













O que é o Elasticsearch?
O Elasticsearch é um poderoso e altamente escalável motor de busca e análise distribuído, construído sobre a biblioteca de busca Apache Lucene. Projetado para lidar com grandes volumes de dados estruturados, semi-estruturados e não estruturados, é ideal para uma ampla gama de casos de uso, incluindo motores de busca, análise de logs, comércio eletrônico e análise de segurança.
Elasticsearch utiliza uma arquitetura distribuída que permite armazenar e processar grandes volumes de dados em vários nós de um cluster. Os dados são indexados e armazenados em fragmentos, que são distribuídos entre os nós para melhorar a escalabilidade e a tolerância a falhas. O Elasticsearch também suporta a busca e análise em tempo real, permitindo que os usuários consultem e analisem dados praticamente em tempo real.
Uma das principais características do Elasticsearch é sua capacidade de busca poderosa. Ele suporta uma ampla gama de consultas de busca, incluindo busca de texto completo, busca geoespacial, etc. Também oferece suporte a recursos avançados de análise, como agregações, métricas e visualização de dados.
O Elasticsearch é frequentemente usado em conjunto com outras ferramentas no Elastic Stack, incluindo Logstash para coleta e processamento de dados e Kibana para visualização e análise de dados. Juntas, essas ferramentas oferecem uma solução abrangente para busca e análise que pode ser usada em uma ampla gama de aplicações e casos de uso.
O que é o Apache Lucene?
Apache Lucene é uma biblioteca de pesquisa de código aberto que oferece capacidades poderosas de pesquisa e indexação de texto. É amplamente utilizado por desenvolvedores e organizações para criar aplicativos de pesquisa, desde motores de busca até plataformas de comércio eletrônico.
Lucene funciona indexando o conteúdo de texto de documentos e armazenando o índice em um formato estruturado que pode ser pesquisado de forma eficiente. O índice é composto por uma série de listas invertidas, que fornecem mapeamentos entre termos e os documentos que os contêm. Quando uma consulta de pesquisa é submetida, Lucene usa o índice para recuperar rapidamente os documentos que correspondem à consulta.
Além de suas capacidades de pesquisa e indexação básicas, Lucene oferece uma gama de recursos avançados, incluindo suporte para pesquisa difusa e pesquisa espacial. Também fornece ferramentas para destacar resultados de pesquisa e classificar resultados de pesquisa com base na relevância.
Lucene é usado por uma ampla gama de organizações e projetos, incluindo Elasticsearch. Sua rica gama de recursos, flexibilidade e extensibilidade tornam-no uma escolha popular para a construção de aplicativos de pesquisa de todos os tipos.
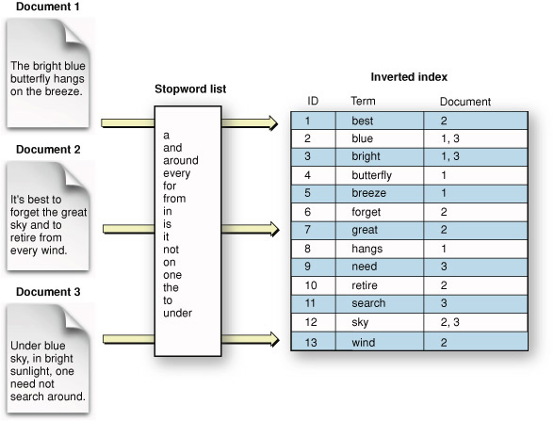
O que é Índice Invertido?
O Índice Invertido de Lucene é uma estrutura de dados usada para pesquisar e recuperar dados de texto de forma eficiente a partir de uma coleção de documentos. O Índice Invertido é uma característica central de Lucene e é usado para armazenar os termos e seus documentos associados que compõem o índice.
O Índice Invertido oferece várias vantagens em relação a outras estratégias de busca. Primeiro, permite a recuperação rápida e eficiente de documentos com base em termos de busca. Segundo, pode lidar com uma grande quantidade de dados de texto, tornando-o adequado para casos de uso com grandes coleções de documentos. Finalmente, suporta uma ampla gama de recursos avançados de busca, como correspondência aproximada e stemming, que podem melhorar a precisão e a relevância dos resultados da busca.
Por que Elasticsearch?
Existem várias razões pelas quais o Elasticsearch é uma escolha popular para construir aplicativos de busca e análise:
Fácil de escalar (Distribuído): O Elasticsearch é projetado para escalar horizontalmente fora da caixa. Sempre que precisar aumentar a capacidade, basta adicionar mais nós e deixar que o cluster se reorganize para aproveitar o hardware extra.
Um servidor pode conter uma ou mais partes de um ou mais índices, e sempre que novos nós são introduzidos ao cluster, eles são simplesmente adicionados à festa. Todo esse índice, ou parte dele, é chamado de shard, e os shards do Elasticsearch podem ser movidos facilmente pelo cluster.
Tudo está a uma chamada JSON de distância (API RESTful): O Elasticsearch é orientado a API. Quase qualquer ação pode ser realizada usando uma simples API RESTful usando JSON sobre HTTP. As respostas são sempre em formato JSON.
Poder liberado do Lucene por trás das cortinas: O Elasticsearch utiliza o Lucene internamente para construir suas capacidades de busca distribuída e análise de ponta. Como o Lucene é uma tecnologia estável e comprovada, e está sendo constantemente aprimorada com mais recursos e melhores práticas, ter o Lucene como o motor subjacente que alimenta o Elasticsearch.
Excelente DSL de Consulta: A API REST expõe um DSL de consulta muito complexo e capaz que é muito fácil de usar. Cada consulta é apenas um objeto JSON que pode conter praticamente qualquer tipo de consulta ou até várias delas combinadas. O uso de consultas filtradas, com algumas consultas expressas como filtros Lucene, ajuda a aproveitar o cache e, assim, acelerar consultas comuns ou complexas com partes que podem ser reutilizadas.
Multitenência: Múltiplos índices podem ser armazenados em uma instalação do Elasticsearch – nó ou cluster. O bom é que você pode consultar múltiplos índices com uma simples consulta.
Suporte para recursos avançados de pesquisa (Texto Completo): O Elasticsearch usa o Lucene nos bastidores para fornecer as capacidades de pesquisa de texto completo mais poderosas disponíveis em qualquer produto de código aberto. A pesquisa vem com suporte multilíngue, uma poderosa linguagem de consulta, suporte à geolocalização, sugestões did-you-mean com reconhecimento de contexto, preenchimento automático e snippets de pesquisa. Suporte a scripts em filtros e pontuadores.
Configurável e Extensível: Muitas configurações do Elasticsearch podem ser alteradas enquanto o Elasticsearch está em execução, mas algumas exigirão um reinício (e, em alguns casos, reindexação). A maioria das configurações também pode ser alterada usando a API REST.
Orientado a Documentos: Armazene entidades do mundo real complexas no Elasticsearch como documentos JSON estruturados. Todos os campos são indexados por padrão e todas as indices podem ser utilizados em uma única consulta para retornar resultados com uma velocidade impressionante.
Escala Livre: O Elasticsearch permite que você comece facilmente. Envie um documento JSON, e ele tentará detectar a estrutura dos dados, indexar os dados e torná-los pesquisáveis.
Gerenciamento de Conflitos: Controle otimista de versão pode ser usado onde necessário para garantir que os dados nunca sejam perdidos devido a alterações conflitantes de múltiplos processos.
Comunidade Ativa: A comunidade, além de criar ótimas ferramentas e plugins, é muito solidária e apoiadora. O ambiente geral é excelente, e isso é um importante indicador de qualquer projeto de SO aberto. Também existem alguns livros atualmente sendo escritos por membros da comunidade e muitos posts de blog na internet compartilhando experiências e conhecimentos.
Arquitetura do Elasticsearch
Os principais componentes da arquitetura do Elasticsearch são:
Nó: Um nó é uma instância do Elasticsearch que armazena dados e fornece capacidades de pesquisa e indexação. Os nós podem ser configurados para serem nós mestres ou nós de dados, ou ambos. Os nós mestres são responsáveis pela administração do cluster em escala, enquanto os nós de dados armazenam os dados e realizam operações de pesquisa.
Cluster: Um cluster é um grupo de um ou mais nós trabalhando juntos para armazenar e processar dados. Um cluster pode conter múltiplos indices (coleções de documentos) e réplicas (uma maneira de distribuir dados em vários nós).
Índice: Um índice é uma coleção de documentos que compartilham uma estrutura semelhante. Cada documento é representado como um objeto JSON e contém um ou mais campos. O Elasticsearch indexa todos os campos por padrão, facilitando a busca e análise de dados.
Partições (Shards): Um índice pode ser dividido em várias partições, que são essencialmente subconjuntos menores do índice. O particionamento permite o processamento paralelo de dados e armazenamento distribuído em vários nós.
Cópias (Replicas): O Elasticsearch pode criar cópias de cada partição para fornecer tolerância a falhas e alta disponibilidade. As cópias são réplicas da partição original e podem estar localizadas em diferentes nós.
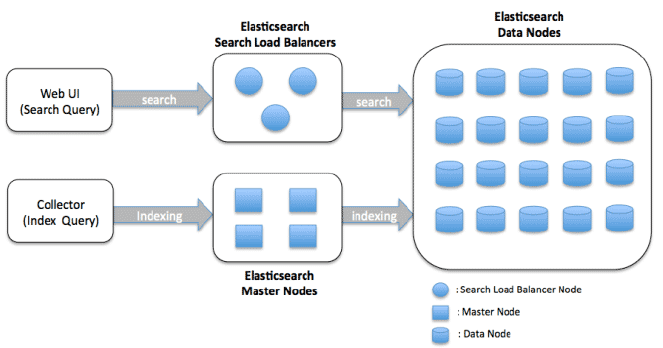
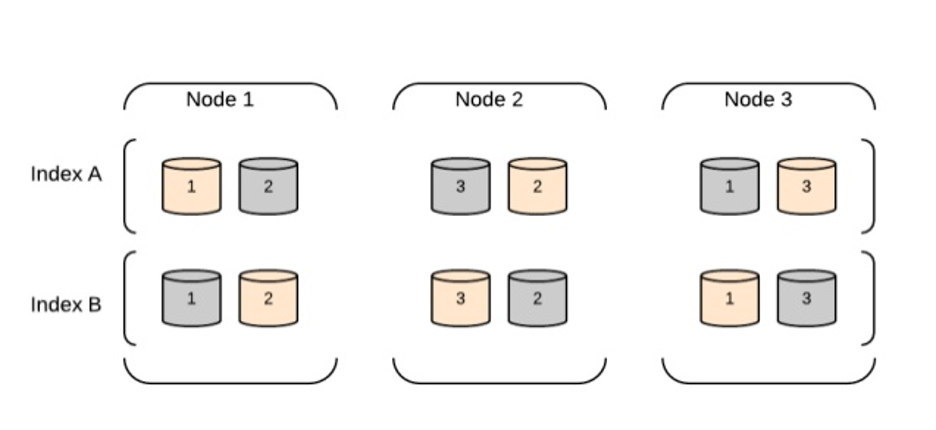
Arquitetura de Cluster de Nós de Dados
Os nós de dados são responsáveis por armazenar e indexar dados, bem como realizar operações de pesquisa e agregação. A arquitetura é projetada para ser escalável e distribuída, permitindo o escalonamento horizontal adicionando mais nós ao cluster.
Aqui estão os principais componentes de uma arquitetura de cluster de nós de dados do Elasticsearch:
Nó de Dados: Um nó é uma instância do Elasticsearch que armazena dados e fornece capacidades de pesquisa e indexação. Em um cluster de nós de dados, cada nó é responsável por armazenar uma porção dos dados do índice e atender a consultas de pesquisa contra esses dados.
Estado do Cluster: O estado do cluster é uma estrutura de dados que contém informações sobre o cluster, incluindo a lista de nós, índices, partições e suas localizações. O nó mestre é responsável por manter o estado do cluster e distribuí-lo a todos os outros nós no cluster.
Descoberta e transporte: Nós em um cluster Elasticsearch se comunicam entre si usando dois protocolos: descoberta e transporte. O protocolo de descoberta é responsável por identificar novos nós que se juntam ao cluster ou nós que deixaram o cluster. O protocolo de transporte é responsável por enviar e receber dados entre nós.
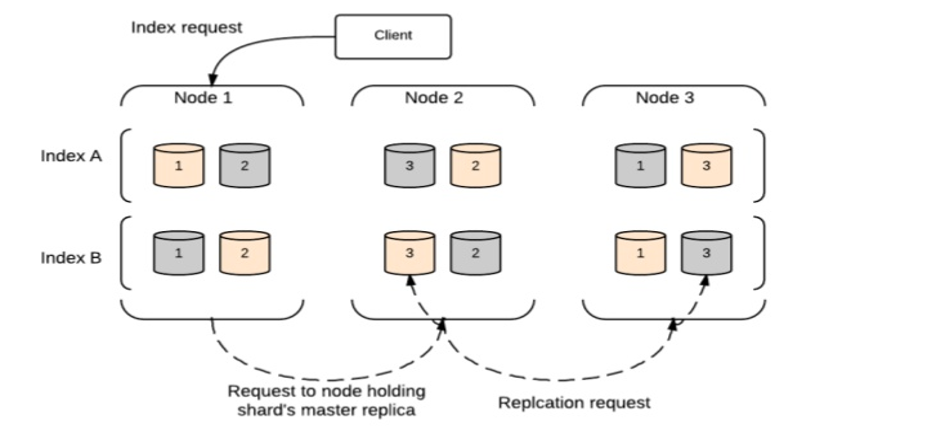
Solicitação de Índice
A solicitação de índice é executada conforme o diagrama de bloco no Elasticsearch.
Quem está usando o Elasticsearch?
Algumas empresas e organizações que usam o Elasticsearch:
Netflix: O Netflix usa o Elasticsearch para impulsionar seu mecanismo de busca e recomendações, permitindo que os usuários encontrem rapidamente conteúdo para assistir.
GitHub: O GitHub usa o Elasticsearch para oferecer capacidades de busca rápida e eficiente em seus repositórios de código, problemas e solicitações de pull.
Uber: O Uber usa o Elasticsearch para impulsionar sua plataforma de análise em tempo real, permitindo que monitore e analise dados em seu serviço de carona em tempo real.
Wikipedia: A Wikipedia usa o Elasticsearch para impulsionar seu mecanismo de busca e fornecer resultados de busca rápidos e precisos aos usuários.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1