













Em uma era caracterizada por um aumento exponencial na geração de dados, as organizações devem aproveitar efetivamente essa riqueza de informações para manter sua vantagem competitiva. Pesquisar e analisar dados de clientes de forma eficiente — como identificar as preferências dos usuários para recomendações de filmes ou análise de sentimentos — desempenha um papel crucial na tomada de decisões informadas e na melhoria das experiências dos usuários. Por exemplo, um serviço de streaming pode empregar busca vetorial para recomendar filmes adaptados aos históricos de visualização e avaliações individuais, enquanto uma marca de varejo pode analisar os sentimentos dos clientes para ajustar suas estratégias de marketing.
Como engenheiros de dados, temos a tarefa de implementar essas soluções sofisticadas, garantindo que as organizações possam extrair insights acionáveis de vastos conjuntos de dados. Este artigo explora as complexidades da busca vetorial usando Elasticsearch, focando em técnicas eficazes e melhores práticas para otimizar o desempenho. Ao examinar estudos de caso sobre recuperação de imagens para marketing personalizado e análise de texto para agrupamento de sentimentos dos clientes, demonstramos como a otimização da busca vetorial pode levar a interações melhoradas com os clientes e um crescimento significativo nos negócios.
O que é busca vetorial?
A busca vetorial é um método poderoso para identificar semelhanças entre pontos de dados ao representá-los como vetores em um espaço de alta dimensão. Essa abordagem é particularmente útil para aplicações que exigem recuperação rápida de itens semelhantes com base em seus atributos.
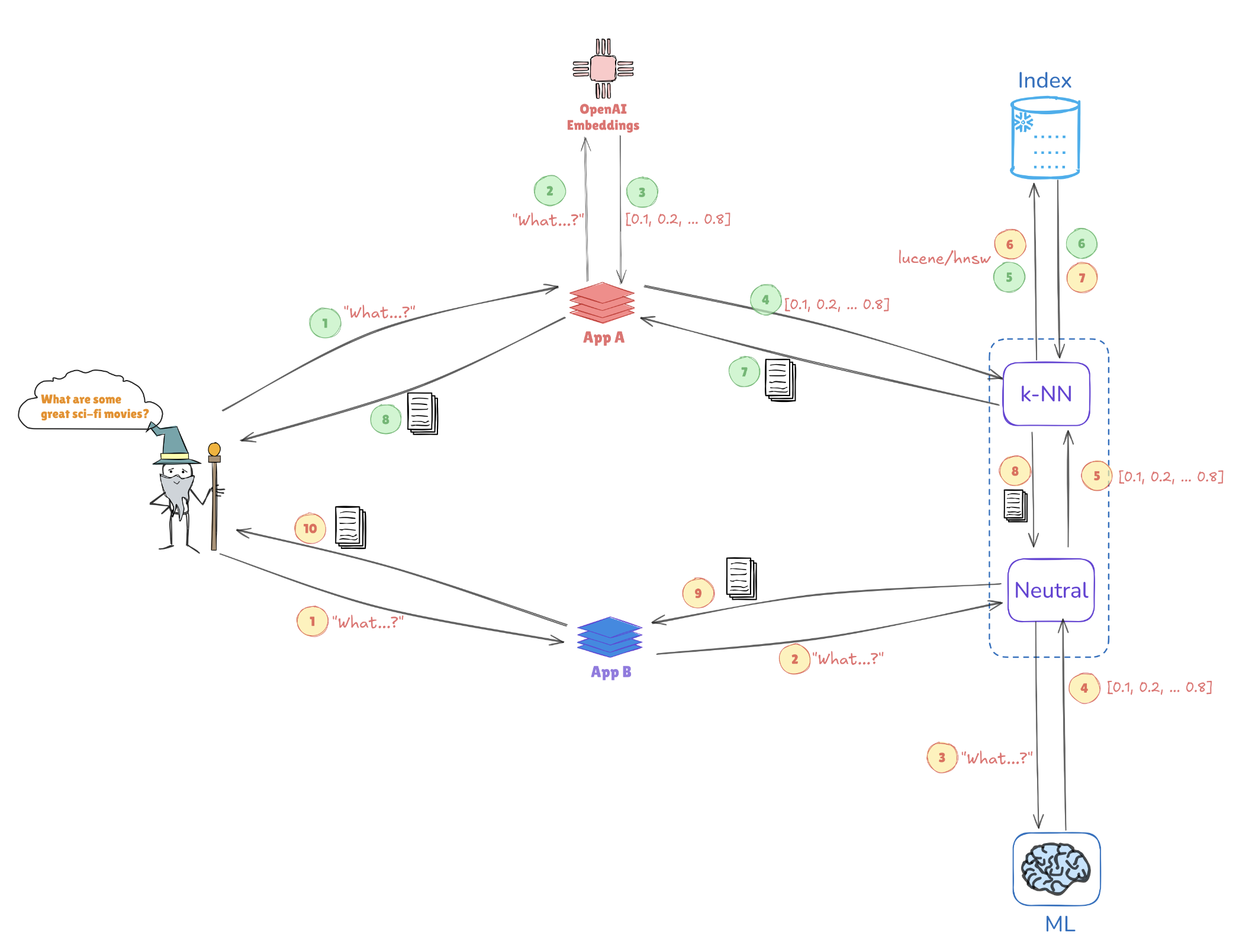
Ilustração da Busca Vetorial
Considere a ilustração abaixo, que retrata como as representações vetoriais possibilitam buscas por semelhança:
- Embutimentos de consulta: A consulta “Quais são alguns ótimos filmes de ficção científica?” é convertida em uma representação vetorial, como [0.1, 0.2, …, 0.4].
- Indexação: Esse vetor é comparado com vetores pré-indexados armazenados no Elasticsearch (por exemplo, de aplicações como AppA e AppB) para encontrar consultas ou pontos de dados semelhantes.
- Busca k-NN: Usando algoritmos como k-Vizinhos Mais Próximos (k-NN), o Elasticsearch recupera de forma eficiente as melhores correspondências dos vetores indexados, ajudando a identificar as informações mais relevantes rapidamente.
Esse mecanismo permite que o Elasticsearch se destaque em casos de uso como sistemas de recomendação, buscas de imagens e processamento de linguagem natural, onde entender o contexto e a semelhança é fundamental.
Principais Benefícios da Busca Vetorial Com Elasticsearch
Suporte a Alta Dimensionalidade
O Elasticsearch se destaca na gestão de estruturas de dados complexas, essenciais para aplicações de IA e aprendizado de máquina. Essa capacidade é crucial ao lidar com tipos de dados multifacetados, como imagens ou dados textuais.
Escalabilidade
A sua arquitetura suporta escalabilidade horizontal, permitindo que as organizações lidem com conjuntos de dados em constante expansão sem sacrificar o desempenho. Isso é vital à medida que os volumes de dados continuam a crescer.
Integração
O Elasticsearch funciona perfeitamente com a stack Elastic, fornecendo uma solução abrangente para ingestão, análise e visualização de dados. Essa integração garante que os engenheiros de dados possam aproveitar uma plataforma unificada para diversas tarefas de processamento de dados.
Melhores Práticas para Otimizar o Desempenho da Busca Vetorial
1. Reduzir Dimensões do Vetor
A redução da dimensionalidade dos seus vetores pode melhorar significativamente o desempenho da busca. Técnicas como PCA (Análise de Componentes Principais) ou UMAP (Aproximação e Projeção de Variedades Uniformes) ajudam a manter características essenciais enquanto simplificam a estrutura dos dados.
Exemplo: Redução de Dimensionalidade com PCA
Aqui está como implementar PCA em Python usando Scikit-learn:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. Indexar Eficientemente
Utilizar algoritmos de Vizinhos Mais Próximos Aproximados (ANN) pode acelerar significativamente os tempos de busca. Considere usar:
- HNSW (Mundo Pequeno Navegável Hierárquico): Conhecido por seu equilíbrio entre desempenho e precisão.
- FAISS (Pesquisa de Similaridade da AI do Facebook): Otimizado para grandes conjuntos de dados e capaz de utilizar aceleração por GPU.
Exemplo: Implementando HNSW no Elasticsearch
Você pode definir as configurações do seu índice no Elasticsearch para utilizar HNSW da seguinte forma:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. Consultas em Lote
Para aumentar a eficiência, o processamento em lote de múltiplas consultas em uma única solicitação minimiza a sobrecarga. Isso é particularmente útil para aplicativos com alto tráfego de usuários.
Exemplo: Processamento em Lote no Elasticsearch
Você pode usar o endpoint _msearch para consultas em lote:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. Use Cache
Implemente estratégias de cache para consultas frequentemente acessadas para diminuir a carga computacional e melhorar os tempos de resposta.
5. Monitore o Desempenho
Analisar regularmente as métricas de desempenho é crucial para identificar gargalos. Ferramentas como Kibana podem ajudar a visualizar esses dados, permitindo ajustes informados na configuração do seu Elasticsearch.
Ajustando Parâmetros no HNSW para Desempenho Aprimorado
Otimizar HNSW envolve ajustar certos parâmetros para alcançar melhor desempenho em grandes conjuntos de dados:
M(número máximo de conexões): Aumentar este valor melhora a recuperação, mas pode exigir mais memória.EfConstruction(tamanho da lista dinâmica durante a construção): Um valor mais alto leva a um grafo mais preciso, mas pode aumentar o tempo de indexação.EfSearch(tamanho dinâmico da lista durante a busca): Ajustar isso afeta a troca entre velocidade e precisão; um valor maior resulta em melhor recuperação, mas leva mais tempo para computar.
Exemplo: Ajustando Parâmetros HNSW
Você pode ajustar os parâmetros HNSW na criação do seu índice assim:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
Estudo de Caso: Impacto da Redução de Dimensionalidade no Desempenho do HNSW em Aplicações de Dados de Clientes
Recuperação de Imagens para Marketing Personalizado
Técnicas de redução de dimensionalidade desempenham um papel fundamental na otimização de sistemas de recuperação de imagens em aplicações de dados de clientes. Em um estudo, pesquisadores aplicaram Análise de Componentes Principais (PCA) para reduzir a dimensionalidade antes de indexar imagens com redes Hierarchical Navigable Small World (HNSW). A PCA proporcionou um aumento notável na velocidade de recuperação — vital para aplicações que lidam com altos volumes de dados de clientes — embora isso tenha ocorrido à custa de uma leve perda de precisão devido à redução de informações. Para enfrentar isso, os pesquisadores também examinaram a Aproximação e Projeção de Manifolds Uniformes (UMAP) como uma alternativa. A UMAP preservou estruturas de dados locais de forma mais eficaz, mantendo os detalhes intrincados necessários para recomendações de marketing personalizadas. Embora a UMAP exigisse maior poder computacional do que a PCA, ela equilibrava a velocidade de busca com alta precisão, tornando-se uma escolha viável para tarefas críticas de precisão.
Análise de Texto para Agrupamento de Sentimentos de Clientes
No campo da análise de sentimento do cliente, um estudo diferente descobriu que UMAP superou o PCA na clusterização de dados de texto semelhantes. UMAP permitiu que o modelo HNSW agrupasse sentimentos de clientes com maior precisão — uma vantagem na compreensão do feedback do cliente e na entrega de respostas mais personalizadas. O uso do UMAP facilitou valores menores de EfSearch no HNSW, aprimorando a velocidade e precisão da busca. Essa melhoria na eficiência de clusterização possibilitou a identificação mais rápida de sentimentos de clientes relevantes, aprimorando os esforços de marketing direcionado e a segmentação de clientes com base no sentimento.
Integrando Técnicas de Otimização Automatizadas
Optimizar a redução de dimensionalidade e os parâmetros do HNSW é essencial para maximizar o desempenho dos sistemas de dados do cliente. As técnicas de otimização automatizadas simplificam esse processo de ajuste, garantindo que as configurações selecionadas sejam eficazes em diversas aplicações:
- Busca em grade e aleatória: Esses métodos oferecem uma exploração ampla e sistemática de parâmetros, identificando configurações adequadas de forma eficiente.
- Otimização Bayesiana: Esta técnica foca nos parâmetros ótimos com menos avaliações, conservando recursos computacionais.
- Validação cruzada: A validação cruzada ajuda a validar parâmetros em diversos conjuntos de dados, garantindo sua generalização para diferentes contextos de dados de clientes.
Abordando Desafios na Automação
Integrar automação dentro de fluxos de trabalho de redução de dimensionalidade e HNSW pode introduzir desafios, particularmente na gestão das demandas computacionais e na prevenção do overfitting. Estratégias para superar esses desafios incluem:
- Redução da sobrecarga computacional: O uso de processamento paralelo para distribuir a carga de trabalho reduz o tempo de otimização, aumentando a eficiência do fluxo de trabalho.
- Integração modular: Uma abordagem modular facilita a integração sem costura de sistemas automatizados em fluxos de trabalho existentes, reduzindo a complexidade.
- Prevenção do overfitting: Validação robusta através de validação cruzada garante que os parâmetros otimizados apresentem desempenho consistente em conjuntos de dados, minimizando o overfitting e aumentando a escalabilidade em aplicações de dados de clientes.
Conclusão
Para aproveitar plenamente o desempenho da busca vetorial no Elasticsearch, adotar uma estratégia que combine redução de dimensionalidade, indexação eficiente e ajuste cuidadoso de parâmetros é essencial. Ao integrar essas técnicas, engenheiros de dados podem criar um sistema de recuperação de dados altamente responsivo e preciso. Métodos de otimização automatizados ainda elevam esse processo, permitindo o refinamento contínuo de parâmetros de busca e estratégias de indexação. À medida que as organizações dependem cada vez mais de insights em tempo real de vastos conjuntos de dados, essas otimizações podem melhorar significativamente as capacidades de tomada de decisão, oferecendo resultados de busca mais rápidos e relevantes. Abraçar essa abordagem prepara o terreno para escalabilidade futura e melhor responsividade, alinhando as capacidades de busca com as demandas comerciais em evolução e o crescimento dos dados.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch