













O sharding de banco de dados é o processo de dividir dados em pedaços menores chamados de “fragmentos”. Fragmentação geralmente é introduzida quando há necessidade de escalar gravações. Ao longo da vida útil de um aplicativo bem-sucedido, o servidor de banco de dados atingirá o número máximo de gravações que pode realizar, seja no nível de processamentos ou de capacidade. Dividir os dados em múltiplos fragmentos—cada um em seu próprio servidor de banco de dados—reduz a pressão em cada nó individual, efetivamente aumentando a capacidade de gravação do banco de dados como um todo. Isso é o que o sharding de banco de dados é.
SQL Distribuído é a nova maneira de escalar bancos de dados relacionais com uma estratégia semelhante ao sharding que é totalmente automatizada e transparente para os aplicativos. Bancos de dados SQL distribuídos são projetados desde o início para escalar quase linearmente. Neste artigo, você aprenderá os fundamentos do SQL distribuído e como começar.
Desvantagens do Sharding de Banco de Dados
A fragmentação introduz uma série de desafios:
- Particionamento de dados: Decidir como particionar os dados em vários fragmentos pode ser um desafio, pois requer encontrar um equilíbrio entre a proximidade dos dados e a distribuição uniforme dos dados para evitar pontos quentes.
- Gerenciamento de falhas: Se um nó chave falhar e não houver fragmentos suficientes para suportar a carga, como você obtém os dados em um novo nó sem tempo de inatividade?
- Complexidade da consulta: O código de aplicação está acoplado à lógica de particionamento de dados e consultas que exigem dados de múltiplos nós precisam ser reagrupadas.
- Consistência de dados: Garantir a consistência de dados em múltiplas partições pode ser um desafio, pois requer coordenação de atualizações nos dados em várias partições. Isso pode ser particularmente difícil quando atualizações são feitas concorrentemente, sendo necessário resolver conflitos entre diferentes gravações.
- Escalabilidade elástica: Com o aumento do volume de dados ou do número de consultas, pode ser necessário adicionar novas partições ao banco de dados. Esse processo pode ser complexo, com tempo de inatividade inevitável, exigindo processos manuais para realocar dados uniformemente em todas as partições.
Alguns desses desvantagens podem ser aliviados adotando persistência poliglota (usando bancos de dados diferentes para diferentes cargas de trabalho), motores de armazenamento de banco de dados com capacidades nativas de sharding, ou proxies de banco de dados. No entanto, enquanto ajudam com alguns dos desafios no sharding de banco de dados, essas ferramentas têm limitações e introduzem complexidade que requer gerenciamento constante.
O que é SQL Distribuído?
Distributed SQL refere-se a uma nova geração de bancos de dados relacionais. Em termos simples, um banco de dados SQL distribuído é um banco de dados relacional com fragmentação transparente que parece um único banco de dados lógico para aplicativos. Os bancos de dados SQL distribuídos são implementados como uma arquitetura shared-nothing e um mecanismo de armazenamento que escala tanto leituras quanto gravações enquanto mantém a conformidade verdadeira com ACID e alta disponibilidade. Os bancos de dados SQL distribuídos possuem os recursos de escalabilidade dos bancos de dados NoSQL—que ganharam popularidade na década de 2000—mas não sacrificam a consistência. Eles mantêm os benefícios dos bancos de dados relacionais e adicionam compatibilidade com a nuvem com resiliência em várias regiões.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
Como Funciona o Distributed SQL?
Para entender como o SQL Distribuído funciona, vamos considerar o caso do MariaDB Xpand — um banco de dados SQL distribuído compatível com o banco de dados de código aberto MariaDB. O Xpand opera dividindo os dados e índices entre os nós e executando automaticamente tarefas como rebalanceamento de dados e execução de consultas distribuídas. As consultas são executadas em paralelo para minimizar o atraso. Os dados são replicados automaticamente para garantir que não haja um único ponto de falha. Quando um nó falha, o Xpand rebalanceia os dados entre os nós sobreviventes. O mesmo acontece quando um novo nó é adicionado. Um componente chamado rebalancer garante que não haja pontos quentes — um desafio com particionamento manual de banco de dados — que ocorre quando um nó tem que lidar de forma desproporcional com muitas transações em comparação com outros nós que podem ficar ociosos às vezes.
Vamos estudar um exemplo. Suponha que temos uma instância de banco de dados com a tabela some_table e um número de linhas:
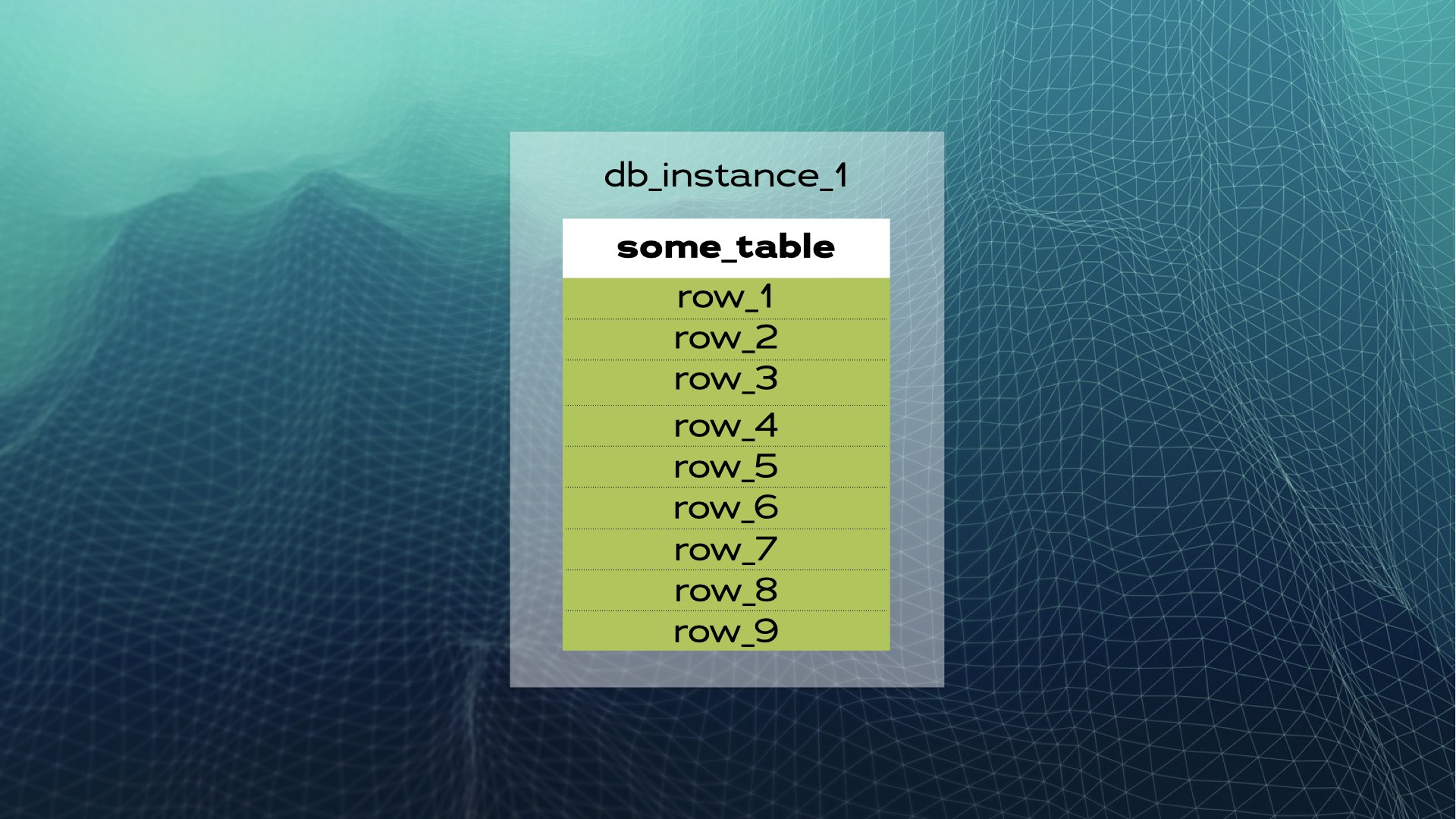
Podemos dividir os dados em três pedaços (fragmentos):

E então mover cada pedaço de dados para uma instância de banco de dados separada:
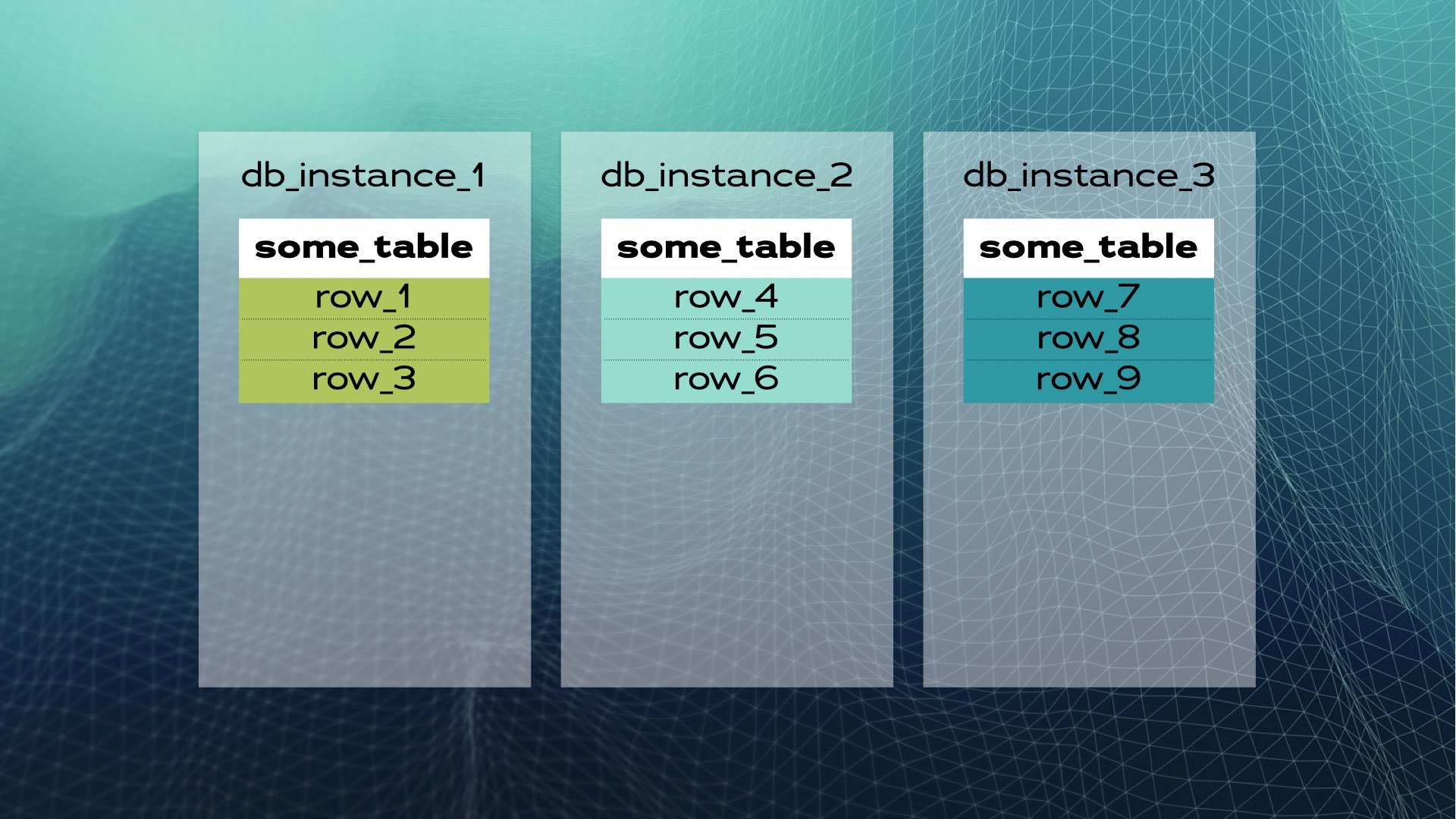
Isto é o que parece o compartilhamento manual de banco de dados. O SQL distribuído faz isso automaticamente para você. No caso do Xpand, cada fragmento é chamado de fatia. As linhas são fatiadas usando um hash de um subconjunto das colunas da tabela. Não apenas os dados são fatiados, mas os índices também são fatiados e distribuídos entre os nós (instâncias de banco de dados). Além disso, para manter alta disponibilidade, as fatias são replicadas em outros nós (o número de réplicas por nó é configurável). Isso também acontece automaticamente:
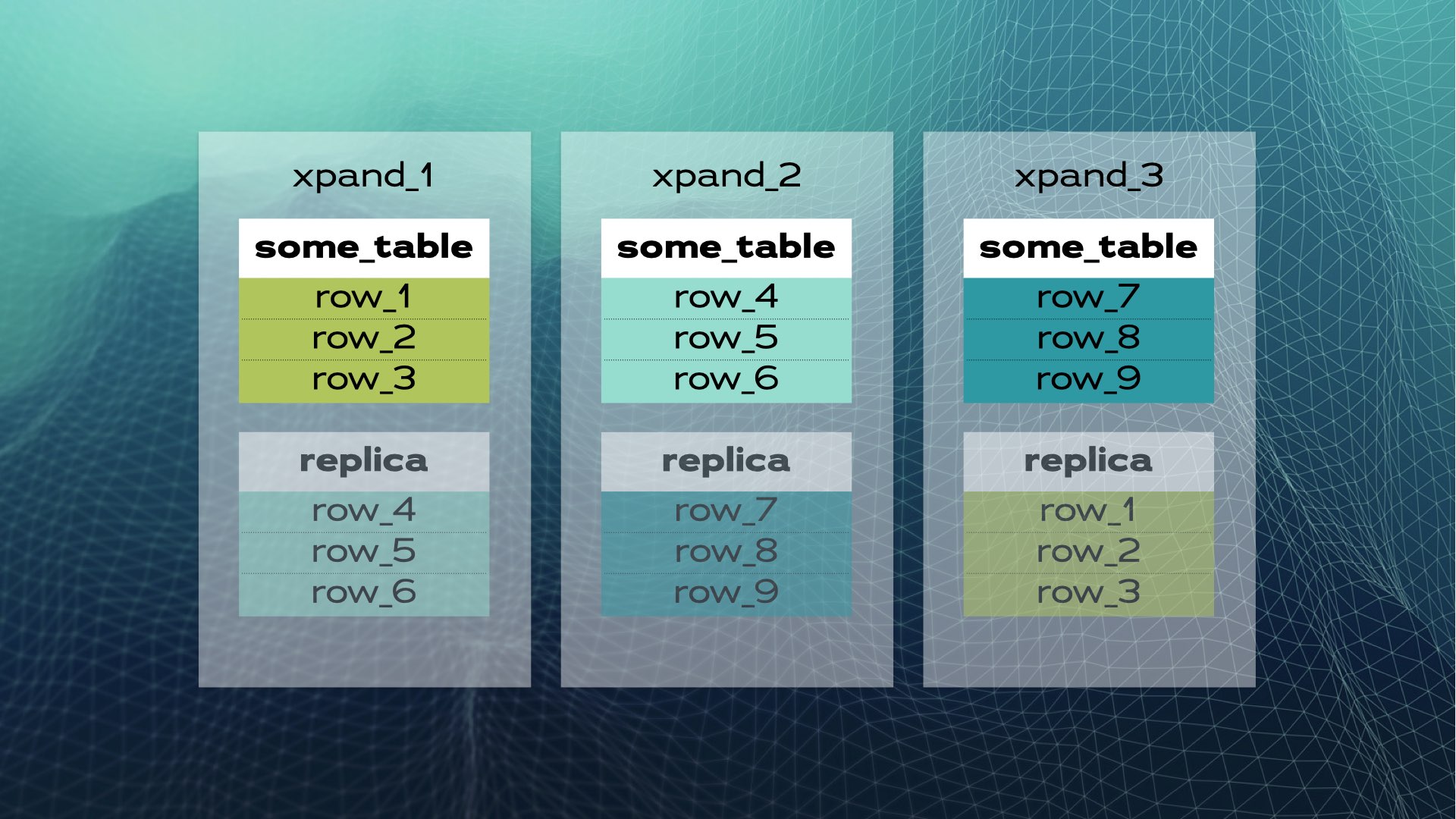
Quando um novo nó é adicionado ao cluster ou quando um nó falha, o Xpand reequilibra automaticamente os dados sem a necessidade de intervenção manual. Veja o que acontece quando um nó é adicionado ao cluster anterior:

Algumas linhas são movidas para o novo nó para aumentar a capacidade geral do sistema. Tenha em mente que, embora não seja mostrado no diagrama, os índices e as réplicas também são realocados e atualizados conforme necessário. Uma visão um pouco mais completa (com uma realocação de dados um pouco diferente) do cluster anterior é mostrada neste diagrama:
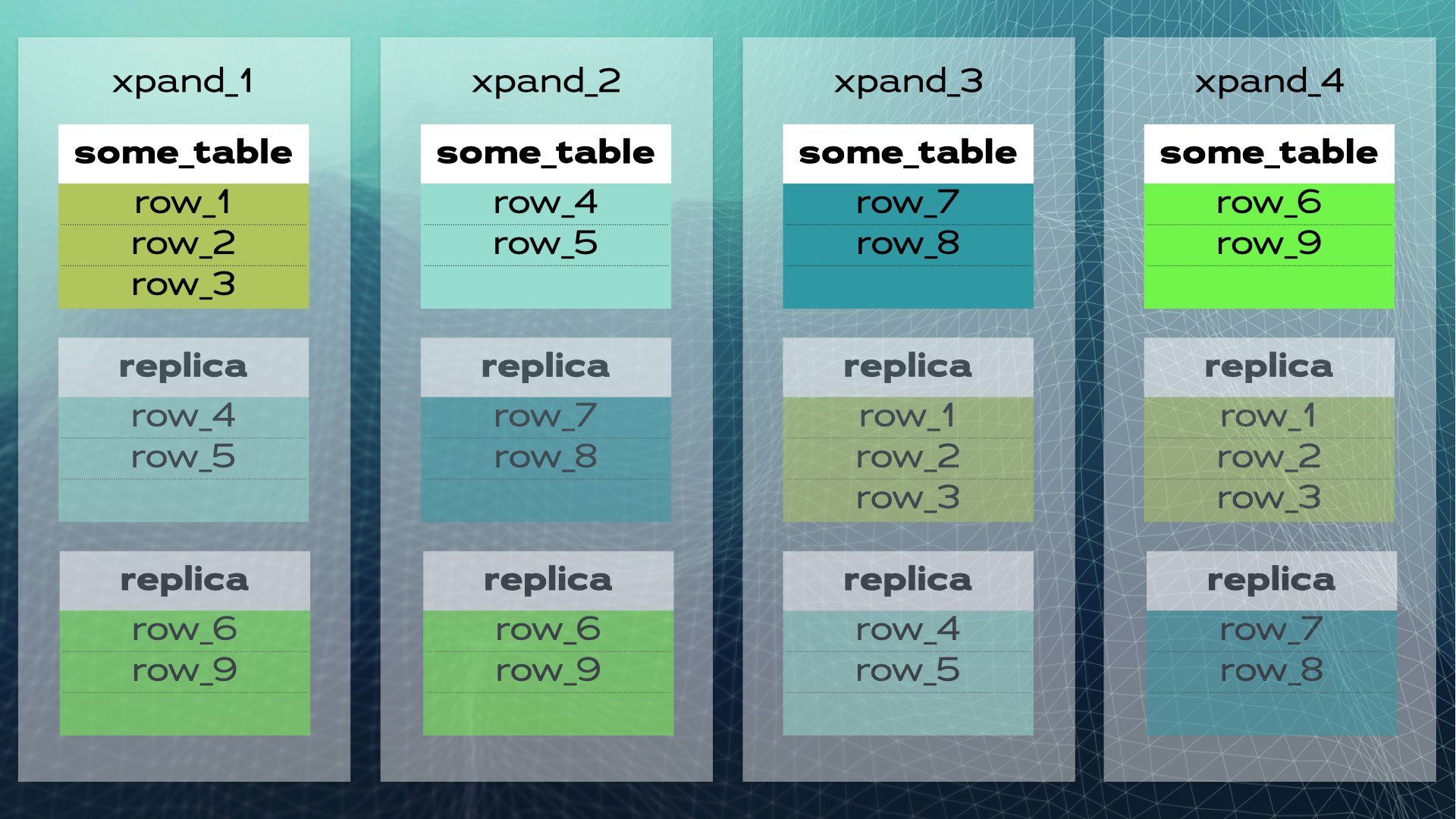
Essa arquitetura permite escalabilidade quase linear. Não é necessária intervenção manual no nível do aplicativo. Para o aplicativo, o cluster parece um único banco de dados lógico. O aplicativo simplesmente se conecta ao banco de dados por meio de um balanceador de carga (MariaDB MaxScale):
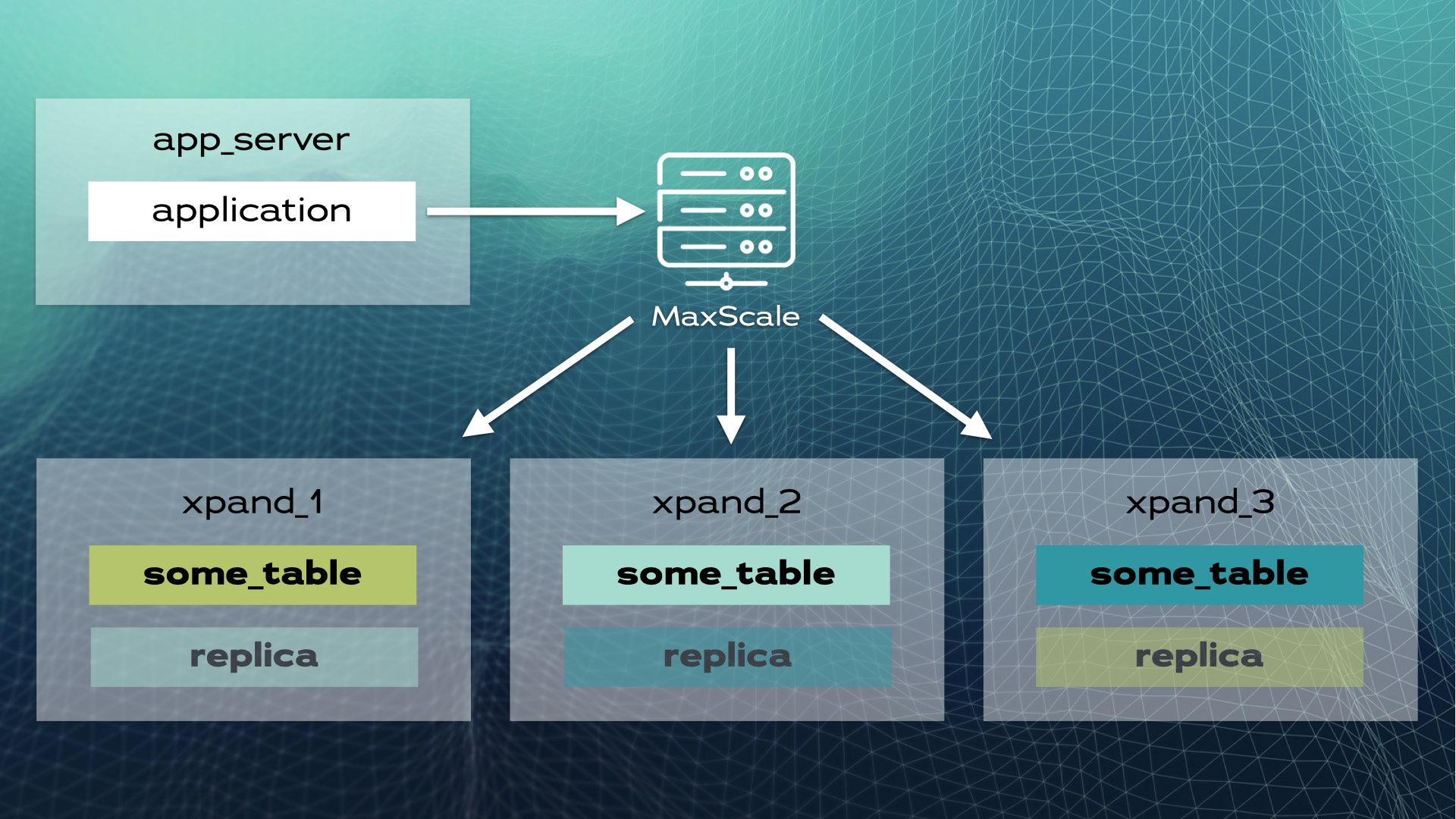
Quando o aplicativo envia uma operação de escrita (por exemplo, INSERT ou UPDATE), o hash é calculado e enviado para a fatia correta. Múltiplas operações de escrita são enviadas em paralelo para vários nós.
Quando Não Usar SQL Distribuído
Dividir um banco de dados melhora o desempenho, mas também introduz overhead adicional no nível de comunicação entre os nós. Isso pode levar a um desempenho mais lento se o banco de dados não estiver configurado corretamente ou se o roteador de consultas não for otimizado. O SQL distribuído pode não ser a melhor alternativa em aplicativos com menos de 10K consultas por segundo ou 5K transações por segundo. Além disso, se seu banco de dados consiste principalmente em muitas pequenas tabelas, um banco de dados monolítico pode ter um melhor desempenho.
Começando com SQL Distribuído
Como um banco de dados SQL distribuído parece a um aplicativo como se fosse um único banco de dados lógico, começar é direto. Tudo o que você precisa é o seguinte:
- Um cliente SQL como DBeaver, DbGate, DataGrip, ou qualquer extensão de cliente SQL para o seu IDE
- A distributed SQL database
Docker facilita a segunda parte. Por exemplo, o MariaDB publica a imagem Docker mariadb/xpand-single que permite iniciar um banco de dados Xpand de nó único para avaliação, teste e desenvolvimento.
Para iniciar um contêiner Xpand, execute o seguinte comando:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Consulte a imagem Docker documentação para mais detalhes.
Nota: No momento de escrever este artigo, a imagem Docker mariadb/xpand-single não está disponível nas arquiteturas ARM. Nesses arquiteturas (por exemplo, máquinas Apple com processadores M1), use UTM para criar uma máquina virtual (VM) e instalar, por exemplo, Debian. Atribua um hostname e use SSH para conectar-se à VM para instalar o Docker e criar o contêiner MariaDB Xpand.
Conectando ao Banco de Dados
Conectar-se a um banco de dados Xpand é o mesmo que conectar-se a um servidor MariaDB Comunidade ou Empresa. Se você tem a ferramenta CLI mariadb instalada, simplesmente execute o seguinte:
mariadb -h 127.0.0.1 -u user -pVocê pode conectar-se ao banco de dados usando uma GUI para bancos de dados SQL como DBeaver, DataGrip, ou uma extensão SQL para o seu IDE (como esta aqui para o VS Code). Vamos utilizar um cliente SQL gratuito e de código aberto chamado DbGate. Você pode baixar o DbGate e executá-lo como uma aplicação de desktop ou, já que está usando Docker, pode implantá-lo como uma aplicação web que você pode acessar de qualquer lugar através de um navegador (similar ao popular phpMyAdmin). Basta executar o seguinte comando:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateUma vez que o contêiner inicia, aponte seu navegador para http://localhost:3000/. Preencha os detalhes de conexão:
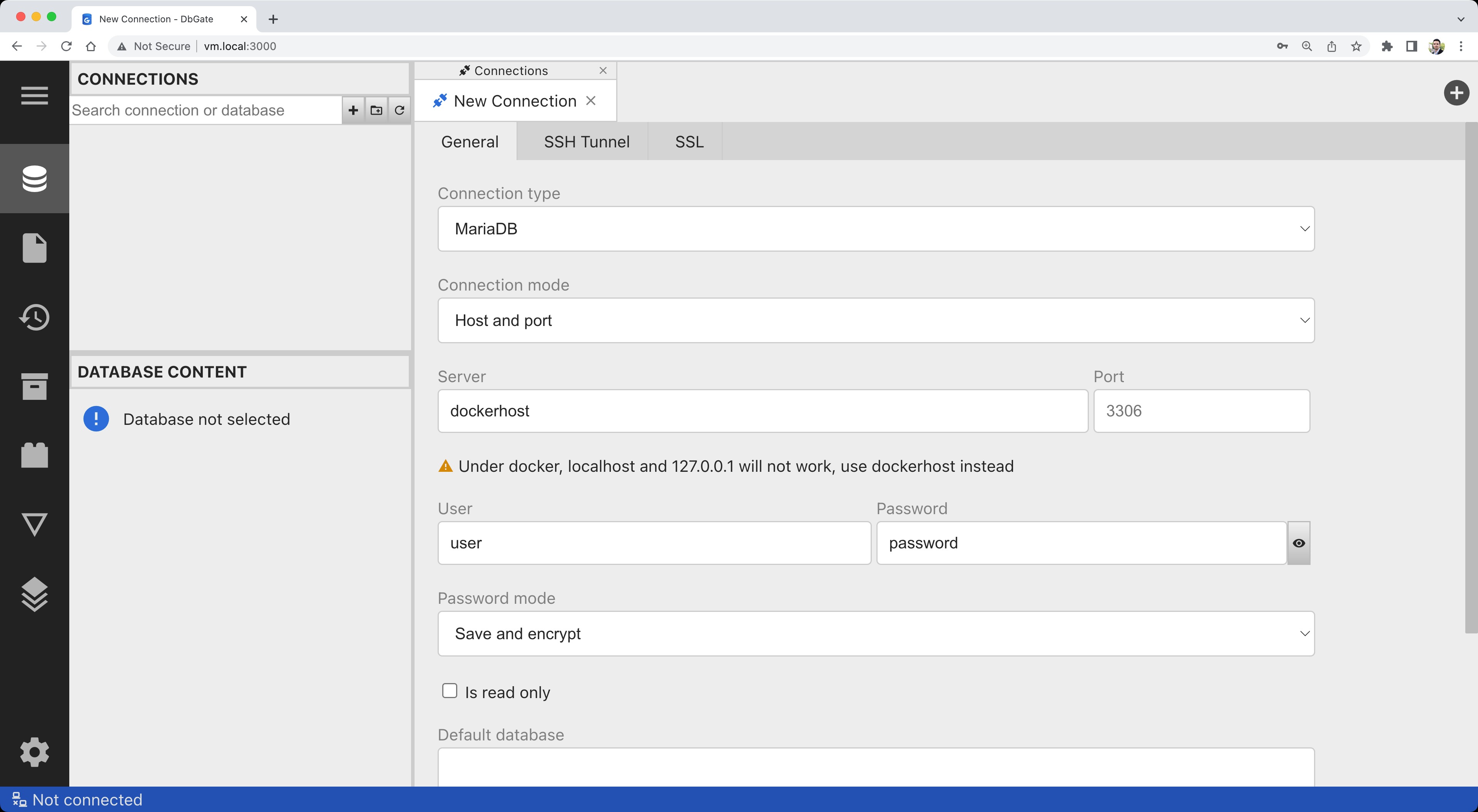
Clique em Testar e confirme que a conexão é bem-sucedida:

Clique em Salvar e crie um novo banco de dados clicando com o botão direito na conexão no painel esquerdo e selecionando Criar banco de dados. Tente criar tabelas ou importar um script SQL. Se você só quer experimentar algo, o Pais ou Sakila são bons bancos de dados de exemplo.
Conectando do Java, JavaScript, Python e C++
Para se conectar ao Xpand a partir de aplicativos, você pode usar os Conectores MariaDB. Existem muitas combinações possíveis de linguagens de programação e frameworks de persistência. Abranger isso está fora do escopo deste artigo, mas se você apenas quer começar e ver algo em ação, dê uma olhada nesta página de início rápido com exemplos de código para Java, JavaScript, Python e C++.
O Verdadeiro Poder do SQL Distribuído
Neste artigo, aprendemos como criar um único nó Xpand para fins de desenvolvimento e teste, em oposição a cargas de trabalho de produção. No entanto, o verdadeiro poder de um banco de dados SQL distribuído está em sua capacidade de escalar não apenas leituras (como na fragmentação de banco de dados clássica) mas também gravações simplesmente adicionando mais nós e deixando o balanceador de carga otimamente realocar os dados. Embora seja possível implantar o Xpand em uma topologia multinó, a maneira mais fácil de usá-lo na produção é através do SkySQL.
Se você deseja aprender mais sobre SQL distribuído e MariaDB Xpand, aqui está uma lista de recursos úteis:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding