













O que é Elasticsearch?
Elasticsearch é um mecanismo de busca e análise distribuído e de código aberto construído sobre a biblioteca Apache Lucene. O Elasticsearch também oferece busca vetorial e geração aumentada por recuperação (RAG), suportando aplicações modernas de IA de forma integrada. As aplicações podem armazenar dados estruturados e não estruturados no Elasticsearch, com ou sem um esquema definido, enviando JSON como carga para um cluster Elasticsearch.
Arquitetura do Elasticsearch
Desde a base, os principais componentes de um cluster Elasticsearch são:
Documento
Um documento é o menor registro de informação armazenado pelo Elasticsearch e é representado como JSON. Um documento consiste em múltiplos campos (pares chave-valor) de diferentes tipos e pode ter um esquema pré-definido ou ser sem esquema, inferindo os tipos de dados de quaisquer novos campos que sejam indexados.
Índice
Um índice é uma coleção lógica de documentos com o mesmo esquema, identificada por um nome de índice.
Shard
Os índices do Elasticsearch são divididos em unidades gerenciáveis chamadas shards, que são uma coleção de documentos. Shards são a unidade básica de busca e são replicados em múltiplos nós para redundância e tolerância a falhas.
Node
Um nó é uma instância independente do Elasticsearch e gerencia uma coleção de shards que pertencem a um ou mais índices. Os nós podem ter diferentes papéis, como nó de dados, nó mestre e nó de ingestão.
Cluster
Um cluster do Elasticsearch é uma coleção de nós interconectados. Todos os nós em um cluster podem lidar com solicitações de clientes e se comunicar entre si. Cada nó em um cluster possui um subconjunto dos shards que pertencem a um índice.
Arquitetura da Consulta
O diagrama de arquitetura a seguir descreve o fluxo de uma solicitação de pesquisa:

- O usuário ou aplicativo faz uma consulta de pesquisa. A consulta pode ser tratada por qualquer nó no cluster. O nó que lida com a solicitação é o nó “coordenador”.
- O nó coordenador transmite a consulta para todos os shards envolvidos e suas réplicas.
- Cada shard executa a consulta localmente e retorna um conjunto leve de resultados para o nó coordenador.
- O nó coordenador mescla os resultados que recebe. Este é o fim da fase de “consulta”. A fase de consulta identifica os documentos básicos que formam o resultado da pesquisa, mas o documento completo ainda precisa ser recuperado.
- O nó coordenador envia solicitações de busca para os shards proprietários, que enriquecem os documentos no conjunto de resultados.
- Os documentos enriquecidos são retornados ao nó coordenador.
- O conjunto completo de resultados de pesquisa, classificado e enriquecido, é retornado ao chamador.
Arquitetura de Indexação
O diagrama de arquitetura a seguir esboça o fluxo de uma solicitação de indexação:
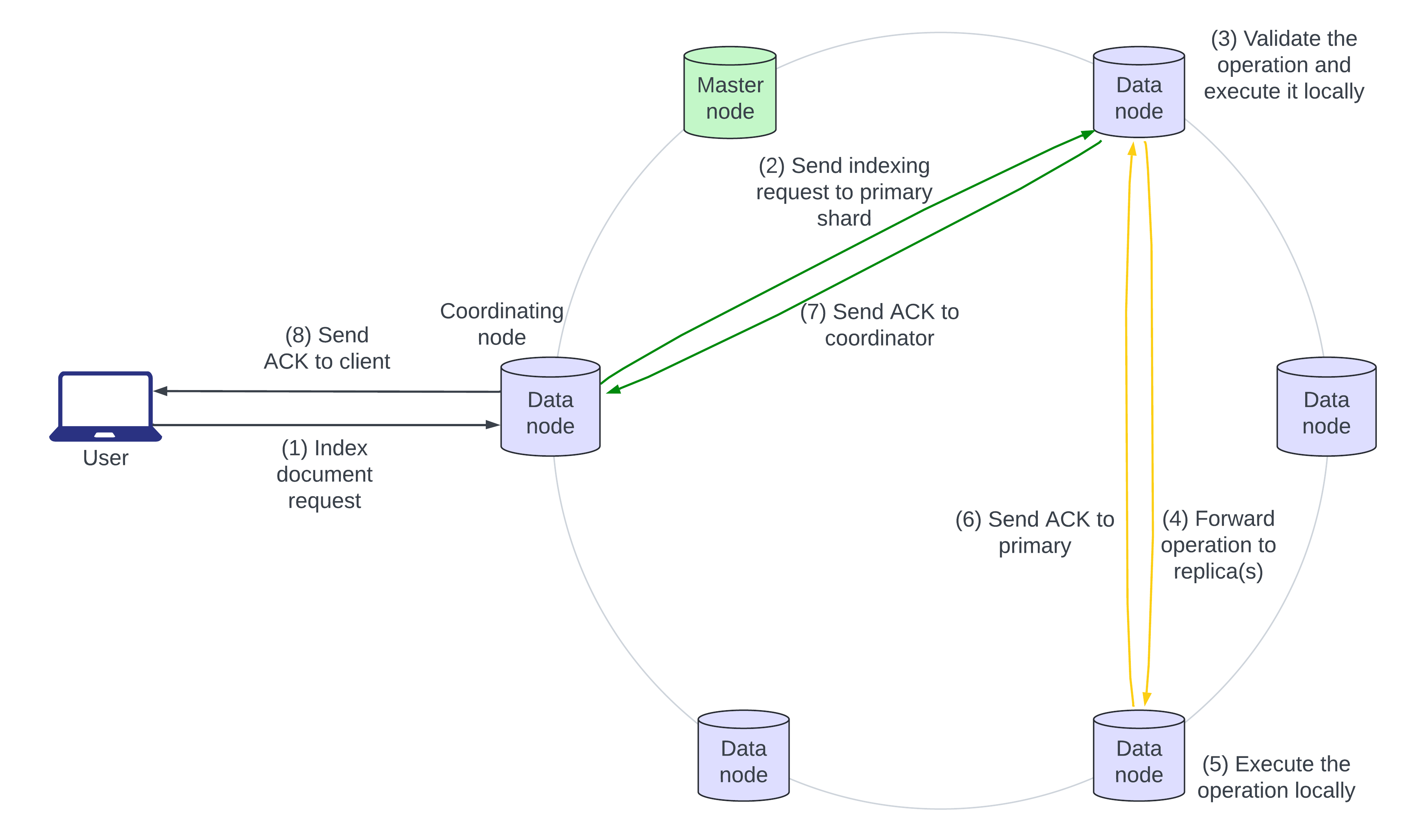
- O usuário envia um documento JSON para o Elasticsearch indexar. Se o documento já existir, novos campos são adicionados e campos existentes são sobrescritos. O nó que primeiro recebe a solicitação é o nó “coordinating”.
- O nó coordenador identifica a partição primária do documento de entrada, geralmente com base no ID do documento, e encaminha a solicitação para o nó de dados que possui a partição primária.
- A partição primária valida a operação e a executa localmente.
- A partição primária então encaminha a operação para todos os seus réplicas em paralelo.
- As réplicas aplicam a operação localmente em seus nós.
- Os passos 6, 7 e 8 mostram o reconhecimento da gravação subindo da réplica para a partição primária, para o nó coordenador e para o chamador.
Conclusão
Este artigo descreve os diferentes componentes de um cluster Elasticsearch: documentos, índices, partições e nós. Também esboça a vida útil de uma solicitação de pesquisa e uma solicitação de indexação. Sua arquitetura flexível facilita a adição e remoção de nós à medida que o cluster se expande. Combinado com recursos como indexação sem esquema e suporte para recursos de pesquisa de IA, isso torna o Elasticsearch o padrão de facto para organizações que precisam armazenar, pesquisar e analisar eficientemente grandes volumes de dados em tempo real.
Source:
https://dzone.com/articles/elasticsearch-query-and-indexing-architecture