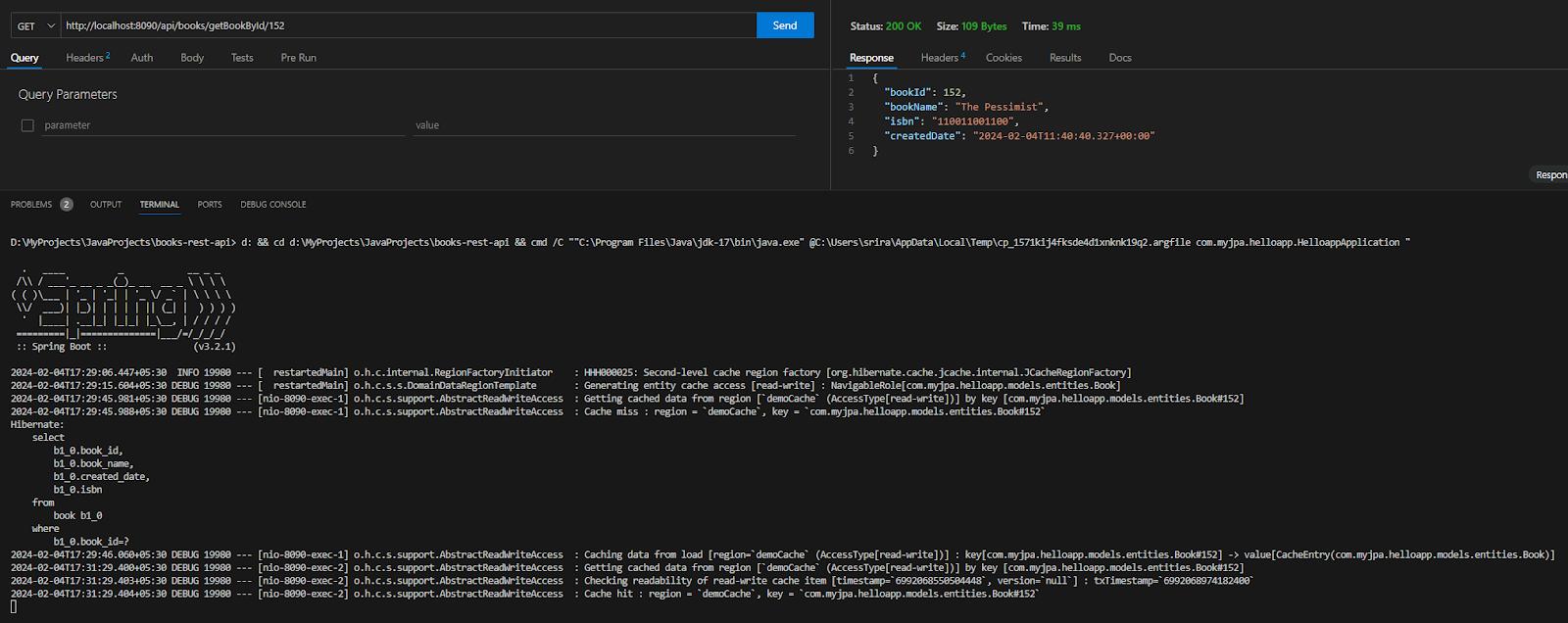
Cache de Consultas com NCache
Outra característica do Hibernate que o NCache suporta plenamente é cache de consultas. Nesta abordagem, o conjunto de resultados de uma consulta pode ser cacheado para dados acessados com frequência. Isso garante que o banco de dados não seja consultado com frequência para dados acessados com frequência. Isso é específico para consultas HQL (Hibernate Query Language).
Para habilitar o Cache de Consultas, adicionarei simplesmente outra linha ao arquivo Hibernate.cfg.xml abaixo:
<property name="hibernate.cache.use_query_cache">true</property>No repositório, criarei outro método que executará uma consulta específica, e o resultado será cacheado.
@Repository
public interface BookRepository extends JpaRepository<Book, Integer> {
@Query(value = "SELECT p FROM Book p WHERE bookName like 'T%'")
@Cacheable(value = "demoCache")
@Cache(usage = CacheConcurrencyStrategy.READ_ONLY, region = "demoCache")
@QueryHints(value = { @QueryHint(name = "org.hibernate.cacheable", value = "true") })
public List<Book> findAllBooks();
}Neste método, estou consultando todos os Livros que começam com a letra T, e o conjunto de resultados deve ser cacheado. Para isso, adicionarei uma dica de consulta que definirá o cache como verdadeiro.
Quando acessarmos a API que chama este método, podemos ver que todo o conjunto de dados agora está cacheado.
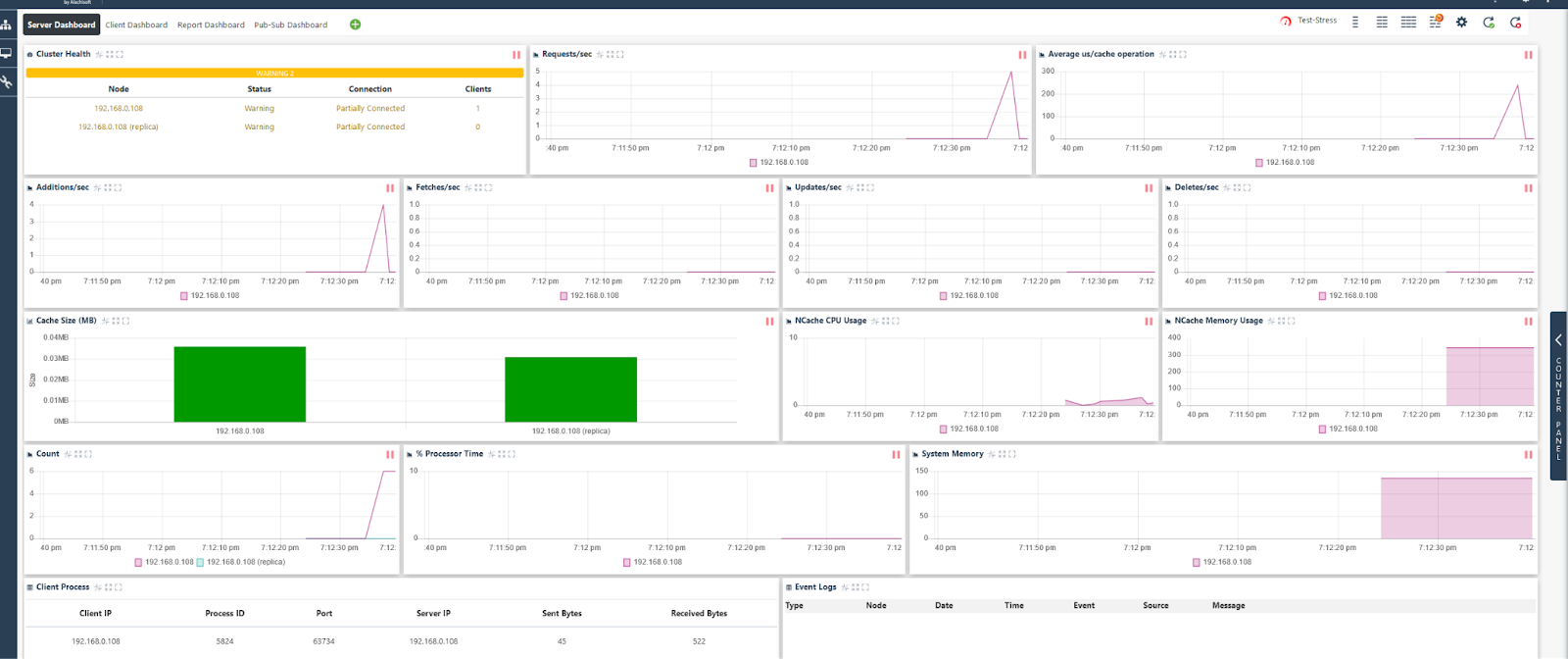
Conclusão
O cache é uma das estratégias mais utilizadas na construção de aplicativos distribuídos. Em uma arquitetura de microserviços, onde um aplicativo é dimensionado X vezes com base na carga, acessar frequentemente um banco de dados para obter dados pode ser dispendioso.
Provedores de cache como NCache oferecem uma solução fácil e plugável para microserviços Java que usam Hibernate para consultar bancos de dados. Neste artigo, vimos como usar o NCache como um Cache L2 para Hibernate e como utilizá-lo para cachear entidades individuais e cache de consultas.
Source:
https://dzone.com/articles/how-to-integrate-ncache-with-jpa-hibernate-for-cac