













Logs frequentemente ocupam a maioria dos ativos de dados de uma empresa. Exemplos de logs incluem logs de negócios (como logs de atividade do usuário) e logs de Operação e Manutenção de servidores, bancos de dados, dispositivos de rede ou IoT.
Os logs são o anjo da guarda dos negócios. Por um lado, eles fornecem alertas de risco do sistema e ajudam os engenheiros a localizar rapidamente as causas raiz em casos de solução de problemas. Por outro lado, se você ampliar o alcance temporal, poderá identificar algumas tendências e padrões úteis, para não mencionar que os logs de negócios são a base das percepções sobre os usuários.
No entanto, os logs podem ser um desafio porque:
- Eles fluem em como loucos. Cada evento do sistema ou clique do usuário gera um log. Uma empresa frequentemente produz dezenas de bilhões de novos logs por dia.
- Eles são volumosos. Os logs são destinados a permanecer. Eles podem não ser úteis até que sejam. Assim, uma empresa pode acumular até PBs de dados de log, muitos dos quais são raramente acessados, mas ocupam um espaço de armazenamento enorme.
- Eles devem ser rápidos de carregar e encontrar. Localizar o log alvo para solução de problemas é literalmente como procurar uma agulha num palheiro. As pessoas desejam a escrita de logs em tempo real e respostas em tempo real às consultas de logs.
Agora você pode ter uma imagem clara do que é um sistema ideal de processamento de logs. Ele deve suportar o seguinte:
- Ingestão de dados em tempo real de alta capacidade: Deve ser capaz de escrever logs em massa e torná-los visíveis imediatamente.
- Armazenamento de baixo custo: Deve ser capaz de armazenar grandes quantidades de logs sem custar muitos recursos.
- Pesquisa em tempo real de texto: Deve ser capaz de realizar pesquisas de texto rapidamente.
Soluções Comuns: Elasticsearch e Grafana Loki
Existem duas soluções comuns de processamento de logs no setor, exemplificadas por Elasticsearch e Grafana Loki, respectivamente.
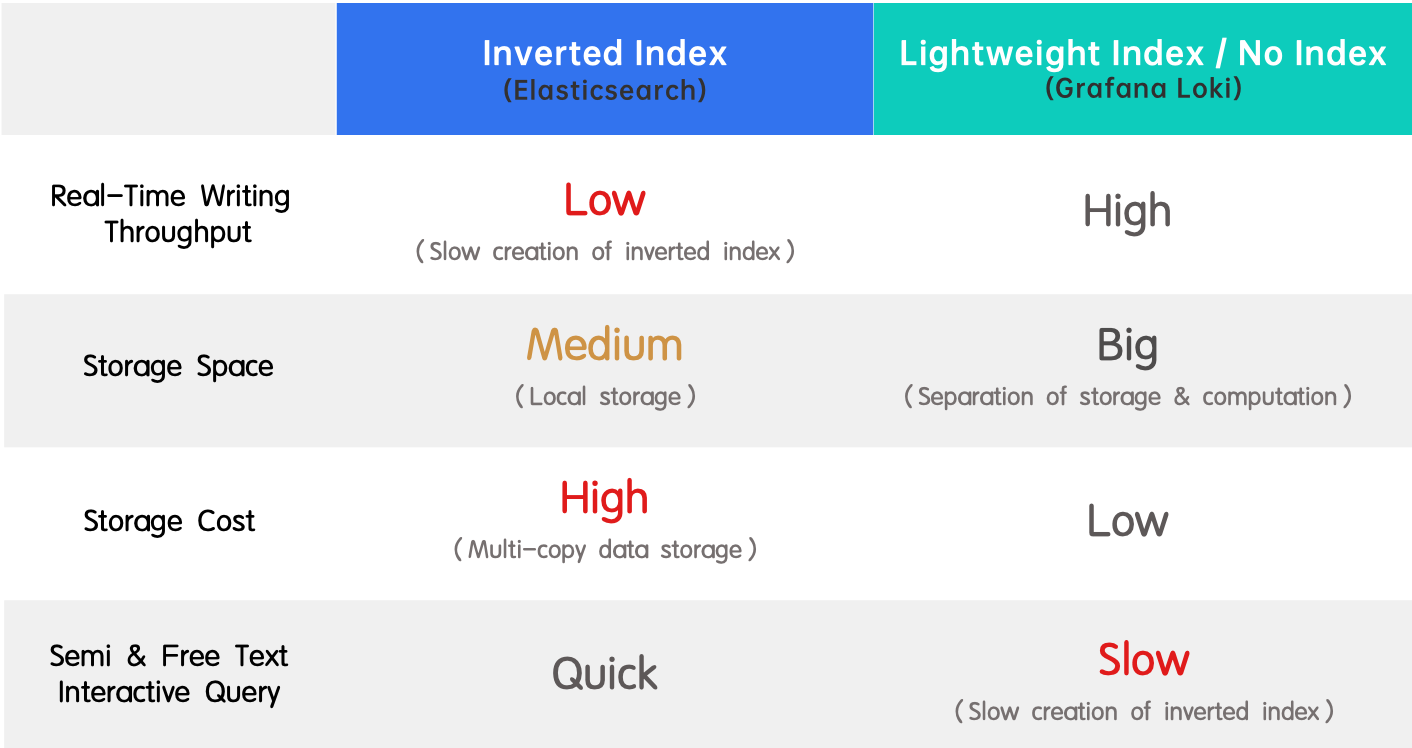
- Índice invertido (Elasticsearch): É amplamente adotado devido ao seu suporte para pesquisa de texto completo e alta performance. A desvantagem é a baixa taxa de transferência na escrita em tempo real e o alto consumo de recursos na criação do índice.
- Índice leve / sem índice (Grafana Loki): É o oposto de um índice invertido, pois possui alta taxa de transferência na escrita em tempo real e custo de armazenamento baixo, mas oferece consultas lentas.
Introdução ao Índice Invertido
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
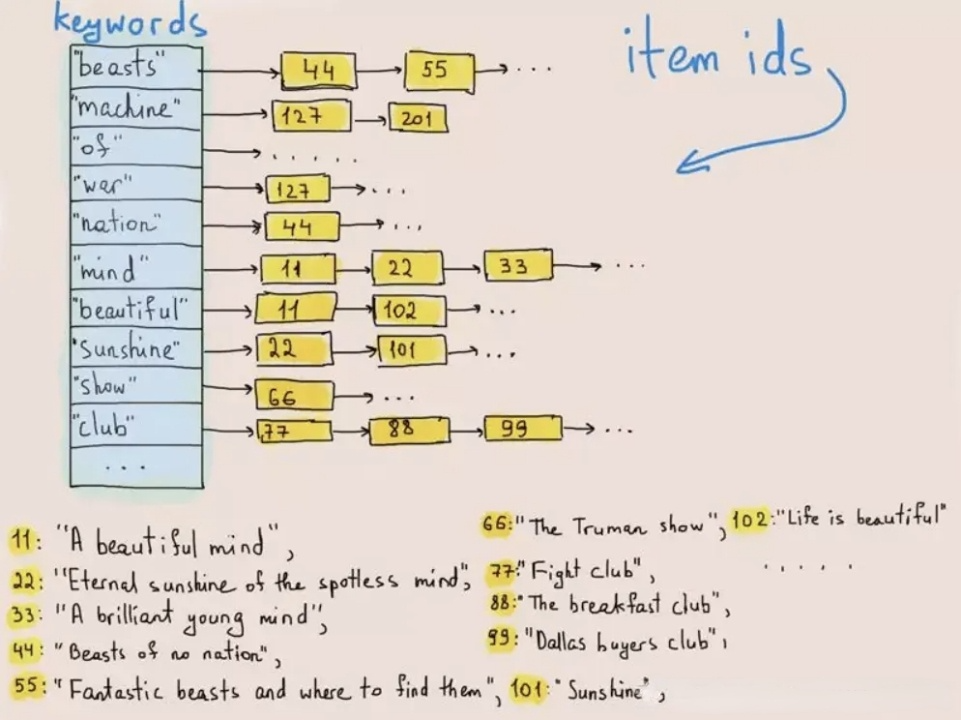
O índice invertido foi originalmente usado para recuperar palavras ou frases em textos. A figura abaixo ilustra como isso funciona:
Ao escrever dados, o sistema tokeniza textos em termos e armazena esses termos em uma lista de postings que mapeia termos para o ID da linha onde eles existem. Nas consultas de texto, o banco de dados encontra o correspondente ID de linha da palavra-chave (termo) na lista de postings e busca a linha alvo com base no ID de linha. Dessa forma, o sistema não precisa percorrer todo o conjunto de dados, o que melhora a velocidade das consultas em ordens de magnitude.
No processo de indexação invertida do Elasticsearch, a rápida recuperação de informações ocorre às custas da velocidade de escrita, da taxa de transferência de escrita e do espaço de armazenamento. Por quê? Primeiro, a tokenização, a ordenação do dicionário e a criação do índice invertido são todas operações intensivas em CPU e memória. Em segundo lugar, o Elasticssearch precisa armazenar os dados originais, o índice invertido e uma cópia extra de dados armazenados em colunas para acelerar as consultas. Isso representa uma tripla redundância.
Mas sem um índice invertido, o Grafana Loki, por exemplo, prejudica a experiência do usuário com consultas lentas, que é o maior ponto de dor para engenheiros na análise de logs.
Em resumo, o Elasticsearch e o Grafana Loki representam diferentes trade-offs entre alta taxa de transferência de escrita, baixo custo de armazenamento e desempenho de consulta rápida. E se eu lhe disser que há uma maneira de ter tudo isso? Introduzimos índices invertidos no Apache Doris 2.0.0 e otimizamos ainda mais para alcançar duas vezes mais rápido desempenho de consulta de logs do que o Elasticsearch com 1/5 do espaço de armazenamento que ele usa. Combinando ambos os fatores, é uma solução 10 vezes melhor.
Índice Invertido no Apache Doris
Geralmente, existem duas maneiras de implementar índices: sistema de indexação externo ou índices integrados.
Sistema de indexação externo: Você conecta um sistema de indexação externo ao seu banco de dados. Na ingestão de dados, os dados são importados para ambos os sistemas. Após o sistema de indexação criar índices, ele exclui os dados originais dentro de si. Quando os usuários de dados inserirem uma consulta, o sistema de indexação fornecerá os IDs dos dados relevantes, e então o banco de dados procurará os dados alvo com base nos IDs.
Criar um sistema de indexação externo é mais fácil e menos intrusivo para o banco de dados, mas vem com algumas falhas irritantes:
- A necessidade de gravar dados em dois sistemas pode resultar em inconsistência de dados e redundância de armazenamento.
- A interação entre o banco de dados e o sistema de indexação traz sobrecargas, então quando os dados alvo são enormes, a consulta entre os dois sistemas pode ser lenta.
- É exaustivo manter dois sistemas.
Em Apache Doris, escolhemos o caminho oposto. Índices invertidos internos são mais difíceis de criar, mas uma vez feitos, são mais rápidos, mais amigáveis ao usuário e de manutenção fácil.
No Apache Doris, os dados são organizados da seguinte forma. Os índices são armazenados na Região de Índice:
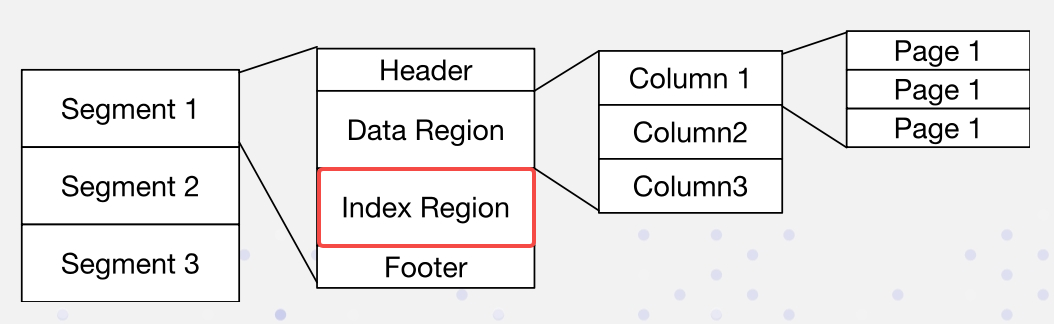
Implementamos índices invertidos de maneira não intrusiva:
- Ingestão e compactação de dados: Enquanto um arquivo de segmento é escrito no Doris, um arquivo de índice invertido também será escrito. O caminho do arquivo de índice é determinado pelo ID do segmento e o ID do índice. As linhas nos segmentos correspondem aos docs nos índices, assim como o RowID e o DocID.
- Pergunta: Se a cláusula
whereincluir uma coluna com índice invertido, o sistema procurará no arquivo de índice, retornará uma lista de DocID e converterá essa lista de DocID em um Bitmap de RowID. Sob o mecanismo de filtragem de RowID do Apache Doris, apenas as linhas alvo serão lidas. É assim que as consultas são aceleradas.
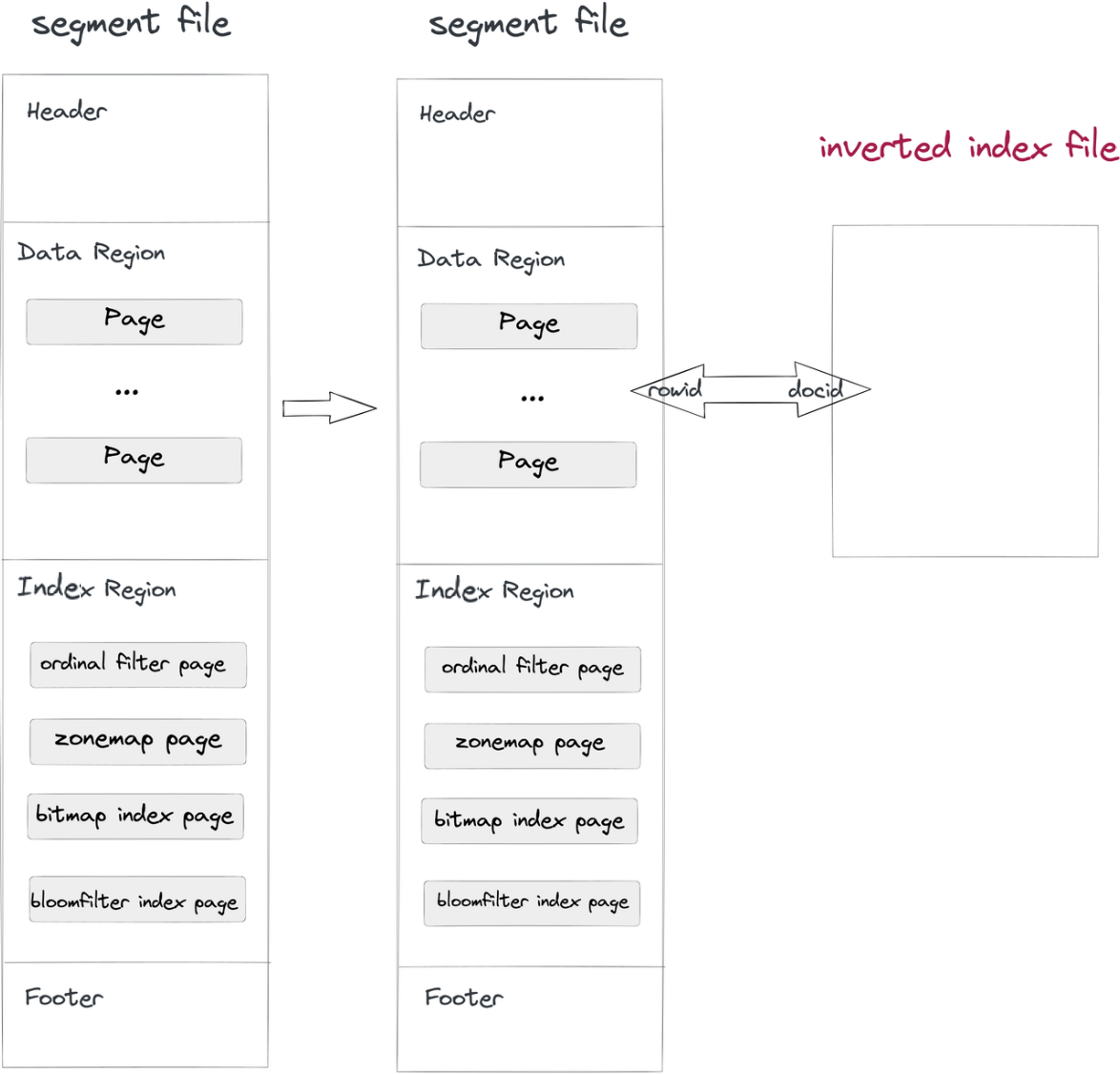
Tal método não intrusivo separa o arquivo de índice dos arquivos de dados, permitindo que você faça quaisquer alterações nos índices invertidos sem se preocupar em afetar os próprios arquivos de dados ou outros índices.
Otimizações para Índice Invertido
Otimizações Gerais
C++ Implementation and Vectorization
Diferentemente do Elasticsearch, que usa Java, o Apache Doris implementa C++ em seus módulos de armazenamento, mecanismo de execução de consulta e índices invertidos. Em comparação com Java, C++ oferece melhor desempenho, permite uma vectorização mais fácil e não produz overheads de GC do JVM. Nós vectorizamos todos os passos do índice invertido no Apache Doris, como tokenização, criação de índice e consultas. Para lhe dar uma perspectiva, no índice invertido, o Apache Doris escreve dados a uma velocidade de 20MB/s por núcleo, o que é quatro vezes maior que o Elasticsearch (5MB/s).
Armazenamento e Compactação em Colunas
O Apache Lucene estabelece a base para índices invertidos no Elasticsearch. Como o próprio Lucene é construído para suportar armazenamento de arquivos, ele armazena dados em um formato orientado a linhas.
No Apache Doris, índices invertidos para colunas diferentes são isolados uns dos outros, e os arquivos de índice invertido adotam armazenamento em colunas para facilitar a vectorização e a compactação de dados.
Ao utilizar a compressão Zstandard, o Apache Doris alcança uma taxa de compressão que varia de 5:1 a 10:1, velocidades de compressão mais rápidas e um uso de espaço 50% menor do que a compressão GZIP.
Árvores BKD para Colunas Numéricas / Data e Hora
O Apache Doris implementa árvores BKD para colunas numéricas e de data e hora. Isso não apenas aumenta o desempenho das consultas de faixa, mas também é um método mais econômico em termos de espaço do que converter essas colunas em strings de comprimento fixo. Outras vantagens incluem:
- Consultas de faixa eficientes: É capaz de localizar rapidamente a faixa de dados alvo nas colunas numéricas e de data e hora.
- Menos espaço de armazenamento: Agrupa e comprime blocos de dados adjacentes para reduzir os custos de armazenamento.
- Suporte para dados multidimensionais: As árvores BKD são escaláveis e adaptativas a tipos de dados multidimensionais, como pontos GEO e faixas.
Além das árvores BKD, fizemos otimizações adicionais nas consultas em colunas numéricas e de data e hora.
- Otimização para cenários de baixa cardinalidade: Otimizamos o algoritmo de compressão para cenários de baixa cardinalidade, de modo que a descompressão e desserialização de grandes quantidades de listas invertidas consumirão menos recursos de CPU.
- Pré-busca: Para cenários de alta taxa de acerto, adotamos a pré-busca. Se a taxa de acerto exceder um determinado limite, o Doris pulará o processo de indexação e iniciará o processo de filtragem de dados.
Otimizações personalizadas para OLAP
Geralmente, a análise de logs é um tipo simples de consulta que não requer recursos avançados (por exemplo, pontuação de relevância no Apache Lucene). A capacidade fundamental de uma ferramenta de processamento de logs é consultas rápidas e custos de armazenamento baixos. Portanto, no Apache Doris, simplificamos a estrutura de índice invertido para atender às necessidades de um banco de dados OLAP.
- No ingestão de dados, impedimos que múltiplas threads escrevam dados no mesmo índice, evitando assim os custos adicionais causados pela contenção de bloqueios.
- Descartamos arquivos de índice direto e arquivos Norm para liberar espaço de armazenamento e reduzir os custos de E/S.
- Simplificamos a lógica de computação de pontuação e classificação de relevância para reduzir ainda mais os custos e aumentar o desempenho.
Considerando que os logs são particionados por faixa de tempo e os logs históricos são visitados com menos frequência, planejamos fornecer uma gestão de índices mais granular e flexível em futuras versões do Apache Doris:
- Criar um índice invertido para uma partição de dados especificada: criar um índice para logs dos últimos sete dias, etc.
- Excluir índice invertido para uma partição de dados especificada: excluir índice para logs de mais de um mês atrás, etc. (para liberar espaço de índice).
Avaliação comparativa
Testamos o Apache Doris em conjuntos de dados públicos contra o Elasticsearch e o ClickHouse.
Para uma comparação justa, garantimos a uniformidade das condições de teste, incluindo ferramenta de benchmarking, conjuntos de dados e hardware.
Apache Doris vs. Elasticsearch
- Ferramenta de Benchmark: ES Rally, a ferramenta oficial de teste para Elasticsearch
- Conjunto de Dados: Registros do Servidor HTTP da Copa do Mundo de 1998 (conjunto de dados autônomo no ES Rally)
- Tamanho dos Dados (Antes da Compactação): 32G, 247 milhões de linhas, 134 bytes por linha (em média)
- Consulta: 11 consultas, incluindo pesquisa por palavras-chave, consulta de intervalo, agregação e classificação; Cada consulta é executada serialmente 100 vezes.
- Ambiente: 3 máquinas virtuais em nuvem com 16C 64G cada
Resultados do Apache Doris:
- Velocidade de Escrita: 550 MB/s, 4,2 vezes maior que o Elasticsearch
- Taxa de Compactação: 10:1
- Uso de Armazenamento: 20% do que o Elasticsearch
- Tempo de Resposta: 43% do que o Elasticsearch

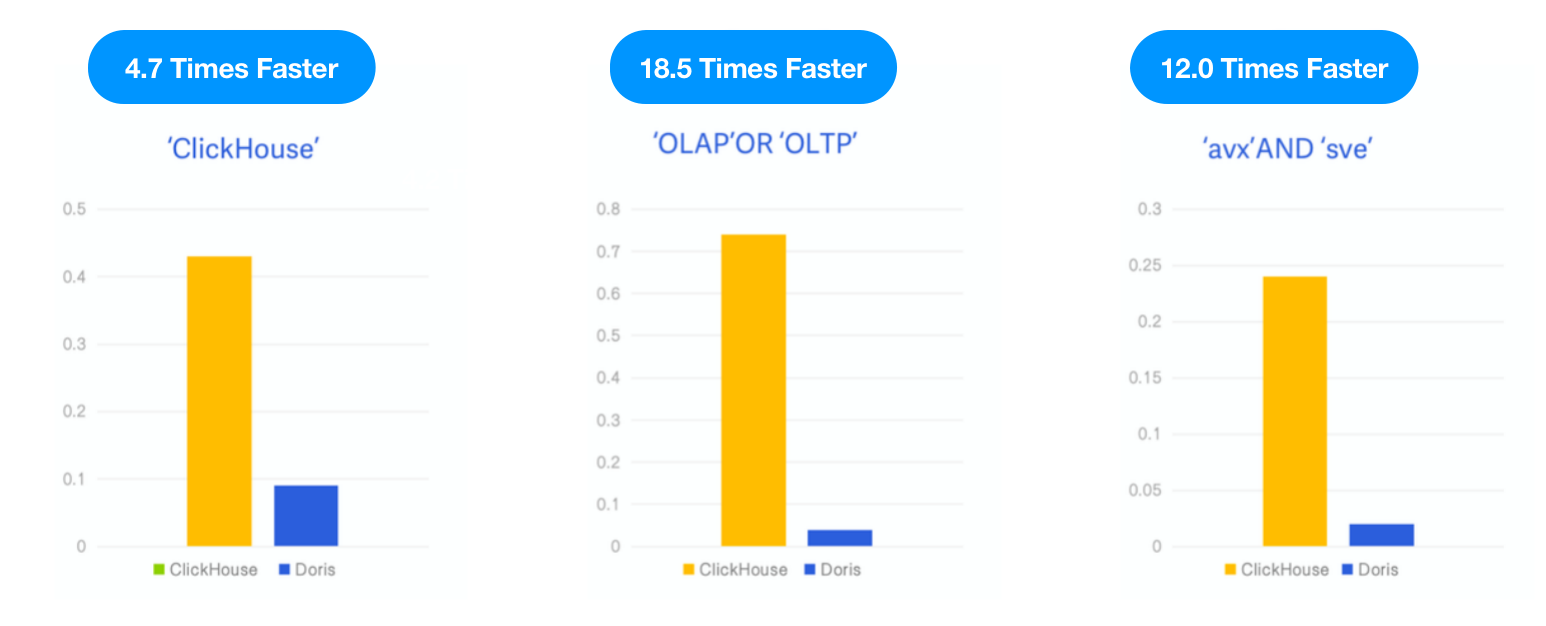
Apache Doris vs. ClickHouse
Como o ClickHouse lançou um índice invertido como uma funcionalidade experimental na versão v23.1, testamos o Apache Doris com o mesmo conjunto de dados e SQL conforme descrito no blog do ClickHouse e comparamos o desempenho dos dois sob os mesmos recursos de teste, caso e ferramenta.
- Dados: 6,7G, 28,73 milhões de linhas, conjunto de dados do Hacker News, formato Parquet
- Consulta: 3 pesquisas por palavras-chave, contando o número de ocorrências das palavras-chave “ClickHouse,” “OLAP,” OR “OLTP,” e “avx” AND “sve”.
- Ambiente: 1 máquina virtual em nuvem com 16C 64G
Resultado: O Apache Doris foi 4,7 vezes, 18,5 vezes e 12 vezes mais rápido que o ClickHouse nas três consultas, respectivamente.
Uso e Exemplo
- Conjunto de Dados: um milhão de registros de comentários do Hacker News
Etapa 1: Especificar o índice invertido na tabela de dados durante a criação da tabela.
Parâmetros:
- INDEX idx_comment (
comment): criar um índice chamado “idx_comment” para a coluna “comment” - USING INVERTED: especificar índice invertido para a tabela
- PROPERTIES(“parser” = “english”): especificar a linguagem de tokenização para Inglês
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(Nota: Você pode adicionar um índice a uma tabela existente através de ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). Diferentemente do índice inteligente e do índice secundário, a criação de um índice invertido envolve apenas a leitura da coluna de comentário, portanto pode ser muito mais rápida.)
Etapa 2: Recuperar as palavras “OLAP” e “OLTP” na coluna de comentário com MATCH_ALL. O tempo de resposta aqui foi 1/10 do que no método de correspondência rígida com like. (A lacuna de desempenho aumenta à medida que o volume de dados aumenta.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
Para mais introdução de recursos e guia de uso, consulte a documentação: Índice Invertido
Encerramento
Em suma, o que contribui para a dez vezes maior eficácia custo-benefício do Apache Doris em relação ao Elasticsearch são suas otimizações personalizadas para processamento analítico online (OLAP) no uso de índices invertidos, apoiadas pelo mecanismo de armazenamento em colunas, estrutura de processamentos em paralelo em massa, motor de consulta vetorizado e otimizador baseado em custos do Apache Doris.
Embora tenhamos orgulho de nossa própria solução de índice invertido, entendemos que benchmarks auto-publicados podem ser controversos, por isso estamos abertos a feedback de qualquer testador terceirizado e veremos como Apache Doris se comporta em casos do mundo real.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co