













Neste laboratório prático da Universidade ScyllaDB, você aprenderá a usar o ScyllaDB CDC source connector para enviar eventos de alterações de linha nas tabelas de um cluster ScyllaDB para um servidor Kafka.
O que é o ScyllaDB CDC?
Para recapitular, a Captura de Dados de Alteração (CDC) é um recurso que permite não apenas consultar o estado atual de uma tabela de banco de dados, mas também consultar a história de todas as alterações feitas na tabela. O CDC está pronto para produção (GA) a partir do ScyllaDB Enterprise 2021.1.1 e do ScyllaDB Open Source 4.3.
No ScyllaDB, o CDC é opcional e habilitado em uma base por tabela. A história das alterações feitas em uma tabela habilitada para CDC é armazenada em uma tabela associada separada.
Você pode habilitar o CDC ao criar ou alterar uma tabela usando a opção CDC, por exemplo:
CREATE TABLE ks.t (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};ScyllaDB CDC Source Connector
O ScyllaDB CDC Source Connector é um conector de origem que captura alterações em nível de linha nas tabelas de um cluster ScyllaDB. É um conector Debezium, compatível com o Kafka Connect (com Kafka 2.6.0+). O conector lê o log CDC para tabelas especificadas e produz mensagens Kafka para cada operação de nível de linha INSERT, UPDATE ou DELETE. O conector é tolerante a falhas, tentando ler dados do Scylla em caso de falha. Ele periodicamente salva a posição atual no log CDC do ScyllaDB usando o rastreamento de deslocamento do Kafka Connect. Cada mensagem Kafka gerada contém informações sobre a fonte, como a marcação de tempo e o nome da tabela.
Nota: no momento da escrita, não há suporte para tipos de coleção (LIST, SET, MAP) e UDTs—colunas com esses tipos são omitidas das mensagens geradas. Fique atualizado sobre esta solicitação de melhoria e outros desenvolvimentos no projeto do GitHub.
Confluent e Kafka Connect
O Confluent é uma plataforma completa de streaming de dados que permite acessar, armazenar e gerenciar dados como fluxos contínuos e em tempo real. Ele amplia os benefícios do Apache Kafka com recursos de nível empresarial. O Confluent facilita a construção de aplicativos modernos orientados a eventos e oferece uma pipeline de dados universal, suportando escalabilidade, desempenho e confiabilidade.
O Kafka Connect é uma ferramenta para transmitir dados de forma escalável e confiável entre o Apache Kafka e outros sistemas de dados. Simplifica a definição de conectores que movem grandes conjuntos de dados para dentro e fora do Kafka. Pode ingerir bancos de dados inteiros ou coletar métricas de servidores de aplicativos em tópicos do Kafka, disponibilizando os dados para processamento em fluxo com baixa latência.
O Kafka Connect inclui dois tipos de conectores:
- Conector de origem: Os conectores de origem ingerem bancos de dados inteiros e transmitem atualizações de tabelas para tópicos do Kafka. Os conectores de origem também podem coletar métricas de servidores de aplicativos e armazenar os dados em tópicos do Kafka, disponibilizando os dados para processamento em fluxo com baixa latência.
- Conector de destino: Os conectores de destino entregam dados de tópicos do Kafka para índices secundários, como o Elasticsearch, ou sistemas em lote, como o Hadoop, para análise offline.
Configuração de Serviço com Docker
Neste laboratório, você usará o Docker.
Certifique-se de que seu ambiente atenda aos seguintes pré-requisitos:
- Docker para Linux, Mac ou Windows.
- Nota: executar o ScyllaDB no Docker é recomendado apenas para avaliação e teste do ScyllaDB.
- ScyllaDB de código aberto. Para obter o melhor desempenho, é recomendado uma instalação regular.
- 8 GB de RAM ou superior para os serviços Kafka e ScyllaDB.
- docker-compose
- Git
Instalação e Inicialização da Tabela ScyllaDB
Primeiro, você vai iniciar um cluster de três nós do ScyllaDB e criar uma tabela com CDC habilitado.
Se ainda não o fez, baixe o exemplo do git:
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/CDC_Kafka_LabEste é o arquivo docker-compose que você usará. Ele inicia um Cluster de Três Nós do ScyllaDB:
version: "3"
services:
scylla-node1:
container_name: scylla-node1
image: scylladb/scylla:5.0.0
ports:
- 9042:9042
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node2:
container_name: scylla-node2
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node3:
container_name: scylla-node3
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0Inicie o cluster do ScyllaDB:
docker-compose -f docker-compose-scylladb.yml up -dAguarde um minuto ou mais e verifique se o cluster do ScyllaDB está ativo e em status normal:
docker exec scylla-node1 nodetool statusEm seguida, você usará cqlsh para interagir com o ScyllaDB. Crie um keyspace e uma tabela com CDC habilitado, e insira uma linha na tabela:
docker exec -ti scylla-node1 cqlsh
CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
exit[guy@fedora cdc_test]$ docker-compose -f docker-compose-scylladb.yml up -d
Creating scylla-node1 ... done
Creating scylla-node2 ... done
Creating scylla-node3 ... done
[guy@fedora cdc_test]$ docker exec scylla-node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Endereço Carga Tokens Possui Host ID Rack
UN 172.19.0.3 ? 256 ? 4d4eaad4-62a4-485b-9a05-61432516a737 rack1
UN 172.19.0.2 496 KB 256 ? bec834b5-b0de-4d55-b13d-a8aa6800f0b9 rack1
UN 172.19.0.4 ? 256 ? 2788324e-548a-49e2-8337-976897c61238 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
[guy@fedora cdc_test]$ docker exec -ti scylla-node1 cqlsh
Connected to at 172.19.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
cqlsh> CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
cqlsh> INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
cqlsh> exit
[guy@fedora cdc_test]$ Configuração do Confluent e do Conector
Para iniciar um servidor Kafka, você usará a plataforma Confluent, que fornece uma GUI web amigável para acompanhar tópicos e mensagens. A plataforma Confluent fornece um arquivo docker-compose.yml para configurar os serviços.
Nota: não é assim que você usaria o Apache Kafka em produção. O exemplo é útil apenas para fins de treinamento e desenvolvimento. Obtenha o arquivo:
wget -O docker-compose-confluent.yml https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.3.0-post/cp-all-in-one/docker-compose.ymlEm seguida, baixe o conector CDC do ScyllaDB:
wget -O scylla-cdc-plugin.jar https://github.com/scylladb/scylla-cdc-source-connector/releases/download/scylla-cdc-source-connector-1.0.1/scylla-cdc-source-connector-1.0.1-jar-with-dependencies.jarAdicione o conector CDC ScyllaDB ao diretório de plugins do serviço Confluent Connect usando um volume Docker, editando o arquivo docker-compose-confluent.yml para adicionar as duas linhas conforme abaixo, substituindo o diretório pelo diretório do seu arquivo scylla-cdc-plugin.jar.
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
+ volumes:
+ - <directory>/scylla-cdc-plugin.jar:/usr/share/java/kafka/plugins/scylla-cdc-plugin.jar
depends_on:
- broker
- schema-registryInicie os serviços Confluent:
docker-compose -f docker-compose-confluent.yml up -dAguarde um minuto ou mais, depois acesse http://localhost:9021 para a GUI da web Confluent.
Adicione o ScyllaConnector usando o dashboard Confluent:
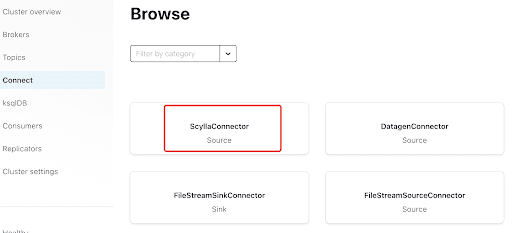
Adicione o Scylla Connector clicando no plugin:
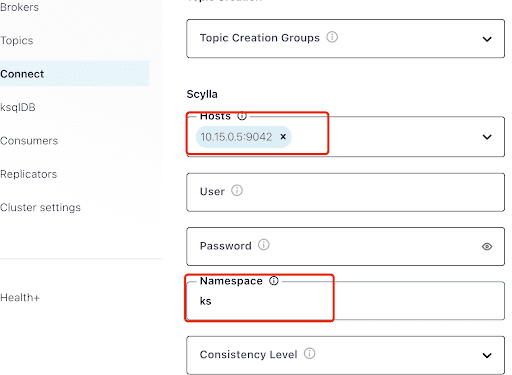
Preencha o “Hosts” com o endereço IP de um dos nós Scylla (você pode ver isso no resultado do comando nodetool status) e porta 9042, que é escutada pelo serviço ScyllaDB.
O “Namespace” é o keyspace que você criou anteriormente no ScyllaDB.
Observe que pode levar um minuto ou mais para que ks.my_table apareça:
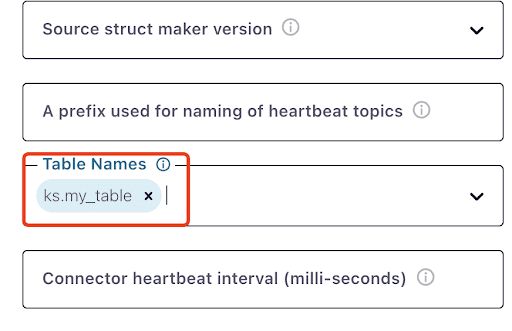
Teste de Mensagens Kafka
Você pode ver que MyScyllaCluster.ks.my_table é o tópico criado pelo conector CDC ScyllaDB.
Agora, verifique as mensagens Kafka a partir do painel de Tópicos:
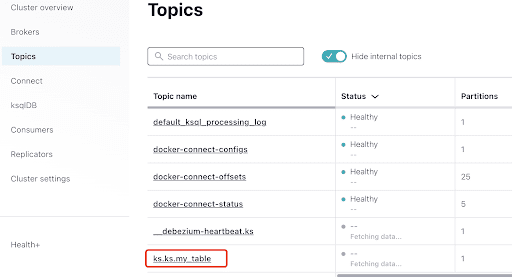
Selecione o tópico, que é o mesmo do nome do keyspace e da tabela que você criou no ScyllaDB:
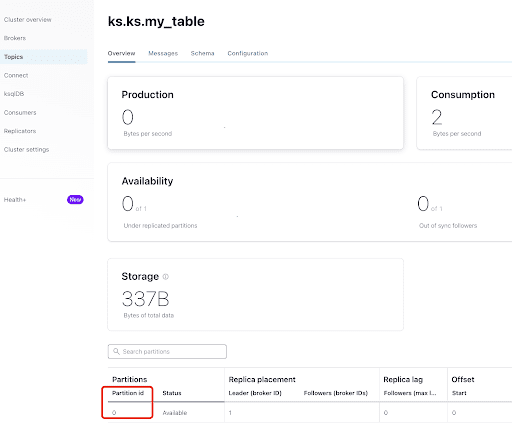
A partir da aba “Visão Geral”, você pode ver as informações do tópico. No final, mostra que este tópico está no partition 0.
A partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion. The records in the partitions are each assigned a sequential identifier called the offset, which is unique for each record within the partition. The offset is an incremental and immutable number maintained by Kafka.
Como você já sabe, as mensagens CDC do ScyllaDB são enviadas para o tópico ks.my_table, e o id da partição do tópico é 0. Em seguida, vá para a aba “Mensagens” e insira o id da partição 0 no campo “offset”:
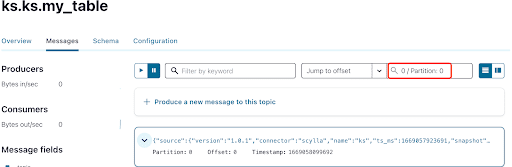
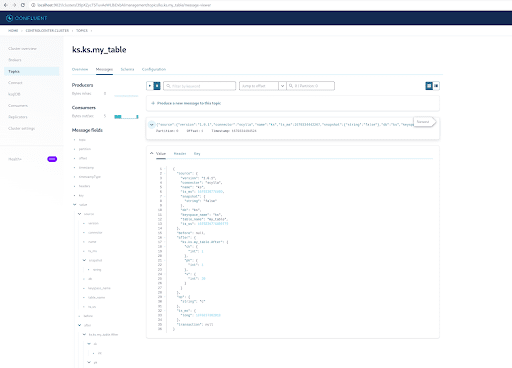
Você pode ver na saída das mensagens do tópico Kafka que o evento de INSERT da tabela ScyllaDB e os dados foram transferidos para mensagens Kafka pelo Scylla CDC Source Connector. Clique na mensagem para visualizar as informações completas da mensagem:
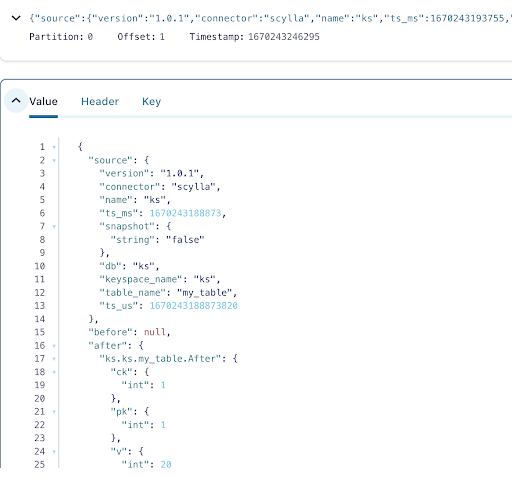
A mensagem contém o nome da tabela ScyllaDB e o nome do keyspace com a hora, assim como o status dos dados antes e depois da ação. Como se trata de uma operação de inserção, os dados antes da inserção são nulos.
Em seguida, insira outra linha na tabela ScyllaDB:
docker exec -ti scylla-node1 cqlsh
INSERT INTO ks.my_table(pk, ck, v) VALUES (200, 50, 70);Agora, no Kafka, espere alguns segundos e poderá ver os detalhes da nova Mensagem:
Limpeza
Uma vez que você terminou de trabalhar neste laboratório, você pode parar e remover os contêineres e imagens do Docker.
Para visualizar uma lista de todos os IDs de contêiner:
docker container ls -aqEntão você pode parar e remover os contêineres que não estão mais sendo usados:
docker stop <ID_or_Name>
docker rm <ID_or_Name>Mais tarde, se quiser reexecutar o laboratório, você pode seguir os passos e usar o docker-compose como antes.
Resumo
Com o conector de origem CDC, um plugin Kafka compatível com Kafka Connect, você pode capturar todas as alterações de nível de linha da tabela ScyllaDB (INSERT, UPDATE, ou DELETE) e converter esses eventos em mensagens Kafka. Você pode então consumir os dados de outras aplicações ou realizar qualquer outra operação com o Kafka.
Source:
https://dzone.com/articles/change-data-capture-apache-kafka-and-scylladb