













Em Parte 1 desta série, analisamos o MongoDB, um dos bancos de dados NoSQL orientados a documentos mais confiáveis e robustos. Aqui na Parte 2, vamos examinar outro banco de dados NoSQL quite inevitável: Elasticsearch.
Mais do que apenas um popular e poderoso banco de dados distribuído open-source NoSQL, o Elasticsearch é antes de tudo um motor de busca e análise. É construído sobre o Apache Lucene, a biblioteca de busca Java mais famosa, e é capaz de realizar operações de busca e análise em tempo real em dados estruturados e não estruturados. É projetado para lidar eficientemente com grandes volumes de dados.
No entanto, precisamos declarar novamente que este breve post não é de forma alguma um tutorial de Elasticsearch. Consequentemente, o leitor é fortemente aconselhado a usar amplamente a documentação oficial, bem como o excelente livro “Elasticsearch in Action” de Madhusudhan Konda (Manning, 2023) para aprender mais sobre a arquitetura e operações do produto. Aqui, estamos apenas reimplantando o mesmo caso de uso como anteriormente, mas dessa vez, usando Elasticsearch em vez de MongoDB.
Então, vamos lá!
O Modelo de Domínio
O diagrama abaixo mostra nosso modelo de domínio *customer-order-product*:
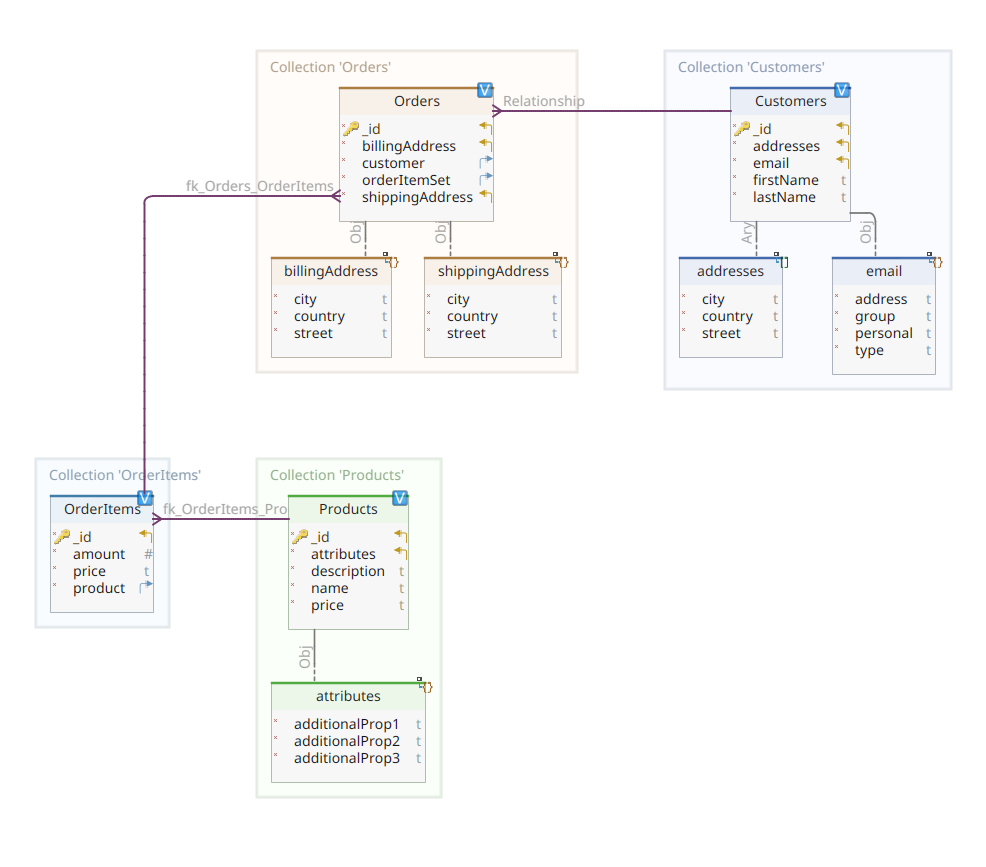
Este diagrama é o mesmo apresentado na Parte 1. Assim como MongoDB, Elasticsearch também é um armazenamento de dados em documentos e, como tal, espera que os documentos sejam apresentados em JSON. A única diferença é que para manipular seus dados, o Elasticsearch precisa indexá-los.
Existem várias maneiras de dados serem indexados em um armazenamento de dados Elasticsearch; por exemplo, redirecionando-os de um banco de dados relacional, extraíndo-os de um sistema de arquivos, transmitindo-os de uma fonte em tempo real, etc. Mas qualquer que seja o método de ingestão, ele finalmente consiste em invocar a API RESTful do Elasticsearch por meio de um cliente dedicado. Existem duas categorias de tais clientes dedicados:
- clientes baseados em REST como
curl,Postman, módulos HTTP para Java, JavaScript, Node.js, etc. - SDKs de linguagens de programação (Software Development Kit): Elasticsearch fornece SDKs para todas as linguagens de programação mais utilizadas, incluindo, mas não se limitando a Java, Python, etc.
Indexar um novo documento com Elasticsearch significa criá-lo usando uma solicitação POST contra um endpoint RESTful especial chamado _doc. Por exemplo, a seguinte solicitação criará um novo índice Elasticsearch e armazenará uma nova instância de cliente nele.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}Executar a solicitação acima usando curl ou o console Kibana (como veremos mais tarde) produzirá o seguinte resultado:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Esta é a resposta padrão do Elasticsearch para uma solicitação POST. Confirma que criou o índice chamado customers, com um novo documento customer, identificado por um ID gerado automaticamente (neste caso, ZEQsJI4BbwDzNcFB0ubC).
Outros parâmetros interessantes aparecem aqui, como _version e especialmente _shards. Sem entrar em muitos detalhes, o Elasticsearch cria índices como coleções lógicas de documentos. Assim como manter documentos em papel em um arquivo, o Elasticsearch mantém documentos em um índice. Cada índice é composto por shards, que são instâncias físicas do Apache Lucene, o motor por trás responsável por colocar os dados na storage ou tirá-los dela. Podem ser primárias, armazenando documentos, ou réplicas, armazenando, como o nome sugere, cópias dos shards primários. Mais sobre isso na documentação do Elasticsearch – por enquanto, precisamos notar que nosso índice chamado customers é composto por dois shards: um deles, é claro, é primário.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
Para voltar ao nosso diagrama de modelo de domínio, como você pode ver, o documento central é Order, armazenado em uma coleção dedicada chamada Orders. Uma Order é um agregado de documentos OrderItem, cada um dos quais aponta para seu Product associado. Um documento Order também referencia o Customer que a placed. Em Java, isso é implementado da seguinte forma:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
O código acima mostra um fragmento da classe Customer. Esta é uma simples POJO (Plain Old Java Object) que possui propriedades como o ID do cliente, nome e sobrenome, endereço de e-mail e um conjunto de endereços postais.
Vamos agora olhar para o documento Order.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
Aqui você pode notar algumas diferenças em comparação com a versão MongoDB. Na verdade, com MongoDB, estávamos usando uma referência à instância do cliente associada a este pedido. Esta noção de referência não existe com Elasticsearch e, portanto, estamos usando este ID de documento para criar uma associação entre o pedido e o cliente que o fez. O mesmo se aplica à propriedade orderItemSet, que cria uma associação entre o pedido e seus itens.
O restante do nosso modelo de domínio é bastante semelhante e baseado nas mesmas ideias de normalização. Por exemplo, o documento OrderItem:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
Aqui, precisamos associar o produto que compõe o objeto do item de pedido atual. Por último, mas não menos importante, temos o documento Product:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}O Repositórios de Dados
Quarkus Panache极大地简化了数据持久化过程,同时支持活动记录和仓库设计模式。在第一部分中,我们使用了Quarkus Panache扩展来为MongoDB实现我们的数据仓库,但目前还没有针对Elasticsearch的等效Quarkus Panache扩展。因此,在等待可能未来的Quarkus Elasticsearch扩展的同时,我们必须手动使用Elasticsearch专用客户端来实现我们的数据仓库。
Elasticsearch是用Java编写的,因此它提供了使用Java客户端库调用Elasticsearch API的本地支持并不奇怪。这个库基于流式API构建器设计模式,并提供了同步和异步处理模型。它至少需要Java 8。
那么,基于流式API构建器的数据仓库看起来是什么样子呢?下面是CustomerServiceImpl类的一个片段,该类作为Customer文档的数据仓库。
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
正如我们所看到的,我们的数据仓库实现必须是一个具有应用程序作用域的CDI bean。Elasticsearch Java客户端简单地通过Quarkus扩展quarkus-elasticsearch-java-client注入。这种方式避免了我们否则必须使用的大量复杂特性。我们需要能够注入客户端的唯一事情是声明以下属性:
quarkus.elasticsearch.hosts = elasticsearch:9200Aqui, elasticsearch é o nome DNS (Servidor de Nomes de Domínio) que associamos ao servidor de banco de dados Elasticsearch no arquivo docker-compose.yaml. 9200 é o número da porta TCP utilizada pelo servidor para ouvir conexões.
O método doIndex() acima cria um novo índice chamado customers se ele não existir e indexa (armazena) nele um novo documento representando uma instância da classe Customer. O processo de indexação é realizado com base em um IndexRequest aceitando como argumentos de entrada o nome do índice e o corpo do documento. Quanto ao ID do documento, ele é gerado automaticamente e retornado ao chamador para referência futura.
O método a seguir permite recuperar o cliente identificado pelo ID fornecido como argumento de entrada:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
O princípio é o mesmo: usando este padrão de construtor de API fluente, construímos uma instância de GetRequest de maneira semelhante à que fizemos com o IndexRequest, e a executamos contra o cliente Java do Elasticsearch. Os outros endpoints do nosso repositório de dados, permitindo a execução de operações de busca completa ou a atualização e exclusão de clientes, são projetados da mesma maneira.
Por favor, reserve um tempo para olhar o código e entender como as coisas funcionam.
A API REST
Nosso interface de API REST para MongoDB foi simples de implementar, graças à extensão quarkus-mongodb-rest-data-panache, na qual o processador de anotações gerou automaticamente todos os endpoints necessários. Com Elasticsearch, ainda não desfrutamos do mesmo conforto e, portanto, precisamos implementá-lo manualmente. Isso não é um grande problema, pois podemos injetar os repositórios de dados anteriores, como mostrado abaixo:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}Esta é a implementação da API REST do cliente. As outras associadas a pedidos, itens de pedidos e produtos são semelhantes.
Vamos ver agora como executar e testar todo o sistema.
Executando e Testando Nossos Microservices
Agora que olhamos os detalhes da nossa implementação, vamos ver como executá-la e testá-la. Escolhemos fazê-lo por meio do utilitário docker-compose. Aqui está o arquivo associado docker-compose.yml:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
Este arquivo instrui o utilitário docker-compose a executar três serviços:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
Agora, você pode verificar se todos os processos necessários estão em execução:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Para confirmar que o servidor Elasticsearch está disponível e capaz de executar consultas, você pode se conectar ao Kibana em http://localhost:601. Após scrolls na página e ao selecionar Dev Tools no menu de preferências, você pode executar consultas como mostrado abaixo:
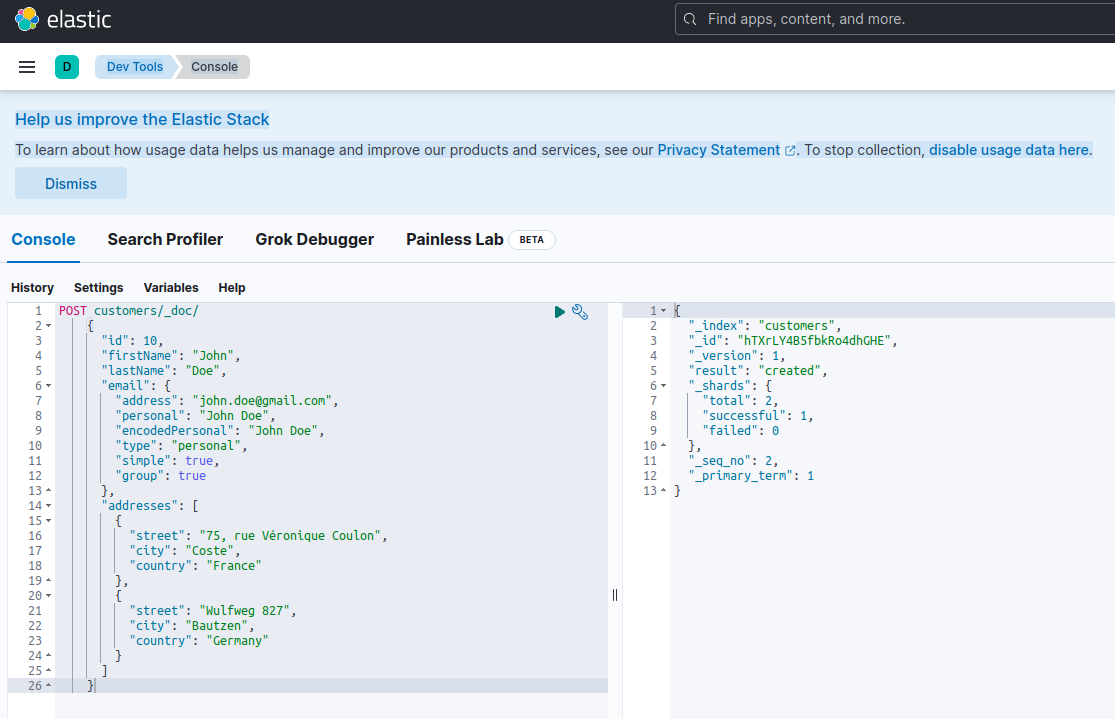
Para testar os microservices, proceda da seguinte forma:
1. Clone o repositório GitHub associado:
$ git clone https://github.com/nicolasduminil/docstore.git2. Vá para o projeto:
$ cd docstore3. Faça checkout do branch correto:
$ git checkout elastic-search4. Construa:
$ mvn clean install5. Execute os testes de integração:
$ mvn -DskipTests=false failsafe:integration-testEste último comando executará os 17 testes de integração fornecidos, que devem todos ter sucesso. Você também pode usar a interface do Swagger UI para fins de teste, abrindo seu navegador preferido em http://localhost:8080/q:swagger-ui. Então, para testar endpoints, você pode usar o payload nos arquivos JSON localizados no diretório src/resources/data do projeto docstore-api.
Aproveite!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse