













Os grandes dados evoluíram significativamente desde sua criação no final da década de 2000. Muitas organizações rapidamente se adaptaram à tendência e construíram suas plataformas de big data usando ferramentas de código aberto como o Apache Hadoop. Mais tarde, essas empresas começaram a enfrentar dificuldades em gerenciar as necessidades de processamento de dados em rápida evolução. Elas enfrentaram desafios ao lidar com mudanças no nível do esquema, evolução do esquema de partição e voltar no tempo para examinar os dados.
Eu enfrentei desafios semelhantes ao projetar sistemas distribuídos em larga escala na década de 2010 para uma grande empresa de tecnologia e um cliente do setor de saúde. Algumas indústrias precisam dessas capacidades para aderir às regulamentações de bancos, finanças e saúde. Empresas fortemente orientadas a dados, como a Netflix, enfrentaram desafios semelhantes. Elas inventaram um formato de tabela chamado “Iceberg,” que se assenta sobre os arquivos de dados existentes e entrega recursos chave aproveitando sua arquitetura. Isso rapidamente se tornou o principal projeto da ASF à medida que ganhou interesse rápido na comunidade de dados. Neste artigo, explorarei os 5 principais recursos chave do Apache Iceberg com exemplos e diagramas.
1. Viagem no Tempo

Figura 1: Viagem no tempo no formato de tabela Apache Iceberg (imagem criada pelo autor)
Este recurso permite que você consulte seus dados conforme eles existem em qualquer ponto. Isso abrirá novas possibilidades para os analistas de dados e de negócios entenderem tendências e como os dados evoluíram ao longo do tempo. Você pode facilmente reverter para um estado anterior em caso de erros. Este recurso também facilita verificações de auditoria, permitindo que você analise os dados em um ponto específico no tempo.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. Evolução de Esquema
A evolução de esquema do Apache Iceberg permite alterações em seu esquema sem esforço ou migrações dispendiosas. Conforme as necessidades do seu negócio evoluem, você pode:
- Adicionar e remover colunas sem tempo de inatividade ou reescrita de tabelas.
- Atualizar a coluna (alargamento).
- Alterar a ordem das colunas.
- Renomear uma coluna existente.
Essas alterações são tratadas no nível de metadados sem a necessidade de reescrever os dados subjacentes.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. Evolução de Partição
Usando o formato de tabela Apache Iceberg, você pode alterar a estratégia de particionamento da tabela sem reescrever a tabela subjacente ou migrar os dados para uma nova tabela. Isso é possível porque as consultas não fazem referência diretamente aos valores de partição como no Apache Hadoop. O Iceberg mantém informações de metadados para cada versão de partição separadamente. Isso facilita obter os splits ao consultar os dados. Por exemplo, ao consultar uma tabela com base no intervalo de datas, enquanto a tabela estava usando o mês como coluna de partição (antes) como um split e o dia como uma nova coluna de partição (depois) como outro split. Isso é chamado de planejamento de split. Veja o exemplo abaixo.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. Transações ACID
Iceberg oferece suporte robusto para transações em termos de Atomicidade, Consistência, Isolamento e Durabilidade (ACID). Ele permite múltiplas operações de escrita simultâneas, o que possibilita alta taxa de transferência em trabalhos pesados e intensivos em dados, sem comprometer a consistência dos dados.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Todas as operações no Iceberg são transacionais, o que significa que os dados permanecem consistentes, apesar de falhas ou modificações nos dados de forma concorrente.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
Ele também suporta diferentes níveis de isolamento, o que permite equilibrar desempenho e consistência com base na necessidade.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
Aqui está um resumo mostrando como o Iceberg lida com atualizações e exclusões em nível de linha.
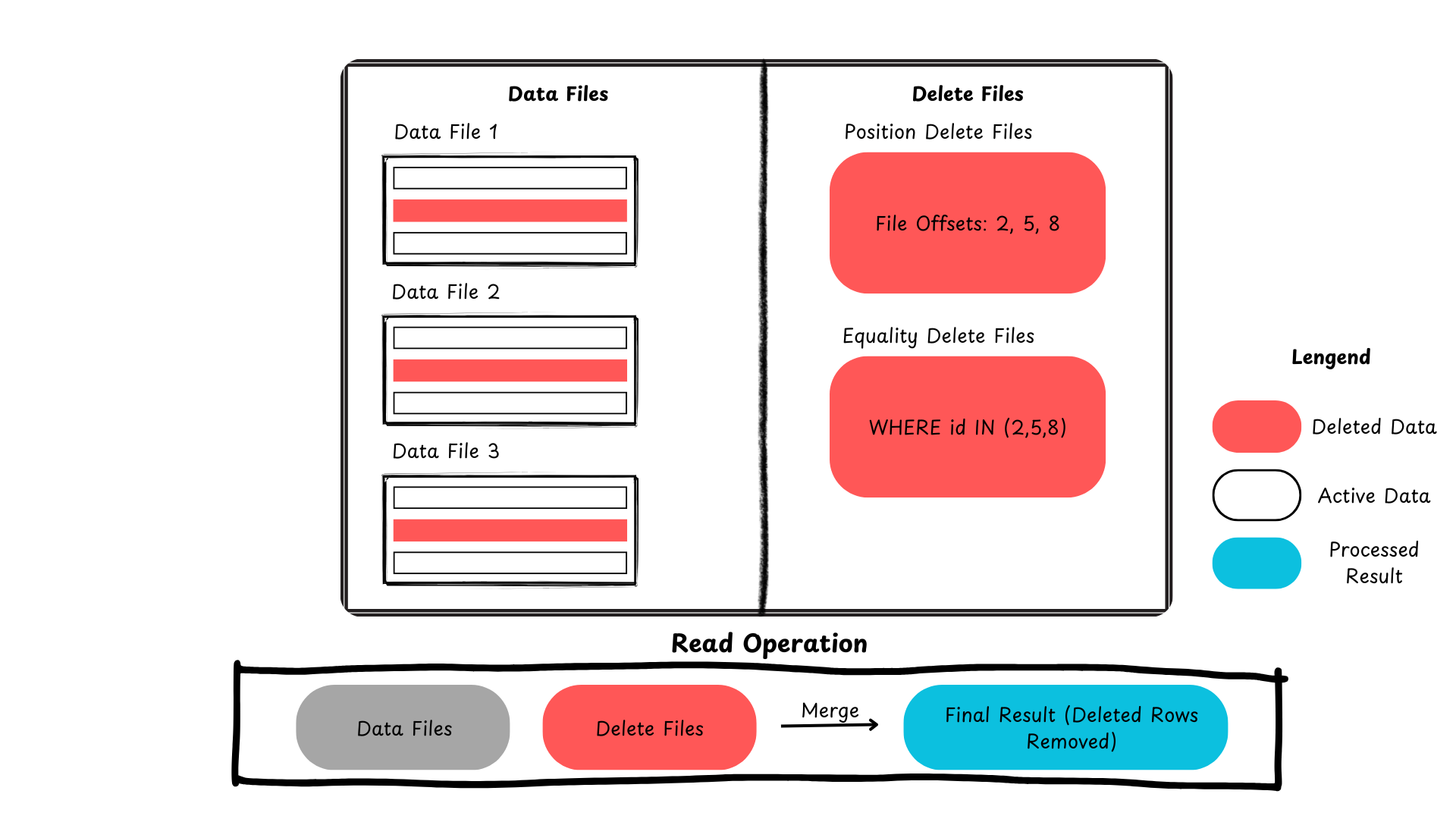
Figura 2: Processo de exclusão de registros no Apache Iceberg (imagem criada pelo autor)
5. Operações Avançadas de Tabelas
O Iceberg suporta operações avançadas de tabelas, como:
- Criação/gerenciamento de snapshots de tabelas: Isso proporciona a capacidade de ter um controle de versão robusto.
- Planejamento e execução de consultas rápidas com seus metadados altamente otimizados
- Ferramentas integradas para manutenção de tabelas, como compactação e limpeza de arquivos órfãos
O Iceberg foi projetado para trabalhar com todos os principais serviços de armazenamento em nuvem, como AWS S3, GCS e Azure Blob Storage. Além disso, o Iceberg se integra facilmente com mecanismos de processamento de dados como Spark, Presto, Trino e Hive.
Considerações Finais
Esses recursos destacados permitem que as empresas construam lagos de dados modernos, flexíveis, escaláveis e eficientes, que podem viajar no tempo, lidar facilmente com alterações de esquema, suportar transações ACID e evolução de partições.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes