













O autor selecionou o Fundo Livre e de Código Aberto para receber uma doação como parte do programa Write for DOnations.
Introdução
O monitoramento de banco de dados é o processo contínuo de acompanhar sistematicamente várias métricas que mostram como o banco de dados está se comportando. Observando dados de desempenho, você pode obter insights valiosos e identificar possíveis gargalos, bem como encontrar maneiras adicionais de melhorar o desempenho do banco de dados. Tais sistemas frequentemente implementam alertas que notificam os administradores quando as coisas saem erradas. As estatísticas coletadas podem ser usadas não apenas para melhorar a configuração e o fluxo de trabalho do banco de dados, mas também os das aplicações cliente.
O benefício de usar o Elastic Stack (ELK stack) para monitorar seu banco de dados gerenciado é o excelente suporte para busca e a capacidade de ingestão de novos dados muito rapidamente. Ele não se destaca na atualização dos dados, mas esse compromisso é aceitável para fins de monitoramento e registro, onde os dados passados quase nunca são alterados. O Elasticsearch oferece um meio poderoso de consultar os dados, que você pode usar através do Kibana para obter uma melhor compreensão de como o banco de dados se comporta em diferentes períodos de tempo. Isso permitirá que você correlacione a carga do banco de dados com eventos da vida real para obter insights sobre como o banco de dados está sendo utilizado.
Neste tutorial, você importará métricas do banco de dados, geradas pelo comando INFO do Redis, no Elasticsearch via Logstash. Isso envolve configurar o Logstash para executar periodicamente o comando, analisar sua saída e enviá-lo para o Elasticsearch para indexação imediatamente após. Os dados importados podem ser posteriormente analisados e visualizados no Kibana. No final do tutorial, você terá um sistema automatizado trazendo estatísticas do Redis para análise posterior.
Pré-requisitos
- Um servidor Ubuntu 18.04 com pelo menos 8 GB de RAM, privilégios de root e uma conta secundária não-root. Você pode configurar isso seguindo este guia de configuração inicial do servidor. Para este tutorial, o usuário não-root é
sammy. - O Java 8 instalado no seu servidor. Para instruções de instalação, visite Como Instalar o Java com
aptno Ubuntu 18.04 e siga os comandos descritos no primeiro passo. Você não precisa instalar o Java Development Kit (JDK). - O Nginx instalado no seu servidor. Para um guia sobre como fazer isso, veja o tutorial Como Instalar o Nginx no Ubuntu 18.04.
- O Elasticsearch e o Kibana instalados no seu servidor. Complete os dois primeiros passos do tutorial Como Instalar o Elasticsearch, Logstash e Kibana (Elastic Stack) no Ubuntu 18.04.
- A Redis managed database provisioned from DigitalOcean with connection information available. Make sure that your server’s IP address is on the whitelist. For a guide on creating a Redis database using the DigitalOcean Control Panel, visit the Redis Quickstart guide.
- Redli instalado no seu servidor de acordo com o tutorial Como Conectar-se a um Banco de Dados Gerenciado no Ubuntu 18.04.
Passo 1 — Instalação e Configuração do Logstash
Nesta seção, você irá instalar o Logstash e configurá-lo para extrair estatísticas do seu cluster de banco de dados Redis e, em seguida, analisá-las para enviar ao Elasticsearch para indexação.
Comece instalando o Logstash com o seguinte comando:
Depois que o Logstash estiver instalado, habilite o serviço para iniciar automaticamente na inicialização:
Antes de configurar o Logstash para extrair as estatísticas, vamos ver como os dados em si se parecem. Para se conectar ao seu banco de dados Redis, acesse o Painel de Controle do seu Banco de Dados Gerenciado e, na área de Detalhes da Conexão, selecione Flags no menu suspenso:
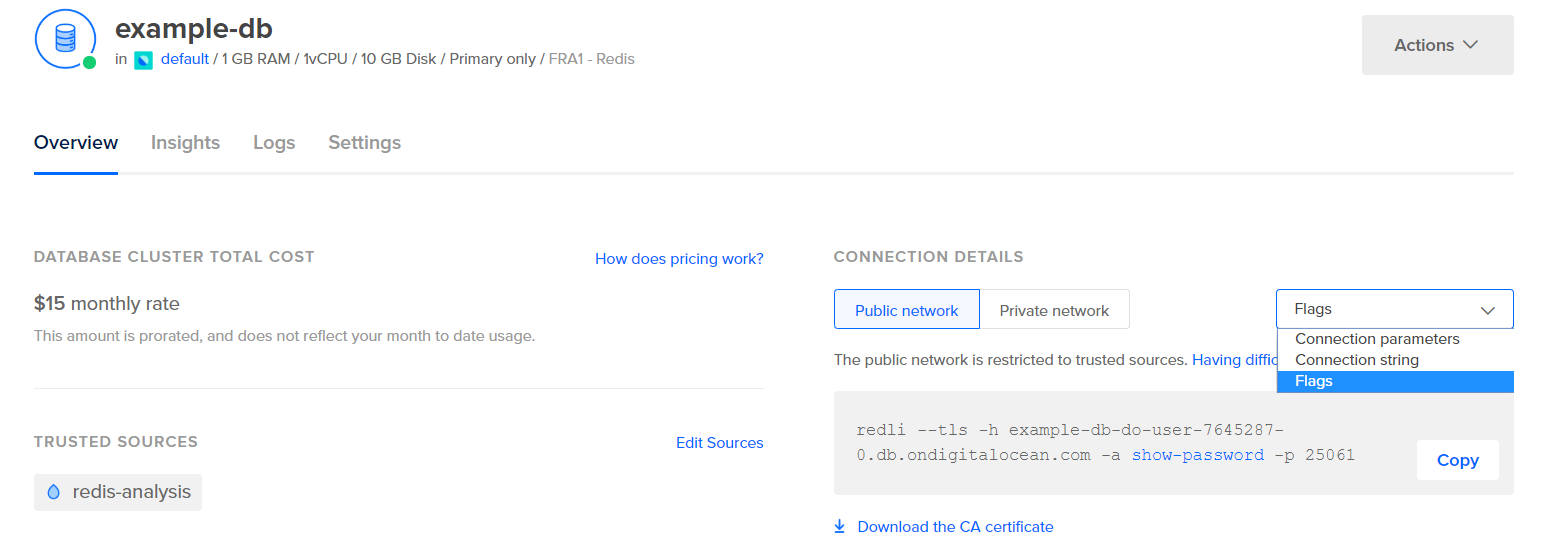
Você verá um comando pré-configurado para o cliente Redli, que você usará para se conectar ao seu banco de dados. Clique em Copiar e execute o seguinte comando no seu servidor, substituindo redli_flags_command pelo comando que acabou de copiar:
Como a saída deste comando é longa, vamos explicar isso dividido em suas diferentes seções.
Na saída do comando info do Redis, as seções são marcadas com #, o que significa um comentário. Os valores são preenchidos no formato chave:valor, o que os torna relativamente fáceis de analisar.
A seção Server contém informações técnicas sobre a construção do Redis, como sua versão e o commit do Git no qual se baseia, enquanto a seção Clients fornece o número de conexões atualmente abertas.
Output# Server
redis_version:6.2.6
redis_git_sha1:4f4e829a
redis_git_dirty:1
redis_build_id:5861572cb79aebf3
redis_mode:standalone
os:Linux 5.11.12-300.fc34.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:11.2.1
process_id:79
process_supervised:systemd
run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
tcp_port:25060
server_time_usec:1640878632737564
uptime_in_seconds:1679
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:13488680
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
io_threads_active:0
# Clients
connected_clients:4
cluster_connections:0
maxclients:10032
client_recent_max_input_buffer:24
client_recent_max_output_buffer:0
...
Memory confirma quanto de RAM o Redis alocou para si, bem como a quantidade máxima de memória que pode utilizar. Se começar a ficar sem memória, ele liberará chaves usando a estratégia especificada no Painel de Controle (mostrado no campo maxmemory_policy neste output).
Output...
# Memory
used_memory:977696
used_memory_human:954.78K
used_memory_rss:9977856
used_memory_rss_human:9.52M
used_memory_peak:977696
used_memory_peak_human:954.78K
used_memory_peak_perc:100.00%
used_memory_overhead:871632
used_memory_startup:810128
used_memory_dataset:106064
used_memory_dataset_perc:63.30%
allocator_allocated:947216
allocator_active:1273856
allocator_resident:3510272
total_system_memory:1017667584
total_system_memory_human:970.52M
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:455081984
maxmemory_human:434.00M
maxmemory_policy:noeviction
allocator_frag_ratio:1.34
allocator_frag_bytes:326640
allocator_rss_ratio:2.76
allocator_rss_bytes:2236416
rss_overhead_ratio:2.84
rss_overhead_bytes:6467584
mem_fragmentation_ratio:11.43
mem_fragmentation_bytes:9104832
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61504
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
...
Na seção Persistence, você pode ver a última vez que o Redis salvou as chaves que armazena no disco, e se foi bem-sucedido. A seção Stats fornece números relacionados a conexões de cliente e em cluster, o número de vezes que a chave solicitada foi (ou não foi) encontrada, e assim por diante.
Output...
# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1640876954
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:217088
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0
# Stats
total_connections_received:202
total_commands_processed:2290
instantaneous_ops_per_sec:0
total_net_input_bytes:38034
total_net_output_bytes:1103968
instantaneous_input_kbps:0.01
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:29
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:452
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:0
dump_payload_sanitizations:0
total_reads_processed:2489
total_writes_processed:2290
io_threaded_reads_processed:0
io_threaded_writes_processed:0
...
Ao observar o role sob Replication, você saberá se está conectado a um nó primário ou de réplica. O restante da seção fornece o número de réplicas atualmente conectadas e a quantidade de dados que a réplica está faltando em relação ao primário. Pode haver campos adicionais se a instância à qual você está conectado for uma réplica.
Nota: O projeto Redis usa os termos “mestre” e “escravo” em sua documentação e em vários comandos. A DigitalOcean geralmente prefere os termos alternativos “primário” e “réplica”. Este guia utilizará os termos “primário” e “réplica” sempre que possível, mas observe que há algumas instâncias em que os termos “mestre” e “escravo” inevitavelmente surgem.
Output...
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:45088768
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
...
Sob CPU, você verá a quantidade de energia do sistema (used_cpu_sys) e do usuário (used_cpu_user) que o Redis está consumindo no momento. A seção Cluster contém apenas um campo único, cluster_enabled, que serve para indicar que o cluster Redis está em execução.
Output...
# CPU
used_cpu_sys:1.617986
used_cpu_user:1.248422
used_cpu_sys_children:0.000000
used_cpu_user_children:0.001459
used_cpu_sys_main_thread:1.567638
used_cpu_user_main_thread:1.218768
# Modules
# Estatísticas de Erro
# Cluster
cluster_enabled:0
# Keyspace
O Logstash será encarregado de executar periodicamente o comando info em seu banco de dados Redis (similar ao que você acabou de fazer), analisar os resultados e enviá-los para o Elasticsearch. Você poderá acessá-los posteriormente no Kibana.
Você irá armazenar a configuração para indexar estatísticas do Redis no Elasticsearch em um arquivo chamado redis.conf no diretório /etc/logstash/conf.d, onde o Logstash armazena os arquivos de configuração. Quando iniciado como serviço, ele os executará automaticamente em segundo plano.
Crie o redis.conf usando seu editor favorito (por exemplo, nano):
Adicione as seguintes linhas:
input {
exec {
command => "redis_flags_command info"
interval => 10
type => "redis_info"
}
}
filter {
kv {
value_split => ":"
field_split => "\r\n"
remove_field => [ "command", "message" ]
}
ruby {
code =>
"
event.to_hash.keys.each { |k|
if event.get(k).to_i.to_s == event.get(k) # is integer?
event.set(k, event.get(k).to_i) # convert to integer
end
if event.get(k).to_f.to_s == event.get(k) # is float?
event.set(k, event.get(k).to_f) # convert to float
end
}
puts 'Ruby filter finished'
"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
Lembre-se de substituir redis_flags_command pelo comando mostrado no painel de controle que você usou anteriormente no passo.
Você define um input, que é um conjunto de filtros que serão executados nos dados coletados, e uma saída que enviará os dados filtrados para o Elasticsearch. A entrada consiste no comando exec, que irá executar um comando no servidor periodicamente, após um tempo definido intervalo (expresso em segundos). Também especifica um parâmetro tipo que define o tipo de documento quando indexado no Elasticsearch. O bloco exec passa um objeto contendo dois campos, comando e mensagem de string. O campo comando conterá o comando que foi executado, e a mensagem conterá sua saída.
Há dois filtros que serão executados sequencialmente nos dados coletados da entrada. O filtro kv representa o filtro de chave-valor e é integrado ao Logstash. É usado para analisar dados no formato geral de chaveseparador_de_valorvalor e fornece parâmetros para especificar o que é considerado separadores de valor e de campo. O separador de campo se refere a strings que separam os dados formatados no formato geral uns dos outros. No caso da saída do comando Redis INFO, o separador de campo (campo_split) é uma nova linha, e o separador de valor (valor_split) é :. Linhas que não seguem a forma definida serão descartadas, incluindo comentários.
Para configurar o filtro kv, você passa : para o parâmetro value_split, e \r\n (indicando uma nova linha) para o parâmetro field_split. Você também ordena a remoção dos campos command e message do objeto de dados atual, passando-os para remove_field como elementos de um array, porque eles contêm dados que agora são inúteis.
O filtro kv representa o valor que analisou como um tipo de string (texto) por design. Isso levanta um problema porque o Kibana não pode processar facilmente tipos de string, mesmo que seja realmente um número. Para resolver isso, você usará código Ruby personalizado para converter as strings contendo apenas números em números, quando possível. O segundo filtro é um bloco ruby que fornece um parâmetro code aceitando uma string contendo o código a ser executado.
event é uma variável que o Logstash fornece para o seu código, e contém os dados atuais no pipeline de filtro. Como foi observado antes, os filtros são executados um após o outro, o que significa que o filtro Ruby receberá os dados analisados do filtro kv. O próprio código Ruby converte o event para um Hash e percorre as chaves, depois verifica se o valor associado à chave pode ser representado como um inteiro ou como um float (um número com decimais). Se puder, o valor da string é substituído pelo número analisado. Quando o loop termina, ele imprime uma mensagem (Filtro Ruby concluído) para relatar o progresso.
A saída envia os dados processados para o Elasticsearch para indexação. O documento resultante será armazenado no índice redis_info, definido na entrada e passado como parâmetro para o bloco de saída. Salve e feche o arquivo.
Você instalou o Logstash usando apt e o configurou para solicitar periodicamente estatísticas do Redis, processá-las e enviá-las para sua instância do Elasticsearch.
Passo 2 — Testando a Configuração do Logstash
Agora você testará a configuração executando o Logstash para verificar se ele puxará os dados corretamente.
O Logstash suporta a execução de uma configuração específica passando o caminho do arquivo para o parâmetro -f. Execute o seguinte comando para testar sua nova configuração do último passo:
Pode levar algum tempo para mostrar a saída, mas logo você verá algo semelhante ao seguinte:
OutputUsing bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
Ruby filter finished
Ruby filter finished
Ruby filter finished
...
Você verá a mensagem Filtro Ruby finalizado sendo impressa em intervalos regulares (configurados para 10 segundos no passo anterior), o que significa que as estatísticas estão sendo enviadas para o Elasticsearch.
Você pode sair do Logstash clicando em CTRL + C no seu teclado. Como mencionado anteriormente, o Logstash executará automaticamente todos os arquivos de configuração encontrados em /etc/logstash/conf.d em segundo plano quando iniciado como um serviço. Execute o seguinte comando para iniciá-lo:
Você executou o Logstash para verificar se ele pode se conectar ao seu cluster Redis e coletar dados. Em seguida, você explorará alguns dos dados estatísticos no Kibana.
Passo 3 — Explorando Dados Importados no Kibana
Nesta seção, você irá explorar e visualizar os dados estatísticos descrevendo o desempenho do seu banco de dados no Kibana.
No seu navegador da web, acesse seu domínio onde você expôs o Kibana como parte dos pré-requisitos. Você verá a página de boas-vindas padrão:
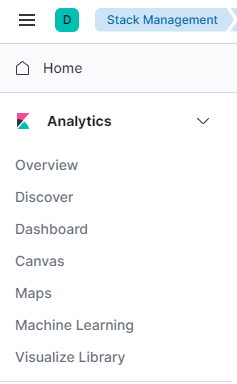
Antes de explorar os dados que o Logstash está enviando para o Elasticsearch, você primeiro precisará adicionar o índice redis_info ao Kibana. Para fazer isso, primeiro selecione Explorar por conta própria na página de boas-vindas e, em seguida, abra o menu hambúrguer no canto superior esquerdo. Sob Análises, clique em Descobrir.
O Kibana então irá solicitar que você crie um novo padrão de índice:
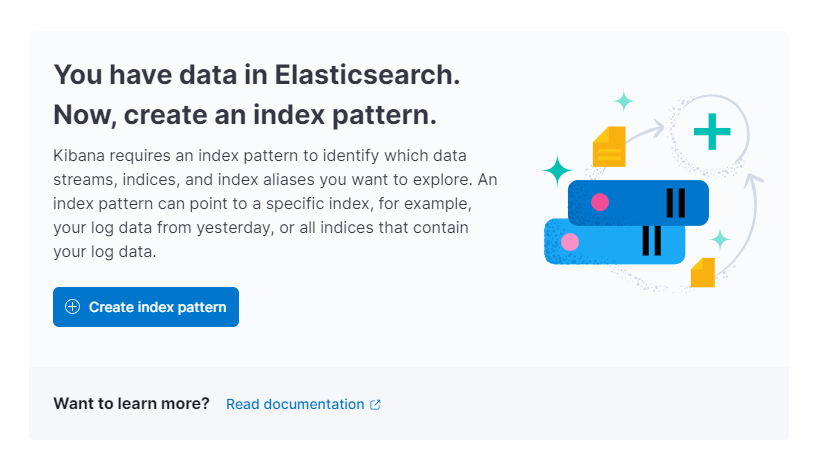
Clique em Criar padrão de índice. Você verá um formulário para criar um novo Padrão de Índice. Padrões de Índice no Kibana fornecem uma maneira de puxar dados de múltiplos índices do Elasticsearch de uma só vez e podem ser usados para explorar apenas um índice.

À direita, o Kibana lista todos os índices disponíveis, como redis_info que você configurou o Logstash para usar. Digite-o no campo de texto Nome e selecione @timestamp no menu suspenso como o Campo de data e hora. Quando terminar, pressione o botão Criar padrão de índice abaixo.
Para criar e ver visualizações existentes, abra o menu hambúrguer. Sob Análises, selecione Painel. Quando carregar, pressione Criar visualização para começar a criar uma nova:
O painel do lado esquerdo fornece uma lista de valores que o Kibana pode usar para desenhar a visualização, que será mostrada na parte central da tela. No canto superior direito da tela está o seletor de intervalo de datas. Se o campo @timestamp estiver sendo usado na visualização, o Kibana mostrará apenas os dados pertencentes ao intervalo de tempo especificado no seletor de intervalo.
No menu suspenso na parte principal da página, selecione Linha na seção Linha e área. Em seguida, encontre o campo used_memory na lista à esquerda e arraste-o para a parte central. Logo você verá uma visualização de linha da quantidade média de memória usada ao longo do tempo:
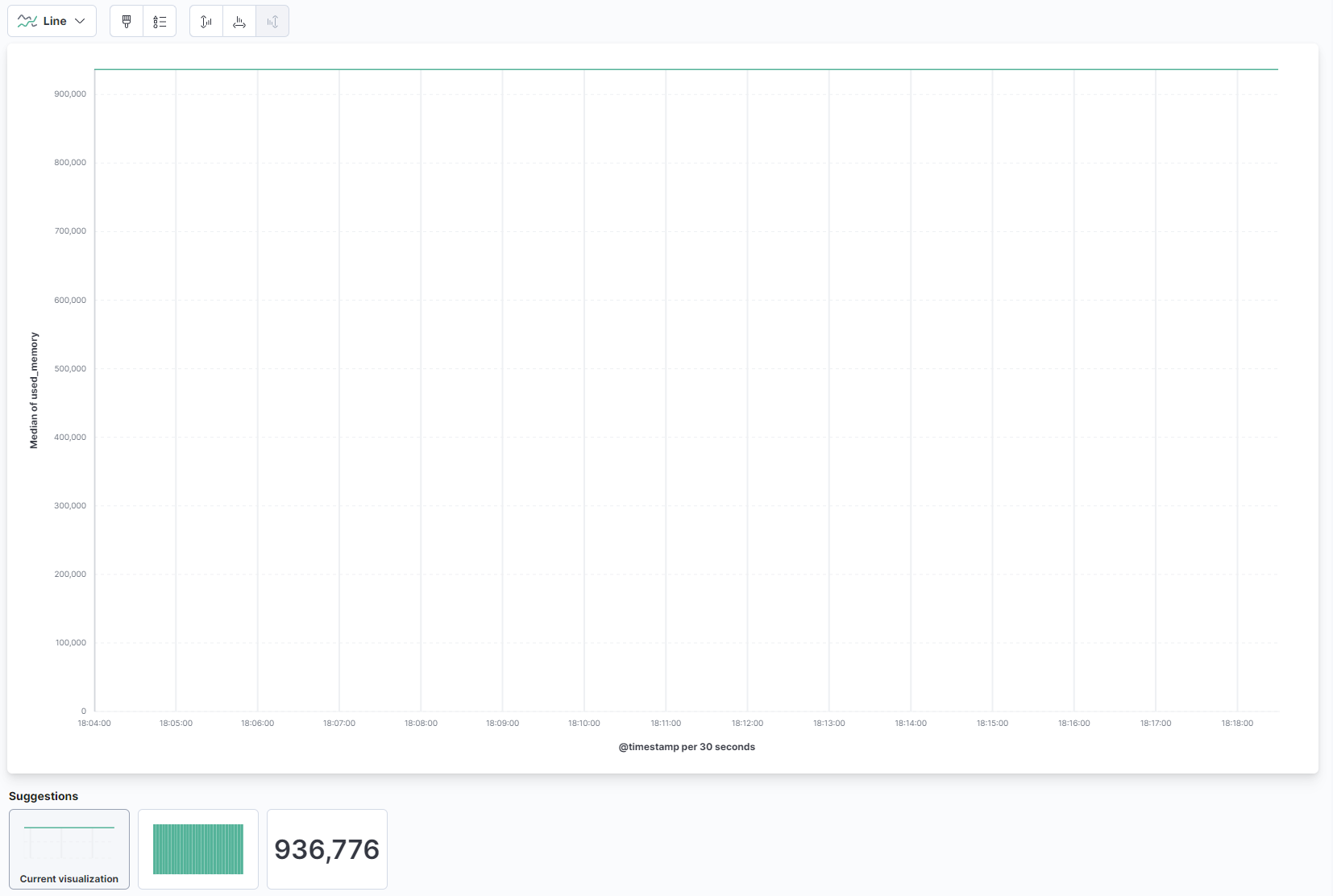
À direita, você pode configurar como os eixos horizontal e vertical são processados. Lá, você pode definir o eixo vertical para mostrar os valores médios em vez de medianos pressionando no eixo mostrado:
Você pode selecionar uma função diferente ou fornecer a sua própria:
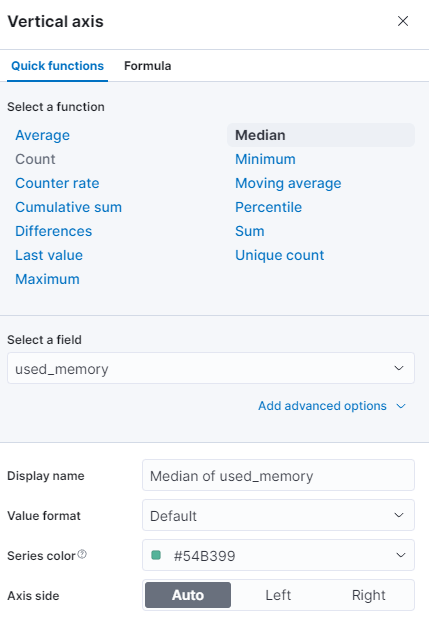
O gráfico será imediatamente atualizado com os valores atualizados.
Neste passo, você visualizou o uso de memória do seu banco de dados Redis gerenciado usando o Kibana. Isso permitirá que você obtenha uma melhor compreensão de como seu banco de dados está sendo utilizado, o que ajudará na otimização de aplicativos clientes, bem como do próprio banco de dados.
Conclusão
Agora você tem o Elastic Stack instalado no seu servidor e configurado para extrair dados estatísticos do seu banco de dados Redis gerenciado regularmente. Você pode analisar e visualizar os dados usando o Kibana, ou outro software adequado, o que ajudará a obter insights valiosos e correlações do mundo real sobre o desempenho do seu banco de dados.
Para obter mais informações sobre o que você pode fazer com seu Banco de Dados Redis Gerenciado, visite a documentação do produto. Se desejar apresentar as estatísticas do banco de dados usando outro tipo de visualização, consulte a documentação do Kibana para obter instruções adicionais.