













A chegada do Apache Hadoop Distributed File System (HDFS) revolucionou o armazenamento, processamento e análise de dados para empresas, acelerando o crescimento do big data e trazendo mudanças transformadoras para a indústria.
Inicialmente, o Hadoop integrou armazenamento e computação, mas a emergência da computação em nuvem levou à separação desses componentes. O armazenamento de objetos surgiu como uma alternativa ao HDFS, mas tinha limitações. Para complementar essas limitações, JuiceFS, um sistema de arquivos distribuído de alto desempenho e de código aberto, oferece soluções rentáveis para cenários intensivos em dados como computação, análise e treinamento. A decisão de adotar a separação de armazenamento e computação depende de fatores como escalabilidade, desempenho, custo e compatibilidade.
Neste artigo, revisaremos a arquitetura do Hadoop, discutiremos a importância e a viabilidade da desacoplagem de armazenamento e computação, e exploraremos as soluções disponíveis no mercado, destacando seus respectivos prós e contras. Nosso objetivo é fornecer insights e inspiração para empresas que estão passando por uma transformação de arquitetura de separação de armazenamento e computação.
Características de Design da Arquitetura do Hadoop
Hadoop como um Framework Integrado
Em 2006, o Hadoop foi lançado como um framework integrado composto por três componentes:
- MapReduce para computação
- YARN para agendamento de recursos
- HDFS para armazenamento de arquivos distribuídos
 Core components of Hadoop
Core components of HadoopComponentes de Computação Diferenciados
Entre esses três componentes, a camada de computação tem visto um desenvolvimento rápido. Inicialmente, havia apenas o MapReduce, mas a indústria logo testemunhou a emergência de vários frameworks como Tez e Spark para computação, Hive para data warehousing e motores de consulta como Presto e Impala. Em conjunto com esses componentes, existem inúmeras ferramentas de transferência de dados como o Sqoop.

HDFS Dominou o Sistema de Armazenamento
Ao longo de cerca de dez anos, o HDFS, o sistema de arquivos distribuídos, permaneceu como o sistema de armazenamento dominante. Era a escolha padrão para quase todos os componentes de computação. Todos os componentes mencionados acima no ecossistema de big data foram projetados para a API do HDFS. Alguns componentes aproveitam profundamente as capacidades específicas do HDFS. Por exemplo:
- HBase utiliza as capacidades de gravação de baixa latência do HDFS para seus logs de escrita antecipada.
- MapReduce e Spark ofereceram recursos de localidade de dados.
As escolhas de design desses componentes de big data, baseadas na API do HDFS, trouxeram desafios potenciais para implantar plataformas de dados na nuvem.
Arquitetura Acoplada de Armazenamento-Computação
O diagrama a seguir mostra parte de uma arquitetura simplificada do HDFS, que combina computação com armazenamento.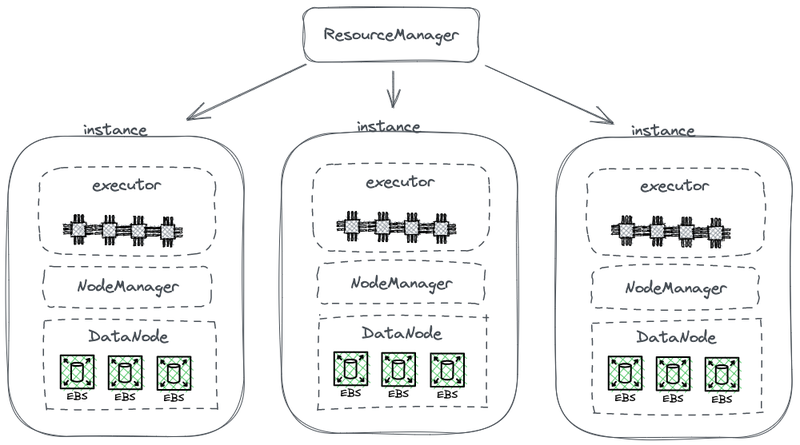
Arquitetura do Hadoop acoplada de armazenamento e computação
Neste diagrama, cada nó atua como um HDFS DataNode para armazenar dados. Além disso, o YARN implementa um processo Node Manager em cada nó. Isso permite que o YARN reconheça o nó como parte de seus recursos gerenciados para tarefas de computação. Essa arquitetura permite que o armazenamento e a computação coexistam no mesmo computador, e os dados podem ser lidos do disco durante a computação.
Por que o Hadoop acopla Armazenamento e Computação
O Hadoop acoplou armazenamento e computação devido às limitações de comunicação de rede e hardware durante sua fase de design.
Em 2006, a computação em nuvem ainda estava em sua fase inicial, e a Amazon havia acabado de lançar seu primeiro serviço. Nos data centers, as placas de rede predominantes estavam operando principalmente a 100 Mbps. Os discos de dados usados para cargas de trabalho de big data atingiam uma taxa de transferência de aproximadamente 50 MB/s, equivalente a 400 Mbps em termos de largura de banda de rede.
Considerando um nó com oito discos operando na capacidade máxima, foram necessárias várias gigabits por segundo de largura de banda de rede para uma transmissão de dados eficiente. Infelizmente, a capacidade máxima dos cartões de rede era limitada a 1 Gbps. Como resultado, a largura de banda de rede por nó era insuficiente para aproveitar totalmente as capacidades de todos os discos dentro do nó. Consequentemente, se as tarefas de computação estivessem em uma extremidade da rede e os dados residissem em nós de dados na outra extremidade, a largura de banda da rede representava um gargalo significativo.
Por que a Desacoplagem de Armazenamento e Computação é Necessária
De 2006 até por volta de 2016, as empresas enfrentaram os seguintes problemas:
- A demanda por poder de computação e armazenamento em aplicações era desequilibrada, e suas taxas de crescimento eram diferentes. Enquanto os dados das empresas cresciam rapidamente, a necessidade de poder de computação não crescia tão rapidamente. Essas tarefas, desenvolvidas por humanos, não se multiplicavam exponencialmente em um curto período. No entanto, os dados gerados a partir dessas tarefas acumulavam-se rapidamente, possivelmente de forma exponencial. Além disso, alguns dados podem não ser imediatamente úteis para a empresa, mas seriam valiosos no futuro. Portanto, as empresas armazenavam os dados de forma abrangente para explorar seu potencial valor.
- Durante a escalabilidade, as empresas tiveram que expandir tanto a computação quanto o armazenamento simultaneamente, o que frequentemente levou a recursos de computação desperdiçados. A topologia de hardware da arquitetura de armazenamento-computação acoplada afetou a expansão de capacidade. Quando a capacidade de armazenamento ficava insuficiente, não apenas precisávamos adicionar máquinas, mas também atualizar CPUs e memória, pois os nós de dados na arquitetura acoplada eram responsáveis pelo cálculo. Portanto, as máquinas eram tipicamente equipadas com uma configuração equilibrada de poder de computação e armazenamento, fornecendo uma capacidade de armazenamento suficiente junto com um poder de computação comparável. No entanto, a demanda real pelo poder de computação não aumentou como se esperava. Como resultado, o poder de computação expandido causou um grande desperdício para as empresas.
- O equilíbrio entre computação e armazenamento e a seleção de máquinas adequadas tornou-se desafiador. A utilização de recursos do cluster inteiro em termos de armazenamento e I/O poderia ser altamente desequilibrada, e esse desequilíbrio piorava à medida que o cluster crescia. Além disso, adquirir máquinas adequadas era difícil, pois as máquinas tinham que equilibrar os requisitos de computação e armazenamento.
- Como os dados podiam ser distribuídos de forma desigual, era difícil programar efetivamente tarefas de computação nos casos onde os dados residiam. A estratégia de agendamento de localidade de dados pode não abordar efetivamente cenários do mundo real devido à possibilidade de distribuição de dados desequilibrada. Por exemplo, certos nós poderiam se tornar pontos quentes locais, exigindo mais poder de computação. Consequentemente, mesmo que as tarefas no plataforma de big data fossem agendadas para esses nós de ponto quente, o desempenho de E/S poderia ainda se tornar um fator limitante.
Por que desacoplar o armazenamento e o cálculo é viável
A viabilidade de separar o armazenamento e o cálculo tornou-se possível graças a avanços em hardware e software entre 2006 e 2016. Esses avanços incluem:
Cartões de Rede
A adoção de cartões de rede de 10 Gb tornou-se generalizada, com crescente disponibilidade de capacidades mais altas, como 20 Gb, 40 Gb e até 50 Gb em centros de dados e ambientes de nuvem. Em cenários de IA, também são utilizados cartões de rede com capacidade de 100 GB. Isso representa um aumento significativo na largura de banda da rede, em mais de 100 vezes.
Discos
Muitas empresas ainda dependem de soluções baseadas em disco para armazenamento em grandes clusters de dados. A taxa de transferência dos discos dobrou, aumentando de 50 MB/s para 100 MB/s. Uma instância equipada com um cartão de rede de 10 GB pode suportar uma taxa de transferência máxima de cerca de 12 discos. Isso é suficiente para a maioria das empresas, e assim, a transmissão de rede não é mais um gargalo.
Software
O uso de algoritmos de compressão eficientes, como Snappy, LZ4 e Zstandard, e formatos de armazenamento de colunas como Avro, Parquet e Orc, aliviou ainda mais a pressão de E/S. O gargalo no processamento de big data mudou de E/S para o desempenho da CPU.
Como Implementar a Separação de Armazenamento e Cálculo
Tentativa Inicial: Implantação Independente do HDFS na Nuvem
Implantação Independente do HDFS
Desde 2013, houve tentativas no setor de separar armazenamento e computação. A abordagem inicial é bastante direta, envolvendo o deploy independente do HDFS sem integrá-lo com os trabalhadores de computação. Essa solução não introduziu nenhum componente novo no ecossistema do Hadoop.
Como mostra o diagrama abaixo, o NodeManager não era mais implantado nos DataNodes. Isso indicava que as tarefas de computação não eram mais enviadas aos DataNodes. O armazenamento tornou-se um cluster separado, e os dados necessários para os cálculos eram transmitidos pela rede, suportados por placas de rede de ponta a ponta de 10 Gb. (Note que as linhas de transmissão de rede não estão marcadas no diagrama.)

Embora essa solução tenha abandonado a localidade de dados, o design mais engenhoso do HDFS, a velocidade aprimorada da comunicação de rede facilitou significativamente a configuração do cluster. Isso foi demonstrado através de experimentos conduzidos por Davies, co-fundador da Juicedata, e seus companheiros durante o tempo deles no Facebook em 2013. Os resultados confirmaram a viabilidade do deploy e gerenciamento independentes de nós de computação.
No entanto, essa tentativa não progrediu mais. A principal razão é os desafios de implantar o HDFS na nuvem.
Desafios de Implantar HDFS na Nuvem
Implantar o HDFS na nuvem enfrenta os seguintes problemas:
- O mecanismo de múltiplos réplicas do HDFS pode aumentar o custo das empresas na nuvem:No passado, as empresas utilizavam discos rígidos para construir um sistema HDFS em seus centros de dados. Para mitigar o risco de danos aos discos, o HDFS implementou um mecanismo de múltiplos réplicas para garantir a segurança e a disponibilidade dos dados. No entanto, ao migrar dados para a nuvem, os provedores de nuvem oferecem discos na nuvem que já são protegidos pelo mecanismo de múltiplos réplicas. Consequentemente, as empresas precisam replicar os dados três vezes dentro da nuvem, resultando em um aumento significativo nos custos.
- Opções limitadas para implantação em discos rígidos:Embora os provedores de nuvem ofereçam alguns tipos de máquinas com discos rígidos, as opções disponíveis são limitadas. Por exemplo, de 100 tipos de máquinas virtuais disponíveis na nuvem, apenas 5-10 tipos de máquinas suportam discos rígidos. Essa seleção limitada pode não atender aos requisitos específicos dos clusters empresariais.
- Inabilidade de aproveitar as vantagens únicas da nuvem:Implantar o HDFS na nuvem requer a criação manual de máquinas, implantação, manutenção, monitoramento e operações sem a conveniência da escalabilidade elástica e do modelo pay-as-you-go. Estas são as principais vantagens do computação em nuvem. Portanto, implantar o HDFS na nuvem enquanto se busca a separação de armazenamento e computação não é fácil.
Limitações do HDFS
O HDFS tem essas limitações:
- NameNodes têm escalabilidade limitada:Os NameNodes no HDFS só podem escalar verticalmente e não podem escalar de forma distribuída. Essa limitação impõe uma restrição no número de arquivos que podem ser gerenciados dentro de um único cluster HDFS.
- Armazenar mais de 500 milhões de arquivos acarreta custos operacionais elevados: De acordo com nossa experiência, geralmente é fácil operar e manter o HDFS com menos de 300 milhões de arquivos. Quando o número de arquivos ultrapassa 500 milhões, é necessário implementar o mecanismo de Federação do HDFS. No entanto, isso introduz custos operacionais e de gerenciamento elevados.
- Alto uso de recursos e carga pesada no NameNode impactam a disponibilidade do cluster HDFS: Quando um NameNode ocupa muitos recursos com uma carga alta, pode ser acionada uma coleta de lixo completa (GC). Isso afeta a disponibilidade de todo o cluster HDFS. O sistema de armazenamento pode experimentar tempo de inatividade, ficando incapaz de ler dados, e não há como intervir no processo de GC. A duração do congelamento do sistema não pode ser determinada. Este tem sido um problema persistente em clusters HDFS de alta carga.
Nuvem Pública + Armazenamento de Objetos
Com o avanço da computação em nuvem, as empresas agora têm a opção de usar o armazenamento de objetos como uma alternativa ao HDFS. O armazenamento de objetos é projetado especificamente para armazenar dados não estruturados em larga escala, oferecendo uma arquitetura para fácil upload e download de dados. Ele fornece uma capacidade de armazenamento altamente escalável, garantindo a eficiência de custos.
Benefícios do Armazenamento de Objetos como Substituto do HDFS
O armazenamento de objetos ganhou destaque, começando com o AWS e posteriormente sendo adotado por outros provedores de nuvem como substituto do HDFS. Os seguintes benefícios são notáveis:
- Orientado a serviços e pronto para uso: O armazenamento de objetos não requer implantação, monitoramento ou tarefas de manutenção, proporcionando uma experiência conveniente e amigável para o usuário.
- Escala elástica e pagamento conforme o uso: As empresas pagam pelo armazenamento de objetos com base em seu uso real, eliminando a necessidade de planejamento de capacidade. Eles podem criar um bucket de armazenamento de objetos e armazenar quantos dados forem necessários, sem se preocupar com limitações de capacidade de armazenamento.
Desvantagens do Armazenamento de Objetos
No entanto, ao usar o armazenamento de objetos para suportar sistemas de dados complexos como o Hadoop, surgem os seguintes desafios:
Desvantagem #1: Pobre Desempenho na Listagem de Arquivos
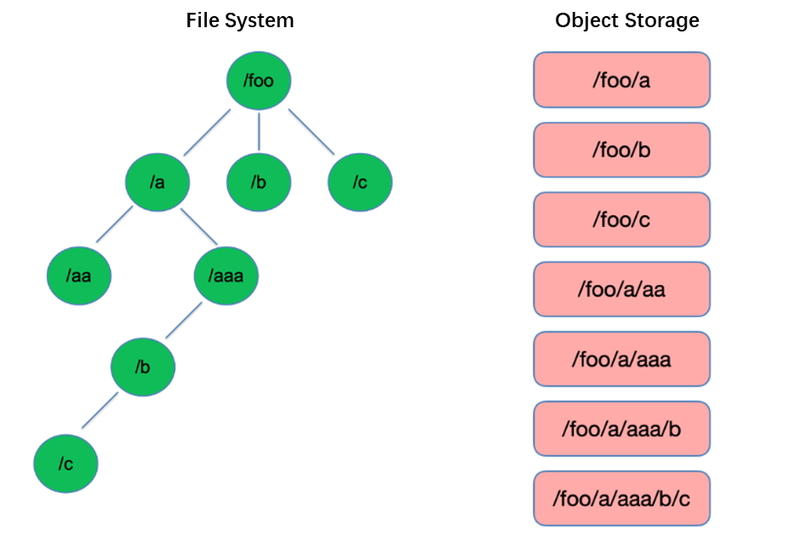
Listar é uma das operações mais básicas no sistema de arquivos. É leve e rápida em estruturas em árvore como o HDFS.
Em contraste, o armazenamento de objetos adota uma estrutura plana e requer indexação com chaves (identificadores únicos) para armazenar e recuperar milhares ou mesmo bilhões de objetos. Como resultado, ao executar uma operação de List, o armazenamento de objetos só pode pesquisar nesse índice, resultando em desempenho significativamente inferior em comparação com estruturas em árvore.
Desvantagem #2: Falta de Capacidade de Renomear Atômica, Afetando Desempenho e Estabilidade de Tarefas
Em modelos de computação de extração, transformação e carregamento (ETL), cada subtarefa escreve seus resultados em um diretório temporário. Quando toda a tarefa é concluída, o diretório temporário pode ser renomeado para o nome do diretório final.
Essas operações de renomeação são atômicas e rápidas em sistemas de arquivos como o HDFS, e garantem transações. No entanto, como o armazenamento de objetos não possui uma estrutura de diretório nativa, lidar com uma operação de renomeação é um processo simulado que envolve uma quantidade substancial de cópia de dados internos. Esse processo pode ser demorado e não fornece garantias de transação.
Quando os usuários utilizam o armazenamento de objetos, geralmente usam o formato de caminho de sistemas de arquivos tradicionais como chave para objetos, como “/order/2-22/8/10/detail”. Durante uma operação de renomeação, torna-se necessário pesquisar todos os objetos cujas chaves contêm o nome do diretório e copiar todos os objetos usando o novo nome do diretório como chave. Esse processo envolve cópia de dados, resultando em desempenho significativamente inferior em comparação com sistemas de arquivos, potencialmente até um ou dois ordens de magnitude mais lento.
Além disso, devido à ausência de garantias de transação, há risco de falha durante o processo, resultando em dados incorretos. Essas diferenças aparentemente menores têm implicações para o desempenho e a estabilidade de toda a pipeline de tarefas.
Desvantagem #3: O Mecanismo de Consistência Eventual Afeta a Correção dos Dados e a Estabilidade das Tarefas
Por exemplo, quando múltiplos clientes criam arquivos simultaneamente sob um caminho, a lista de arquivos obtida através da API de List pode não incluir imediatamente todos os arquivos criados. É necessário tempo para que os sistemas internos do armazenamento de objetos alcancem a consistência dos dados. Esse padrão de acesso é comumente usado na processamento de dados ETL, e a consistência eventual pode afetar a correção dos dados e a estabilidade das tarefas.
Para resolver o problema da incapacidade do armazenamento de objetos em manter uma forte consistência de dados, a AWS lançou um produto chamado EMRFS. Sua abordagem é empregar um banco de dados DynamoDB adicional. Por exemplo, quando o Spark escreve um arquivo, também escreve simultaneamente uma cópia da lista de arquivos no DynamoDB. Uma mecanismo é estabelecido para chamar continuamente a API List do armazenamento de objetos e comparar os resultados obtidos com os resultados armazenados no banco de dados até que sejam os mesmos, momento em que os resultados são retornados. No entanto, a estabilidade deste mecanismo não é suficiente, pois pode ser influenciada pela carga na região onde o armazenamento de objetos está localizado, resultando em desempenho variável. Portanto, não é uma solução ideal.
Desvantagem #4: Compatibilidade Limitada com Componentes do Hadoop
O HDFS foi a escolha primária de armazenamento nos estágios iniciais do ecossistema Hadoop, e vários componentes foram desenvolvidos com base na API do HDFS. A introdução do armazenamento de objetos levou a mudanças na estrutura de armazenamento de dados e APIs.
Os provedores de nuvem precisam modificar os conectores entre os componentes e o armazenamento de objetos na nuvem, bem como aplicar patches em componentes de nível superior para garantir a compatibilidade. Esta tarefa coloca uma carga significativa nos provedores de nuvem pública.
Consequentemente, o número de componentes de computação suportados nos plataformas de big data oferecidas por provedores de nuvem pública é limitado, geralmente incluindo apenas algumas versões do Spark, Hive e Presto. Essa limitação apresenta desafios para migrar plataformas de big data para a nuvem ou para usuários com requisitos específicos para sua própria distribuição e componentes.
Para aproveitar o poderoso desempenho do armazenamento de objetos, enquanto preserva a confiabilidade dos sistemas de arquivos, as empresas podem usar o armazenamento de objetos + JuiceFS.
Armazenamento de Objetos + JuiceFS
Quando os usuários desejam realizar computação, análise e treinamento de dados complexos no armazenamento de objetos, apenas o armazenamento de objetos pode não atender adequadamente às necessidades das empresas. Esta é uma motivação chave por trás do desenvolvimento de JuiceFS pela Juicedata, que visa complementar as limitações do armazenamento de objetos.
JuiceFS é um sistema de arquivos distribuído de alto desempenho, de código aberto, projetado para a nuvem. Juntamente com o armazenamento de objetos, JuiceFS fornece soluções econômicas para cenários intensivos em dados, como computação, análise e treinamento.
Como Funciona o JuiceFS + Armazenamento de Objetos
O diagrama abaixo mostra a implantação do JuiceFS em um cluster Hadoop.
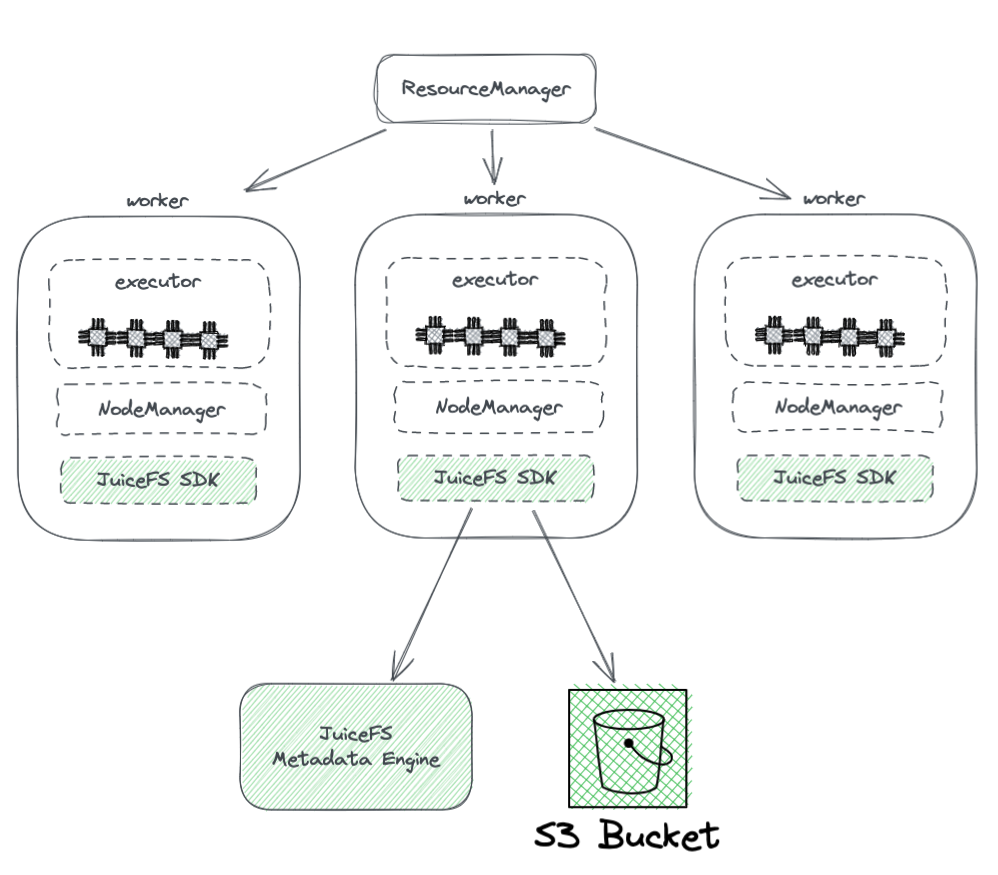
A partir do diagrama, podemos ver o seguinte:
- Todos os nós de trabalho gerenciados por YARN carregam um SDK do JuiceFS Hadoop, que pode garantir a compatibilidade total com o HDFS.
- O SDK acessa dois componentes:
-
JuiceFS Metadata Engine: O mecanismo de metadados serve como o equivalente ao NameNode do HDFS. Ele armazena as informações de metadados de todo o sistema de arquivos, incluindo contagens de diretórios, nomes de arquivos, permissões e timestamps, e resolve os desafios de escalabilidade e GC enfrentados pelo NameNode do HDFS.
-
Bucket S3: Os dados são armazenados dentro do bucket S3, que pode ser visto como análogo ao DataNode do HDFS. Pode ser usado como uma grande quantidade de discos, gerenciando tarefas de armazenamento e replicação de dados.
-
-
JuiceFS é composto por três componentes:
- JuiceFS Hadoop SDK
- Mecanismo de Metadados
- Bucket S3
Vantagens do Juicefs em relação ao uso direto de armazenamento de objetos
JuiceFS oferece várias vantagens em comparação com o uso direto de armazenamento de objetos:
- Compatibilidade total com o HDFS: Isso é alcançado pelo design inicial do JuiceFS para suportar totalmente o POSIX. A API POSIX tem uma cobertura e complexidade maiores do que o HDFS.
- Capacidade de uso com o HDFS e armazenamento de objetos existentes: Graças ao design do sistema Hadoop, o JuiceFS pode ser usado ao lado dos sistemas de HDFS e armazenamento de objetos existentes sem a necessidade de uma substituição completa. Em um cluster Hadoop, múltiplos sistemas de arquivos podem ser configurados, permitindo que o JuiceFS e o HDFS coexistam e colaborem. Essa arquitetura elimina a necessidade de uma substituição completa de clusters HDFS existentes, o que envolveria um esforço e riscos significativos. Os usuários podem integrar gradualmente o JuiceFS com base nas necessidades de seus aplicativos e situações do cluster.
- Desempenho de metadados poderoso: JuiceFS separa o mecanismo de metadados do S3 e não depende mais do desempenho de metadados do S3. Isso garante o melhor desempenho de metadados. Ao usar o JuiceFS, as interações com o armazenamento de objetos subjacente são simplificadas para operações básicas como Get, Put e Delete. Essa arquitetura supera as limitações de desempenho de metadados do armazenamento de objetos e elimina problemas relacionados à consistência eventual.
- Suporte para Renomeação Atômica: O JuiceFS suporta operações de Renomeação Atômica devido ao seu mecanismo de metadados independente. O cache melhora o desempenho de acesso à dados quentes e fornece o recurso de localidade de dados: Com cache, os dados quentes não precisam ser recuperados do armazenamento de objetos pela rede a cada vez. Além disso, o JuiceFS implementa a API de localidade de dados específica do HDFS, de modo que todos os componentes de nível superior que suportam localidade de dados possam recuperar a percepção da afinidade de dados. Isso permite que o YARN priorize o agendamento de tarefas em nós onde foi estabelecido o cache, resultando em desempenho geral comparável ao do HDFS com armazenamento e computação acoplados.
- O JuiceFS é compatível com o POSIX, facilitando a integração com aplicativos relacionados a aprendizado de máquina e IA.
Conclusão
Com a evolução dos requisitos das empresas e avanços nas tecnologias, a arquitetura de armazenamento e computação passou por mudanças, passando do acoplamento para a separação.
Existem diversas abordagens para alcançar a separação de armazenamento e computação, cada uma com suas próprias vantagens e desvantagens. Estes vão desde o deploy do HDFS na nuvem até a utilização de soluções em nuvem pública que são compatíveis com o Hadoop e até mesmo a adoção de soluções como armazenamento de objetos + JuiceFS, que são adequadas para computação e armazenamento de big data complexos na nuvem.
Para as empresas, não há uma solução perfeita, e o segredo está em selecionar a arquitetura com base em suas necessidades específicas. No entanto, independentemente da escolha, a simplicidade é sempre uma aposta segura.
Sobre o Autor
Rui Su, sócio da Juicedata, tem sido membro fundador envolvido na completa evolução do produto JuiceFS, mercado e comunidade open-source desde 2017. Com 16 anos de experiência na indústria, ocupou posições como desenvolvedor, gerente de produto e fundador em software, internet e organizações não governamentais.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora