













Amazon Simple Storage Service (S3) é um serviço de armazenamento de objetos altamente escalável, durável e seguro oferecido pela Amazon Web Services (AWS). O S3 permite que as empresas armazenem e recuperem qualquer quantidade de dados de qualquer lugar na web, aproveitando seus serviços de nível corporativo. O S3 é projetado para ser altamente interoperável e integra-se perfeitamente com outros serviços da Amazon Web Services (AWS) e ferramentas e tecnologias de terceiros para processar dados armazenados no Amazon S3. Um deles é o Amazon EMR (Elastic MapReduce), que permite processar grandes quantidades de dados usando ferramentas de código aberto como o Spark.
O Apache Spark é um sistema de computação distribuída de código aberto usado para processamentos em larga escala de dados. O Spark foi construído para permitir velocidade e suporta várias fontes de dados, incluindo o Amazon S3. O Spark fornece uma maneira eficiente de processar grandes quantidades de dados e executar cálculos complexos em tempo mínimo.
Memphis.dev é uma alternativa de próxima geração aos tradicionais brokers de mensagens. Um broker de mensagens simples, robusto e durável, nativo de nuvem, envolto em uma eco-sistema completa que permite o desenvolvimento rápido, econômico e confiável de casos de uso modernos baseados em filas.
O padrão comum de brokers de mensagens é apagar as mensagens após passar pela política de retenção definida, como tempo/tamanho/número de mensagens. O Memphis oferece uma segunda camada de armazenamento para retenção mais longa, possivelmente infinita, de mensagens armazenadas. Cada mensagem que é expulsa da estação migrará automaticamente para a segunda camada de armazenamento, que, nesse caso, é o AWS S3.
Neste tutorial, você será guiado através do processo de configuração de uma estação Memphis com uma segunda classe de armazenamento conectada ao AWS S3. Um ambiente na AWS. Seguido da criação de um bucket S3, configuração de um cluster EMR, instalação e configuração do Apache Spark no cluster, preparação de dados no S3 para processamentos, processamento de dados com o Apache Spark, boas práticas e ajuste de desempenho.
Configuração do Ambiente
Memphis
- Para começar, primeiro instale Memphis.
- Habilite a integração com o AWS S3 através do centro de integração do Memphis.
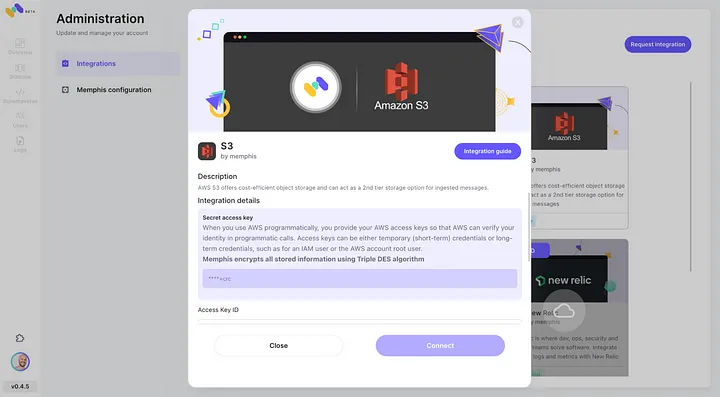
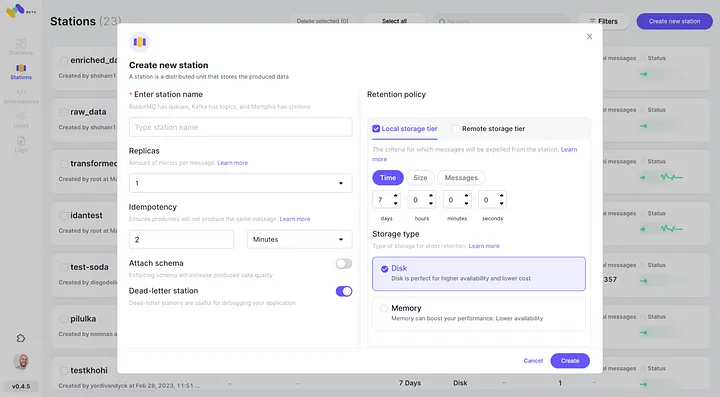
3. Crie uma estação (tópico) e escolha uma política de retenção.
4. Cada mensagem que passar pela política de retenção configurada será descarregada em um bucket S3.
5. Verifique a nova integração com o AWS S3 configurada como segunda classe de armazenamento clicando em “Conectar”.
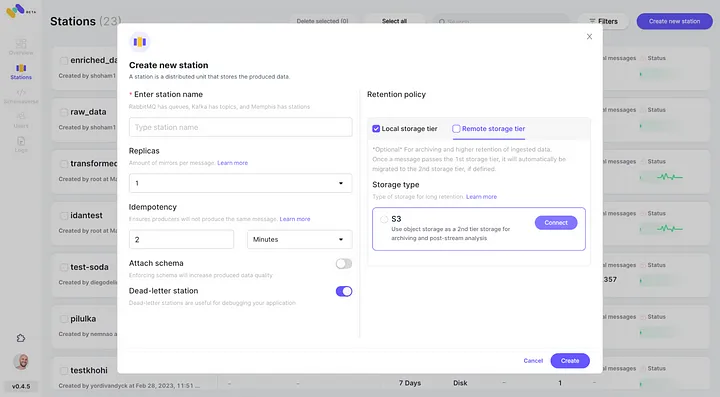
6. Comece a produzir eventos para sua nova estação Memphis criada.
Crie um Bucket AWS S3
Se você ainda não fez isso, primeiro, você precisa criar uma conta AWS conta. Em seguida, crie um bucket S3 onde você pode armazenar seus dados. Você pode usar o Console de Gerenciamento da AWS, a CLI da AWS ou um SDK para criar um bucket. Para este tutorial, você usará o console de gerenciamento da AWS console.
Clique em “Criar bucket”.
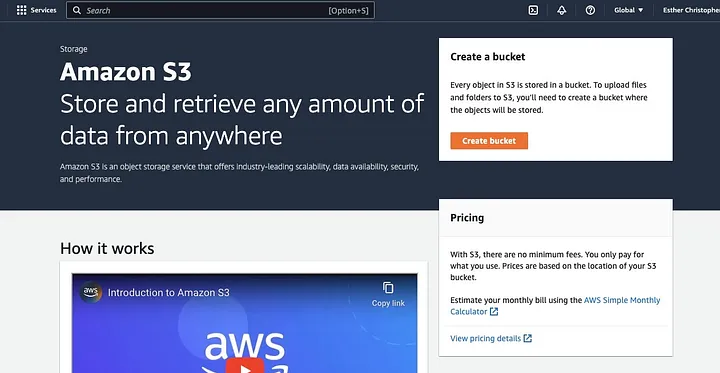
Em seguida, prossiga para criar um nome de bucket que siga a convenção de nomenclatura e escolha a região onde deseja que o bucket seja localizado. Configure a “Propriedade do objeto” e “Bloquear todo o acesso público” de acordo com seu caso de uso.
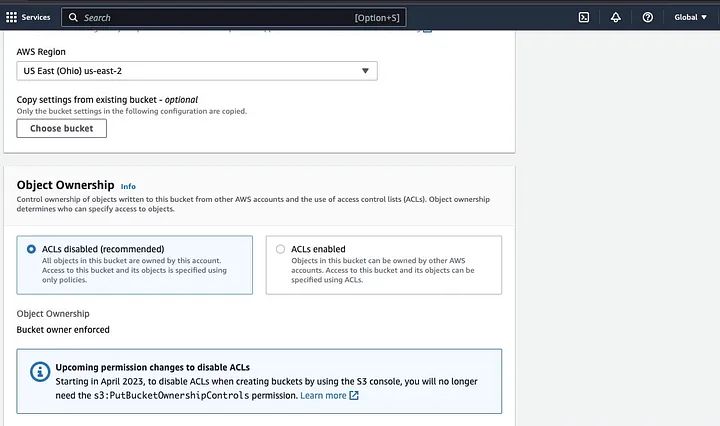
Certifique-se de configurar outras permissões do bucket para permitir que seu aplicativo Spark acesse os dados. Por fim, clique no botão “Criar bucket” para criar o bucket.
Configurando um Cluster EMR com Spark Instalado
O Amazon Elastic MapReduce (EMR) é um serviço baseado na web em Apache Hadoop que permite aos usuários processar grandes quantidades de dados de forma rentável usando tecnologias de big data, incluindo Apache Spark. Para criar um cluster EMR com Spark instalado, abra o console EMR e selecione “Clusters” em “EMR on EC2” no lado esquerdo da página.
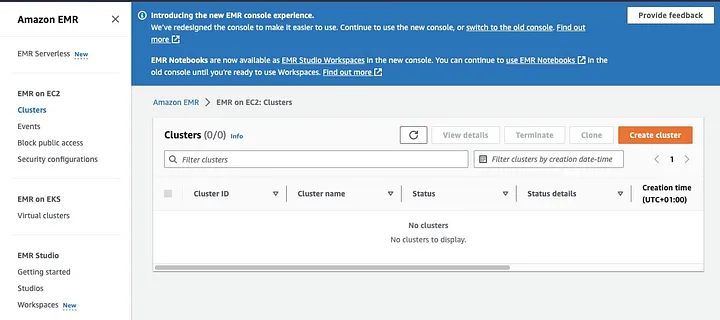
Clique em “Criar cluster” e dê ao cluster um nome descritivo. Em “Pacote de aplicativos”, selecione Spark para instalá-lo no seu cluster.
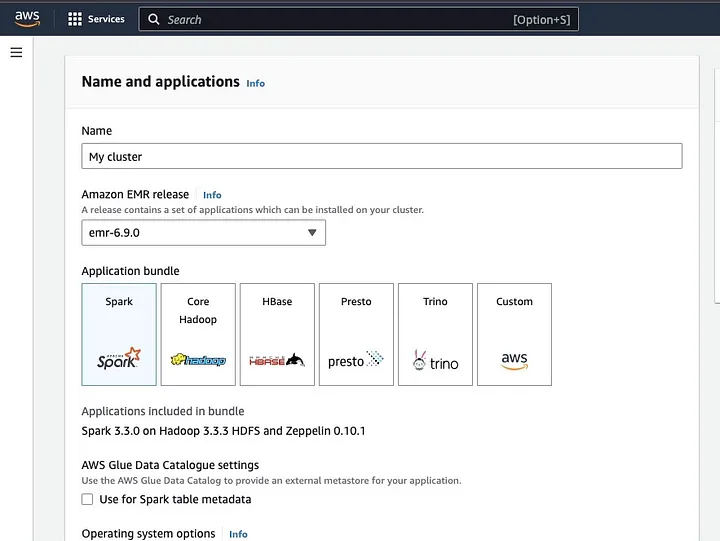
Role para a seção “Logs do cluster” e marque a caixa de “Publicar logs específicos do cluster para o Amazon S3”.
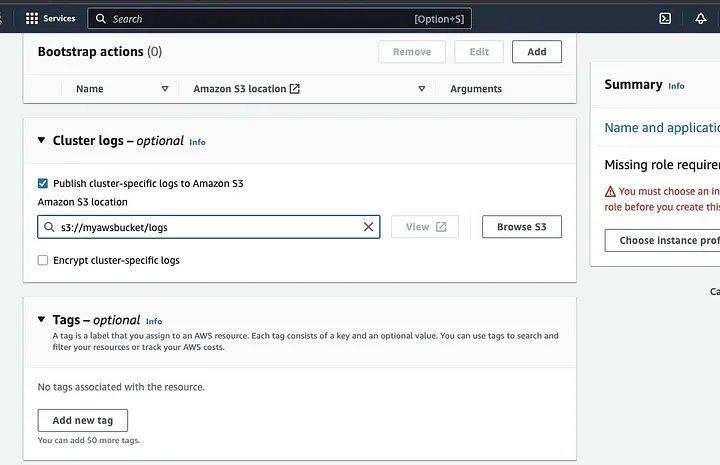
Isso abrirá um prompt para inserir a localização do Amazon S3 usando o nome do bucket S3 que você criou no passo anterior, seguido de /logs, por exemplo, s3://meu-bucket-aws/logs. /logs são necessários pelo Amazon para criar uma nova pasta em seu bucket onde o Amazon EMR pode copiar os arquivos de log do seu cluster.
Vá para a seção “Configuração de segurança e permissões” e insira sua chave EC2 ou vá com a opção para criar uma.
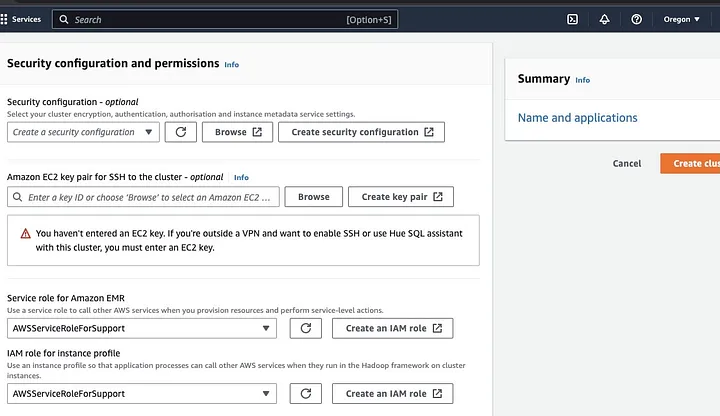
Em seguida, clique nas opções suspensas para “Papel de serviço para o Amazon EMR” e escolha AWSServiceRoleForSupport. Escolha a mesma opção suspensa para “Papel IAM para perfil de instância”. Atualize o ícone se necessário para obter essas opções suspensas.
Finalmente, clique no botão “Criar cluster” para iniciar o cluster e monitore o status do cluster para validar se ele foi criado.
Instalação e Configuração do Apache Spark no Cluster EMR
Após criar com sucesso um cluster EMR, o próximo passo será configurar o Apache Spark no Cluster EMR. Os clusters EMR fornecem um ambiente gerenciado para executar aplicativos Spark na infraestrutura AWS, facilitando o lançamento e a gestão de clusters Spark na nuvem. Ele configura o Spark para trabalhar com seus dados e necessidades de processamento e, em seguida, envia trabalhos Spark para o cluster para processar seus dados.
Você pode configurar o Apache Spark para o cluster com o protocolo Secure Shell (SSH). Mas primeiro, você precisa autorizar as conexões seguras do SSH para o seu cluster, que foi definido por padrão quando você criou o cluster EMR. Um guia sobre como autorizar conexões SSH pode ser encontrado aqui.
Para criar uma conexão SSH, você precisa especificar o par de chaves EC2 que você selecionou ao criar o cluster. Em seguida, conecte-se ao cluster EMR usando o shell do Spark, primeiro conectando-se ao nó primário. Primeiro, você precisa buscar o DNS público mestre do nó primário navegando para a esquerda do console da AWS, em EMR on EC2, escolha Clusters e, em seguida, selecione o cluster do nome do DNS público que deseja obter.
No terminal do seu sistema operacional, insira o seguinte comando.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemSubstitua o ec2-###-##-##-###.compute-1.amazonaws.com pelo nome do seu DNS público mestre e o ~/mykeypair.pem pelo nome do arquivo e caminho do seu arquivo .pem (Siga este guia para obter o arquivo .pem ). Uma mensagem de prompt aparecerá à qual sua resposta deve ser sim — digite exit para fechar o comando SSH.
Preparando Dados para Processamento com Spark e Enviando para o Bucket S3
O processamento de dados requer preparação antes de ser enviado para apresentar os dados em um formato que o Spark possa processar facilmente. O formato utilizado é influenciado pelo tipo de dados que você possui e pela análise que pretende realizar. Alguns formatos utilizados incluem CSV, JSON e Parquet.
Crie uma nova sessão do Spark e carregue seus dados no Spark usando a API relevante. Por exemplo, use o método spark.read.csv() para ler arquivos CSV em um DataFrame do Spark.
O Amazon EMR, um serviço gerenciado para clusters do ecossistema Hadoop, pode ser usado para processar dados. Reduz a necessidade de configurar, ajustar e manter clusters. Também apresenta outras integrações com Amazon SageMaker, por exemplo, para iniciar um trabalho de treinamento de modelo do SageMaker a partir de um pipeline do Spark no Amazon EMR.
Uma vez que seus dados estejam prontos, usando o método DataFrame.write.format("s3"), você pode ler um arquivo CSV do bucket Amazon S3 em um DataFrame do Spark. Você deve ter configurado suas credenciais da AWS e ter permissões de escrita para acessar o bucket S3.
Indique o bucket e o caminho do S3 onde deseja salvar os dados. Por exemplo, você pode usar o método df.write.format("s3").save("s3://meu-bucket/caminho/para/dados") para salvar os dados no bucket S3 especificado.
Uma vez que os dados sejam salvos no bucket S3, você pode acessá-los a partir de outras aplicações do Spark ou ferramentas, ou pode baixá-los para análise ou processamentos adicionais. Para fazer o upload do bucket, crie uma pasta e escolha o bucket que inicialmente criou. Selecione o botão Ações e clique em “Criar Pasta” nos itens suspensos. Agora você pode nomear a nova pasta.
Para fazer o upload dos arquivos de dados para o bucket, selecione o nome da pasta de dados.
Na seção de Upload — Escolha o “Assistente de Arquivos” e selecione Adicionar Arquivos.
Siga as instruções no console da Amazon S3 para fazer o upload dos arquivos e selecione “Iniciar Upload”.
É importante considerar e garantir as melhores práticas para proteger seus dados antes de fazer o upload para o bucket S3.
Compreendendo Formatos e Esquemas de Dados
Formatos e esquemas de dados são dois conceitos relacionados, mas completamente diferentes e importantes na gestão de dados. O formato de dados refere-se à organização e estrutura dos dados dentro do banco de dados. Existem vários formatos para armazenar dados, como CSV, JSON, XML, YAML, etc. Esses formatos definem como os dados devem ser estruturados juntamente com os diferentes tipos de dados e aplicativos aplicáveis a eles. Por outro lado, os esquemas de dados são a própria estrutura do banco de dados. Define o layout do banco de dados e garante que os dados sejam armazenados adequadamente. Um esquema de banco de dados especifica as visualizações, tabelas, índices, tipos e outros elementos. Esses conceitos são importantes em análises e na visualização do banco de dados.
Limpeza e Pré-processamento de Dados no S3
É essencial verificar se há erros nos seus dados antes de processá-los. Para começar, acesse a pasta de dados em que você salvou o arquivo de dados no seu bucket S3 e baixe-o para sua máquina local. Em seguida, você carregará os dados no ferramenta de processamento de dados, que será usada para limpar e pré-processar os dados. Para este tutorial, a ferramenta de pré-processamento utilizada é o Amazon Athena, que ajuda a analisar dados não estruturados e estruturados armazenados no Amazon S3.
Vá para o Amazon Athena no AWS Console.
Clique em “Create” para criar uma nova tabela e depois em “CREATE TABLE”.
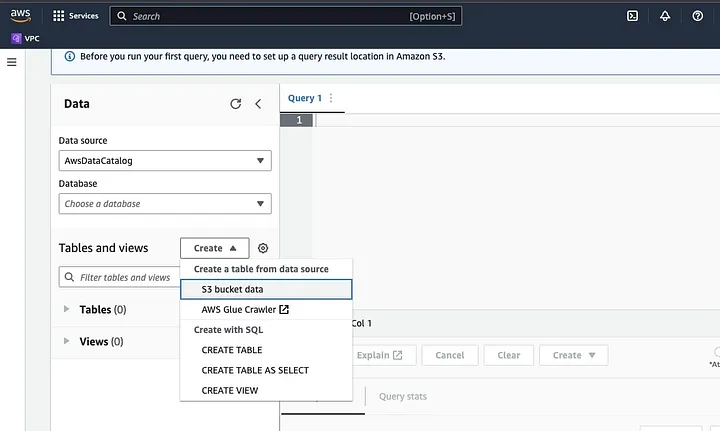
Digite o caminho do seu arquivo de dados no trecho destacado como LOCALIZAÇÃO.
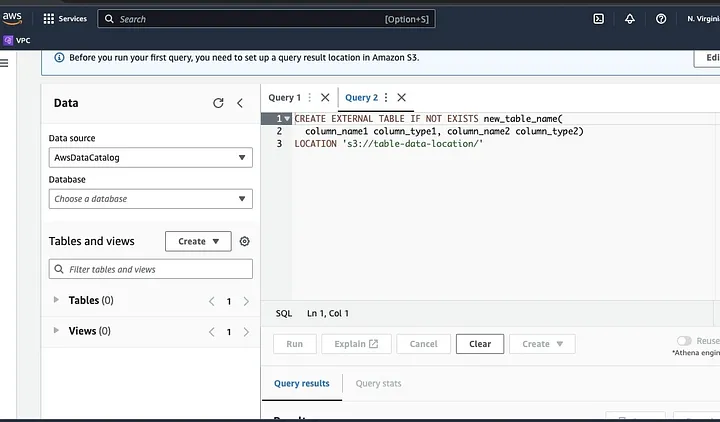
Siga as instruções para definir o esquema para os dados e salve a tabela. Agora, você pode executar uma consulta para validar se os dados foram carregados corretamente e, em seguida, limpar e pré-processar os dados
Um exemplo:
Esta consulta identifica as duplicatas presentes nos dados.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;Este exemplo cria uma nova tabela sem as duplicatas:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;Por fim, exporte os dados limpos de volta para o S3 navegando até o bucket do S3 e a pasta para fazer o upload do arquivo.
Entendendo o Framework Spark
O framework Spark é uma plataforma de computação em cluster de código aberto, simples e expressiva que foi criada para desenvolvimento rápido. Baseia-se na linguagem de programação Java e serve como uma alternativa a outros frameworks Java. A característica central do Spark é sua capacidade de computação em memória, que acelera o processamento de grandes conjuntos de dados.
Configurando o Spark Para Trabalhar Com o S3
Para configurar o Spark para trabalhar com o S3, comece adicionando a dependência Hadoop AWS à sua aplicação Spark. Faça isso adicionando a seguinte linha ao seu arquivo de compilação (por exemplo, build.sbt para Scala ou pom.xml para Java):
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"Insira a chave de acesso AWS e a chave de acesso secreta em sua aplicação Spark, definindo as seguintes propriedades de configuração:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>Defina as seguintes propriedades usando o objeto SparkConf em seu código:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")Defina a URL do endpoint S3 em seu aplicativo Spark definindo a seguinte propriedade de configuração:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.comSubstitua <REGION> pela região da AWS onde está localizado seu bucket S3 (por exemplo, us-east-1).
É necessário um nome de bucket compatível com DNS para conceder ao cliente S3 no Hadoop acesso aos pedidos S3. Se o nome do seu bucket contiver pontos ou underscores, você pode precisar habilitar o acesso em estilo de caminho para o cliente S3 no Hadoop, que utiliza um estilo de host virtual. Defina a seguinte propriedade de configuração para habilitar o acesso em estilo de caminho:
spark.hadoop.fs.s3a.path.style.access truePor fim, crie uma sessão Spark com a configuração S3 definindo o prefixo spark.hadoop na configuração Spark:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()Substitua os campos de <ACCESS_KEY_ID>, <SECRET_ACCESS_KEY> e <REGION> com suas credenciais da AWS e a região do S3.
Para ler os dados do S3 no Spark, o método spark.read será utilizado, especificando o caminho S3 para seus dados como fonte de entrada.
Um exemplo de código demonstrando como ler um arquivo CSV do S3 em um DataFrame no Spark:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")Neste exemplo, substitua <BUCKET_NAME> pelo nome do seu bucket S3 e <FILE_PATH> pelo caminho para o seu arquivo CSV dentro do bucket.
Transformando Dados com Spark
Transformar dados com Spark geralmente se refere a operações em dados para limpar, filtrar, agregar e mesclar dados. O Spark disponibiliza um conjunto rico de APIs para transformação de dados. Eles incluem APIs de DataFrame, Dataset e RDD. Algumas das operações comuns de transformação de dados no Spark incluem filtragem, seleção de colunas, agregação de dados, junção de dados e ordenação de dados.
Aqui está um exemplo de operações de transformação de dados:
Ordenação de dados: Esta operação envolve ordenar dados com base em uma ou mais colunas. O método orderBy ou sort em um DataFrame ou Dataset é usado para ordenar dados com base em uma ou mais colunas. Por exemplo:
val sortedData = df.orderBy(col("age").desc)Por fim, você pode precisar escrever o resultado de volta para o S3 para armazenar os resultados.
O Spark fornece várias APIs para gravar dados no S3, como DataFrameWriter, DatasetWriter e RDD.saveAsTextFile.
O seguinte é um exemplo de código demonstrando como escrever um DataFrame no S3 no formato Parquet:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)Substitua o campo de entrada do <BUCKET_NAME> pelo nome do seu bucket S3 e <OUTPUT_DIRECTORY> pelo caminho para o diretório de saída no bucket.
O método mode especifica o modo de escrita, que pode ser Overwrite, Append, Ignore ou ErrorIfExists. O método option pode ser usado para especificar várias opções para o formato de saída, como codec de compressão.
Você também pode escrever dados no S3 em outros formatos, como CSV, JSON e Avro, alterando o formato de saída e especificando as opções apropriadas.
Compreendendo a Particionamento de Dados no Spark
Em termos simples, o particionamento de dados no Spark refere-se à divisão do conjunto de dados em partes menores e mais gerenciáveis em todo o cluster. O objetivo disso é otimizar o desempenho, reduzir a escalabilidade e, em última análise, melhorar a capacidade de gerenciamento do banco de dados. No Spark, os dados são processados em paralelo em vários clusters. Isso é possível graças aos Datasets Distribuídos Resilientes (RDD), que são uma coleção de dados grandes e complexos. Por padrão, o RDD é particionado em vários nós devido ao seu tamanho.
Para funcionar de forma ideal, existem maneiras de configurar o Spark para garantir que os trabalhos sejam executados de forma rápida e que os recursos sejam gerenciados de forma eficaz. Alguns desses métodos incluem caching, gerenciamento de memória, serialização de dados e o uso de mapPartitions() em vez de map().
A Interface do Usuário do Spark (Spark UI) é uma interface gráfica baseada na web que fornece informações abrangentes sobre o desempenho e o uso de recursos de um aplicativo Spark. Inclui várias páginas, como Visão Geral, Executores, Fases e Tarefas, que fornecem informações sobre vários aspectos de um trabalho Spark. A Spark UI é uma ferramenta essencial para monitorar e depurar aplicativos Spark, pois ajuda a identificar gargalos de desempenho e restrições de recursos e a solucionar erros. Examinando métricas como o número de tarefas concluídas, a duração do trabalho, o uso de CPU e memória, e os dados de shuffle escritos e lidos, os usuários podem otimizar seus trabalhos Spark e garantir que sejam executados de forma eficiente.
Conclusão
Em resumo, processar seus dados no AWS S3 usando o Apache Spark é uma maneira eficaz e escalável de analisar grandes conjuntos de dados. Ao utilizar os recursos de armazenamento e computação baseados em nuvem do AWS S3 e do Apache Spark, os usuários podem processar seus dados rapidamente e de forma eficaz, sem se preocupar com a gestão da arquitetura.
Neste tutorial, percorremos a criação de um bucket S3 e de um cluster Apache Spark no AWS EMR, configurando o Spark para trabalhar com o AWS S3 e escrevendo e executando aplicativos Spark para processar dados. Também abordamos a partição de dados no Spark, a IU do Spark e a otimização do desempenho no Spark.
Referência
Para mais detalhes sobre a configuração do Spark para um desempenho otimizado, consulte aqui.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark