













Isenção de responsabilidade: Todas as opiniões expressas no blog pertencem exclusivamente ao autor e não necessariamente ao empregador do autor ou a qualquer outro grupo ou indivíduo. Este artigo não é uma promoção para qualquer plataforma de gerenciamento de nuvem/dados. Todas as imagens e APIs estão publicamente disponíveis no site do Azure/Databricks.
O que é o Monitoramento do Lakehouse do Databricks?
Em meus outros artigos, descrevi o que são o Databricks e o Catálogo Unity, e como criar um catálogo do zero usando um script. Neste artigo, descreverei o recurso de Monitoramento do Lakehouse disponível como parte da plataforma Databricks e como habilitar o recurso usando scripts.
O Monitoramento do Lakehouse fornece perfis de dados e métricas relacionadas à qualidade dos dados para as Tabelas Delta Live no Lakehouse. O Monitoramento do Lakehouse do Databricks oferece uma visão abrangente dos dados, como mudanças no volume de dados, mudanças na distribuição numérica, % de nulos e zeros nas colunas, e detecção de anomalias categóricas ao longo do tempo.
Por que usar o Monitoramento do Lakehouse?
Monitorar seus dados e o desempenho do modelo de ML fornece medidas quantitativas que ajudam a rastrear e confirmar a qualidade e consistência de seus dados e do desempenho do modelo ao longo do tempo.
Aqui está uma quebra das principais características:
- Rastreamento de qualidade de dados e integridade de dados: Acompanha o fluxo de dados em pipelines, garantindo a integridade dos dados e fornecendo visibilidade sobre como os dados mudaram ao longo do tempo, 90º percentil de uma coluna numérica, % de colunas nulas e zeros, etc.
- Derivação de dados ao longo do tempo: Fornece métricas para detectar a derivação de dados entre os dados atuais e uma linha de base conhecida, ou entre janelas de tempo sucessivas dos dados
- Distribuição estatística de dados: Fornece mudança na distribuição numérica dos dados ao longo do tempo que responde sobre qual é a distribuição de valores em uma coluna categórica e como ela difere do passado
- Desempenho do modelo de ML e derivação de previsão: Entradas do modelo de ML, previsões e tendências de desempenho ao longo do tempo
Como Funciona
O Monitoramento do Lakehouse do Databricks fornece os seguintes tipos de análise: série temporal, snapshot e inferência.
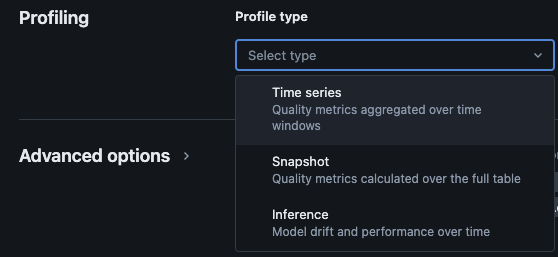
Tipos de perfil para monitoramento
Quando você habilita o monitoramento do Lakehouse para uma tabela no Catálogo Unity, ele cria duas tabelas no esquema de monitoramento especificado. Você pode consultar e criar painéis de controle (o Databricks fornece um painel de controle configurável padrão) e notificações nas tabelas para obter informações estatísticas e de perfil abrangentes sobre seus dados ao longo do tempo.
- Tabela de métricas de deriva: A tabela de métricas de deriva contém estatísticas relacionadas à deriva dos dados ao longo do tempo. Ela captura informações como diferenças na contagem, a diferença na média, a diferença em % de nulos e zeros, etc.
- Tabela de métricas de perfil: A tabela de métricas de perfil contém estatísticas resumidas para cada coluna e para cada combinação de janela de tempo, segmento e colunas de agrupamento. Para análise de InferenceLog, a tabela de análise também contém métricas de precisão do modelo.
Como Habilitar o Monitoramento do Lakehouse via Scripts
Pré-requisitos
- O Catálogo Unity, o esquema e as Tabelas Delta Live estão presentes.
- O usuário é o proprietário da Tabela Delta Live.
- Para clusters privados do Azure Databricks, a conectividade privada a partir de computação serverless está configurada.
Passo 1: Criar um Notebook e Instalar o SDK do Databricks
Crie um caderno no espaço de trabalho do Databricks. Para criar um caderno no seu espaço de trabalho, clique no “+” Novo na barra lateral e, em seguida, escolha Caderno.
Um caderno em branco será aberto no espaço de trabalho. Certifique-se de que Python esteja selecionado como o idioma do caderno.
Copie e cole o trecho de código abaixo na célula do caderno e execute a célula.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
Passo 2: Criar Variáveis
Copie e cole o trecho de código abaixo na célula do caderno e execute a célula.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
Passo 3: Criar Esquema de Monitoramento
Copie e cole o trecho de código abaixo na célula do caderno e execute a célula. Este trecho irá criar o esquema de monitoramento se ainda não existir.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
Passo 4: Criar Monitor
Copie e cole o trecho de código abaixo na célula do caderno e execute a célula. Este trecho irá criar o Monitor de Lakehouse para todas as tabelas dentro do esquema.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
Validação
Após o script ser executado com sucesso, você pode navegar até catálogo -> esquema -> tabela e ir para a aba “Qualidade” na tabela para visualizar os detalhes de monitoramento. 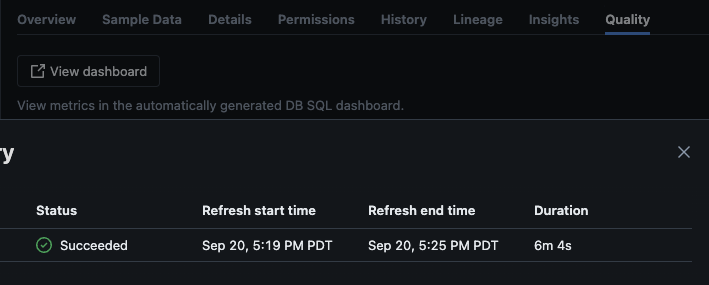
Se você clicar no botão “Visualizar painel” no canto superior esquerdo da página Monitoramento, o painel de monitoramento padrão será aberto. Inicialmente, os dados estarão em branco. Conforme o monitoramento é executado no cronograma, com o tempo ele preencherá todos os valores estatísticos, de perfil e de qualidade dos dados.
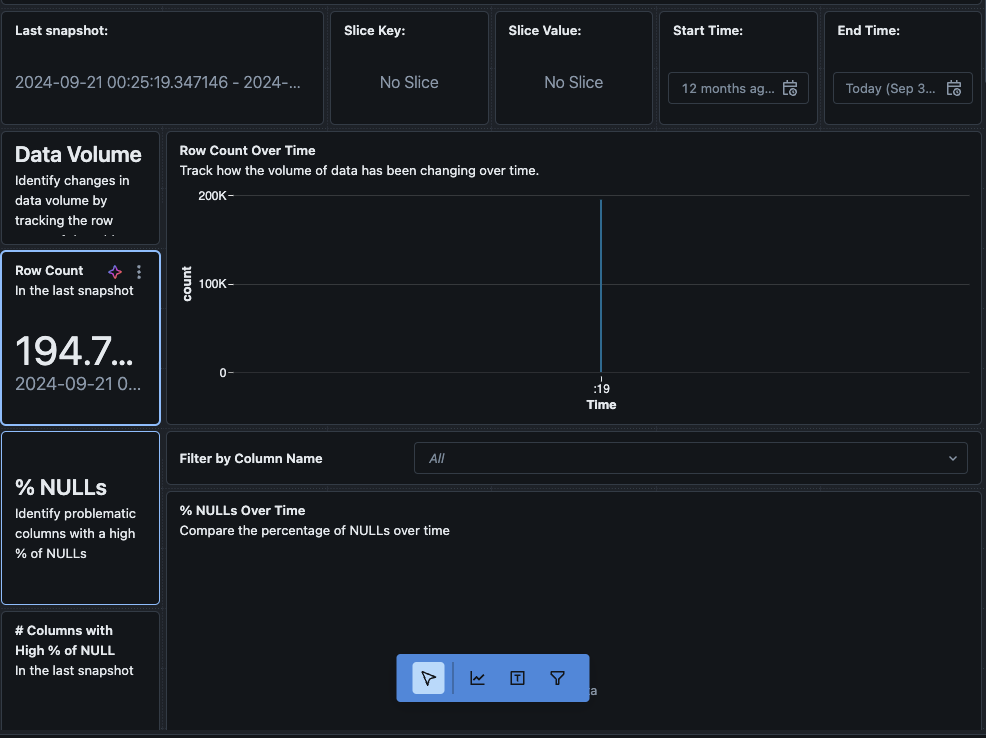
Você também pode navegar até a aba “Dados” no painel. O Databricks fornece uma lista de consultas prontas para obter a derivação e outras informações de perfil. Você também pode criar suas próprias consultas conforme sua necessidade para obter uma visão abrangente de seus dados ao longo do tempo. 
Conclusão
O Monitoramento do Lakehouse do Databricks oferece uma maneira estruturada de rastrear a qualidade dos dados, métricas de perfil e detectar derivações de dados ao longo do tempo. Ao habilitar esse recurso por meio de scripts, as equipes podem obter insights sobre o comportamento dos dados e garantir a confiabilidade de seus pipelines de dados. O processo de configuração descrito neste artigo fornece uma base para manter a integridade dos dados e apoiar os esforços contínuos de análise de dados.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring