













Quando se trabalha com Amazon S3 (Simple Storage Service), você provavelmente está usando o console web do S3 para baixar, copiar ou enviar arquivos para os buckets do S3. Usar o console é perfeitamente aceitável, afinal, foi para isso que ele foi projetado inicialmente.
Especialmente para administradores que estão acostumados a clicar mais com o mouse do que a usar comandos do teclado, o console web é provavelmente o mais fácil. No entanto, os administradores eventualmente vão encontrar a necessidade de realizar operações em massa de arquivos com a Amazon S3, como um envio de arquivos não assistido. A GUI não é a melhor ferramenta para isso.
Para tais requisitos de automação com Amazon Web Services, incluindo Amazon S3, a ferramenta AWS CLI fornece aos administradores opções de linha de comando para gerenciar buckets e objetos da Amazon S3.
Neste artigo, você aprenderá como usar a ferramenta de linha de comando AWS CLI para enviar, copiar, baixar e sincronizar arquivos com a Amazon S3. Você também aprenderá o básico de como fornecer acesso ao seu bucket do S3 e configurar esse perfil de acesso para funcionar com a ferramenta AWS CLI.
Pré-requisitos
Já que este é um artigo prático, haverá exemplos e demonstrações nas seções seguintes. Para acompanhar com sucesso, você precisará atender a vários requisitos.
- Uma conta da AWS. Se você não tiver uma assinatura da AWS existente, você pode se inscrever para um Plano Gratuito da AWS.
- Um bucket do AWS S3. Você pode usar um bucket existente se preferir, mas é recomendável criar um bucket vazio. Por favor, consulte Criando um bucket.
- A Windows 10 computer with at least Windows PowerShell 5.1. In this article, PowerShell 7.0.2 will be used.
- A ferramenta CLI da AWS versão 2 deve estar instalada no seu computador.
- Pastas e arquivos locais que você irá fazer upload ou sincronizar com o Amazon S3
Preparando seu acesso ao AWS S3
Supondo que você já tenha os requisitos necessários. Você pensaria que já poderia ir e começar a operar a CLI da AWS com seu bucket S3. Quer dizer, não seria bom se fosse tão simples assim?
Para aqueles de vocês que estão começando a trabalhar com o Amazon S3 ou a AWS em geral, esta seção visa ajudá-lo a configurar o acesso ao S3 e configurar um perfil da CLI da AWS.
A documentação completa para criar um usuário IAM na AWS pode ser encontrada neste link abaixo. Criando um usuário IAM na sua conta da AWS
Criando um usuário IAM com permissão de acesso ao S3
Ao acessar a AWS usando a CLI, você precisará criar um ou mais usuários IAM com acesso suficiente aos recursos com os quais pretende trabalhar. Nesta seção, você criará um usuário IAM com acesso ao Amazon S3.
Para criar um usuário IAM com acesso ao Amazon S3, você primeiro precisa fazer login no seu console AWS IAM. Sob o grupo de gerenciamento de acesso, clique em Usuários. Em seguida, clique em Adicionar usuário.
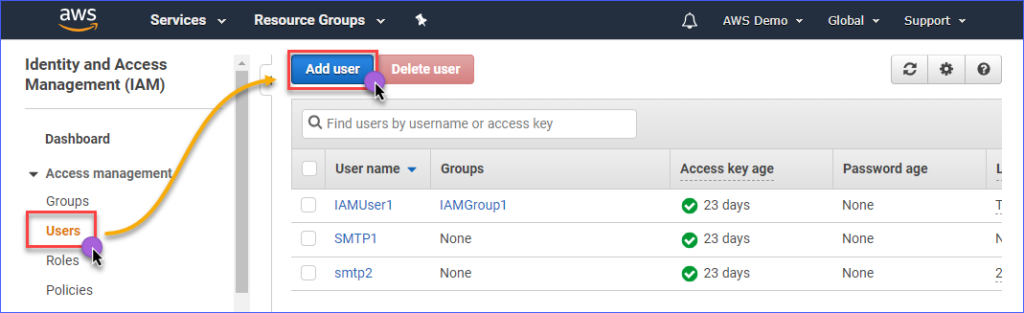
Insira o nome do usuário IAM que está criando na caixa Nome do usuário*, como por exemplo s3Admin. Na seleção de Tipo de acesso*, marque Acesso programático. Em seguida, clique no botão Próxima: Permissões.

Depois, clique em Anexar políticas existentes diretamente. Em seguida, pesquise pelo nome da política AmazonS3FullAccess e marque-a. Quando terminar, clique em Próxima: Tags.

A criação de tags é opcional na página Adicionar tags, e você pode pular esta etapa e clicar no botão Próxima: Revisar.
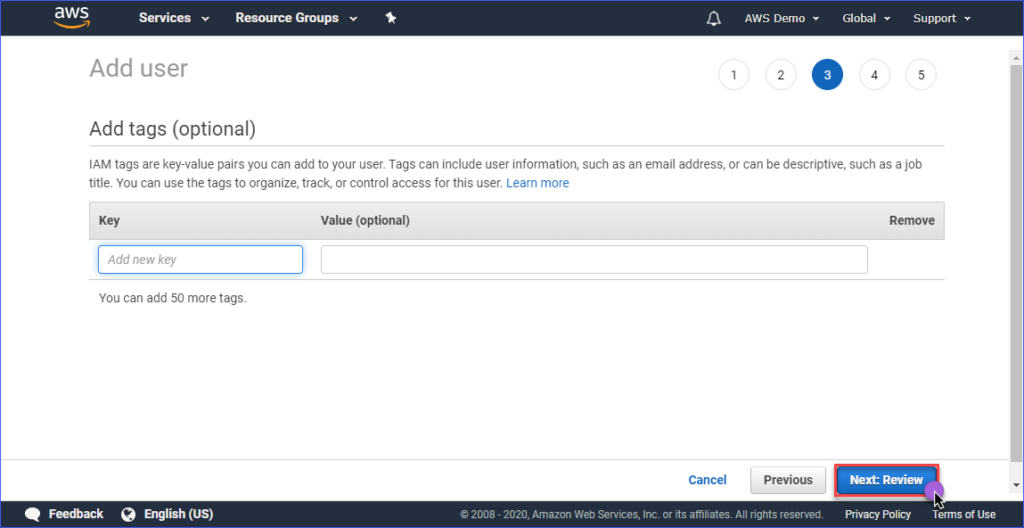
Na página Revisar, você verá um resumo da nova conta sendo criada. Clique em Criar usuário.
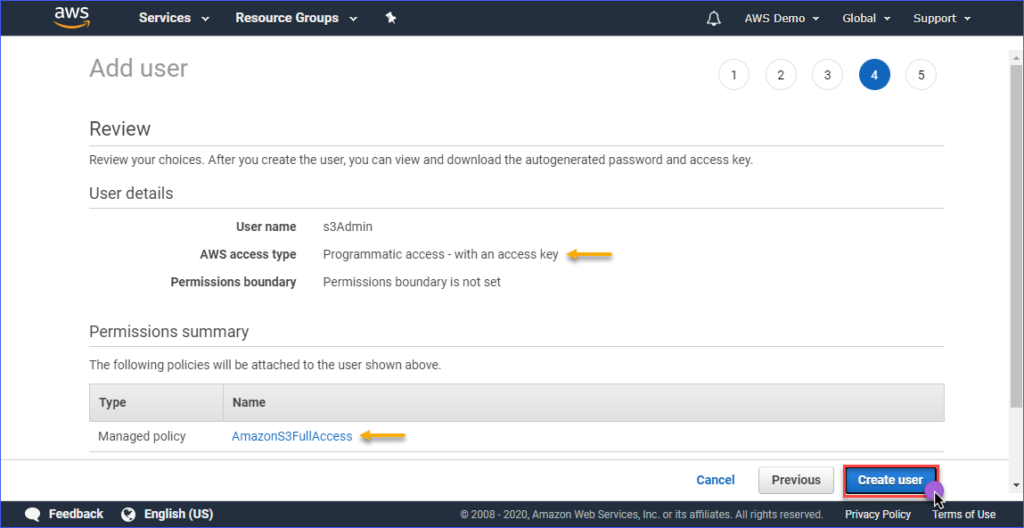
Finalmente, após a criação do usuário, você deve copiar os valores de Chave de acesso e Chave de acesso secreta e salvá-los para uso posterior. Lembre-se de que esta é a única vez que você pode visualizar esses valores.
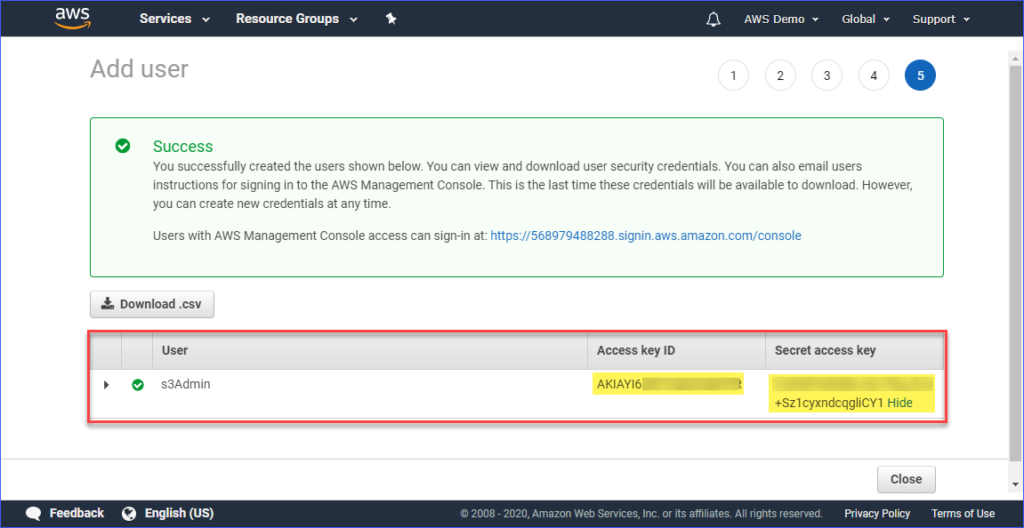
Configurando um Perfil AWS em seu Computador
Agora que você criou o usuário IAM com o acesso apropriado ao Amazon S3, o próximo passo é configurar o perfil AWS CLI no seu computador.
Esta seção pressupõe que você já tenha instalado a AWS CLI versão 2 como necessário. Para a criação do perfil, você precisará das seguintes informações:
- O ID da chave de acesso do usuário IAM.
- A chave de acesso secreta associada ao usuário IAM.
- O nome da região padrão corresponde à localização do seu bucket AWS S3. Você pode conferir a lista de endpoints usando este link. Neste artigo, o bucket AWS S3 está localizado na região Ásia Pacífico (Sydney), e o endpoint correspondente é ap-southeast-2.
- O formato padrão de saída. Use JSON para isso.
Para criar o perfil, abra o PowerShell e digite o comando abaixo e siga as instruções.
Insira o ID da chave de acesso, chave de acesso secreta, nome da região padrão, e nome de saída padrão. Consulte a demonstração abaixo.

Testando o acesso à AWS CLI
Após configurar o perfil da AWS CLI, você pode confirmar que o perfil está funcionando executando o seguinte comando no PowerShell.
O comando acima deve listar os buckets do Amazon S3 que você tem em sua conta. A demonstração abaixo mostra o comando em ação. O resultado mostra que a lista de buckets S3 disponíveis indica que a configuração do perfil foi bem-sucedida.

Para aprender sobre os comandos AWS CLI específicos para o Amazon S3, você pode visitar a página Referência de Comandos AWS CLI S3.
Gerenciando Arquivos no S3
Com o AWS CLI, operações típicas de gerenciamento de arquivos podem ser realizadas, como fazer upload de arquivos para o S3, baixar arquivos do S3, excluir objetos no S3 e copiar objetos do S3 para outra localização no S3. Tudo se resume a conhecer o comando certo, a sintaxe, parâmetros e opções corretos.
Nas seções seguintes, o ambiente usado consiste no seguinte.
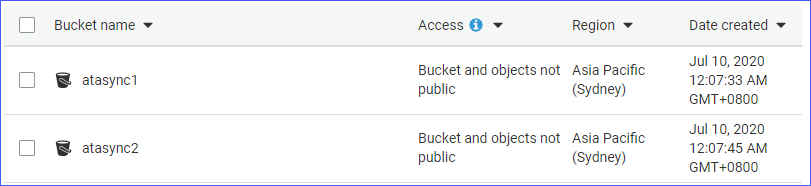
- Duas buckets S3, nomeadamente atasync1 e atasync2. A captura de tela abaixo mostra as buckets S3 existentes na console Amazon S3.
- Diretório local e arquivos localizados em c:\sync.

Enviando Arquivos Individuais para o S3
Ao enviar arquivos para o S3, você pode fazer o upload de um arquivo por vez ou fazer o upload de vários arquivos e pastas recursivamente. Dependendo de seus requisitos, você pode escolher um ou outro, conforme julgar apropriado.
Para enviar um arquivo para o S3, você precisará fornecer dois argumentos (origem e destino) para o comando aws s3 cp.
Por exemplo, para enviar o arquivo c:\sync\logs\log1.xml para a raiz da bucket atasync1, você pode usar o comando abaixo.
Observação: Os nomes das buckets S3 sempre têm o prefixo S3:// quando usados com o AWS CLI
Execute o comando acima no PowerShell, mas altere a origem e o destino que se adequam ao seu ambiente primeiro. A saída deve se parecer com a demonstração abaixo.

A demonstração acima mostra que o arquivo chamado c:\sync\logs\log1.xml foi carregado sem erros para o destino S3 s3://atasync1/.
Use o comando abaixo para listar os objetos na raiz do bucket S3.
Executar o comando acima no PowerShell resultaria em uma saída semelhante, conforme mostrado na demonstração abaixo. Como você pode ver na saída abaixo, o arquivo log1.xml está presente na raiz da localização S3.

Carregando Múltiplos Arquivos e Pastas para S3 Recursivamente
A seção anterior mostrou como copiar um único arquivo para uma localização S3. E se você precisar carregar vários arquivos de uma pasta e subpastas? Certamente você não gostaria de executar o mesmo comando várias vezes para diferentes nomes de arquivo, certo?
O comando aws s3 cp possui uma opção para processar arquivos e pastas recursivamente, e esta é a opção --recursive.
Como exemplo, o diretório c:\sync contém 166 objetos (arquivos e subpastas).
Usando a opção --recursive, todo o conteúdo da pasta c:\sync será carregado para o S3, mantendo também a estrutura de pastas. Para testar, use o código de exemplo abaixo, mas certifique-se de alterar a origem e o destino adequados ao seu ambiente.
Você perceberá no código abaixo que a origem é c:\sync, e o destino é s3://atasync1/sync. A chave /sync que segue o nome do bucket S3 indica ao AWS CLI para enviar os arquivos na pasta /sync para o S3. Se a pasta /sync não existir no S3, ela será criada automaticamente.
O código acima resultará na saída, conforme mostrado na demonstração abaixo.

Enviando Múltiplos Arquivos e Pastas para o S3 de Forma Seletiva
Em alguns casos, enviar TODOS os tipos de arquivos não é a melhor opção. Por exemplo, quando você precisa enviar apenas arquivos com extensões específicas (por exemplo, *.ps1). Outras duas opções disponíveis para o comando cp são --include e --exclude.
Enquanto o uso do comando na seção anterior inclui todos os arquivos no envio recursivo, o comando abaixo incluirá apenas os arquivos que correspondem à extensão de arquivo *.ps1 e excluirá todos os outros arquivos do envio.
A demonstração abaixo mostra como o código acima funciona quando executado.

Outro exemplo é se você quiser incluir várias extensões de arquivo diferentes, será necessário especificar a opção --include várias vezes.
O comando de exemplo abaixo incluirá apenas os arquivos *.csv e *.png no comando de cópia.
A execução do código acima no PowerShell apresentaria um resultado semelhante, conforme mostrado abaixo.

Download de Objetos do S3
Com base nos exemplos que você aprendeu nesta seção, você também pode realizar as operações de cópia em sentido inverso. Ou seja, você pode baixar objetos da localização do bucket S3 para a máquina local.
Copiar do S3 para o local exigiria que você trocasse as posições da origem e do destino. A origem sendo a localização do S3, e o destino é o caminho local, como mostrado abaixo.
Observe que as mesmas opções usadas ao carregar arquivos no S3 também são aplicáveis ao baixar objetos do S3 para o local. Por exemplo, baixar todos os objetos usando o comando abaixo com a opção --recursive.
Copiando Objetos Entre Localizações do S3
Além de carregar e baixar arquivos e pastas, usando o AWS CLI, você também pode copiar ou mover arquivos entre duas localizações de bucket S3.
Você notará o comando abaixo usando uma localização do S3 como origem e outra localização do S3 como destino.
A demonstração abaixo mostra o arquivo de origem sendo copiado para outra localização do S3 usando o comando acima.

Sincronizando Arquivos e Pastas com o S3
Você aprendeu como carregar, baixar e copiar arquivos no S3 usando os comandos AWS CLI até agora. Nesta seção, você aprenderá sobre mais um comando de operação de arquivo disponível no AWS CLI para o S3, que é o comando sync. O comando sync processa apenas os arquivos atualizados, novos e excluídos.
Existem alguns casos em que você precisa manter os conteúdos de um bucket S3 atualizados e sincronizados com um diretório local em um servidor. Por exemplo, você pode ter a necessidade de manter os logs de transação em um servidor sincronizados com o S3 em um intervalo.
Usando o comando abaixo, arquivos de log *.XML localizados sob a pasta c:\sync no servidor local serão sincronizados com a localização S3 em s3://atasync1.
A demonstração abaixo mostra que, após executar o comando acima no PowerShell, todos os arquivos *.XML foram enviados para o destino S3 s3://atasync1/.

Sincronizando Novos Arquivos e Atualizações com o S3
No próximo exemplo, assume-se que o conteúdo do arquivo de log Log1.xml foi modificado. O comando sync deve identificar essa modificação e enviar as alterações feitas no arquivo local para o S3, conforme mostrado na demonstração abaixo.
O comando a ser usado ainda é o mesmo do exemplo anterior.

Como você pode ver na saída acima, uma vez que apenas o arquivo Log1.xml foi alterado localmente, ele também foi o único arquivo sincronizado com o S3.
Sincronizando Deleções com o S3
Por padrão, o comando sync não processa deleções. Qualquer arquivo excluído da localização de origem não é removido no destino. Bem, a não ser que você use a opção --delete.
No próximo exemplo, o arquivo chamado Log5.xml foi excluído da origem. O comando para sincronizar os arquivos será acrescido da opção --delete, conforme mostrado no código abaixo.
Quando você executa o comando acima no PowerShell, o arquivo excluído chamado Log5.xml também deve ser excluído no local de destino do S3. O resultado de exemplo é mostrado abaixo.

Resumo
O Amazon S3 é um excelente recurso para armazenar arquivos na nuvem. Com o uso da ferramenta AWS CLI, a forma como você utiliza o Amazon S3 é ampliada, abrindo a oportunidade para automatizar seus processos.
Neste artigo, você aprendeu como usar a ferramenta AWS CLI para fazer upload, download e sincronização de arquivos e pastas entre locais locais e buckets S3. Você também aprendeu que o conteúdo dos buckets S3 pode ser copiado ou movido para outros locais do S3.
Pode haver muitos cenários de uso para a ferramenta AWS CLI na automação da gestão de arquivos com o Amazon S3. Você pode até tentar combiná-lo com scripts PowerShell e criar suas próprias ferramentas ou módulos reutilizáveis. Cabe a você encontrar essas oportunidades e mostrar suas habilidades.