













Whisper AI é um modelo avançado de reconhecimento automático de fala (ASR) desenvolvido pela OpenAI que pode transcrever áudio em texto com precisão impressionante e suporta múltiplos idiomas. Embora o Whisper AI seja projetado principalmente para processamento em lote, ele pode ser configurado para transcrição de fala em tempo real no Linux.
Neste guia, vamos passar pelo processo passo a passo de instalação, configuração e execução do Whisper AI para transcrição ao vivo em um sistema Linux.
O que é o Whisper AI?
Whisper AI é um modelo de reconhecimento de fala de código aberto treinado em um vasto conjunto de dados de gravações de áudio e é baseado em uma arquitetura de aprendizado profundo que permite que ele:
- Transcreva fala em múltiplos idiomas.
- Gerencie sotaques e ruídos de fundo de forma eficiente.
- Realize a tradução de linguagem falada para o inglês.
Como é projetado para transcrição de alta precisão, é amplamente utilizado em:
- Serviços de transcrição ao vivo (por exemplo, para acessibilidade).
- Assistentes de voz e automação.
- Transcrição de arquivos de áudio gravados.
Por padrão, Whisper AI não é otimizado para processamento em tempo real. No entanto, com algumas ferramentas adicionais, ele pode processar fluxos de áudio ao vivo para transcrição imediata.
Requisitos do Sistema Whisper AI
Antes de executar o Whisper AI no Linux, certifique-se de que seu sistema atenda aos seguintes requisitos:
Requisitos de hardware:
- CPU: Um processador multi-core (Intel/AMD).
- RAM: Pelo menos 8GB (16GB ou mais é recomendado).
- GPU: GPU NVIDIA com CUDA (opcional, mas acelera significativamente o processamento).
- Armazenamento: Mínimo de 10GB de espaço livre em disco para modelos e dependências.
Requisitos de software:
- Uma distribuição Linux como Ubuntu, Debian, Arch, Fedora, etc.
- Python versão 3.8 ou posterior.
- Gerenciador de pacotes Pip para instalar pacotes Python.
- FFmpeg para lidar com arquivos e fluxos de áudio.
Passo 1: Instalando Dependências Necessárias
Antes de instalar o Whisper AI, atualize sua lista de pacotes e atualize os pacotes existentes.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
Em seguida, você precisa instalar o Python 3.8 ou superior e o gerenciador de pacotes Pip conforme mostrado.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Por fim, você precisa instalar o FFmpeg, que é um framework multimídia usado para processar arquivos de áudio e vídeo.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Passo 2: Instale o Whisper AI no Linux
Uma vez que as dependências necessárias estejam instaladas, você pode prosseguir para instalar Whisper AI em um ambiente virtual que permite instalar pacotes Python sem afetar os pacotes do sistema.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
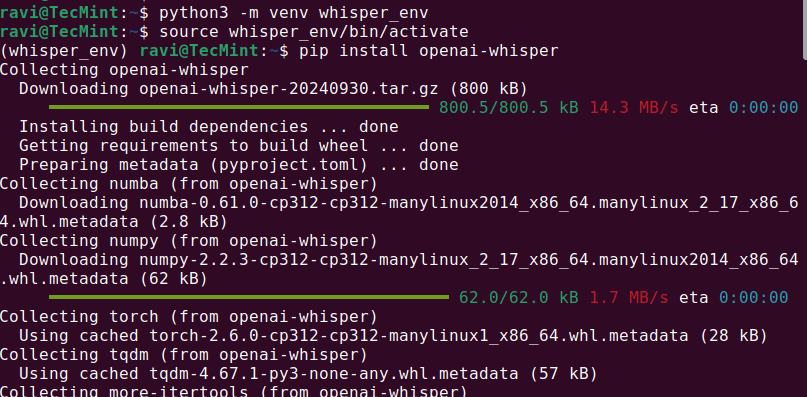
Após a instalação ser concluída, verifique se Whisper AI foi instalado corretamente executando.
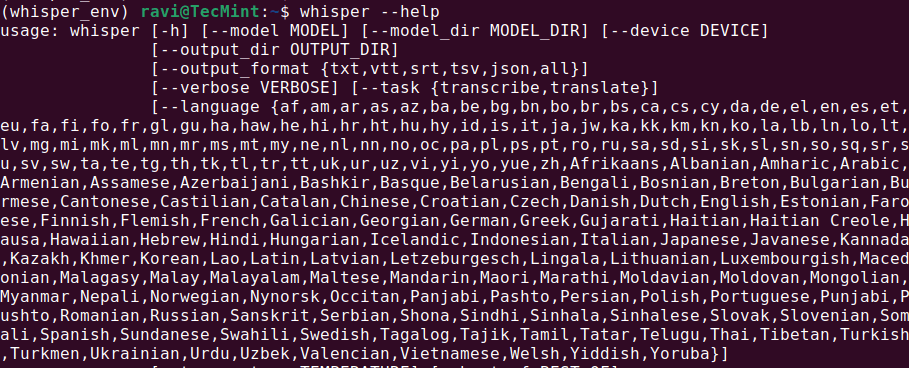
whisper --help
Isso deve exibir um menu de ajuda com os comandos e opções disponíveis, o que significa que Whisper AI está instalado e pronto para uso.
Passo 3: Executando Whisper AI no Linux
Uma vez que Whisper AI esteja instalado, você pode começar a transcrever arquivos de áudio usando diferentes comandos.
Transcrevendo um Arquivo de Áudio
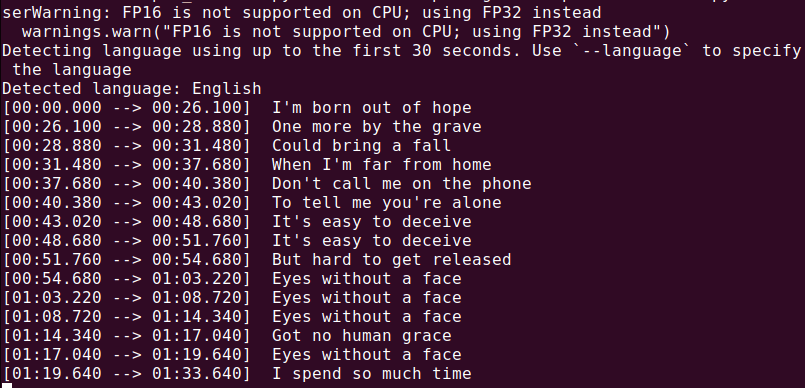
Para transcrever um arquivo de áudio (audio.mp3), execute:
whisper audio.mp3
Whisper processará o arquivo e gerará uma transcrição em formato de texto.
Agora que tudo está instalado, vamos criar um script Python para capturar áudio do seu microfone e transcrevê-lo em tempo real.
nano real_time_transcription.py
Copie e cole o seguinte código no arquivo.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
Execute o script usando Python, que começará a escutar a entrada do seu microfone e exibirá o texto transcrito em tempo real. Fale claramente no seu microfone e você deverá ver os resultados impressos no terminal.
python3 real_time_transcription.py
Conclusão
Whisper AI é uma poderosa ferramenta de conversão de fala em texto que pode ser adaptada para transcrição em tempo real no Linux. Para melhores resultados, use uma GPU e otimize seu sistema para processamento em tempo real.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/