













Shift-left é uma abordagem para o desenvolvimento e operações de software que enfatiza testes, monitoramento e automação desde o início do ciclo de vida do desenvolvimento de software. O objetivo da abordagem shift-left é evitar problemas antes que surjam, detectando-os cedo e resolvendo-os rapidamente.
Quando você identifica um problema de escalabilidade ou um bug desde o início, é mais rápido e econômico resolvê-lo. Mover código ineficiente para contêineres em nuvem pode ser caro, pois pode ativar a escalabilidade automática e aumentar sua conta mensal. Além disso, você estará em estado de emergência até conseguir identificar, isolar e corrigir o problema.
A Declaração do Problema
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
Esta é a linha do tempo dos eventos.
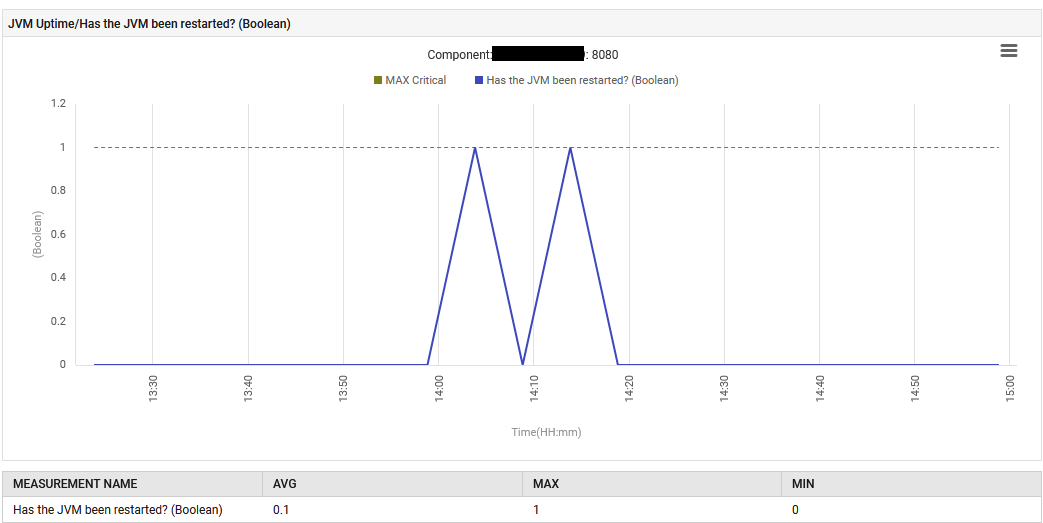
Em 6 de agosto às 14:13, o aplicativo foi reiniciado com um novo arquivo jar do Spring Boot contendo um Tomcat embutido.
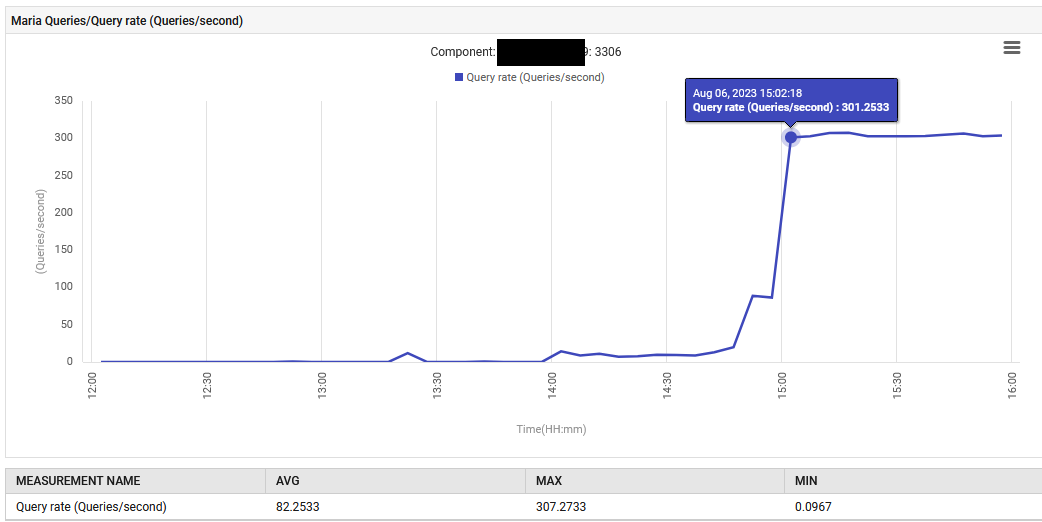
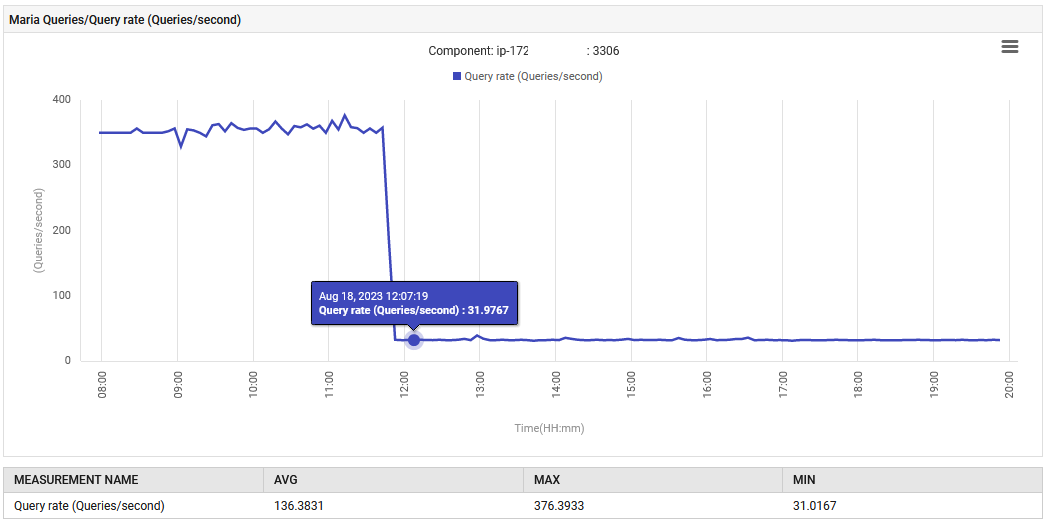
Às 14:52, a taxa de processamento de consultas para o MariaDB aumentou de 0,1 para 88 consultas por segundo e depois para 301 consultas por segundo.
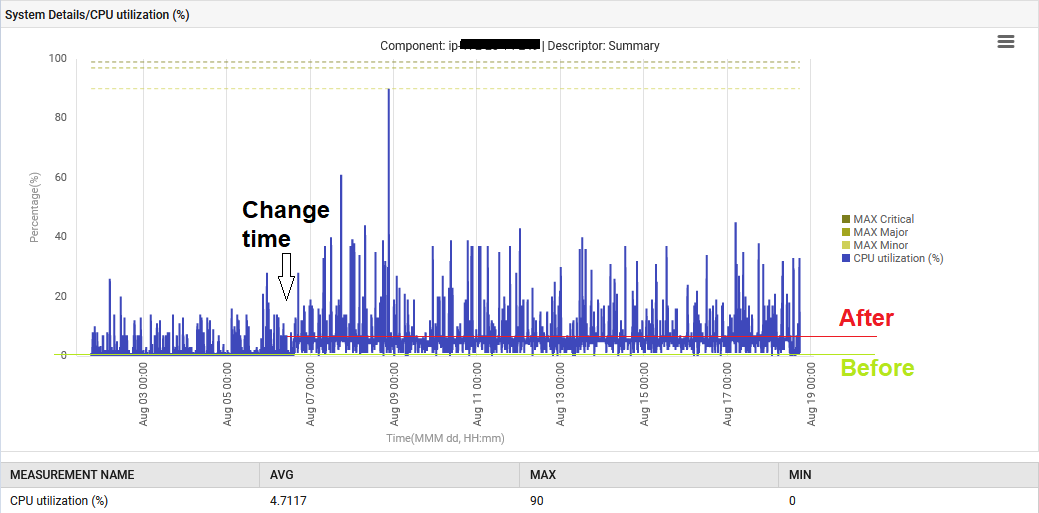
Além disso, a CPU do sistema foi elevada de 1% para 6%.
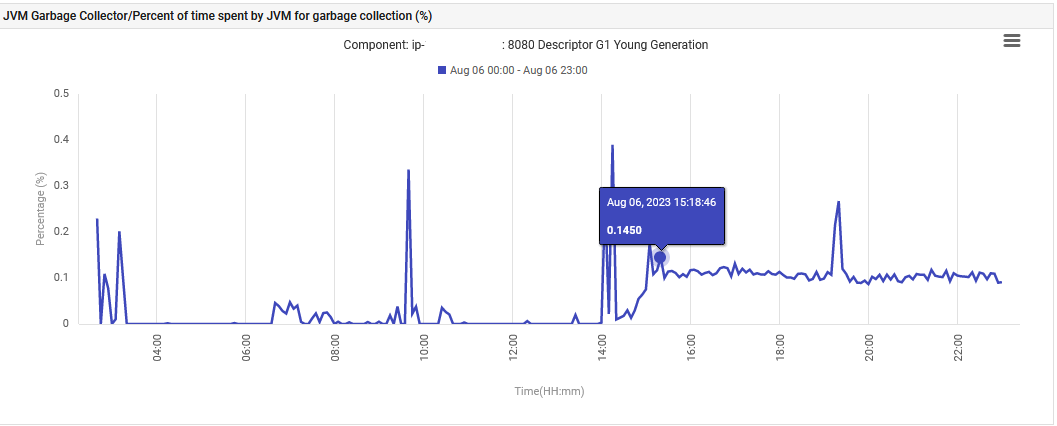
Por fim, o tempo gasto pelo JVM na Geração Jovem do Garbage Collection aumentou de 0% para 0,1% e permaneceu nesse nível.
A aplicação, em sua fase de UAT, está emitindo de forma anormal 300 consultas por segundo, o que está muito além do que foi projetado para fazer. O novo recurso causou um aumento na conexão com o banco de dados, razão pela qual o aumento nas consultas é tão drástico. No entanto, o painel de monitoramento mostrou que as medidas problemáticas eram normais antes da implantação da nova versão.
A Resolução
Trata-se de uma aplicação Spring Boot que usa JPA para consultar um MariaDB. A aplicação foi projetada para rodar em dois contêineres para um carregamento mínimo, mas é esperado que possa escalar até dez.
Se um único contêiner pode gerar 300 consultas por segundo, ele poderá lidar com 3000 consultas por segundo se todos os dez contêineres estiverem operacionais? O banco de dados terá conexões suficientes para atender às necessidades das outras partes da aplicação?
Não tínhamos outra escolha senão voltar à mesa do desenvolvedor para inspecionar as alterações no Git.
A nova mudança levará algumas registros de uma tabela e processá-los. Foi isso que observamos no serviço classe.
List<X> findAll = this.xRepository.findAll();
Não, usar o método findAll() sem paginação no CrudRepository do Spring não é eficiente. A paginação ajuda a reduzir o tempo necessário para recuperar dados do banco de dados limitando a quantidade de dados buscados. Isso é o que nosso ensino primário em RDBMS nos ensinou. Além disso, a paginação ajuda a manter o uso de memória baixo para evitar que o aplicativo trave devido a uma sobrecarga de dados, bem como reduzir o esforço de coleta de lixo da Java Virtual Machine, conforme mencionado no problema acima.
Este teste foi realizado usando apenas 2.000 registros em um único contêiner. Se este código fosse para produção, onde existem cerca de 200.000 registros em até 10 contêineres, poderia causar muita estresse e preocupação à equipe naquele dia.
O aplicativo foi reconstruído com a adição de uma cláusula WHERE ao método.
List<X> findAll = this.xRepository.findAllByY(Y);
O funcionamento normal foi restaurado. O número de consultas por segundo diminuiu de 300 para 30, e o esforço colocado na coleta de lixo retornou ao nível original. Além disso, o uso de CPU do sistema diminuiu.
Aprendizado e Resumo
Qualquer pessoa que trabalha em Engenharia de Confiabilidade de Sites (SRE) vai apreciar a importância desta descoberta. Fomos capazes de agir sobre ela sem precisar levantar uma bandeira de Gravidade 1. Se este pacote defeituoso tivesse sido implantado em produção, poderia ter ativado o limiar de auto-dimensionamento do cliente, resultando em novos contêineres sendo lançados mesmo sem uma carga adicional de usuários.
Há três principais lições a serem tiradas desta história.
Primeiro, é uma boa prática ativar uma solução de observabilidade desde o início, pois ela pode fornecer um histórico de eventos que pode ser usado para identificar potenciais problemas. Sem este histórico, eu poderia não ter levado a sério uma porcentagem de Garbage Collection de 0,1% e um consumo de CPU de 6%, e o código poderia ter sido lançado em produção com consequências desastrosas. Ampliar o escopo da solução de monitoramento para servidores de UAT ajudou a equipe a identificar potenciais causas raiz e prevenir problemas antes que ocorram.
Em segundo lugar, casos de teste relacionados à performance devem existir no processo de teste, e estes devem ser revisados por alguém com experiência em observabilidade. Isso garantirá que a funcionalidade do código seja testada, bem como sua performance.
Terceiro, técnicas de rastreamento de performance nativas da nuvem são boas para receber alertas sobre alta utilização, disponibilidade, etc. Para alcançar observabilidade, você pode precisar ter as ferramentas e expertise adequadas em vigor. Happy Coding!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c