













Hibernate
O Hibernate por si só não possui suporte a pesquisa de texto completo. Ele precisa contar com o suporte do mecanismo de banco de dados ou soluções de terceiros.
Uma extensão chamada Hibernate Search se integra com Apache Lucene ou Elasticsearch (há também integração com o OpenSearch).
Postgres
O Postgres possui funcionalidade de pesquisa de texto completo desde a versão 7.3. Embora não possa competir com mecanismos de pesquisa como o Elasticsearch ou Lucene, ainda oferece uma solução flexível e robusta que pode ser suficiente para atender às expectativas dos usuários de aplicativos—recursos como stemming, classificação e indexação.
Vamos explicar brevemente como podemos fazer uma pesquisa de texto completo no Postgres. Para mais informações, visite a documentação do Postgres. Quanto à correspondência de texto essencial, a parte mais crucial é o operador matemático @@.
Ele retorna true se o documento (objeto do tipo tsvector) corresponder à consulta (objeto do tipo tsquery).
A ordem não é crucial para o operador. Portanto, não importa se colocamos o documento à esquerda do operador e a consulta à direita ou em uma ordem diferente.
Para melhor demonstração, utilizamos uma tabela de banco de dados chamada tweet.
create table tweet (
id bigint not null,
short_content varchar(255),
title varchar(255),
primary key (id)
)Com tais dados:
INSERT INTO tweet (id, title, short_content) VALUES (1, 'Cats', 'Cats rules the world');
INSERT INTO tweet (id, title, short_content) VALUES (2, 'Rats', 'Rats rules in the sewers');
INSERT INTO tweet (id, title, short_content) VALUES (3, 'Rats vs Cats', 'Rats and Cats hates each other');
INSERT INTO tweet (id, title, short_content) VALUES (4, 'Feature', 'This project is design to wrap already existed functions of Postgres');
INSERT INTO tweet (id, title, short_content) VALUES (5, 'Postgres database', 'Postgres is one of the widly used database on the market');
INSERT INTO tweet (id, title, short_content) VALUES (6, 'Database', 'On the market there is a lot of database that have similar features like Oracle');Agora, vejamos como o objeto tsvector se parece para a coluna short_content de cada registro.
SELECT id, to_tsvector('english', short_content) FROM tweet;Saída:
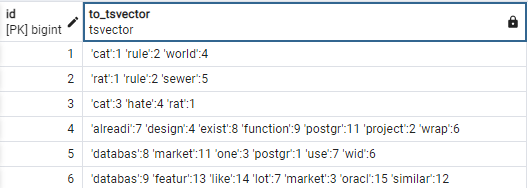
A saída mostra como o to_tsvcector converte a coluna de texto em um objeto tsvector para a configuração de pesquisa de texto ‘english‘.
Configuração de Pesquisa de Texto
O primeiro parâmetro para a função to_tsvector passado no exemplo acima foi o nome da configuração de pesquisa de texto. Nesse caso, foi o “english“. De acordo com a documentação do Postgres, a configuração de pesquisa de texto é a seguinte:
… a funcionalidade de pesquisa de texto completo inclui a capacidade de fazer muito mais: pular a indexação de certas palavras (palavras irrelevantes), processar sinônimos e usar análise sofisticada, por exemplo, analisar com base em mais do que apenas espaços em branco. Essa funcionalidade é controlada por configurações de pesquisa de texto.
Então, a configuração é uma parte crucial do processo e fundamental para os resultados de pesquisa de texto completo. Para configurações diferentes, o motor do Postgres pode retornar resultados diferentes. Isso não precisa ser o caso entre dicionários de diferentes idiomas. Por exemplo, você pode ter duas configurações para a mesma língua, mas uma ignora nomes contendo dígitos (por exemplo, alguns números de série). Se passarmos em nossa consulta o número de série específico que estamos procurando, que é obrigatório, não encontraremos nenhum registro para a configuração que ignora palavras com números. Mesmo que tenhamos tais registros no banco de dados, consulte a documentação de configuração para obter mais informações.
Consulta de Texto
A consulta de texto suporta operadores como & (AND), | (OR), ! (NOT) e <-> (SEGUIDO POR). Os três primeiros operadores não exigem uma explicação mais profunda. O operador <-> verifica se as palavras existem e se estão em uma ordem específica. Então, por exemplo, para a consulta “rat <-> cat“, esperamos que a palavra “cat” exista, seguida pela “rat”.
Exemplos
- Conteúdo que contém o rat e cat:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Rat & cat');
- Conteúdo que contém banco de dados e mercado, e o mercado é a terceira palavra após banco de dados:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database <3> market');
- Conteúdo que contém banco de dados mas não Postgres:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database & !Postgres');
- Conteúdo que contém Postgres ou Oracle:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Postgres | Oracle');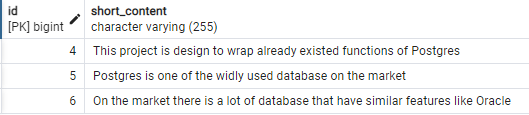
Funções de Wrapper
Uma das funções de wrapper que cria consultas em texto já foi mencionada neste artigo, que é a to_tsquery. Existem mais funções como:
plainto_tsqueryphraseto_tsquerywebsearch_to_tsquery
plainto_tsquery
A plainto_tsquery converte todas as palavras passadas em uma consulta onde todas as palavras são combinadas com o operador & (AND). Por exemplo, o equivalente à plainto_tsquery('english', 'Rat cat') é to_tsquery('english', 'Rat & cat').
Para o seguinte uso:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ plainto_tsquery('english', 'Rat cat');Temos o resultado abaixo:

phraseto_tsquery
A phraseto_tsquery converte todas as palavras passadas em uma consulta onde todas as palavras são combinadas com o operador <-> (FOLLOW BY). Por exemplo, o equivalente à phraseto_tsquery('english', 'cat rule') é to_tsquery('english', 'cat <-> rule').
Para o seguinte uso:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ phraseto_tsquery('english', 'cat rule');Temos o resultado abaixo:

websearch_to_tsquery
A websearch_to_tsquery utiliza uma sintaxe alternativa para criar uma consulta de texto válida.
- Texto sem aspas: Converte parte da sintaxe da mesma maneira que
plainto_tsquery - Texto com aspas: Converte parte da sintaxe da mesma maneira que
phraseto_tsquery - OR: Converte para “
|” (operador OR) - “
-“: Igual a “!” (operador NOT)
Por exemplo, o equivalente ao websearch_to_tsquery('english', '"cat rule" or database -Postgres') é to_tsquery('english', 'cat <-> rule | database & !Postgres').
Para o seguinte uso:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ websearch_to_tsquery('english', '"cat rule" or database -Postgres');Temos o resultado abaixo:

Suporte Nativo para Postgres e Hibernate
Como mencionado no artigo, Hibernate sozinho não possui suporte a pesquisa de texto completo. Ele precisa contar com o suporte do mecanismo do banco de dados. Isso significa que podemos executar consultas SQL nativas como mostrado nos exemplos abaixo:
plainto_tsquery
public List<Tweet> findBySinglePlainQueryInDescriptionForConfigurationWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ plainto_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}websearch_to_tsquery
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescriptionWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ websearch_to_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}Hibernate Com a Biblioteca posjsonhelper
A biblioteca posjsonhelper é um projeto de código aberto que adiciona suporte para consultas Hibernate para funções JSON do PostgreSQL e pesquisa de texto completo.
Para o projeto Maven, precisamos adicionar as dependências abaixo:
<dependency>
<groupId>com.github.starnowski.posjsonhelper.text</groupId>
<artifactId>hibernate6-text</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.0.Final</version>
</dependency>Para usar componentes que existem na biblioteca posjsonhelper, precisamos registrá-los no contexto do Hibernate.
Isso significa que deve haver uma implementação especificada do org.hibernate.boot.model.FunctionContributor. A biblioteca possui uma implementação deste interface, que é com.github.starnowski.posjsonhelper.hibernate6.PosjsonhelperFunctionContributor.
A file with the name “org.hibernate.boot.model.FunctionContributor” under the “resources/META-INF/services” directory is required to use this implementation.
Existe outra maneira de registrar o componente de posjsonhelper, que pode ser feito através da programação. Para ver como fazer isso, verifique este link.
Agora, podemos usar operadores de pesquisa de texto completo em consultas do Hibernate.
PlainToTSQueryFunction
Este é um componente que envolve a função plainto_tsquery.
public List<Tweet> findBySinglePlainQueryInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PlainToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Para uma configuração com o valor 'english', o código gerará a declaração abaixo:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ plainto_tsquery('english', ?);PhraseToTSQueryFunction
Este componente envolve a função phraseto_tsquery.
public List<Tweet> findBySinglePhraseInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PhraseToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Para configuração com o valor 'english', o código gerará a seguinte declaração:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ phraseto_tsquery('english', ?)WebsearchToTSQueryFunction
Este componente envolve a função websearch_to_tsquery.
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescription(String phrase, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new WebsearchToTSQueryFunction((NodeBuilder) cb, configuration, phrase), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Para configuração com o valor 'english', o código gerará a seguinte declaração:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ websearch_to_tsquery('english', ?)Consultas HQL
Todos os componentes mencionados podem ser usados em consultas HQL. Para ver como isso pode ser feito, clique neste link.
Por que usar a biblioteca posjsonhelper quando podemos usar a abordagem nativa com o Hibernate?
Embora concatenar dinamicamente uma string que deveria ser uma consulta HQL ou SQL possa ser fácil, implementar predicados seria uma prática melhor, especialmente quando você precisa lidar com critérios de pesquisa baseados em atributos dinâmicos de sua API.
Conclusão
Como mencionado no artigo anterior, o suporte ao full-text search do Postgres pode ser uma boa alternativa para motores de pesquisa substanciais como o Elasticsearch ou Lucene, em alguns casos. Isso poderia nos poupar da decisão de adicionar soluções de terceiros à nossa pilha tecnológica, o que também poderia adicionar mais complexidade e custos adicionais.
Source:
https://dzone.com/articles/postgres-full-text-search-with-hibernate-6