













Vamos supor que você tenha um aplicativo desenvolvido em Node.js (ou qualquer outra plataforma). Esse aplicativo se conecta a um banco de dados MongoDB (NoSQL) para armazenar avaliações de livros (número de estrelas dadas e um comentário). Vamos também supor que você tenha outro aplicativo desenvolvido em Java (ou Python, C#, TypeScript… qualquer coisa). Esse aplicativo se conecta a um banco de dados MariaDB (SQL, relacional) para gerenciar um catálogo de livros (título, ano de publicação, número de páginas).
Você é solicitado a criar um relatório que mostre o título e informações de classificação para cada livro. Observe que o banco de dados MongoDB não contém o título dos livros, e o banco de dados relacional não contém as avaliações. Precisamos misturar dados criados por um aplicativo NoSQL com dados criados por um aplicativo SQL.
A common approach to this is to query both databases independently (using different data sources) and process the data to match by, for example, ISBN (the id of a book) and put the combined information in a new object. This needs to be done in a programming language like Java, TypeScript, C#, Python, or any other imperative programming language that is able to connect to both databases.
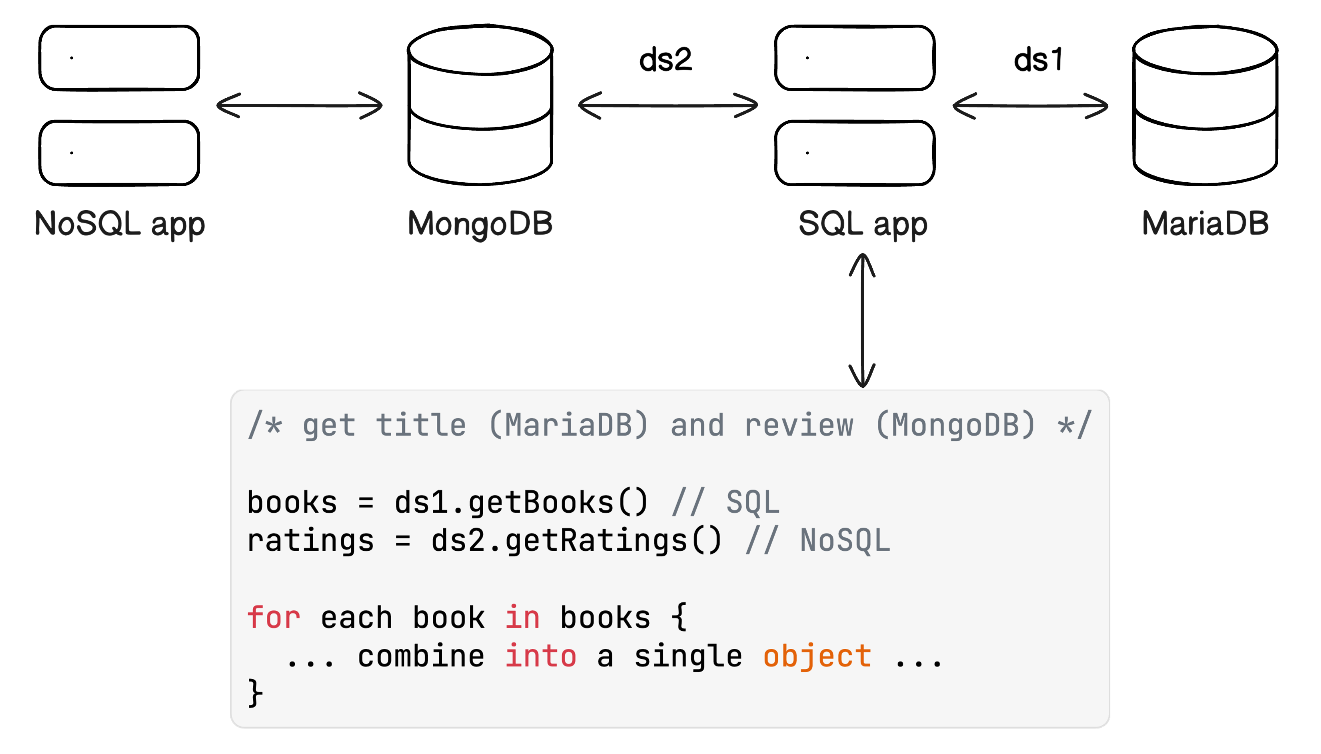
A polyglot application
Essa abordagem funciona. No entanto, juntar dados é uma tarefa para um banco de dados. Eles são construídos para esse tipo de operação de dados. Além disso, com essa abordagem, o aplicativo SQL não é mais um aplicativo apenas SQL; se torna um poliglota de banco de dados, e isso aumenta a complexidade, tornando-o mais difícil de manter.
Com um proxy de banco de dados como MaxScale, você pode juntar esses dados no nível do banco de dados usando a melhor linguagem para dados — SQL. Seu aplicativo SQL não precisa se tornar um poliglota.
Embora isso exija um elemento adicional na infraestrutura, você também ganha todas as funcionalidades que um proxy de banco de dados oferece. Coisas como failover automático, mascaramento de dados transparente, isolamento de topologia, cache, filtros de segurança e muito mais.
MaxScale é um poderoso proxy de banco de dados inteligente que entende tanto SQL quanto NoSQL. Também entende Kafka (para CDC ou ingestão de dados), mas isso é um tópico para outra ocasião. Em suma, com MaxScale, você pode conectar seu aplicativo NoSQL a um banco de dados relacional totalmente compatível com ACID e armazenar os dados ali mesmo ao lado de tabelas que outros aplicativos SQL utilizam.
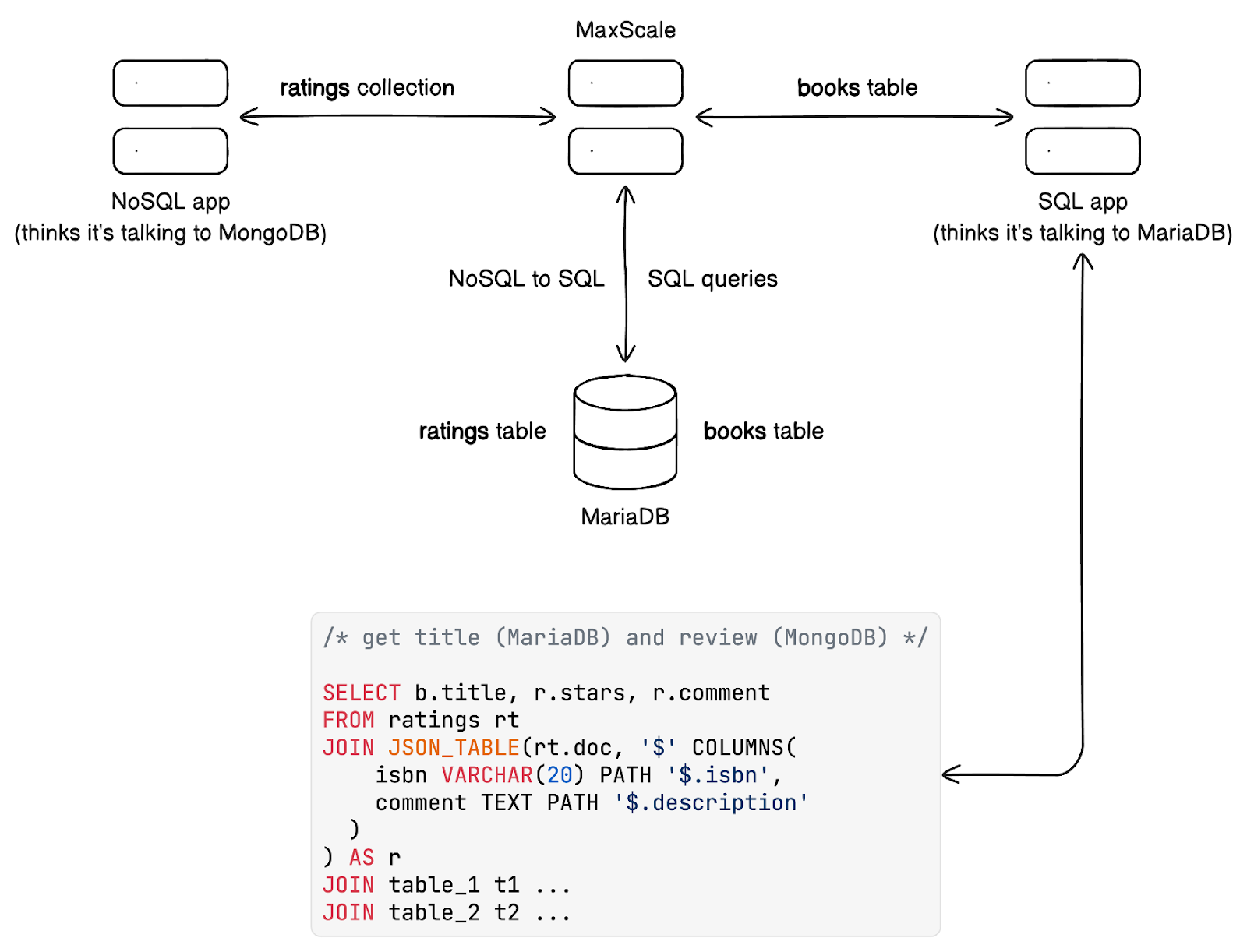
MaxScale permite que um aplicativo SQL consuma dados NoSQL.
Vamos tentar essa última abordagem em um experimento rápido e fácil de seguir com MaxScale. Você precisará ter o seguinte instalado em seu computador:
- Docker
- O
mariadb-shellferramenta - O
mongoshferramenta
Configuração do Banco de Dados MariaDB
Usando um editor de texto simples, crie um novo arquivo e salve-o com o nome docker-compose.yml. O arquivo deve conter o seguinte:
version: "3.9"
services:
mariadb:
image: alejandrodu/mariadb
environment:
- MARIADB_CREATE_DATABASE=demo
- MARIADB_CREATE_USER=user:Password123!
- MARIADB_CREATE_MAXSCALE_USER=maxscale_user:MaxScalePassword123!
maxscale:
image: alejandrodu/mariadb-maxscale
command: --admin_host 0.0.0.0 --admin_secure_gui false
ports:
- "3306:4000"
- "27017:27017"
- "8989:8989"
environment:
- MAXSCALE_USER=maxscale_user:MaxScalePassword123!
- MARIADB_HOST_1=mariadb 3306
- MAXSCALE_CREATE_NOSQL_LISTENER=user:Password123!Este é um arquivo Docker Compose. Ele descreve um conjunto de serviços a serem criados pelo Docker. Estamos criando dois serviços (ou containers) — um servidor de banco de dados MariaDB e um proxy de banco de dados MaxScale. Eles estarão funcionando localmente em sua máquina, mas em ambientes de produção, é comum implantá-los em máquinas físicas separadas. Tenha em mente que essas imagens Docker não são adequadas para produção! Elas são destinadas a serem adequadas para demonstrações rápidas e testes. Você pode encontrar o código-fonte dessas imagens no GitHub. Para as imagens oficiais do Docker da MariaDB, acesse a página MariaDB no Docker Hub.
O arquivo Docker Compose anterior configura um servidor de banco de dados MariaDB com um banco de dados (ou esquema; são sinônimos no MariaDB) chamado demo. Ele também cria um usuário user com a senha Password123!. Este usuário possui privilégios adequados no banco de dados demo. Há um usuário adicional com o nome maxscale_user e senha MaxScalePassword123!. Este é o usuário que o proxy de banco de dados MaxScale usará para se conectar ao banco de dados MariaDB.
O arquivo Docker Compose também configura o proxy de banco de dados desabilitando HTTPS (não faça isso em produção!), expondo um conjunto de portas (mais sobre isso em um momento) e configurando o usuário do banco de dados e o local do proxy MariaDB (geralmente um endereço IP, mas aqui podemos usar o nome do contêiner previamente definido no arquivo Docker). A última linha cria um ouvinte NoSQL que usaremos para conectar como um cliente MongoDB na porta padrão (27017).
Para iniciar os serviços (contêineres) usando a linha de comando, vá para o diretório em que você salvou o arquivo Docker Compose e execute o seguinte:
docker compose up -dApós baixar todo o software e iniciar os contêineres, você terá um banco de dados MariaDB e um proxy MaxScale, ambos pré-configurados para esta experiência.
Criando uma Tabela SQL no MariaDB
Vamos conectar ao banco de dados relacional. Na linha de comando, execute o seguinte:
mariadb-shell --dsn mariadb://user:'Password123!'@127.0.0.1Verifique se você consegue visualizar o banco de dados demo:
show databases;Mude para o banco de dados demo:
use demo;
Conectando a um banco de dados com o MariaDB Shell.
Crie a tabela books:
CREATE TABLE books(
isbn VARCHAR(20) PRIMARY KEY,
title VARCHAR(256),
year INT
);Insira alguns dados. Vou usar o clichê de inserir meus próprios livros:
INSERT INTO books(title, isbn, year)
VALUES
("Vaadin 7 UI Design By Example", "978-1-78216-226-1", 2013),
("Data-Centric Applications with Vaadin 8", "978-1-78328-884-7", 2018),
("Practical Vaadin", "978-1-4842-7178-0", 2021);Verifique se os livros estão armazenados no banco de dados executando:
SELECT * FROM books;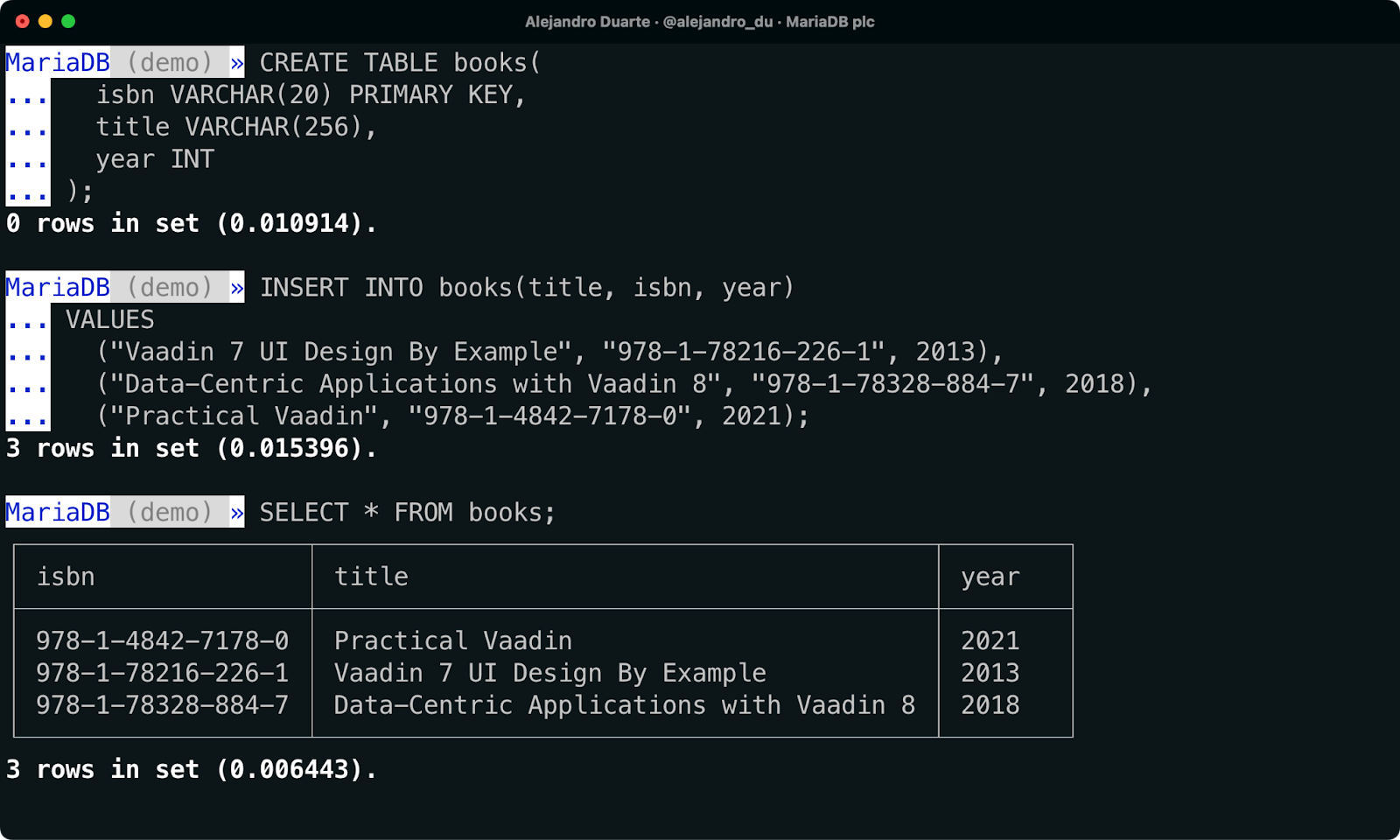
Inserindo dados com o MariaDB Shell.
Criando uma Coleção JSON no MariaDB
Não instalamos o MongoDB, mas podemos usar um cliente (ou aplicativo) do MongoDB para conectar e criar coleções e documentos como se estivéssemos usando o MongoDB, exceto que os dados são armazenados em um banco de dados relacional poderoso, totalmente compatível com ACID, e escalável. Vamos tentar isso!
No terminal, use a ferramenta do shell do MongoDB para conectar ao MongoDB… espere… é na verdade o banco de dados MariaDB! Execute o seguinte:
mongoshPor padrão, esta ferramenta tenta se conectar a um servidor MongoDB (que, mais uma vez, acaba sendo o MariaDB desta vez) em execução na sua máquina local (127.0.0.1) usando a porta padrão (20017). Se tudo correr bem, você deve ser capaz de ver o banco de dados demo listado quando executar o seguinte comando:
show databasesMude para o banco de dados demo:
use demo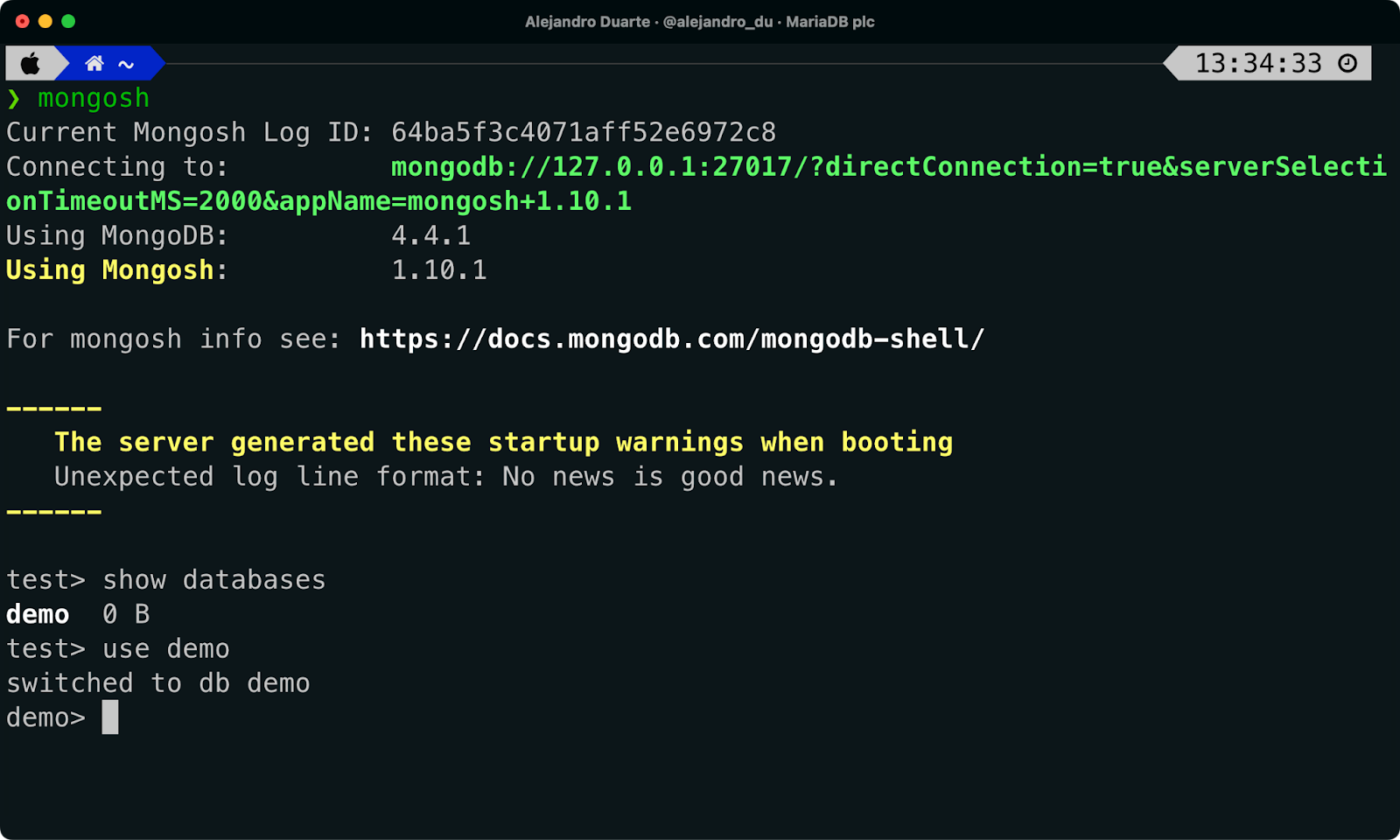
Conectando ao MariaDB usando o Mongo Shell.
Estamos conectados a um banco de dados relacional a partir de um cliente não relacional! Vamos criar a coleção ratings e inserir alguns dados nela:
db.ratings.insertMany([
{
"isbn": "978-1-78216-226-1",
"starts": 5,
"comment": "A good resource for beginners who want to learn Vaadin"
},
{
"isbn": "978-1-78328-884-7",
"starts": 4,
"comment": "Explains Vaadin in the context of other Java technologies"
},
{
"isbn": "978-1-4842-7178-0",
"starts": 5,
"comment": "The best resource to learn web development with Java and Vaadin"
}
])Verifique se as avaliações são persistentes no banco de dados:
db.ratings.find()
Consultando um banco de dados MariaDB usando Mongo Shell.
Usando Funções JSON no MariaDB
Neste ponto, temos um único banco de dados que, por fora, parece um banco de dados NoSQL (MongoDB) e um banco de dados relacional (MariaDB). Somos capazes de conectar-nos ao mesmo banco de dados e escrever e ler dados de clientes MongoDB e clientes SQL. Todo o dado é armazenado no MariaDB, então podemos usar SQL para unir dados de clientes MongoDB ou aplicativos com dados de clientes MariaDB ou aplicativos. Vamos explorar como o MaxScale está usando o MariaDB para armazenar dados MongoDB (coleções e documentos).
Conecte-se ao banco de dados usando um cliente SQL como mariadb-shell e mostre as tabelas no esquema de demonstração:
show tables in demo;Você deve ver tanto as tabelas books quanto ratings listadas. ratings Foi criada como uma coleção MongoDB. O MaxScale traduziu os comandos enviados pelo cliente MongoDB e criou uma tabela para armazenar os dados em uma tabela. Vamos ver a estrutura desta tabela:
describe demo.ratings;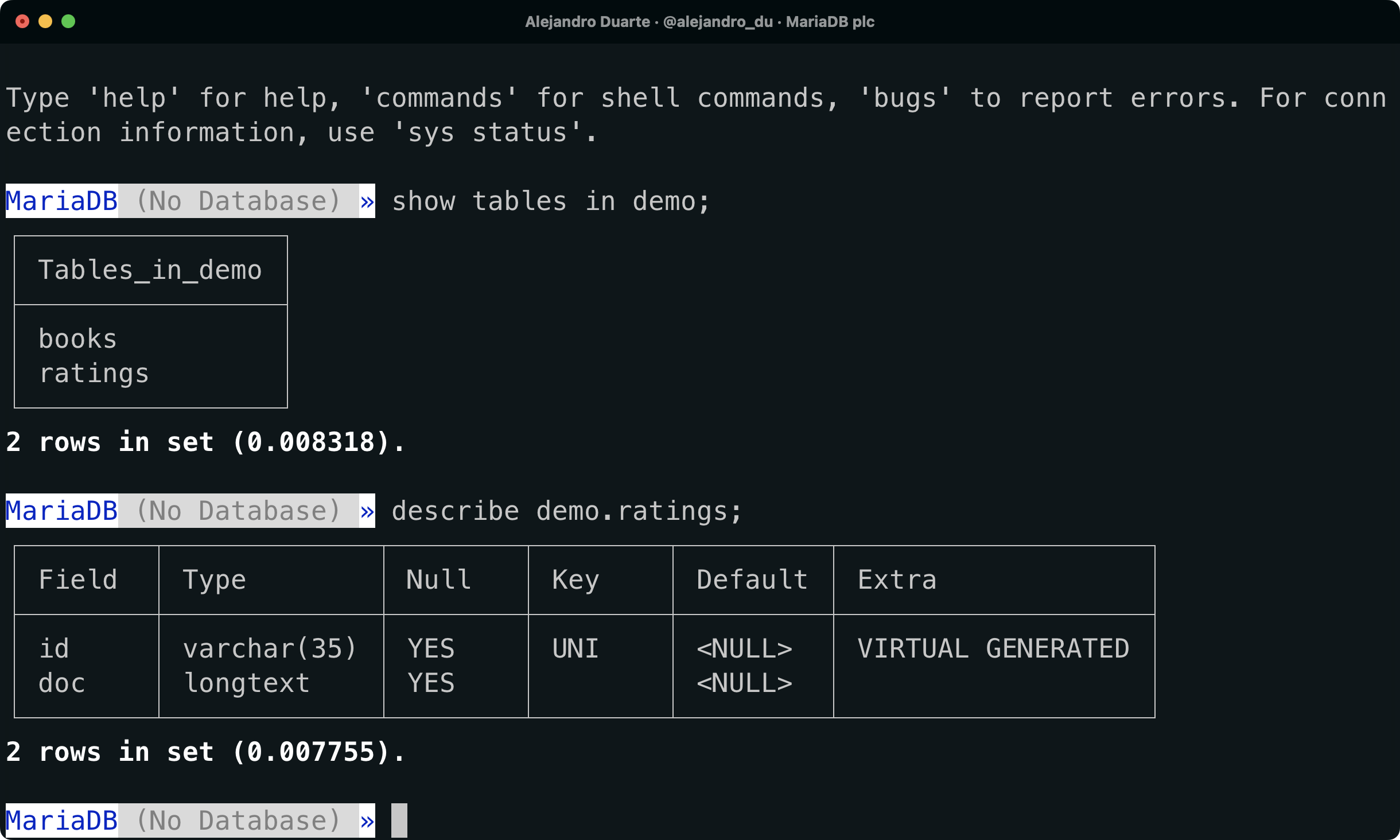
A NoSQL collection is stored as a MariaDB relational table.
A tabela ratings contém duas colunas:
id: o ID do objeto.doc: o documento em formato JSON.
Ao inspecionarmos o conteúdo da tabela, veremos que todos os dados sobre classificações são armazenados na coluna doc em formato JSON:
SELECT doc FROM demo.ratings \G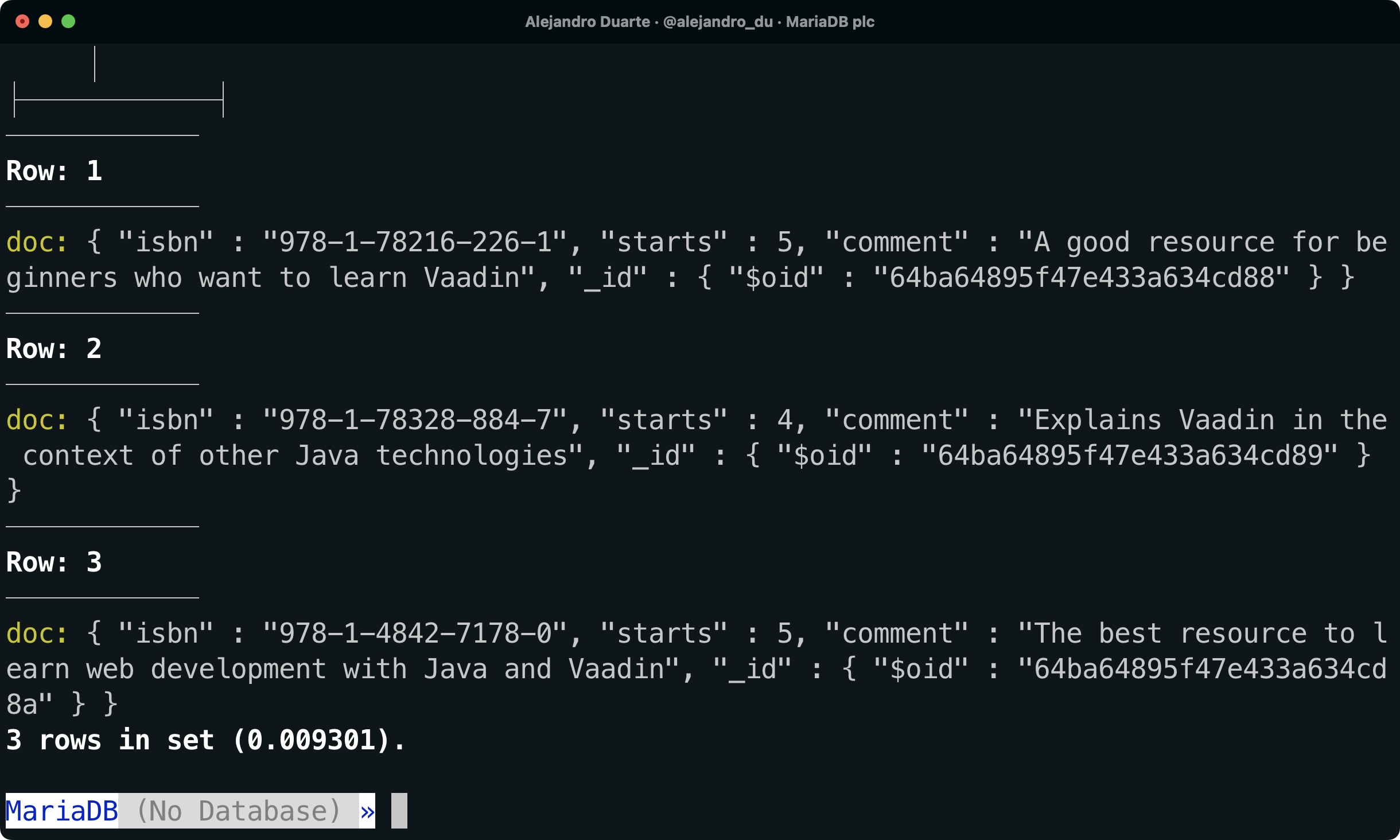
Documentos NoSQL são armazenados em um banco de dados MariaDB.
Voltemos ao nosso objetivo original—mostrar os títulos dos livros com suas informações de classificação. O seguinte não é o caso, mas vamos supor por um momento que a tabela ratings é uma tabela regular com colunas stars e comment. Se fosse esse o caso, juntar essa tabela com a tabela books seria fácil e nosso trabalho estaria concluído:
/* this doesn’t work */
SELECT b.title, r.stars, r.comment
FROM ratings r
JOIN books b USING(isbn)De volta à realidade. Precisamos converter a coluna doc da tabela ratings real em uma expressão relacional que possa ser usada como uma nova tabela na consulta. Algo assim:
/* this still doesn’t work */
SELECT b.title, r.stars, r.comment
FROM ratings rt
JOIN ...something to convert rt.doc to a table... AS r
JOIN books b USING(isbn)Esse algo é a função JSON_TABLE . O MariaDB inclui um conjunto abrangente de funções JSON para manipular strings JSON. Usaremos a função JSON_TABLE para converter a coluna doc em uma forma relacional que possamos usar para realizar junções SQL. A sintaxe geral da função JSON_TABLE é a seguinte:
JSON_TABLE(json_document, context_path COLUMNS (
column_definition_1,
column_definition_2,
...
)
) [AS] the_new_relational_tableOnde:
json_document: uma string ou expressão que retorna os documentos JSON a serem utilizados.context_path: uma expressão JSON Path que define os nós a serem usados como fonte das linhas.
E as definições de coluna (column_definition_1, column_definition_2, etc…) têm a seguinte sintaxe:
new_column_name sql_type PATH path_in_the_json_doc [on_empty] [on_error]Combinando este conhecimento, nossa consulta SQL ficaria da seguinte forma:
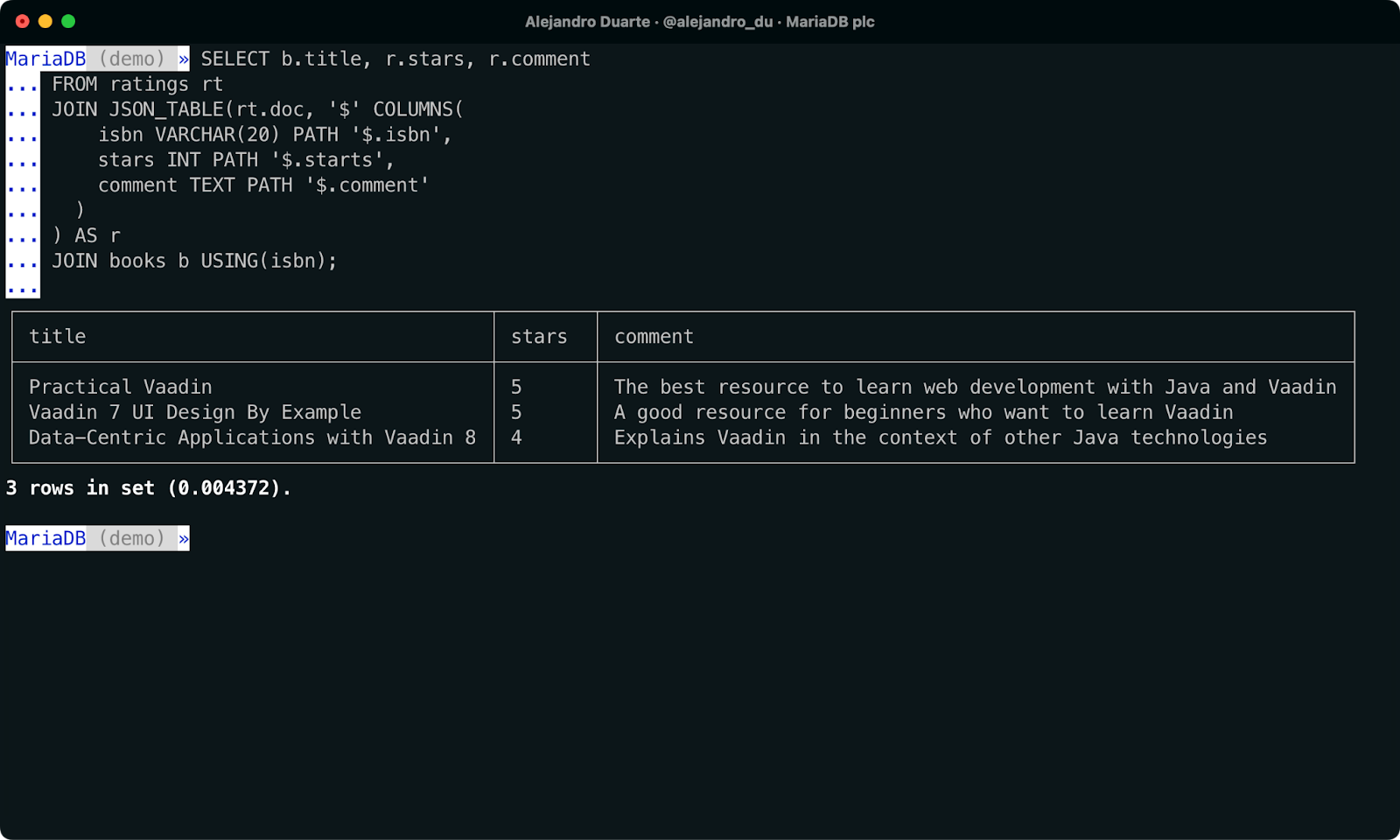
SELECT b.title, r.stars, r.comment
FROM ratings rt
JOIN JSON_TABLE(rt.doc, '$' COLUMNS(
isbn VARCHAR(20) PATH '$.isbn',
stars INT PATH '$.starts',
comment TEXT PATH '$.comment'
)
) AS r
JOIN books b USING(isbn);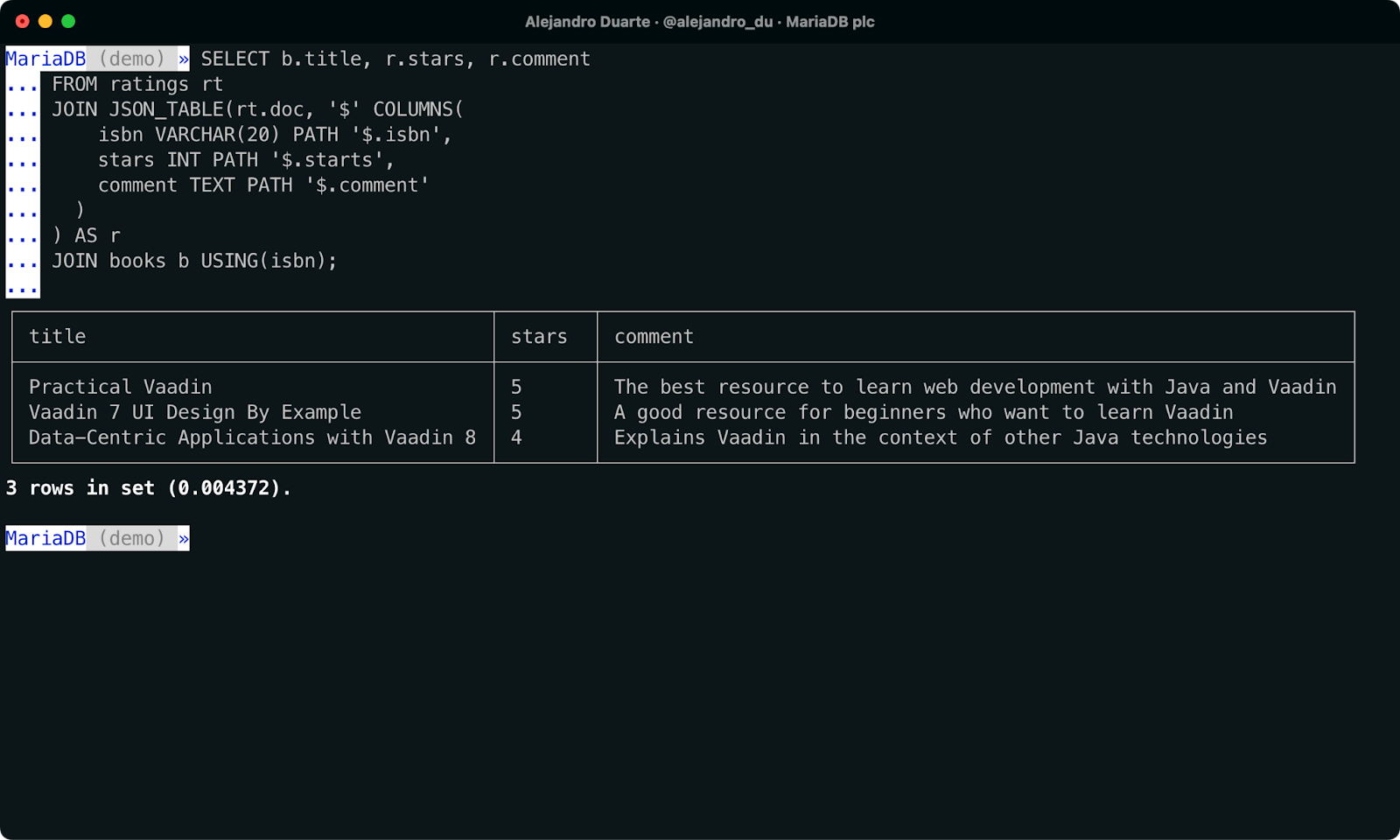
Juntando dados NoSQL e SQL em uma única consulta SQL.
Poderíamos ter usado o valor ISBN como ObjectID do MongoDB e, consequentemente, como a coluna id na tabela ratings, mas deixarei isso para você como exercício (dica: use _id em vez de isbn ao inserir dados usando o cliente ou aplicativo do MongoDB).
A Word on Scalability
Há um equívoco de que bancos de dados relacionais não escalam horizontalmente (adicionando mais nós) enquanto bancos de dados NoSQL escalam. Mas bancos de dados relacionais escalam sem sacrificar as propriedades ACID. O MariaDB possui vários mecanismos de armazenamento adaptados a diferentes cargas de trabalho. Por exemplo, você pode escalar um banco de dados MariaDB implementando sharding de dados com a ajuda do Spider. Você também pode usar uma variedade de mecanismos de armazenamento para lidar com diferentes cargas de trabalho em uma base por tabela. Junções entre mecanismos são possíveis em uma única consulta SQL.
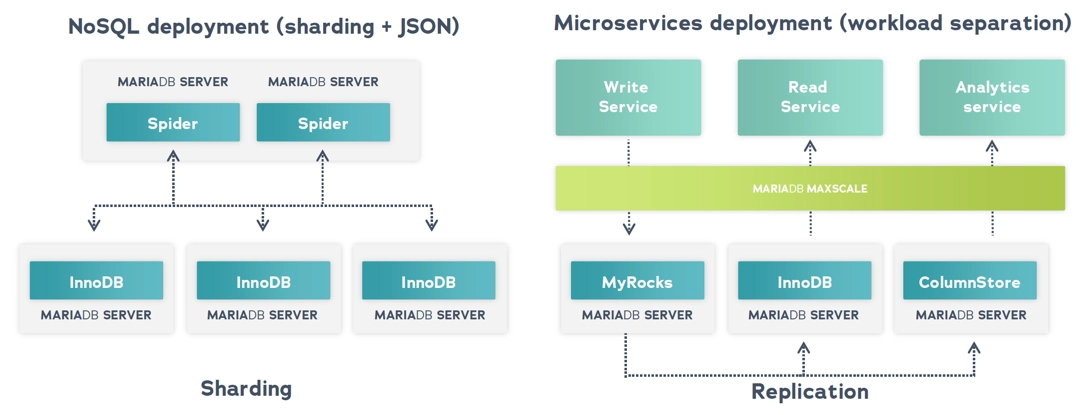
Combinando múltiplos mecanismos de armazenamento em um único banco de dados lógico MariaDB.
Outra alternativa mais moderna é SQL distribuído com MariaDB Xpand. Um banco de dados SQL distribuído aparece como um único banco de dados relacional lógico para as aplicações através do particionamento transparente. Ele utiliza uma arquitetura sem partilha de nada que escala tanto leitura quanto escrita.
A distributed SQL database deployment.
Conclusão
Nosso trabalho aqui está concluído! Agora, seus sistemas podem ter uma visão escalável de 360 graus dos seus dados compatível com ACID, independentemente de ter sido criado por aplicações SQL ou NoSQL. Há menos necessidade de migrar seus aplicativos de NoSQL para SQL ou de tornar aplicativos SQL políglotas em banco de dados. Se deseja aprender mais sobre outras funcionalidades no MaxScale, assista este vídeo ou visite a documentação.
Source:
https://dzone.com/articles/mixing-sql-and-nosql-with-mariadb-and-mongodb