













Introdução
O modelo de dados relacional, que organiza dados em tabelas de linhas e colunas, predomina nas ferramentas de gerenciamento de banco de dados. Hoje existem outros modelos de dados, incluindo NoSQL e NewSQL, mas os sistemas de gerenciamento de banco de dados relacionais (RDBMSs) permanecem dominantes para armazenar e gerenciar dados em todo o mundo.
Este artigo compara e contrasta três dos RDBMSs de código aberto mais amplamente implementados: SQLite, MySQL e PostgreSQL. Especificamente, explorará os tipos de dados que cada RDBMS usa, suas vantagens e desvantagens, e situações onde são melhor otimizados.
A Bit About Database Management Systems
Bancos de dados são agrupamentos logicamente modelados de informações, ou dados. Um sistema de gerenciamento de banco de dados (DBMS), por outro lado, é um programa de computador que interage com um banco de dados. Um DBMS permite controlar o acesso a um banco de dados, escrever dados, executar consultas e realizar quaisquer outras tarefas relacionadas ao gerenciamento de banco de dados.
Embora os sistemas de gerenciamento de banco de dados sejam frequentemente referidos como “bancos de dados”, os dois termos não são intercambiáveis. Um banco de dados pode ser qualquer coleção de dados, não apenas aquele armazenado em um computador. Em contraste, um SGDB refere-se especificamente ao software que permite interagir com um banco de dados.
Todos os sistemas de gerenciamento de banco de dados têm um modelo subjacente que estrutura como os dados são armazenados e acessados. Um sistema de gerenciamento de banco de dados relacional é um SGDB que emprega o modelo de dados relacional. Neste modelo relacional, os dados são organizados em tabelas. Tabelas, no contexto de SGDBs, são formalmente referidas como relações. Uma relação é um conjunto de tuplas, que são as linhas em uma tabela, e cada tupla compartilha um conjunto de atributos, que são as colunas em uma tabela:
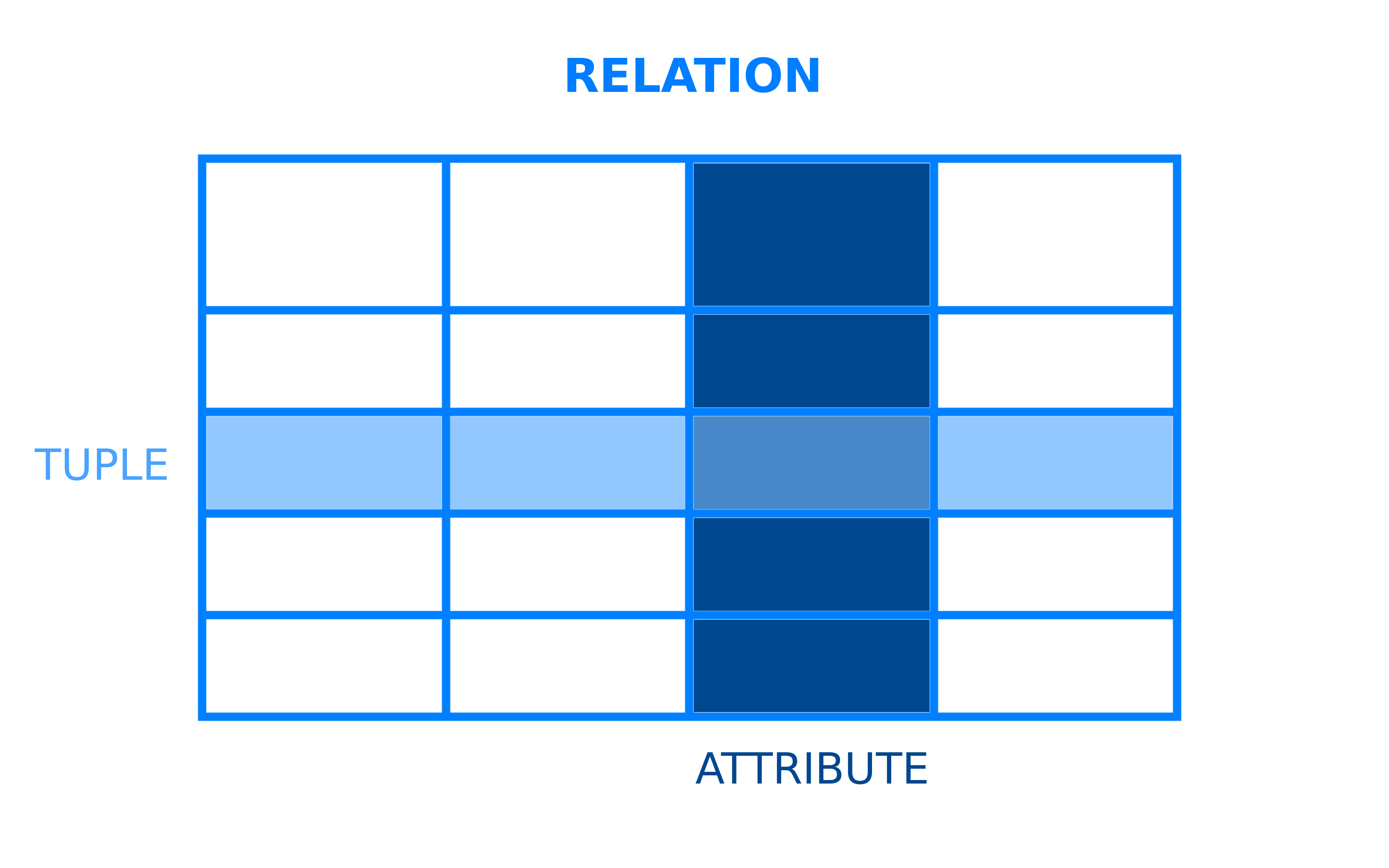
A maioria dos bancos de dados relacionais usa linguagem de consulta estruturada (SQL) para gerenciar e consultar dados. No entanto, muitos SGDBs usam seu próprio dialeto específico de SQL, que pode ter certas limitações ou extensões. Essas extensões geralmente incluem recursos adicionais que permitem aos usuários realizar operações mais complexas do que poderiam fazer com o SQL padrão.
Observação: O termo “SQL padrão” aparece várias vezes ao longo deste guia. Os padrões SQL são mantidos em conjunto pelo Instituto Nacional de Padrões Americano (ANSI), pela Organização Internacional de Normalização (ISO), e pela Comissão Eletrotécnica Internacional (IEC). Sempre que este artigo menciona “SQL padrão” ou “o padrão SQL”, está se referindo à versão atual do padrão SQL publicada por esses órgãos.
É importante notar que o padrão SQL completo é grande e complexo: a conformidade total com o núcleo do SQL:2011 requer 179 recursos. Devido a isso, a maioria dos SGBDRs não suporta o padrão inteiro, embora alguns se aproximem mais da conformidade total do que outros.
Tipos de Dados e Restrições
Cada coluna é atribuída a um tipo de dados que dita que tipo de entradas são permitidas nessa coluna. Diferentes SGBDRs implementam tipos de dados diferentes, que nem sempre são diretamente intercambiáveis. Alguns tipos de dados comuns incluem datas, strings, inteiros e booleanos.
Armazenar inteiros em um banco de dados é mais sutil do que colocar números em uma tabela. Tipos de dados numéricos podem ser assinados, o que significa que podem representar números positivos e negativos, ou não assinados, o que significa que só podem representar números positivos. Por exemplo, o tipo de dados tinyint do MySQL pode armazenar 8 bits de dados, o que equivale a 256 valores possíveis. A faixa assinada deste tipo de dados é de -128 a 127, enquanto a faixa não assinada é de 0 a 255.
Poder controlar quais dados são permitidos em um banco de dados é importante. Às vezes, um administrador de banco de dados irá impor uma restrição em uma tabela para limitar quais valores podem ser inseridos nela. Uma restrição normalmente se aplica a uma coluna específica, mas algumas restrições também podem se aplicar a uma tabela inteira. Aqui estão algumas restrições comumente usadas no SQL:
ÚNICO: Aplicar essa restrição a uma coluna garante que não haja duas entradas idênticas nessa coluna.NÃO NULO: Essa restrição garante que uma coluna não tenha nenhuma entradaNULA.CHAVE PRIMÁRIA: Uma combinação deÚNICOeNÃO NULO, a restrição deCHAVE PRIMÁRIAgarante que nenhuma entrada na coluna sejaNULAe que cada entrada seja distinta.CHAVE ESTRANGEIRA: UmaCHAVE ESTRANGEIRAé uma coluna em uma tabela que se refere àCHAVE PRIMÁRIAde outra tabela. Essa restrição é usada para vincular duas tabelas. As entradas na coluna deCHAVE ESTRANGEIRAdevem existir previamente na coluna deCHAVE PRIMÁRIApai para que o processo de gravação tenha sucesso.CHECAR: Essa restrição limita o intervalo de valores que podem ser inseridos em uma coluna. Por exemplo, se sua aplicação for destinada apenas a residentes do Alasca, você poderia adicionar uma restrição deCHECARem uma coluna de código postal para permitir apenas entradas entre 99501 e 99950.
Se você gostaria de aprender mais sobre sistemas de gerenciamento de banco de dados, confira nosso artigo sobre Uma Comparação de Sistemas e Modelos de Gerenciamento de Banco de Dados NoSQL.
Agora que cobrimos os sistemas de gerenciamento de banco de dados relacionais de forma geral, vamos avançar para o primeiro dos três bancos de dados relacionais de código aberto que este artigo abordará: SQLite.
SQLite
O SQLite é um sistema de gerenciamento de banco de dados relacional (RDBMS) autocontido, baseado em arquivos e totalmente de código aberto, conhecido por sua portabilidade, confiabilidade e alto desempenho mesmo em ambientes com pouca memória. Suas transações são compatíveis com ACID, mesmo em casos em que o sistema trava ou sofre uma queda de energia.
O site do projeto SQLite o descreve como um banco de dados “sem servidor”. A maioria dos motores de banco de dados relacionais são implementados como um processo de servidor no qual os programas se comunicam com o servidor hospedeiro por meio de uma comunicação entre processos que transmite solicitações. Em contraste, o SQLite permite que qualquer processo que acesse o banco de dados leia e escreva no arquivo de disco do banco de dados diretamente. Isso simplifica o processo de configuração do SQLite, pois elimina a necessidade de configurar um processo de servidor. Da mesma forma, não é necessária nenhuma configuração para os programas que usarão o banco de dados SQLite: tudo o que eles precisam é de acesso ao disco.
O SQLite é um software livre e de código aberto, e não é necessário nenhum licenciamento especial para usá-lo. No entanto, o projeto oferece várias extensões — cada uma por uma taxa única — que ajudam com compressão e criptografia. Além disso, o projeto oferece diversos pacotes de suporte comercial, cada um por uma taxa anual.
Tipos de Dados Suportados pelo SQLite
O SQLite permite uma variedade de tipos de dados, organizados nas seguintes classes de armazenamento:
| Data Type | Explanation |
|---|---|
null |
Includes any NULL values. |
integer |
Signed integers, stored in 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. |
real |
Real numbers, or floating point values, stored as 8-byte floating point numbers. |
text |
Text strings stored using the database encoding, which can either be UTF-8, UTF-16BE or UTF-16LE. |
blob |
Any blob of data, with every blob stored exactly as it was input. |
No contexto do SQLite, os termos “classe de armazenamento” e “tipo de dados” são considerados intercambiáveis. Se você deseja saber mais sobre os tipos de dados do SQLite e a afinidade de tipos do SQLite, confira a documentação oficial sobre o assunto.
Vantagens do SQLite
- Pequena Pegada: Como o próprio nome sugere, a biblioteca SQLite é muito leve. Embora o espaço que ela ocupa varie dependendo do sistema onde está instalada, pode ocupar menos de 600KiB de espaço. Além disso, é totalmente autocontida, o que significa que não há dependências externas que você precise instalar no seu sistema para o SQLite funcionar.
- Amigável ao usuário: O SQLite é às vezes descrito como um banco de dados “de configuração zero” que está pronto para uso assim que é instalado. O SQLite não funciona como um processo de servidor, o que significa que nunca precisa ser parado, iniciado ou reiniciado e não possui arquivos de configuração que precisam ser gerenciados. Esses recursos ajudam a simplificar o processo, desde a instalação do SQLite até a integração com uma aplicação.
- Portátil: Ao contrário de outros sistemas de gerenciamento de banco de dados, que normalmente armazenam dados como um grande lote de arquivos separados, um banco de dados SQLite inteiro é armazenado em um único arquivo. Este arquivo pode estar localizado em qualquer lugar em uma hierarquia de diretórios e pode ser compartilhado via mídia removível ou protocolo de transferência de arquivos.
Desvantagens do SQLite
- Concorrência limitada: Embora vários processos possam acessar e consultar um banco de dados SQLite ao mesmo tempo, apenas um processo pode fazer alterações no banco de dados em um determinado momento. Isso significa que, enquanto o SQLite suporta uma maior concorrência do que a maioria dos outros sistemas de gerenciamento de banco de dados embutidos, ele não pode suportar tanto quanto RDBMSs cliente/servidor como MySQL ou PostgreSQL.
- Sem gerenciamento de usuários: Sistemas de banco de dados frequentemente vêm com suporte para usuários, ou conexões gerenciadas com privilégios de acesso predefinidos ao banco de dados e tabelas. Como o SQLite lê e escreve diretamente em um arquivo de disco comum, as únicas permissões de acesso aplicáveis são as permissões de acesso típicas do sistema operacional subjacente. Isso torna o SQLite uma escolha ruim para aplicativos que requerem múltiplos usuários com permissões de acesso especiais.
- Segurança: Um mecanismo de banco de dados que usa um servidor pode, em alguns casos, fornecer uma proteção melhor contra bugs na aplicação cliente do que um banco de dados sem servidor como o SQLite. Por exemplo, ponteiros perdidos em um cliente não podem corromper a memória no servidor. Além disso, como um servidor é um único processo persistente, um banco de dados cliente-servidor pode controlar o acesso aos dados com mais precisão do que um banco de dados sem servidor. Isso permite um bloqueio mais refinado e melhor concorrência.
Quando usar o SQLite
- Aplicações embarcadas: O SQLite é uma ótima escolha de banco de dados para aplicativos que precisam de portabilidade e não requerem expansão futura. Exemplos incluem aplicativos locais de usuário único, aplicativos móveis ou jogos.
- Substituição de acesso a disco: Em casos em que uma aplicação precisa ler e escrever arquivos diretamente no disco, pode ser benéfico usar o SQLite pela funcionalidade adicional e simplicidade que vem com o uso do SQL.
- Testando: Para muitas aplicações, pode ser exagerado testar sua funcionalidade com um SGBD que utiliza um processo de servidor adicional. O SQLite possui um modo em memória que pode ser utilizado para executar testes rapidamente sem o overhead de operações de banco de dados reais, tornando-o uma escolha ideal para testes.
Quando Não Usar o SQLite
- Trabalhando com muitos dados: O SQLite pode tecnicamente suportar um banco de dados com até 140TB de tamanho, contanto que o disco rígido e o sistema de arquivos também suportem os requisitos de tamanho do banco de dados. No entanto, o site do SQLite recomenda que qualquer banco de dados que esteja se aproximando de 1TB seja hospedado em um banco de dados cliente-servidor centralizado, pois um banco de dados SQLite desse tamanho ou maior seria difícil de gerenciar.
- Volumes de escrita elevados: O SQLite permite apenas uma operação de escrita ocorrer de cada vez, o que limita significativamente seu throughput. Se sua aplicação requer muitas operações de escrita ou múltiplos escritores concorrentes, o SQLite pode não ser adequado para suas necessidades.
- O acesso à rede é necessário: Como o SQLite é um banco de dados sem servidor, ele não fornece acesso direto à rede para seus dados. Esse acesso é integrado à aplicação. Se os dados no SQLite estiverem localizados em uma máquina separada da aplicação, será necessário um link de alto desempenho entre o mecanismo e o disco através da rede. Esta é uma solução cara e ineficiente, e em tais casos um SGBD cliente-servidor pode ser uma escolha melhor.
MySQL
De acordo com o Ranking do DB-Engines, o MySQL tem sido o SGBD relacional de código aberto mais popular desde que o site começou a rastrear a popularidade de bancos de dados em 2012. É um produto rico em recursos que alimenta muitos dos maiores sites e aplicativos do mundo, incluindo Twitter, Facebook, Netflix e Spotify. Começar com o MySQL é relativamente simples, em grande parte graças à sua documentação abrangente e grande comunidade de desenvolvedores, além da abundância de recursos relacionados ao MySQL online.
O MySQL foi projetado para velocidade e confiabilidade, em detrimento da conformidade total com o SQL padrão. Os desenvolvedores do MySQL trabalham continuamente para uma conformidade mais próxima com o SQL padrão, mas ainda está atrás de outras implementações de SQL. No entanto, ele vem com vários modos e extensões SQL que o aproximam da conformidade.
Ao contrário de aplicativos que utilizam SQLite, aplicativos que utilizam um banco de dados MySQL acessam-no através de um processo daemon separado. Como o processo do servidor fica entre o banco de dados e outros aplicativos, isso permite um maior controle sobre quem tem acesso ao banco de dados.
O MySQL inspirou uma variedade de aplicativos de terceiros, ferramentas e bibliotecas integradas que ampliam sua funcionalidade e ajudam a tornar o trabalho com ele mais fácil. Algumas das ferramentas de terceiros mais amplamente utilizadas são phpMyAdmin, DBeaver e HeidiSQL.
Tipos de Dados Suportados pelo MySQL
Os tipos de dados do MySQL podem ser organizados em três categorias principais: tipos numéricos, tipos de data e hora, e tipos de string.
Tipos numéricos:
| Data Type | Explanation |
|---|---|
tinyint |
A very small integer. The signed range for this numeric data type is -128 to 127, while the unsigned range is 0 to 255. |
smallint |
A small integer. The signed range for this numeric type is -32768 to 32767, while the unsigned range is 0 to 65535. |
mediumint |
A medium-sized integer. The signed range for this numeric data type is -8388608 to 8388607, while the unsigned range is 0 to 16777215. |
int or integer |
A normal-sized integer. The signed range for this numeric data type is -2147483648 to 2147483647, while the unsigned range is 0 to 4294967295. |
bigint |
A large integer. The signed range for this numeric data type is -9223372036854775808 to 9223372036854775807, while the unsigned range is 0 to 18446744073709551615. |
float |
A small (single-precision) floating-point number. |
double, double precision, or real |
A normal sized (double-precision) floating-point number. |
dec, decimal, fixed, or numeric |
A packed fixed-point number. The display length of entries for this data type is defined when the column is created, and every entry adheres to that length. |
bool or boolean |
A Boolean is a data type that only has two possible values, usually either true or false. |
bit |
A bit value type for which you can specify the number of bits per value, from 1 to 64. |
Tipos de data e hora:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
Tipos de string:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; entries of this type are padded on the right with spaces to meet the specified length when stored. |
varchar |
A string of variable length. |
binary |
Similar to the char type, but a binary byte string of a specified length rather than a nonbinary character string. |
varbinary |
Similar to the varchar type, but a binary byte string of a variable length rather than a nonbinary character string. |
blob |
A binary string with a maximum length of 65535 (2^16 – 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 – 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 – 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 – 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 – 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 – 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 – 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 – 1) characters. |
enum |
An enumeration, which is a string object that takes a single value from a list of values that are declared when the table is created. |
set |
Similar to an enumeration, a string object that can have zero or more values, each of which must be chosen from a list of allowed values that are specified when the table is created. |
Vantagens do MySQL
- Popularidade e facilidade de uso: Como um dos sistemas de banco de dados mais populares do mundo, não há escassez de administradores de banco de dados que tenham experiência em trabalhar com o MySQL. Da mesma forma, há uma abundância de documentação impressa e online sobre como instalar e gerenciar um banco de dados MySQL. Isso inclui uma série de ferramentas de terceiros — como o phpMyAdmin — que visam simplificar o processo de começar com o banco de dados.
- Segurança: O MySQL vem instalado com um script que ajuda a melhorar a segurança do seu banco de dados, definindo o nível de segurança da senha da instalação, definindo uma senha para o usuário root, removendo contas anônimas e removendo bancos de dados de teste que, por padrão, são acessíveis a todos os usuários. Além disso, ao contrário do SQLite, o MySQL oferece suporte à gerência de usuários e permite conceder privilégios de acesso de forma específica para cada usuário.
- Velocidade: Ao optar por não implementar certas funcionalidades do SQL, os desenvolvedores do MySQL puderam priorizar a velocidade. Embora testes de benchmark mais recentes mostrem que outros SGBDs como o PostgreSQL podem igualar ou pelo menos se aproximar do MySQL em termos de velocidade, o MySQL ainda mantém uma reputação como uma solução de banco de dados excepcionalmente rápida.
- Replicação: O MySQL suporta diversos tipos de replicação, que é a prática de compartilhar informações entre dois ou mais hosts para ajudar a melhorar a confiabilidade, disponibilidade e tolerância a falhas. Isso é útil para configurar uma solução de backup de banco de dados ou escalonamento horizontal do banco de dados.
Desvantagens do MySQL
- Limitações conhecidas: Como o MySQL foi projetado para velocidade e facilidade de uso, em vez de conformidade total com SQL, ele possui certas limitações funcionais. Por exemplo, ele falta de suporte para cláusulas
FULL JOIN. - Licenciamento e recursos proprietários: O MySQL é um software com licença dupla, com uma edição comunitária gratuita e de código aberto licenciada sob GPLv2 e várias edições comerciais pagas lançadas sob licenças proprietárias. Devido a isso, alguns recursos e plugins estão disponíveis apenas para as edições proprietárias.
- Desenvolvimento desacelerado: Desde que o projeto MySQL foi adquirido pela Sun Microsystems em 2008 e posteriormente pela Oracle Corporation em 2009, houve reclamações dos usuários de que o processo de desenvolvimento do SGBD desacelerou significativamente, pois a comunidade não tem mais a capacidade de reagir rapidamente a problemas e implementar mudanças.
Quando Usar o MySQL
- Operações distribuídas: O suporte de replicação do MySQL o torna uma ótima escolha para configurações de banco de dados distribuídos como arquiteturas primário-secundário ou primário-primário.
- Websites e aplicações web: O MySQL alimenta muitos websites e aplicações na internet. Isso se deve, em grande parte, à facilidade de instalação e configuração de um banco de dados MySQL, bem como sua velocidade e escalabilidade no longo prazo.
- Crescimento futuro esperado: O suporte de replicação do MySQL pode ajudar a facilitar a escalabilidade horizontal. Além disso, é um processo relativamente simples atualizar para um produto MySQL comercial, como o MySQL Cluster, que suporta shard automático, outro processo de escalabilidade horizontal.
Quando não usar o MySQL
- Conformidade com SQL é necessária: Como o MySQL não tenta implementar o padrão SQL completo, esta ferramenta não é totalmente compatível com SQL. Se a conformidade completa ou mesmo quase completa com SQL é essencial para o seu caso de uso, você pode querer usar um SGBD mais completamente compatível.
- Concorrência e grandes volumes de dados: Embora o MySQL geralmente tenha um bom desempenho com operações de leitura intensiva, operações de leitura-gravação simultâneas podem ser problemáticas. Se sua aplicação tiver muitos usuários gravando dados nela ao mesmo tempo, outro SGBD como o PostgreSQL pode ser uma escolha melhor de banco de dados.
PostgreSQL
O PostgreSQL, também conhecido como Postgres, se autodenomina “o banco de dados relacional de código aberto mais avançado do mundo”. Foi criado com o objetivo de ser altamente extensível e compatível com padrões. O PostgreSQL é um banco de dados objeto-relacional, o que significa que, embora seja principalmente um banco de dados relacional, também inclui recursos – como herança de tabela e sobrecarga de função – que são mais frequentemente associados a bancos de dados de objeto.
O PostgreSQL é capaz de lidar eficientemente com múltiplas tarefas ao mesmo tempo, uma característica conhecida como concorrência. Ele alcança isso sem travamentos de leitura graças à sua implementação do Controle de Concorrência de Múltiplas Versões (MVCC), que garante a atomicidade, consistência, isolamento e durabilidade de suas transações, também conhecido como conformidade ACID.
O PostgreSQL não é tão amplamente utilizado quanto o MySQL, mas ainda existem várias ferramentas e bibliotecas de terceiros projetadas para simplificar o trabalho com o PostgreSQL, incluindo pgAdmin e Postbird.
Tipos de Dados Suportados pelo PostgreSQL
O PostgreSQL suporta tipos de dados numéricos, de string, de data e hora, assim como o MySQL. Além disso, ele suporta tipos de dados para formas geométricas, endereços de rede, cadeias de bits, pesquisas de texto e entradas JSON, assim como diversos tipos de dados idiossincráticos.
Tipos Numéricos:
| Data Type | Explanation |
|---|---|
bigint |
A signed 8 byte integer. |
bigserial |
An auto-incrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
A number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An auto-incrementing 2 byte integer. |
serial |
An auto-incrementing 4 byte integer. |
Tipos de Caracteres:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
Tipos de Data e Hora:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
Tipos Geométricos:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
Tipos de Endereço de Rede:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
Tipos de Cadeia de Bits:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
Tipos de Pesquisa de Texto:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
Tipos JSON:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
Outros tipos de dados:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for “byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
Vantagens do PostgreSQL
- Conformidade com SQL: Mais do que o SQLite ou o MySQL, o PostgreSQL visa aderir de perto aos padrões do SQL. De acordo com a documentação oficial do PostgreSQL, o PostgreSQL suporta 160 dos 179 recursos necessários para conformidade total com o SQL:2011, além de uma longa lista de recursos opcionais.
- Código aberto e orientado pela comunidade: Um projeto totalmente de código aberto, o código-fonte do PostgreSQL é desenvolvido por uma comunidade grande e dedicada. Da mesma forma, a comunidade do Postgres mantém e contribui para numerosos recursos online que descrevem como trabalhar com o SGBD, incluindo a documentação oficial, o wiki do PostgreSQL, e vários fóruns online.
- Extensível: Os usuários podem estender o PostgreSQL de forma programática e dinâmica através de sua operação orientada por catálogo e seu uso de carregamento dinâmico. Pode-se designar um arquivo de código de objeto, como uma biblioteca compartilhada, e o PostgreSQL o carregará conforme necessário.
Desvantagens do PostgreSQL
- Desempenho de memória: Para cada nova conexão de cliente, o PostgreSQL cria um novo processo. Cada novo processo é alocado cerca de 10MB de memória, o que pode se acumular rapidamente para bancos de dados com muitas conexões. Portanto, para operações simples com muitas leituras, o PostgreSQL geralmente tem um desempenho inferior a outros SGBDs, como o MySQL.
- Popularidade: Embora mais amplamente utilizado nos últimos anos, o PostgreSQL historicamente ficou atrás do MySQL em termos de popularidade. Uma consequência disso é que ainda há menos ferramentas de terceiros que podem ajudar a gerenciar um banco de dados PostgreSQL. Da mesma forma, não há tantos administradores de banco de dados com experiência em gerenciamento de banco de dados do Postgres em comparação com aqueles com experiência em MySQL.
Quando usar PostgreSQL
- A integridade dos dados é importante: O PostgreSQL é totalmente compatível com ACID desde 2001 e implementa controle de concorrência de várias versões para garantir que os dados permaneçam consistentes, tornando-o uma escolha forte de SGBD quando a integridade dos dados é crítica.
- Integração com outras ferramentas: O PostgreSQL é compatível com uma ampla variedade de linguagens de programação e plataformas. Isso significa que, se você precisar migrar seu banco de dados para outro sistema operacional ou integrá-lo com uma ferramenta específica, provavelmente será mais fácil com um banco de dados PostgreSQL do que com outro SGBD.
- Operações complexas: O Postgres suporta planos de consulta que podem aproveitar múltiplas CPUs para responder consultas com maior velocidade. Isso, aliado ao seu forte suporte para múltiplos escritores concorrentes, o torna uma ótima escolha para operações complexas como data warehousing e processamento de transações online.
Quando não usar o PostgreSQL
- A velocidade é imperativa: À custa da velocidade, o PostgreSQL foi projetado com extensibilidade e compatibilidade em mente. Se o seu projeto requer as operações de leitura mais rápidas possíveis, o PostgreSQL pode não ser a melhor escolha de SGBD.
- Configurações simples: Devido ao seu amplo conjunto de recursos e forte aderência ao SQL padrão, o Postgres pode ser exagerado para configurações de banco de dados simples. Para operações com alta carga de leitura onde a velocidade é necessária, o MySQL geralmente é uma escolha mais prática.
- Replicação complexa: Embora o PostgreSQL ofereça um forte suporte para replicação, ainda é uma funcionalidade relativamente nova. Algumas configurações — como uma arquitetura primária-primária — só são possíveis com extensões. A replicação é uma funcionalidade mais madura no MySQL e muitos usuários consideram a replicação do MySQL mais fácil de implementar, especialmente para aqueles que não têm experiência em administração de banco de dados e sistemas.
Conclusão
Hoje, SQLite, MySQL e PostgreSQL são os três sistemas de gerenciamento de banco de dados relacional de código aberto mais populares do mundo. Cada um tem suas próprias características e limitações únicas, e se destaca em cenários específicos. Existem várias variáveis em jogo ao decidir sobre um SGBD, e a escolha raramente é tão simples quanto escolher o mais rápido ou aquele com mais recursos. Da próxima vez que precisar de uma solução de banco de dados relacional, certifique-se de pesquisar essas e outras ferramentas a fundo para encontrar aquela que melhor atenda às suas necessidades.
Se você gostaria de aprender mais sobre SQL e como usá-lo para gerenciar um banco de dados relacional, nós o incentivamos a consultar nosso guia Como Gerenciar um Banco de Dados SQL. Por outro lado, se você gostaria de aprender sobre bancos de dados não relacionais (ou NoSQL), confira nossa Comparação de Sistemas de Gerenciamento de Bancos de Dados NoSQL.