













Este é um segmento da transformação digital de uma gigante do mercado imobiliário. Por motivos de confidencialidade, não vou revelar nenhum dado de negócios, mas você terá uma visão detalhada do nosso data warehouse e das nossas estratégias de otimização.
Agora, vamos começar.
Arquitetura
Logicamente, a nossa arquitetura de dados pode ser dividida em quatro partes.
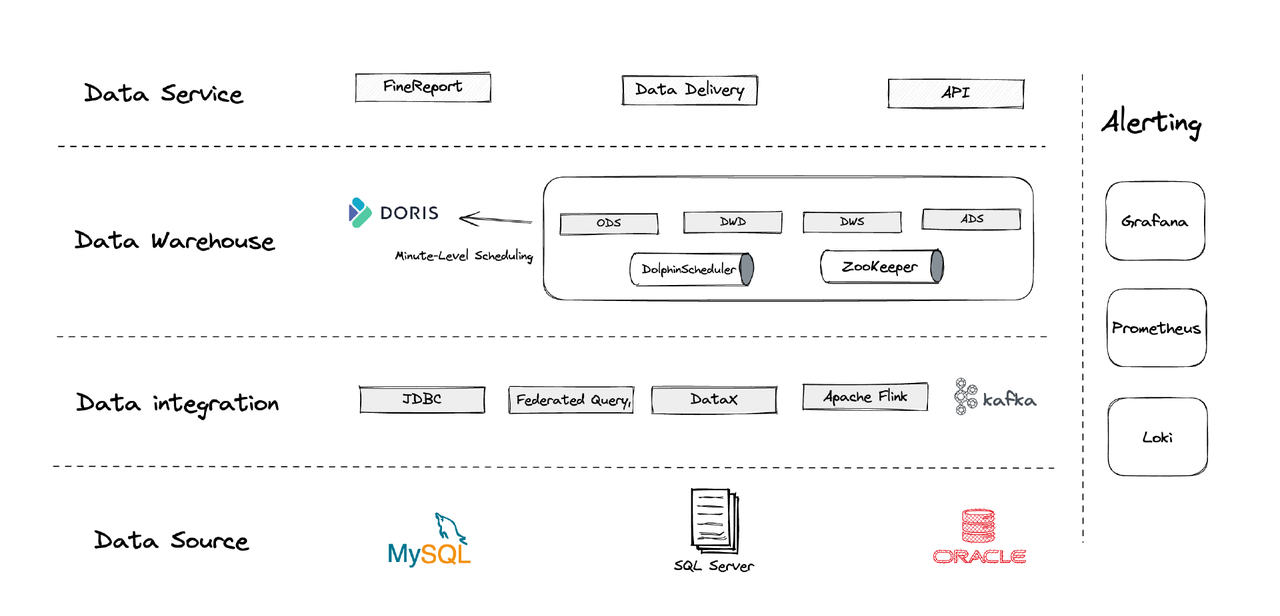
- Integração de dados: Isso é suportado pelo Flink CDC, DataX e o recurso Multi-Catalog do Apache Doris.
- Gestão de dados: Utilizamos o Apache DolphinScheduler para gerenciar o ciclo de vida dos scripts, privilégios na gestão de multi-locatários e monitoramento da qualidade dos dados.
- Alertas: Utilizamos Grafana, Prometheus e Loki para monitorar os recursos dos componentes e os logs.
- Serviços de dados: É aqui que as ferramentas de BI entram em ação para a interação do usuário, como consultas e análises de dados.
1. Tabelas
Criamos nossas tabelas de dimensões e de fatos centralizando cada entidade operacional no negócio, incluindo clientes, casas, etc. Se houver uma série de atividades envolvendo a mesma entidade operacional, elas devem ser registradas por um único campo. (Esta é uma lição aprendida a partir do nosso antigo sistema de gestão de dados caótico.)
2. Camadas
Nosso data warehouse é dividido em cinco camadas conceituais. Utilizamos o Apache Doris e o Apache DolphinScheduler para agendar os scripts DAG entre essas camadas.

Todos os dias, as camadas passam por uma atualização geral além de atualizações incrementais no caso de alterações nos campos de status históricos ou sincronização incompleta de dados das tabelas ODS.
3. Estratégias de Atualização Incremental
(1) Defina where >= "activity time -1 dia ou -1 hora" em vez de where >= "activity time
A razão para fazer isso é impedir o desvio de dados causado pela lacuna de tempo nos scripts de agendamento. Digamos que, com o intervalo de execução definido para 10 minutos, suponha que o script seja executado às 23:58:00 e um novo dado chegue às 23:59:00. Se definirmos where >= "activity time, esse dado do dia será perdido.
(2) Busque o ID da maior chave primária da tabela antes de cada execução do script, armazene o ID na tabela auxiliar e defina where >= "ID na tabela auxiliar"
Isso é para evitar a duplicação de dados. A duplicação de dados pode ocorrer se você usar o modelo de Chave Única do Apache Doris e designar um conjunto de chaves primárias, pois se houver quaisquer alterações nas chaves primárias na tabela de origem, as alterações serão registradas e os dados relevantes serão carregados. Este método pode corrigir isso, mas é aplicável apenas quando as tabelas de origem têm chaves primárias de incremento automático.
(3) Particione as tabelas
No que diz respeito a dados auto-incrementais baseados no tempo, como tabelas de log, pode haver menos alterações nos dados históricos e no status, mas o volume de dados é grande, portanto, pode haver uma enorme pressão computacional em atualizações globais e criação de instantâneos. Por isso, é melhor particionar tais tabelas para que, a cada atualização incremental, precisemos substituir apenas uma partição. (Você também pode precisar estar atento à deriva de dados.)
4. Estratégias de Atualização Geral
(1) Truncar Tabela
Limpar a tabela e, em seguida, ingerir todos os dados da tabela de origem nela. Isso é aplicável para pequenas tabelas e cenários sem atividade do usuário nas primeiras horas da madrugada.
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
Esta é uma operação atômica, e é recomendável para tabelas grandes. Antes de executar um script, criamos uma tabela temporária com o mesmo esquema, carregamos todos os dados nela e substituímos a tabela original por ela.
Aplicação
- Trabalho ETL: a cada minuto
- Configuração para implantação inicial: 8 nós, 2 frontends, 8 backends, implantação híbrida
- Configuração do Nó: 32C * 60GB * 2TB SSD
Esta é a nossa configuração para TBs de dados legados e GBs de dados incrementais. Você pode usá-la como referência e dimensionar seu cluster a partir disso. A implantação do Apache Doris é simples. Você não precisa de outros componentes.
1. Para integrar dados offline e dados de log, utilizamos o DataX, que suporta o formato CSV e leitores de vários bancos de dados relacionais, e o Apache Doris fornece um DataX-Doris-Writer.

2. Utilizamos o Flink CDC para sincronizar dados das tabelas de origem. Em seguida, agregamos as métricas em tempo real utilizando a Visualização Materializada ou o Modelo Agregado do Apache Doris. Como só precisamos processar parte das métricas de maneira em tempo real e não queremos gerar muitas conexões com o banco de dados, usamos um trabalho Flink para manter várias tabelas de origem CDC. Isso é realizado pelas funcionalidades de mescla de múltiplas fontes e sincronização completa do banco de dados do Dinky, ou você pode implementar uma tarefa de mescla de múltiplas fontes do Flink DataStream por conta própria. Vale ressaltar que o Flink CDC e o Apache Doris suportam a Mudança de Esquema.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. Utilizamos scripts SQL ou “Shell + SQL” e realizamos a gestão do ciclo de vida dos scripts. Na camada ODS, escrevemos um arquivo de trabalho DataX genérico e passamos parâmetros para cada ingestão de tabela de origem em vez de escrever um trabalho DataX para cada tabela de origem. Dessa forma, facilitamos muito a manutenção. Gerenciamos os scripts ETL do Apache Doris no DolphinScheduler, onde também realizamos o controle de versão. Caso ocorra algum erro no ambiente de produção, sempre podemos fazer um rollback.
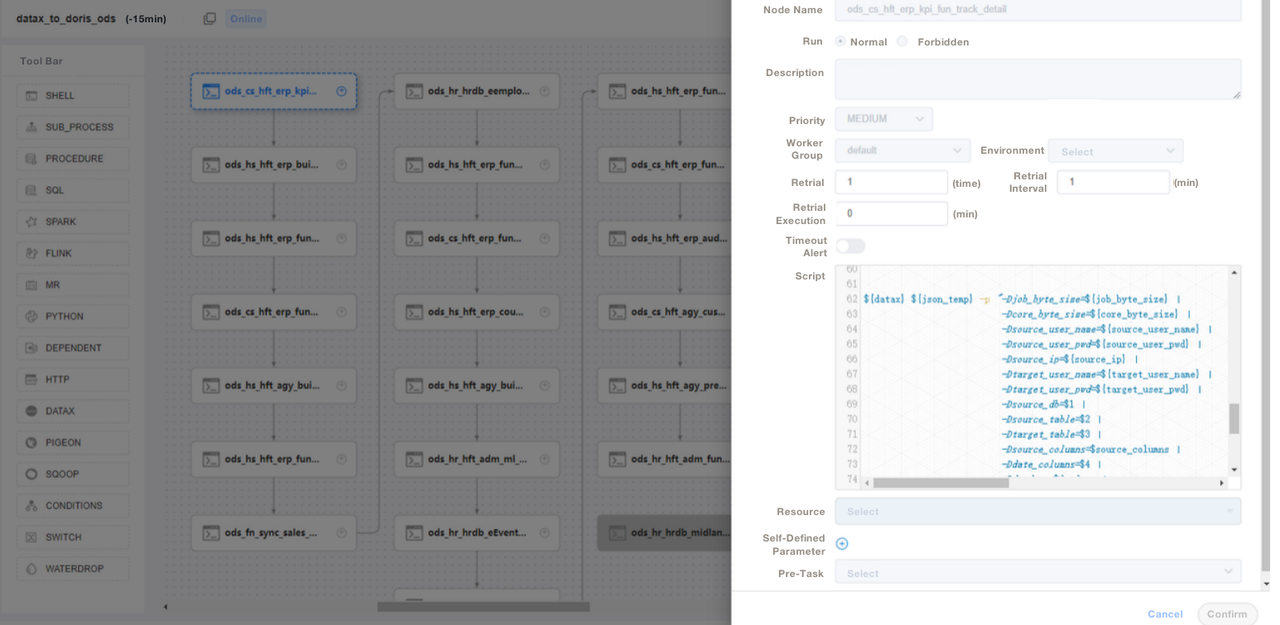
4. Após ingerir dados com scripts ETL, criamos uma página em nossa ferramenta de relatórios. Atribuímos diferentes privilégios a contas diferentes usando SQL, incluindo o privilégio de modificar linhas, campos e dicionários globais. O Apache Doris suporta controle de privilégios sobre contas, o que funciona da mesma maneira que no MySQL.
Também utilizamos o backup de dados do Apache Doris para recuperação de desastres, logs de auditoria do Apache Doris para monitorar a eficiência da execução de SQL, Grafana+Loki para alertas de métricas do cluster e Supervisor para monitorar os processos de daemon dos componentes de nó.
Otimização
Ingestão de Dados
Utilizamos o DataX para carregar dados offline em fluxo. Permite-nos ajustar o tamanho de cada lote. O método de carregamento em fluxo retorna resultados de forma síncrona, o que atende às necessidades de nossa arquitetura. Se executarmos a importação de dados assíncrona usando o DolphinScheduler, o sistema pode assumir que o script foi executado, o que pode causar confusão. Se você utilizar um método diferente, recomendamos que execute show load no script de shell e verifique o status de filtragem de regex para ver se a ingestão é bem-sucedida.
Modelo de Dados
Adotamos o modelo de Chave Única do Apache Doris para a maioria de nossas tabelas. O modelo de Chave Única garante a idempotência dos scripts de dados e evita efetivamente a duplicação de dados no upstream.
Leitura de Dados Externos
Utilizamos o recurso Multi-Catalog do Apache Doris para conectar-se a fontes de dados externas. Permite-nos criar mapeamentos de dados externos no nível do Catálogo.
Otimização de Consulta
Sugerimos que você coloque os campos mais frequentemente utilizados de tipos não-caracteres (como int e cláusulas where) nos primeiros 36 bytes, para que possa filtrar esses campos em milissegundos em consultas pontuais.
Dicionário de Dados
Para nós, é importante criar um dicionário de dados porque reduz em grande parte os custos de comunicação entre os funcionários, o que pode ser uma dor de cabeça quando se tem uma grande equipe. Utilizamos o information_schema no Apache Doris para gerar um dicionário de dados. Com ele, podemos rapidamente compreender a visão geral das tabelas e campos, o que aumenta a eficiência do desenvolvimento.
Desempenho
Tempo de ingestão de dados offline: Em minutos
Latência de consulta: Para tabelas contendo mais de 100 milhões de linhas, o Apache Doris responde a consultas ad-hoc em um segundo e consultas complexas em cinco segundos.
Consumo de recursos: São necessários apenas um pequeno número de servidores para construir este data warehouse. A taxa de compressão de 70% do Apache Doris nos economiza muitos recursos de armazenamento.
Experiência e Conclusão
Na verdade, antes de evoluirmos para a nossa atual arquitetura de dados, tentamos Hive, Spark e Hadoop para construir um data warehouse offline. Aconteceu que o Hadoop era desnecessariamente robusto para uma empresa tradicional como a nossa, já que não tínhamos muitos dados para processar. É importante encontrar o componente que mais se adequa a você.
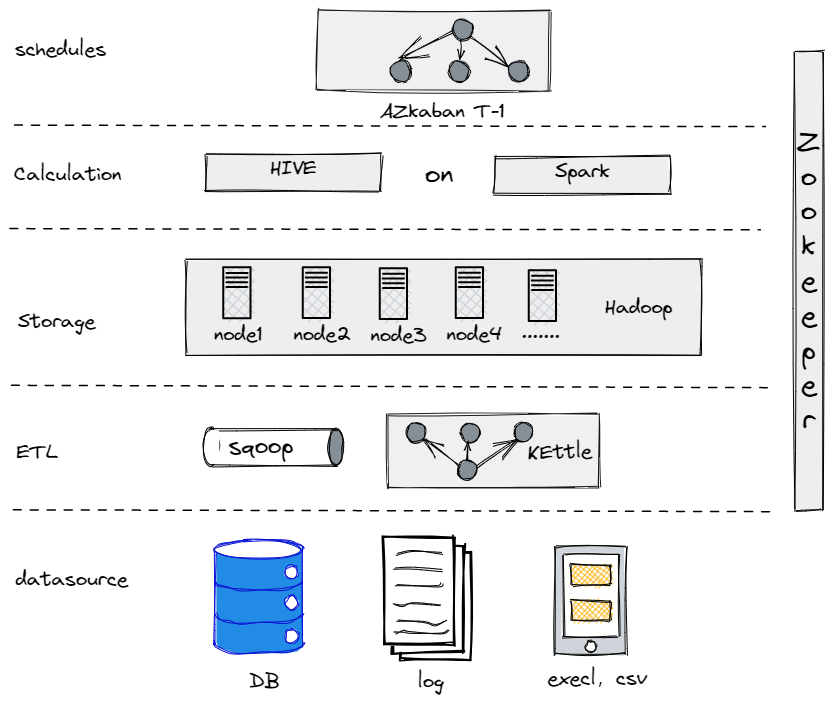
Nosso Antigo Data Warehouse Offline
Por outro lado, para suavizar nossa transição para big data, precisamos tornar nossa plataforma de dados o mais simples possível em termos de uso e manutenção. É por isso que escolhemos o Apache Doris. Ele é compatível com o protocolo MySQL e oferece uma rica coleção de funções, portanto, não precisamos desenvolver nossas próprias UDFs. Além disso, é composto apenas por dois tipos de processos: frontends e backends, facilitando a escalabilidade e o rastreamento.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry