













VAR-As-A-Service é uma abordagem MLOps para a unificação e reutilização de modelos estatísticos e de aprendizagem de máquina, além de pipelines de implantação desses modelos. Este é o segundo de uma série de artigos construídos sobre esse projeto, representando experimentos com vários modelos estatísticos e de aprendizagem de máquina, pipelines de dados implementados usando ferramentas existentes DAG, e serviços de armazenamento, tanto baseados em nuvem quanto soluções alternativas on-premises. Este artigo se concentra na armazenagem de arquivos de modelos usando uma abordagem também aplicável e utilizada para modelos de aprendizagem de máquina. O armazenamento implementado é baseado em MinIO como um serviço de armazenamento de objetos compatível com o AWS S3. Além disso, o artigo fornece uma visão geral de soluções de armazenamento alternativas e destaca os benefícios do armazenamento baseado em objetos.
O primeiro artigo da série (Análise de Séries Temporais: VARMAX-As-A-Service) compara modelos estatísticos e de aprendizagem de máquina como sendo ambos modelos matemáticos e fornece uma implementação completa de um modelo estatístico baseado em VARMAX para previsão macroeconômica usando uma biblioteca Python chamada statsmodels. O modelo é implantado como um serviço REST usando o Flask Python e o servidor web Apache, embalado em um contêiner Docker. A arquitetura de alto nível do aplicativo é mostrada na imagem a seguir:
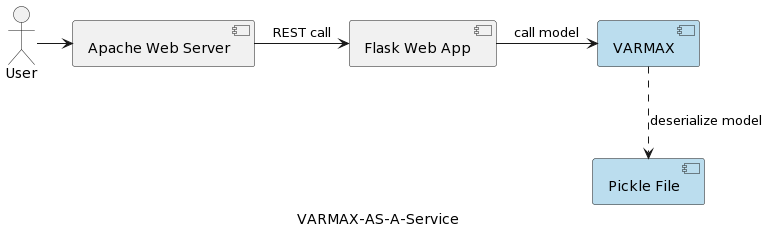
O modelo é serializado como um arquivo pickle e implantado no servidor web como parte do pacote de serviço REST. No entanto, em projetos reais, os modelos são versionados, acompanhados de informações de metadados, e protegidos, e os experimentos de treinamento precisam ser registrados e mantidos reproduzíveis. Além disso, do ponto de vista arquitetural, armazenar o modelo no sistema de arquivos ao lado do aplicativo contradiz o princípio da responsabilidade única. Um bom exemplo é uma arquitetura baseada em microsserviços. Dimensionar o serviço do modelo horizontalmente significa que cada instância de microsserviço terá sua própria versão do arquivo pickle físico replicado em todas as instâncias do serviço. Isso também significa que o suporte a múltiplas versões dos modelos exigirá um novo lançamento e reimplementação do serviço REST e de sua infraestrutura. O objetivo deste artigo é desacoplar os modelos da infraestrutura do serviço web e permitir a reutilização da lógica do serviço web com diferentes versões de modelos.
Antes de mergulhar na implementação, vamos falar um pouco sobre modelos estatísticos e o modelo VAR utilizado nesse projeto. Modelos estatísticos são modelos matemáticos, assim como modelos de aprendizado de máquina. Mais informações sobre a diferença entre os dois podem ser encontradas no primeiro artigo da série. Um modelo estatístico geralmente é especificado como uma relação matemática entre uma ou mais variáveis aleatórias e outras variáveis não aleatórias. Autoregressão Vetorial (VAR) é um modelo estatístico usado para capturar a relação entre múltiplas quantidades à medida que elas mudam ao longo do tempo. Os modelos VAR generalizam o modelo autoregressivo univariado (AR) permitindo séries temporais multivariadas. No projeto apresentado, o modelo é treinado para fazer previsões para duas variáveis. Os modelos VAR são frequentemente utilizados em economia e ciências naturais. Em geral, o modelo é representado por um sistema de equações, que no projeto está oculto atrás da biblioteca Python statsmodels.
A arquitetura do aplicativo de serviço do modelo VAR é retratada na imagem a seguir:
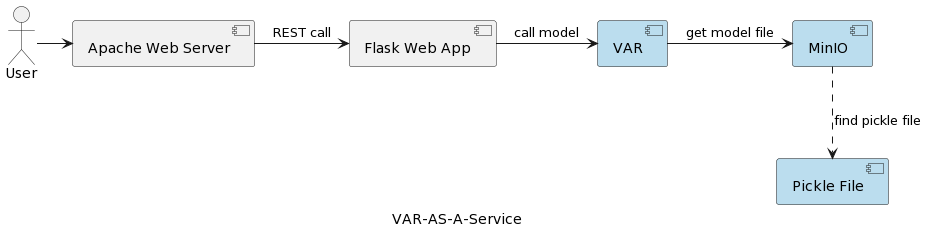
O componente de tempo de execução VAR representa a execução real do modelo com base nos parâmetros enviados pelo usuário. Ele se conecta a um serviço MinIO por meio de uma interface REST, carrega o modelo e executa a previsão. Comparado à solução no primeiro artigo, onde o modelo VARMAX é carregado e desserializado na inicialização do aplicativo, o modelo VAR é lido do servidor MinIO cada vez que uma previsão é acionada. Isso tem o custo de tempo adicional para carregamento e desserialização, mas também traz o benefício de ter a versão mais recente do modelo implantado em cada execução. Além disso, isso permite a versão dinâmica de modelos, tornando-os automaticamente acessíveis a sistemas externos e usuários finais, como será mostrado mais adiante no artigo. Observe que devido a essa sobrecarga de carregamento, o desempenho do serviço de armazenamento selecionado é de grande importância.
Mas por que MinIO e o armazenamento baseado em objetos em geral?
O MinIO é uma solução de armazenamento de objetos de alta performance com suporte nativo para implantações em Kubernetes, oferecendo uma API compatível com o Amazon Web Services S3 e suportando todos os recursos principais do S3. No projeto apresentado, o MinIO está em Modo Standalone, composto por um único servidor MinIO e um único disco ou volume de armazenamento no Linux usando Docker Compose. Para ambientes de desenvolvimento ou produção estendidos, há a opção de modo distribuído descrita no artigo Implantar MinIO em Modo Distribuído.
Vamos dar uma olhada rápida em algumas alternativas de armazenamento, enquanto uma descrição abrangente pode ser encontrada aqui e aqui:
- Armazenamento de arquivos local/distribuído: O armazenamento de arquivos local é a solução implementada no primeiro artigo, pois é a opção mais simples. A computação e o armazenamento estão no mesmo sistema. É aceitável durante a fase de PoC ou para modelos muito simples que suportam uma única versão do modelo. Os sistemas de arquivos locais têm capacidade de armazenamento limitada e são inadequados para conjuntos de dados maiores, caso queiramos armazenar metadados adicionais, como o conjunto de dados de treinamento utilizado. Como não há replicação ou autoscaling, um sistema de arquivos local não pode operar de forma disponível, confiável e escalável. Cada serviço implantado para escalonamento horizontal é implantado com sua própria cópia do modelo. Além disso, o armazenamento local é tão seguro quanto o sistema host. Alternativas ao armazenamento de arquivos local são NAS (Network-attached storage), SAN (Storage-area network), sistemas de arquivos distribuídos (Hadoop Distributed File System (HDFS), Google File System (GFS), Amazon Elastic File System (EFS) e Azure Files). Comparado ao sistema de arquivos local, essas soluções são caracterizadas por disponibilidade, escalabilidade e resiliência, mas vêm com o custo de complexidade aumentada.
- Bancos de dados relacionais: Devido à serialização binária dos modelos, os bancos de dados relacionais oferecem a opção de armazenar modelos em colunas de tabelas como blobs ou dados binários. Desenvolvedores de software e muitos cientistas de dados estão familiarizados com bancos de dados relacionais, o que torna essa solução direta. Versões de modelos podem ser armazenadas como linhas de tabela separadas com metadados adicionais, o que também é fácil de ler do banco de dados. Uma desvantagem é que o banco de dados exigirá mais espaço de armazenamento, o que afetará as cópias de segurança. Ter grandes quantidades de dados binários em um banco de dados também pode afetar o desempenho. Além disso, os bancos de dados relacionais impõem algumas restrições às estruturas de dados, o que pode complicar o armazenamento de dados heterogêneos como arquivos CSV, imagens e arquivos JSON como metadados do modelo.
- Armazenamento de objetos: O armazenamento de objetos existe há algum tempo, mas foi revolucionado quando a Amazon o transformou no primeiro serviço da AWS em 2006 com o Simple Storage Service (S3). O armazenamento de objetos moderno é nativo da nuvem, e outras nuvens logo trouxeram suas ofertas ao mercado. A Microsoft oferece o Azure Blob Storage, e o Google tem o serviço Google Cloud Storage. A API do S3 é o padrão de fato para que os desenvolvedores interajam com o armazenamento na nuvem, e há várias empresas que oferecem armazenamento compatível com o S3 para a nuvem pública, nuvem privada e soluções privadas on-premises. Independentemente de onde o armazenamento de objetos esteja localizado, ele é acessado por meio de uma interface RESTful. Embora o armazenamento de objetos elimine a necessidade de diretórios, pastas e outras organizações hierárquicas complexas, não é uma boa solução para dados dinâmicos que estão constantemente mudando, pois será necessário reescrever todo o objeto para modificá-lo, mas é uma boa escolha para armazenar modelos serializados e a metadados do modelo.
A summary of the main benefits of object storage are:
- Escalabilidade massiva: O tamanho do armazenamento de objetos é praticamente ilimitado, permitindo que os dados escalem para exabytes simplesmente adicionando novos dispositivos. As soluções de armazenamento de objetos também têm o melhor desempenho quando executadas como um cluster distribuído.
- Redução da complexidade: Os dados são armazenados em uma estrutura plana. A falta de árvores complexas ou partições (sem pastas ou diretórios) simplifica a recuperação de arquivos, pois não é necessário conhecer a localização exata.
- Pesquisa: O metadado faz parte dos objetos, facilitando a busca e a navegação sem a necessidade de um aplicativo separado. Pode-se marcar objetos com atributos e informações, como consumo, custo e políticas para exclusão automática, retenção e escalonamento. Devido ao espaço de endereçamento plano do armazenamento subjacente (cada objeto em apenas um bucket e sem buckets dentro de buckets), os repositórios de objetos podem encontrar um objeto entre bilhões de objetos rapidamente.
- Resiliência: O armazenamento de objetos pode replicar automaticamente os dados e armazená-los em vários dispositivos e localizações geográficas. Isso pode ajudar a proteger contra interrupções, garantir contra perda de dados e ajudar a apoiar estratégias de recuperação de desastres.
- Simplicidade: O uso de uma API REST para armazenar e recuperar modelos implica quase nenhuma curva de aprendizado e torna a integração em arquiteturas baseadas em microsserviços uma escolha natural.
É hora de analisar a implementação do modelo VAR como serviço e a integração com o MinIO. O部署 da solução apresentada é simplificado usando Docker e Docker Compose. A organização de todo o projeto é a seguinte:

Assim como no primeiro artigo, a preparação do modelo envolve alguns passos que estão escritos em um script Python chamado var_model.py, localizado em um repositório dedicado GitHub:
- Carregar dados
- Dividir dados em conjunto de treinamento e teste
- Preparar variáveis endógenas
- Encontrar parâmetro de modelo ótimo p (primeiros p lags de cada variável usados como preditores de regressão)
- Instanciar o modelo com os parâmetros ótimos identificados
- Serializar o modelo instanciado em um arquivo pickle
- Armazenar o arquivo pickle como um objeto versionado em um bucket MinIO
Esses passos também podem ser implementados como tarefas em um mecanismo de fluxo de trabalho (por exemplo, Apache Airflow), disparado pela necessidade de treinar uma nova versão do modelo com dados mais recentes. DAGs e suas aplicações em MLOps serão o foco de outro artigo.
O último passo implementado em var_model.py é armazenar o modelo serializado como um arquivo pickle em um bucket no S3. Devido à estrutura plana do armazenamento de objetos, o formato selecionado é:
<nome do bucket>/<nome do arquivo>
No entanto, para nomes de arquivos, é permitido usar uma barra (/) para imitar uma estrutura hierárquica, mantendo a vantagem de uma pesquisa linear rápida. A convenção para armazenar modelos VAR é a seguinte:
models/var/0_0_1/model.pkl
Onde o nome do bucket é models, e o nome do arquivo é var/0_0_1/model.pkl e no MinIO UI, é assim:

Esta é uma maneira muito conveniente de estruturar vários tipos de modelos e versões de modelos, mantendo ainda o desempenho e a simplicidade do armazenamento de arquivos planos.
Observe que a versão do modelo é implementada como parte do nome do modelo. O MinIO também fornece a versão de arquivos, mas a abordagem selecionada aqui tem alguns benefícios:
- Suporte de versões de instantâneo e substituição
- Uso de versão semântica (pontos substituídos por ‘_’ devido a restrições)
- Maior controle da estratégia de versão
- Desacoplamento do mecanismo de armazenamento subjacente em termos de recursos específicos de versão
Uma vez que o modelo é implantado, é hora de expô-lo como um serviço REST usando Flask e implantá-lo usando docker-compose executando MinIO e um servidor Web Apache. A imagem do Docker, bem como o código do modelo, podem ser encontrados em um repositório dedicado GitHub.
E, finalmente, as etapas necessárias para executar o aplicativo são:
- Implantar aplicativo:
docker-compose up -d - Execute o algoritmo de preparação do modelo:
python var_model.py(requer um serviço MinIO em execução) - Verifique se o modelo foi implantado: http://127.0.0.1:9101/browser
- Teste o modelo:
http://127.0.0.1:80/apidocs
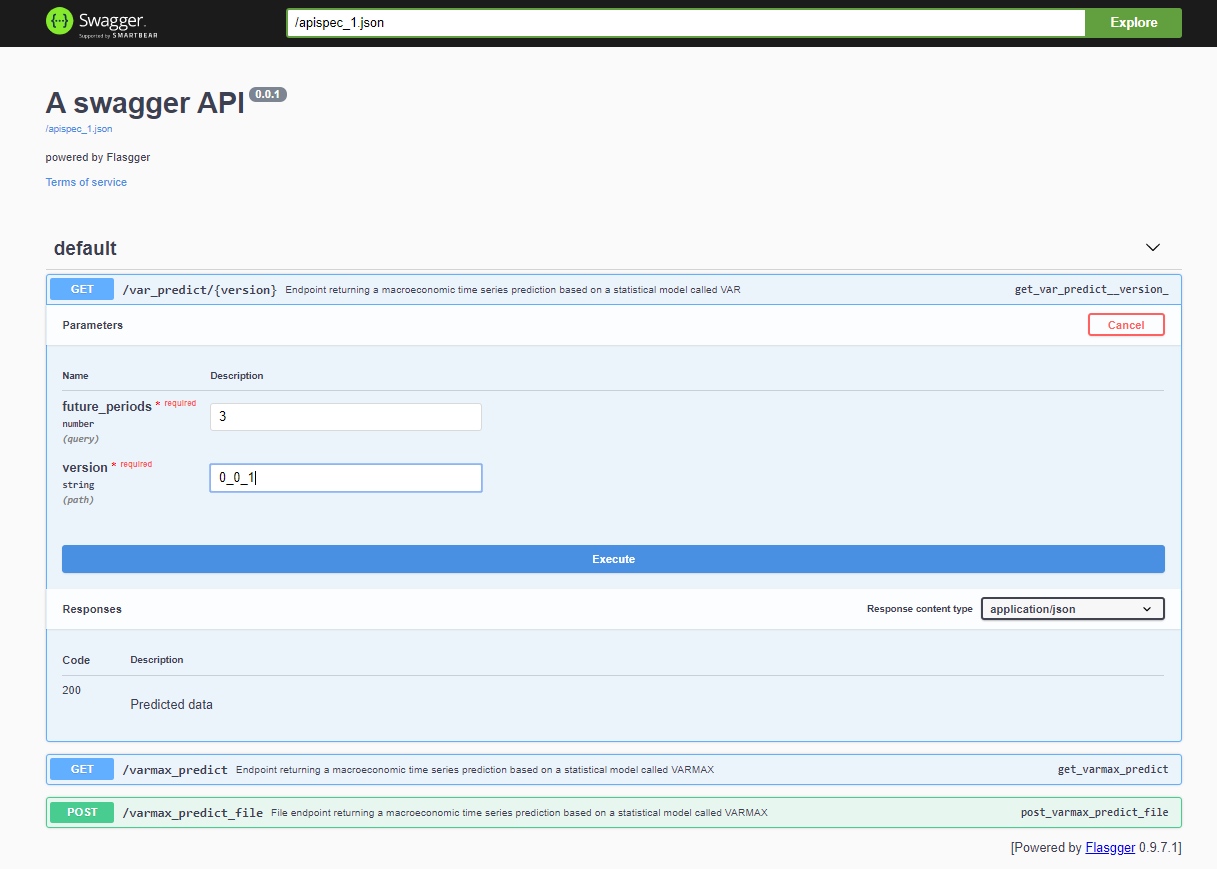
Após implantar o projeto, a API Swagger é acessível através de <host>:<port>/apidocs (por exemplo, 127.0.0.1:80/apidocs). Existe um endpoint para o modelo VAR representado ao lado dos outros dois que expõem um modelo VARMAX:
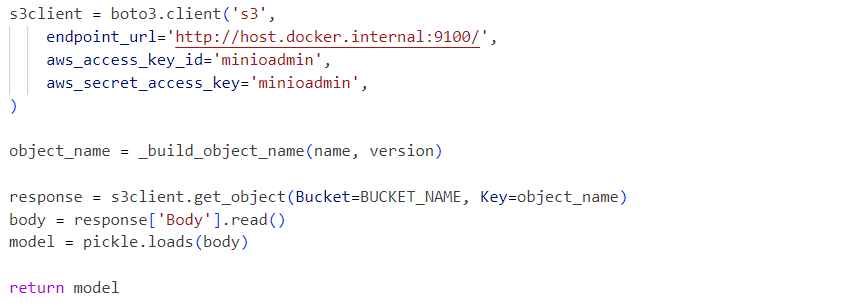
Internamente, o serviço utiliza o arquivo pickle do modelo deserializado carregado a partir de um serviço MinIO:
As requisições são enviadas para o modelo inicializado da seguinte forma:

O projeto apresentado é um fluxo de trabalho de modelo VAR simplificado que pode ser estendido passo a passo com funcionalidades adicionais como:
- Explore formatos de serialização padrão e substitua o pickle por uma solução alternativa
- Integre ferramentas de visualização de dados de séries temporais como Kibana ou Apache Superset
- Armazene dados de séries temporais em um banco de dados de séries temporais como Prometheus, TimescaleDB, InfluxDB, ou um Storage de Objetos como o S3
- Amplie o pipeline com etapas de carregamento de dados e pré-processamento de dados
- Incorpore relatórios de métricas como parte dos pipelines
- Implemente pipelines usando ferramentas específicas como Apache Airflow ou AWS Step Functions ou ferramentas mais padrão como Gitlab ou GitHub
- Comparear o desempenho e a precisão de modelos estatísticos com modelos de aprendizado de máquina
- Implementar soluções integradas em nuvem de ponta a ponta, incluindo Infraestrutura Como Código
- Expôr outros modelos estatísticos e de ML como serviços
- Implementar uma API de Armazenamento de Modelos que abstrai o mecanismo de armazenamento real e a versão do modelo, armazena metadados do modelo e dados de treinamento
Essas melhorias futuras serão o foco de artigos e projetos futuros. O objetivo deste artigo é integrar uma API de armazenamento compatível com S3 e permitir o armazenamento de modelos versão. Essa funcionalidade será extraída em uma biblioteca separada em breve. A solução de infraestrutura end-to-end apresentada pode ser implantada em produção e melhorada como parte de um processo de CI/CD ao longo do tempo, também usando as opções de implantação distribuída do MinIO ou substituindo-o por AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service