













As organizações iniciam a adoção de streaming de dados com um único cluster Apache Kafka para implementar os primeiros casos de uso. A necessidade de governança de dados e segurança em toda a empresa, mas com diferentes SLAs, latência e requisitos de infraestrutura, introduz novos clusters Kafka. Múltiplos clusters Kafka são a norma, não uma exceção. Os casos de uso incluem integração híbrida, agregação, migração e recuperação de desastres. Este post de blog explora histórias de sucesso do mundo real e estratégias de cluster para diferentes implantações do Kafka em diferentes setores.

O Apache Kafka: O Padrão de Fato para Arquiteturas Orientadas a Eventos e Streaming de Dados
O Apache Kafka é uma plataforma de streaming de eventos distribuída e de código aberto projetada para processamento de dados de alta taxa de transferência e baixa latência. Permite publicar, se inscrever, armazenar e processar fluxos de registros em tempo real.
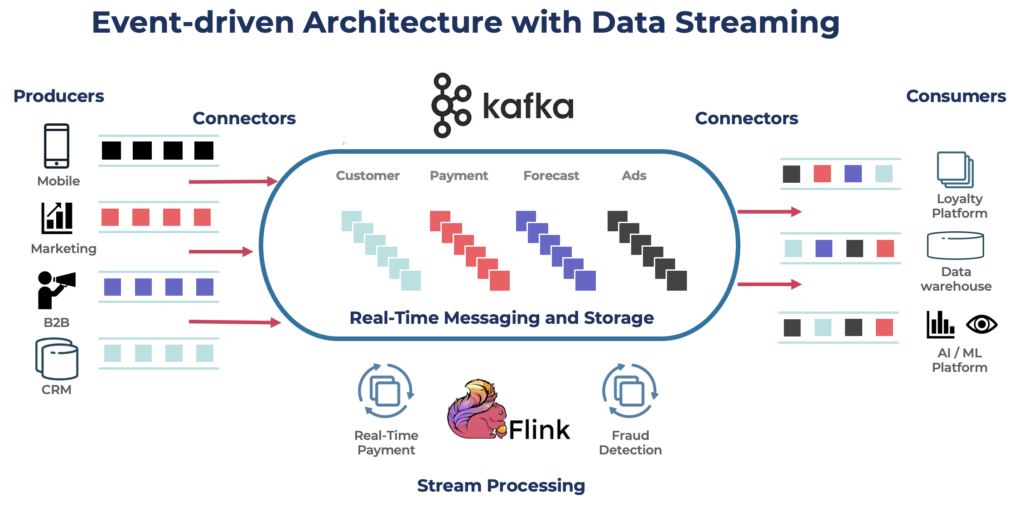
Kafka é uma escolha popular para construir pipelines de dados em tempo real e aplicações de streaming. O protocolo Kafka se tornou o padrão de facto para streaming de eventos em diversos frameworks, soluções e serviços em nuvem. Ele suporta cargas de trabalho operacionais e analíticas com recursos como armazenamento persistente, escalabilidade e tolerância a falhas. Kafka inclui componentes como Kafka Connect para integração e Kafka Streams para processamento de streams, tornando-o uma ferramenta versátil para vários casos de uso orientados a dados.
Embora Kafka seja famoso por casos de uso em tempo real, muitos projetos utilizam a plataforma de streaming de dados para consistência de dados em toda a arquitetura empresarial, incluindo bancos de dados, lakes de dados, sistemas legados, Open APIs e aplicações nativas da nuvem.
Tipos Diferentes de Cluster do Apache Kafka
Kafka é um sistema distribuído. Uma configuração de produção geralmente requer pelo menos quatro brokers. Portanto, a maioria das pessoas automaticamente assume que tudo o que você precisa é de um único cluster distribuído que você escala quando adiciona throughput e casos de uso. Isso não está errado no início. Mas…
Um cluster Kafka não é a resposta certa para todos os casos de uso. Várias características influenciam a arquitetura de um cluster Kafka:
- Disponibilidade: Tempo de inatividade zero? SLA de 99,99% de uptime? Análises não críticas?
- Latência: Processamento de ponta a ponta em menos de 100ms (incluindo o processamento)? Pipeline de data warehouse de ponta a ponta em 10 minutos? Viagem no tempo para reprocessamento de eventos históricos?
- Custo: Valor versus custo? O custo total de propriedade (TCO) é importante. Por exemplo, na nuvem pública, a rede pode representar até 80% do custo total do Kafka!
- Segurança e Privacidade de Dados: Privacidade de dados (dados PCI, GDPR, etc.)? Governança de dados e conformidade? Criptografia de ponta a ponta no nível de atributo? Trazer sua própria chave? Acesso público e compartilhamento de dados? Ambiente de borda com isolamento de rede?
- Throughput e Tamanho dos Dados: Transações críticas (tipicamente de baixo volume)? Grandes volumes de dados (fluxo de cliques, sensores IoT, logs de segurança, etc.)?
Tópicos relacionados como on-premise versus nuvem pública, regional versus global, e muitos outros requisitos também afetam a arquitetura do Kafka.
Estratégias e Arquiteturas de Cluster do Apache Kafka
Um único cluster do Kafka é frequentemente o ponto de partida certo para a sua jornada de streaming de dados. Ele pode lidar com múltiplos casos de uso de diferentes domínios de negócio e processar gigabytes por segundo (se operado e dimensionado da maneira correta).
No entanto, dependendo dos requisitos do seu projeto, você pode precisar de uma arquitetura empresarial com múltiplos clusters do Kafka. Aqui estão alguns exemplos comuns:
- Arquitetura Híbrida: Integração de dados e sincronização de dados uni ou bidirecional entre vários data centers. Frequentemente, a conectividade entre um data center local e um provedor de serviços de nuvem pública. A transferência de dados de sistemas legados para análise em nuvem é um dos cenários mais comuns. Mas a comunicação de comando e controle também é possível, ou seja, enviar decisões/recomendações/transações para um ambiente regional (por exemplo, armazenar um pagamento ou pedido de um aplicativo móvel no mainframe).
- Múltiplas Regiões/Multi-Nuvem: Replicação de dados por motivos de conformidade, custo ou privacidade de dados. O compartilhamento de dados geralmente inclui apenas uma fração dos eventos, não todos os Tópicos do Kafka. A área da saúde é uma das muitas indústrias que seguem nessa direção.
- Recuperação de Desastres: Replicação de dados críticos em modo ativo-ativo ou ativo-passivo entre diferentes data centers ou regiões na nuvem. Inclui estratégias e ferramentas para mecanismos de fail-over e fallback no caso de um desastre para garantir a continuidade dos negócios e conformidade.
- Agregação: Agrupamento de clusters regionais para processamento local (por exemplo, pré-processamento, ETL em streaming, aplicativos de negócios de processamento em stream) e replicação de dados curados para o grande data center ou nuvem. As lojas de varejo são um excelente exemplo.
- Migração: Modernização de TI com uma migração de um ambiente local para a nuvem ou de um sistema de código aberto auto-gerenciado para um SaaS totalmente gerenciado. Essas migrações podem ser feitas sem tempo de inatividade ou perda de dados, enquanto os negócios continuam durante a transição.
- Borda (Desconectado/Sem Conexão): Segurança, custo ou latência exigem implantações na borda, por exemplo, em uma fábrica ou loja de varejo. Algumas indústrias implantam em ambientes críticos de segurança com gateway de hardware unidirecional e diodo de dados.
- Broker Único: Não é resiliente, mas é suficiente para cenários como incorporar um broker Kafka em uma máquina ou em um PC Industrial (IPC) e replicar dados agregados para um grande cluster de análise de nuvem Kafka. Um bom exemplo é a instalação de streaming de dados (incluindo integração e processamento) no computador de um soldado no campo de batalha.
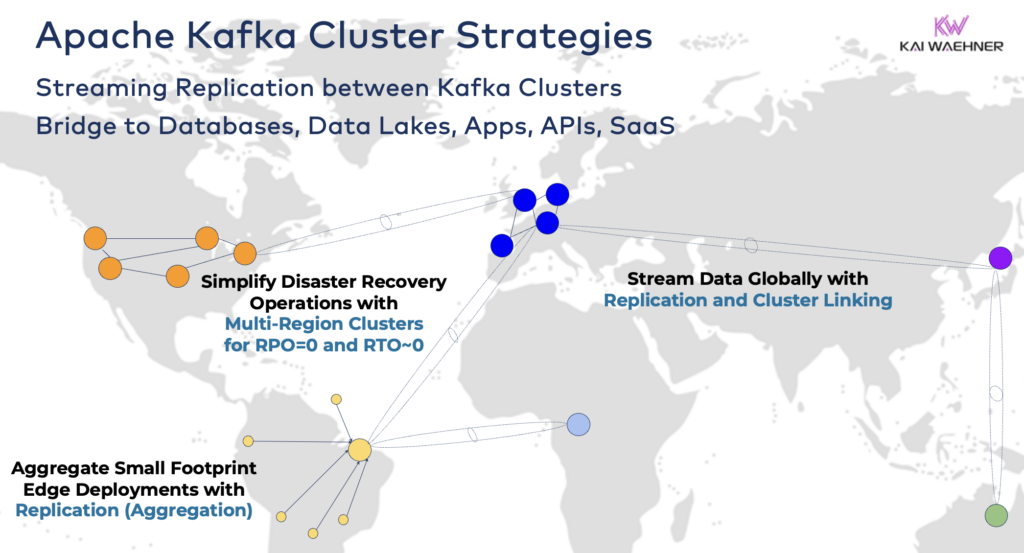
Conectando Clusters Híbridos do Kafka
Essas opções podem ser combinadas. Por exemplo, um único broker na borda normalmente replica alguns dados selecionados para um centro de dados remoto. Os clusters híbridos têm arquiteturas diferentes dependendo de como são conectados: conexões pela Internet pública, link privado, VPC peering, transit gateway, etc.
Ao longo dos anos, ao acompanhar o desenvolvimento do Confluent Cloud, subestimei o tempo de engenharia necessário para segurança e conectividade. No entanto, a falta de pontes de segurança são os principais obstáculos para a adoção de um serviço de nuvem Kafka. Portanto, é indispensável fornecer diversas pontes de segurança entre os clusters Kafka além da simples internet pública.
Existem até casos de uso em que as organizações precisam replicar dados do centro de dados para a nuvem, mas o serviço de nuvem não tem permissão para iniciar a conexão. A Confluent construiu um recurso específico, “link iniciado pela fonte”, para atender a esses requisitos de segurança, onde a fonte (ou seja, o cluster Kafka local) sempre inicia a conexão – mesmo que os clusters Kafka na nuvem estejam consumindo os dados:
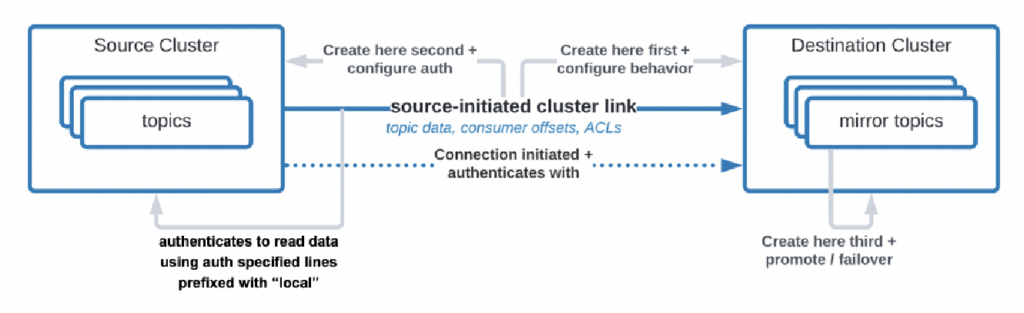 Fonte: Confluent
Fonte: Confluent
Como você pode ver, isso se torna complexo rapidamente. Encontre os especialistas certos para ajudá-lo desde o início, não depois de já ter implantado os primeiros clusters e aplicativos.
Há muito tempo, descrevi em uma apresentação detalhada os padrões de arquitetura para implantações distribuídas, híbridas, de borda e globais do Apache Kafka. Consulte esse conjunto de slides e a gravação em vídeo para obter mais detalhes sobre as opções de implantação e compensações.
RPO vs. RTO = Perda de Dados vs. Tempo de Inatividade
RPO e RTO são dois KPIs críticos que você precisa discutir antes de decidir sobre uma estratégia de cluster Kafka:
- O RPO (Recovery Point Objective) é a quantidade máxima aceitável de perda de dados medida no tempo, indicando com que frequência os backups devem ocorrer para minimizar a perda de dados.
- RTO (Recovery Time Objective) é a duração máxima aceitável do tempo que leva para restaurar as operações comerciais após uma interrupção. Juntamente, eles ajudam as organizações a planejar suas estratégias de backup de dados e recuperação de desastres para equilibrar custo e impacto operacional.
Embora as pessoas frequentemente comecem com o objetivo de RPO = 0 e RTO = 0, elas rapidamente percebem o quão difícil (mas não impossível) é conseguir isso. Você precisa decidir quanto de dados pode perder em um desastre. Você precisa de um plano de recuperação de desastres se um desastre ocorrer. As equipes jurídicas e de conformidade terão que dizer se é aceitável perder alguns conjuntos de dados em caso de desastre ou não. Esses e muitos outros desafios precisam ser discutidos ao avaliar sua estratégia de cluster Kafka.
A replicação entre clusters Kafka com ferramentas como MIrrorMaker ou Cluster Linking é assíncrona e RPO > 0. Apenas um cluster Kafka estendido fornece RPO = 0.
Cluster Kafka Estendido: Zero Perda de Dados Com Replicação Síncrona Entre Data Centers
A maioria das implantações com múltiplos clusters Kafka utiliza replicação assíncrona entre data centers ou nuvens via ferramentas como MirrorMaker ou Confluent Cluster Linking. Isso é suficiente para a maioria dos casos de uso. Mas em caso de desastre, você perde algumas mensagens. O RPO é > 0.
Um cluster Kafka estendido implanta brokers Kafka de um único cluster em três data centers. A replicação é síncrona (pois é assim que o Kafka replica dados dentro de um cluster) e garante zero perda de dados (RPO = 0) – mesmo em caso de desastre!
Por que você não deveria sempre usar clusters estendidos?
- Latência baixa (<~50ms) e conexão estável são necessárias entre os centros de dados.
- São necessários três (!) centros de dados; dois não são suficientes, pois a maioria (quórum) deve reconhecer escritas e leituras para garantir a confiabilidade do sistema.
- Eles são difíceis de configurar, operar e monitorar e muito mais difíceis do que um cluster rodando em um único centro de dados.
- Custo vs. valor não vale a pena em muitos casos de uso; durante um desastre real, a maioria das organizações e casos de uso têm problemas maiores do que perder algumas mensagens (mesmo que sejam dados críticos como um pagamento ou pedido).
Para esclarecer, na nuvem pública, uma região geralmente tem três centros de dados (= zonas de disponibilidade). Portanto, na nuvem, depende dos seus SLAs se uma região de nuvem conta como um cluster estendido ou não. A maioria das ofertas SaaS Kafka são implantadas em um cluster estendido aqui.
Entretanto, muitos cenários de conformidade não consideram um cluster Kafka em uma única região de nuvem como suficiente para garantir SLAs e continuidade dos negócios caso um desastre ocorra.
Confluent desenvolveu um produto dedicado para resolver (alguns desses) desafios: Multi-Region Clusters (MRC). Ele oferece capacidades para realizar replicação síncrona e assíncrona dentro de um cluster Kafka estendido.
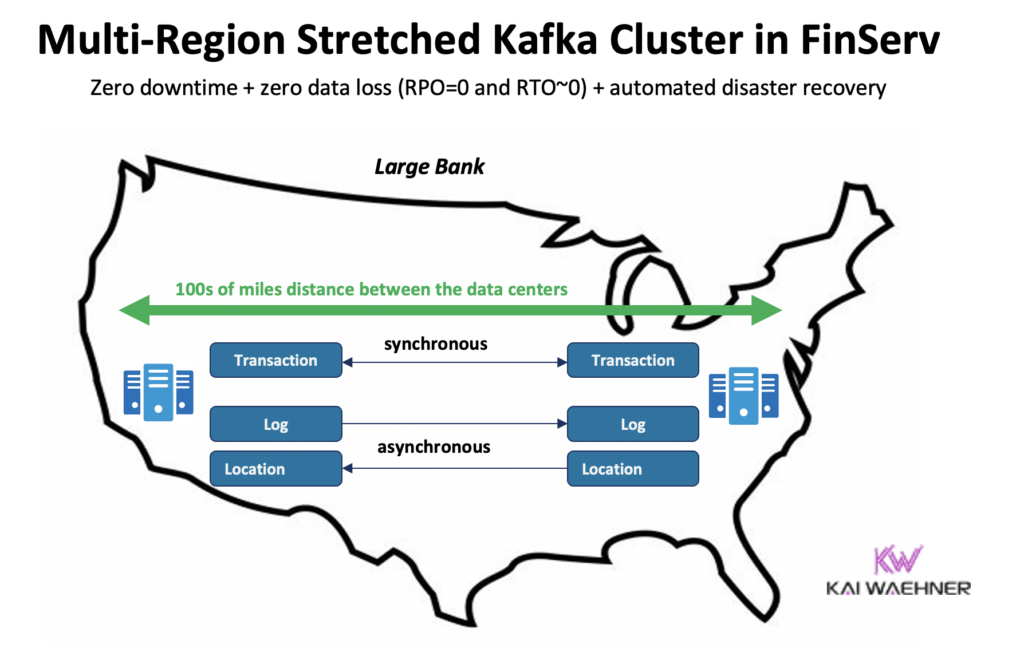
Por exemplo, em um cenário de serviços financeiros, o MRC replica transações críticas de baixo volume de forma síncrona, mas logs de alto volume de forma assíncrona:
- As transações ‘Pagamento’ entram dos EUA Leste e Oeste com replicação totalmente síncrona
- As informações de ‘Log’ e ‘Localização’ no mesmo cluster usam assíncrono – otimizado para latência
- Recuperação de desastres automatizada (zero tempo de inatividade, zero perda de dados)
Mais detalhes sobre clusters Kafka estendidos vs. replicação ativa-ativa / ativa-passiva entre dois clusters Kafka na minha apresentação global do Kafka.
Preços das Ofertas de Nuvem do Kafka (vs. Auto-gerenciado)
As seções acima explicam por que você precisa considerar diferentes arquiteturas do Kafka, dependendo dos requisitos do seu projeto. Clusters Kafka auto-gerenciados podem ser configurados da maneira que você precisa. Na nuvem pública, ofertas totalmente gerenciadas parecem diferentes (da mesma forma que qualquer outro SaaS totalmente gerenciado). Os preços são diferentes porque os fornecedores de SaaS precisam configurar limites razoáveis. O fornecedor deve fornecer SLAs específicos.
O panorama de streaming de dados inclui várias ofertas de nuvem do Kafka. Aqui está um exemplo das ofertas de nuvem atuais da Confluent, incluindo ambientes multi-inquilinos e dedicados com diferentes SLAs, recursos de segurança e modelos de custo.
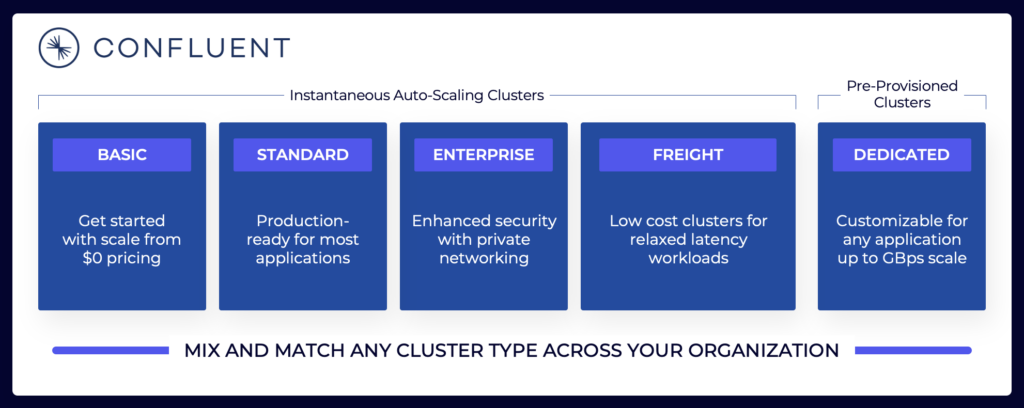 Fonte: Confluent
Fonte: Confluent
Assegure-se de avaliar e compreender os vários tipos de clusters de diferentes fornecedores disponíveis na nuvem pública, incluindo TCO, SLAs de tempo de atividade fornecidos, custos de replicação entre regiões ou provedores de nuvem, e assim por diante. As lacunas e limitações muitas vezes estão intencionalmente ocultas nos detalhes.
Por exemplo, se você usar o Amazon Managed Streaming for Apache Kafka (MSK), você deve estar ciente de que os termos e condições afirmam que “O compromisso de serviço não se aplica a qualquerindisponibilidade, suspensão ou término… causado pelo software do mecanismo subjacente Apache Kafka ou Apache Zookeeper que leva a falhas de solicitação.”
No entanto, preços e SLAs de suporte são apenas uma peça crítica de comparação. Existem muitas “decisões de construir versus comprar” que você tem que tomar como parte da avaliação de uma plataforma de streaming de dados.
Armazenamento do Kafka: Armazenamento em Camadas e Formato de Tabela do Iceberg para Armazenar Dados Apenas uma Vez
Apache Kafka adicionou Armazenamento em Camadas para separar computação e armazenamento. Essa capacidade permite arquiteturas empresariais mais escaláveis, confiáveis e econômicas. O Armazenamento em Camadas para Kafka possibilita um novo tipo de cluster Kafka: Armazenar Petabytes de dados no log de confirmação do Kafka de maneira econômica (como em seu data lake) com timestamps e ordenação garantida para reprocessar dados históricos. A KOR Financial é um bom exemplo de uso do Apache Kafka como um banco de dados para persistência de longo prazo.
Kafka possibilita uma Arquitetura Shift Left para armazenar dados apenas uma vez para conjuntos de dados operacionais e analíticos:

Com isso em mente, pense novamente sobre os casos de uso que descrevi acima para múltiplos clusters Kafka. Você ainda deve replicar dados em lote em repouso no banco de dados, data lake ou lakehouse de um centro de dados ou região de nuvem para outro? Não. Você deve sincronizar dados em tempo real, armazenar os dados uma vez (geralmente em um armazenamento de objetos como o Amazon S3) e, em seguida, conectar todos os mecanismos analíticos como Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery, e assim por diante a esse formato de tabela padrão.
Histórias de Sucesso do Mundo Real para Múltiplos Clusters Kafka
A maioria das organizações possui múltiplos clusters Kafka. Esta seção explora quatro histórias de sucesso em diferentes indústrias:
- Paypal (Serviços Financeiros) – EUA: Pagamentos instantâneos, prevenção de fraudes.
- JioCinema (Telco/Mídia) – APAC: Integração de dados, análise de clique, publicidade, personalização.
- Audi (Automotivo/Fabricação)– EMEA: Carros conectados com requisitos críticos e analíticos.
- New Relic (Software/Cloud)– US: Observabilidade e gerenciamento de desempenho de aplicativos (APM) em todo o mundo.
Paypal: Separação por Zona de Segurança
O PayPal é uma plataforma de pagamento digital que permite aos usuários enviar e receber dinheiro online de forma segura e conveniente em todo o mundo em tempo real. Isso requer uma infraestrutura escalável, segura e compatível com Kafka.
Durante a Black Friday de 2022, o volume de tráfego do Kafka atingiu cerca de 1,3 trilhão de mensagens diariamente. Atualmente, o PayPal possui mais de 85 clusters Kafka e, a cada temporada de festas, eles ampliam sua infraestrutura Kafka para lidar com o aumento de tráfego. A plataforma Kafka continua a escalar perfeitamente para suportar esse crescimento de tráfego sem impacto em seus negócios.
Atualmente, a frota de Kafka do PayPal consiste em mais de 1.500 corretores que hospedam mais de 20.000 tópicos. Os eventos são replicados entre os clusters, oferecendo 99,99% de disponibilidade.
As implantações de clusters Kafka são separadas em diferentes zonas de segurança dentro de um data center:
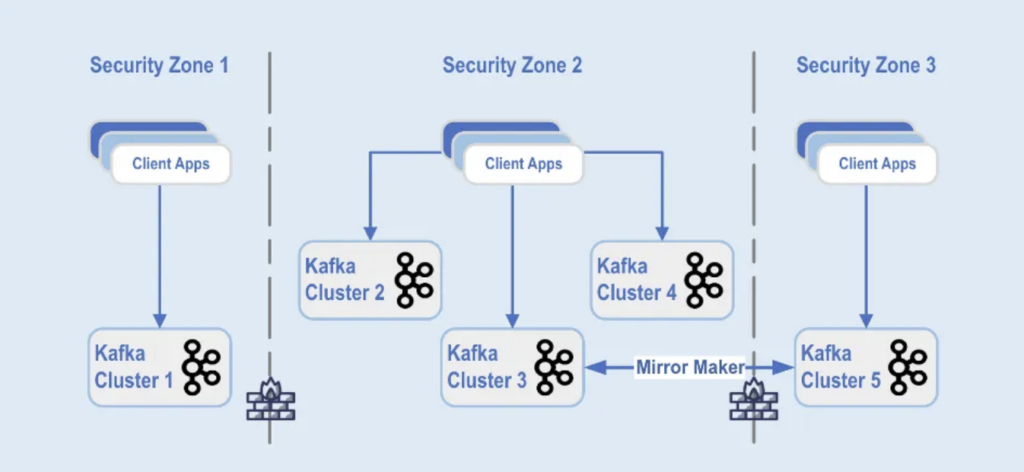 Fonte: Paypal
Fonte: Paypal
Os clusters Kafka são implantados nessas zonas de segurança, com base na classificação de dados e nos requisitos de negócios. A replicação em tempo real com ferramentas como MirrorMaker (neste exemplo, funcionando na infraestrutura Kafka Connect) ou Confluent Cluster Linking (usando uma abordagem mais simples e menos propensa a erros diretamente usando o protocolo Kafka para replicação) é utilizada para espelhar os dados entre os centros de dados, o que ajuda na recuperação de desastres e a alcançar a comunicação entre zonas de segurança.
JioCinema: Separação por Caso de Uso e SLA
JioCinema é uma plataforma de streaming de vídeo em rápido crescimento na Índia. O serviço OTT da telecomunicações é conhecido por sua ampla oferta de conteúdo, incluindo esportes ao vivo como a Indian Premier League (IPL) de críquete, um novo Anime Hub lançado recentemente e planos abrangentes para cobrir grandes eventos como os Jogos Olímpicos de Paris 2024.
A arquitetura de dados aproveita Apache Kafka, Flink e Spark para processamento de dados, conforme apresentado na Kafka Summit India 2024 em Bangalore:
 Fonte: JioCinema
Fonte: JioCinema
O streaming de dados desempenha um papel crucial em diversos casos de uso para transformar as experiências do usuário e a entrega de conteúdo. Mais de dez milhões de mensagens por segundo aprimoram a análise, os insights do usuário e os mecanismos de entrega de conteúdo.
Os casos de uso do JioCinema incluem:
- Comunicação entre Serviços
- Clickstream/Análise
- Rastreador de Anúncios
- Aprendizado de Máquina e Personalização
Kushal Khandelwal, Chefe de Plataforma de Dados, Análise e Consumo no JioCinema, explicou que nem todos os dados são iguais e que as prioridades e SLAs variam conforme o caso de uso:
 Fonte: JioCinema
Fonte: JioCinema
O streaming de dados é uma jornada. Assim como muitas outras organizações em todo o mundo, o JioCinema começou com um grande cluster Kafka usando mais de 1000 Tópicos Kafka e mais de 100.000 Partções Kafka para diversos casos de uso. Com o tempo, uma separação de preocupações em relação aos casos de uso e SLAs se desenvolveu em múltiplos clusters Kafka:
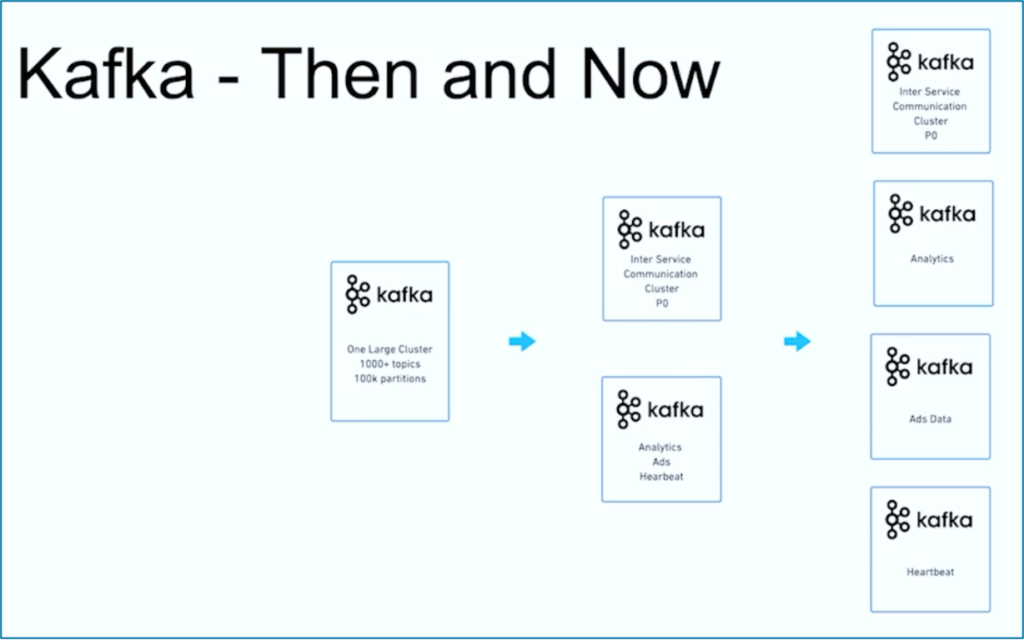 Fonte: JioCinema
Fonte: JioCinema
A história de sucesso da JioCinema mostra a evolução comum de uma organização de streaming de dados. Vamos agora explorar outro exemplo em que dois clusters Kafka muito diferentes foram implantados desde o início para um caso de uso.
Audi: Operações vs. Análise para Carros Conectados
O fabricante de automóveis Audi fornece carros conectados com tecnologia avançada que integra conectividade à internet e sistemas inteligentes. Os carros da Audi permitem navegação em tempo real, diagnóstico remoto e entretenimento aprimorado no carro. Esses veículos são equipados com serviços Audi Connect. Os recursos incluem chamadas de emergência, informações de tráfego online e integração com dispositivos domésticos inteligentes, para aprimorar a conveniência e a segurança dos motoristas.
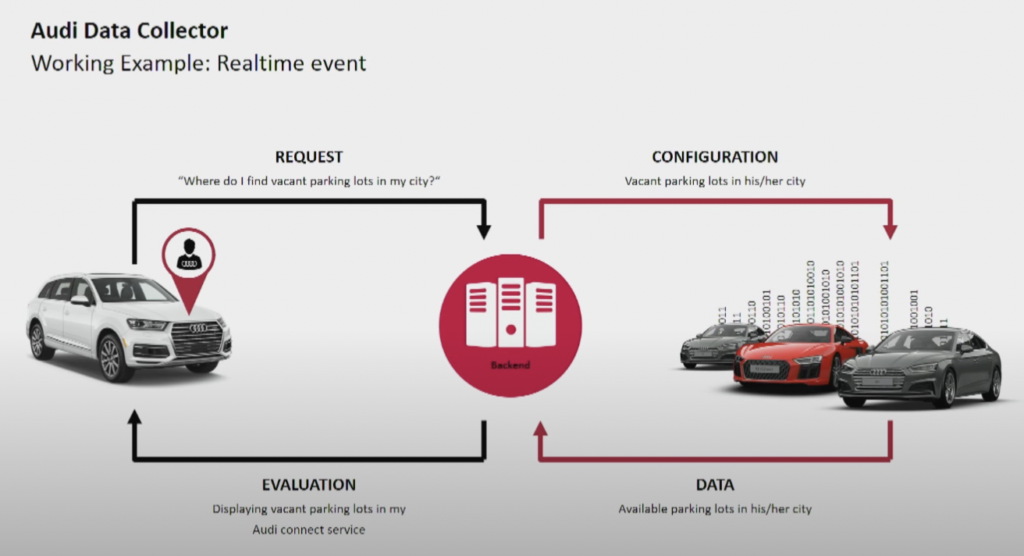 Fonte: Audi
Fonte: Audi
A Audi apresentou sua arquitetura de carro conectado na palestra principal da Kafka Summit de 2018. A arquitetura empresarial da Audi depende de dois clusters Kafka com SLAs e casos de uso muito diferentes.
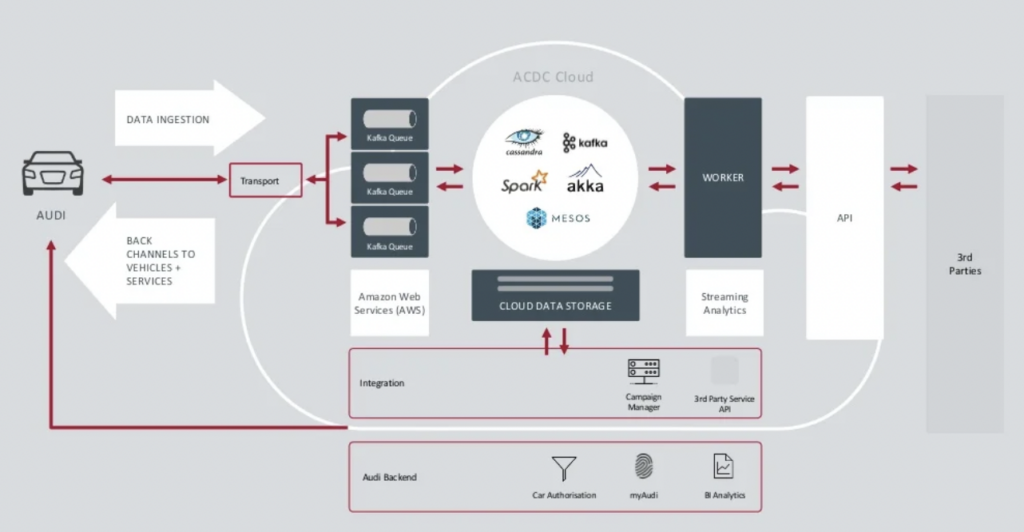 Fonte: Audi
Fonte: Audi
O cluster de ingestão de dados Kafka é muito crítico. Ele precisa funcionar 24 horas por dia, 7 dias por semana, em grande escala. Ele oferece conectividade de última milha para milhões de carros usando Kafka e MQTT. Canais reversos do lado de TI para o veículo ajudam na comunicação de serviços e atualizações via over-the-air (OTA).
O ACDC Cloud é o cluster de análise Kafka da arquitetura de carro conectado da Audi. O cluster é a base de muitas cargas de trabalho analíticas, que processam enormes volumes de dados de IoT e logs em escala com frameworks de processamento em lote como o Apache Spark.
Essa arquitetura já foi apresentada em 2018. O slogan da Audi, “Progresso através da Tecnologia”, mostra como a empresa aplicou novas tecnologias para inovação muito antes da maioria dos fabricantes de automóveis implementarem cenários semelhantes. Todos os dados dos sensores dos carros conectados são processados em tempo real e armazenados para análise e relatórios históricos.
New Relic: Observabilidade Multi-Cloud Mundial
New Relic é uma plataforma de observabilidade baseada em nuvem que fornece monitoramento de desempenho em tempo real e análises para aplicações e infraestrutura para clientes em todo o mundo.
Andrew Hartnett, VP de Engenharia de Software da New Relic, explica como o streaming de dados é crucial para todo o modelo de negócios da New Relic:
“Kafka é nosso sistema nervoso central. Ele faz parte de tudo o que fazemos. A maioria dos serviços em 110 equipes de engenharia diferentes, com centenas de serviços, interage com o Kafka de alguma forma em nossa empresa, então ele é realmente crítico para a missão. O que estávamos procurando é a capacidade de crescer, e o Confluent Cloud proporcionou isso.”
New Relic ingeriu até 7 bilhões de pontos de dados por minuto e está a caminho de ingerir 2,5 exabytes de dados em 2023. À medida que a New Relic expande suas estratégias de multi-nuvem, as equipes usarão o Confluent Cloud para uma visão unificada de todos os ambientes.
“New Relic é multi-nuvem. Queremos estar onde nossos clientes estão. Queremos estar nesses mesmos ambientes, nessas mesmas regiões, e queríamos ter nosso Kafka lá conosco.” diz Artnett em um estudo de caso da Confluent.
Múltiplos Clusters Kafka são a norma, não uma exceção
Arquiteturas orientadas a eventos e processamento de streams existem há décadas. A adoção cresce com frameworks de código aberto como Apache Kafka e Flink, em combinação com serviços de nuvem totalmente gerenciados. Cada vez mais organizações lutam com a escala do seu Kafka. Governança de dados em toda a empresa, centro de excelência, automação de implantação e operações, e melhores práticas de arquitetura corporativa ajudam a fornecer com sucesso streaming de dados com múltiplos clusters Kafka para domínios de negócios independentes ou colaborativos.
Múltiplos clusters Kafka são a norma, não uma exceção. Casos de uso como integração híbrida, recuperação de desastres, migração ou agregação possibilitam o streaming de dados em tempo real em todos os lugares com os SLAs necessários.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies