













O Apache Iceberg tornou-se uma escolha popular para gerenciar grandes conjuntos de dados com flexibilidade e escalabilidade. Os catálogos são centrais para a funcionalidade do Iceberg, o que é vital na organização de tabelas, consistência e gerenciamento de metadados. Este artigo explorará o que são os catálogos do Iceberg, suas várias implementações, casos de uso e configurações, fornecendo uma compreensão das soluções de catálogo mais adequadas para diferentes casos de uso.
O Que É um Catálogo do Iceberg?
No Iceberg, um catálogo é responsável por gerenciar caminhos de tabela, apontando para os arquivos de metadados atuais que representam o estado de uma tabela. Esta arquitetura é essencial porque ela permite atomicidade, consistência e consultas eficientes, garantindo que todos os leitores e escritores acessem o mesmo estado da tabela. Diferentes implementações de catálogo armazenam esses metadados de várias maneiras, desde sistemas de arquivos até serviços de metastore especializados.
Responsabilidades Principais de um Catálogo do Iceberg
As responsabilidades fundamentais de um catálogo do Iceberg são:
- Mapeamento de Caminhos de Tabela: Vincular um caminho de tabela (por exemplo, “db.tabela”) ao arquivo de metadados correspondente.
- Suporte a Operações Atômicas: Garantir o estado consistente da tabela durante leituras/escritas concorrentes.
- Gerenciamento de Metadados: Armazenar e gerenciar os metadados, garantindo acessibilidade e consistência.
Os catálogos Iceberg oferecem várias implementações para acomodar diferentes arquiteturas de sistema e requisitos de armazenamento. Vamos examinar essas implementações e sua adequação para diferentes ambientes.
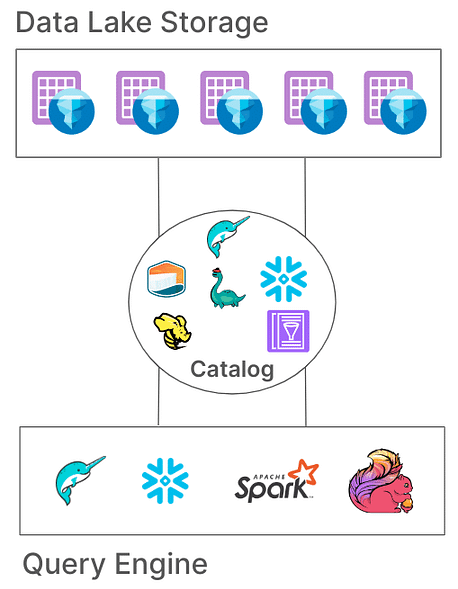
Tipos de Catálogos Iceberg
1. Catálogo Hadoop
O Catálogo Hadoop é tipicamente o mais fácil de configurar, exigindo apenas um sistema de arquivos. Este catálogo gerencia metadados buscando o arquivo de metadados mais recente no diretório de uma tabela com base em carimbos de data/hora dos arquivos. No entanto, devido à sua dependência de operações atômicas a nível de arquivo (que alguns sistemas de armazenamento, como o S3, não possuem), o catálogo Hadoop pode não ser adequado para ambientes de produção onde gravações simultâneas são comuns.
Exemplo de Configuração
Para configurar o catálogo Hadoop com Apache Spark:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:0.14.0 \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.type=hadoop \
--conf spark.sql.catalog.my_catalog.warehouse=file:///D:/sparksetup/iceberg/spark_warehouse
Uma maneira diferente de definir o catálogo no próprio trabalho do Spark:
SparkConf sparkConf = new SparkConf()
.setAppName("Example Spark App")
.setMaster("local[*]")
.set("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.set("spark.sql.catalog.local","org.apache.iceberg.spark.SparkCatalog")
.set("spark.sql.catalog.local.type","hadoop")
.set("spark.sql.catalog.local.warehouse", "file:///D:/sparksetup/iceberg/spark_warehouse")
No exemplo acima, definimos o nome do catálogo como “local”, conforme configurado em spark.sql.catalog.local“. Isso pode ser uma escolha do seu nome.
Prós:
- Configuração simples, sem necessidade de metastore externo.
- Ideal para ambientes de desenvolvimento e teste.
Contras:
- Limitado a sistemas de arquivos únicos (por exemplo, um único bucket S3).
- Não recomendado para produção
2. Catálogo Hive
O Catálogo Hive aproveita o Metastore Hive para gerenciar a localização de metadados, tornando-o compatível com diversas ferramentas de big data. Este catálogo é amplamente utilizado em produção devido à sua integração com a infraestrutura existente baseada em Hive e compatibilidade com múltiplos motores de consulta.
Exemplo de Configuração
Para usar o catálogo Hive no Spark:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:0.14.0 \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.type=hive \
--conf spark.sql.catalog.my_catalog.uri=thrift://<metastore-host>:<port>
Prós:
- Alta compatibilidade com ferramentas de big data existentes.
- Independente de nuvem e flexível em configurações locais e na nuvem.
Contras:
- Requer a manutenção de um metastore Hive, o que pode adicionar complexidade operacional.
- Falta suporte a transações multi-tabela, limitando a atomicidade para operações entre tabelas
3. Catálogo AWS Glue
O Catálogo AWS Glue é um catálogo de metadados gerenciado fornecido pela AWS, tornando-o ideal para organizações fortemente investidas no ecossistema AWS. Ele lida com metadados de tabelas Iceberg como propriedades de tabela dentro do AWS Glue, permitindo uma integração perfeita com outros serviços da AWS.
Exemplo de Configuração
Para configurar o AWS Glue com Iceberg no Spark:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-x.x_x.xx:x.x.x,software.amazon.awssdk:bundle:x.xx.xxx \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog \
--conf spark.sql.catalog.my_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO \
--conf spark.hadoop.fs.s3a.access.key=$AWS_ACCESS_KEY \
--conf spark.hadoop.fs.s3a.secret.key=$AWS_SECRET_ACCESS_KEY
Prós:
- Serviço gerenciado, reduzindo a sobrecarga de infraestrutura e manutenção.
- Forte integração com os serviços da AWS.
Contras:
- Específico da AWS, o que limita a flexibilidade entre nuvens.
- Sem suporte para transações multi-tabela
4. Catálogo Project Nessie
O Projeto Nessie oferece uma abordagem de “dados como código”, permitindo o controle de versão de dados. Com suas capacidades de ramificação e etiquetagem semelhantes ao Git, o Nessie permite que os usuários gerenciem ramificações de dados de uma maneira similar ao código-fonte. Ele fornece uma estrutura robusta para transações multi-tabela e multi-instrução.
Exemplo de Configuração
Para configurar o Nessie como o catálogo:
spark-sql --packages "org.apache.iceberg:iceberg-spark-runtime-x.x_x.xx:x.x.x" \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.catalog-impl=org.apache.iceberg.nessie.NessieCatalog \
--conf spark.sql.catalog.my_catalog.uri=http://<host>:<port>
Prós:
- Fornece funcionalidades de “dados como código” com controle de versão.
- Suporta transações multi-tabela.
Contras:
- Requer auto-hospedagem, adicionando complexidade à infraestrutura.
- Suporte limitado a ferramentas em comparação com Hive ou AWS Glue
5. Catálogo JDBC
O Catálogo JDBC permite que você armazene metadados em qualquer banco de dados compatível com JDBC, como PostgreSQL ou MySQL. Este catálogo é agnóstico em relação à nuvem e garante alta disponibilidade utilizando sistemas RDBMS confiáveis.
Exemplo de Configuração
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-x.x_x.xx:x.x.x \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.catalog-impl=org.apache.iceberg.jdbc.JdbcCatalog \
--conf spark.sql.catalog.my_catalog.uri=jdbc:<protocol>://<host>:<port>/<database> \
--conf spark.sql.catalog.my_catalog.jdbc.user=<username> \
--conf spark.sql.catalog.my_catalog.jdbc.password=<password>
Prós:
- Fácil de configurar com a infraestrutura RDBMS existente.
- Alta disponibilidade e agnóstico em relação à nuvem.
Contras:
- Sem suporte para transações multi-tabela.
- Aumenta as dependências de drivers JDBC para todas as ferramentas de acesso
6. Catálogo Snowflake
O Snowflake oferece suporte robusto para tabelas Apache Iceberg, permitindo que os usuários aproveitem a plataforma Snowflake como o catálogo Iceberg. Essa integração combina o desempenho e a semântica de consulta do Snowflake com a flexibilidade do formato de tabela aberto do Iceberg, possibilitando a gestão eficiente de grandes conjuntos de dados armazenados em armazenamento em nuvem externo. Consulte a documentação do Snowflake para mais configurações no link
Prós:
- Integração Sem Costura: Combina o desempenho e as capacidades de consulta do Snowflake com o formato de tabela aberto do Iceberg, facilitando a gestão eficiente de dados.
- Suporte Completo à Plataforma: Oferece acesso abrangente para leitura e gravação, juntamente com recursos como transações ACID, evolução de esquema e viagem no tempo.
- Manutenção Simplificada: O Snowflake cuida de tarefas de ciclo de vida, como compactação e redução da sobrecarga operacional.
Contras:
- Restrições de Nuvem e Região: O volume externo deve estar no mesmo provedor de nuvem e região que a conta Snowflake, limitando configurações entre nuvens ou regiões.
- Limitação de Formato de Dados: Suporta apenas o formato de arquivo Apache Parquet, que pode não estar alinhado com todas as preferências de formato de dados organizacionais.
- Restrições de Clientes de Terceiros: Impede que clientes de terceiros modifiquem dados em tabelas Iceberg gerenciadas pelo Snowflake, potencialmente impactando fluxos de trabalho que dependem de ferramentas externas.
7. Catálogos Baseados em REST
A Iceberg suporta catálogos baseados em REST para abordar vários desafios associados às implementações tradicionais de catálogos.
Desafios com Catálogos Tradicionais
- Complexidade do Lado do Cliente: Catálogos tradicionais frequentemente exigem configurações e dependências do lado do cliente para cada linguagem (Java, Python, Rust, Go), levando a inconsistências entre diferentes linguagens de programação e mecanismos de processamento. Leia mais sobre isso aqui.
- Restrições de Escalabilidade: Gerenciar metadados e operações de tabela no nível do cliente pode introduzir gargalos, afetando o desempenho e a escalabilidade em ambientes de dados em larga escala.
Benefícios da Adoção do Catálogo REST
- Integração Simplificada do Cliente: Os clientes podem interagir com o catálogo REST usando protocolos HTTP padrão, eliminando a necessidade de configurações ou dependências complexas.
- Escalabilidade: A arquitetura do lado do servidor do catálogo REST permite uma gestão escalável de metadados, acomodando conjuntos de dados em crescimento e padrões de acesso concorrentes.
- Flexibilidade: As organizações podem implementar lógica de catálogo personalizada no lado do servidor, adaptando o catálogo REST para atender a requisitos específicos sem alterar os aplicativos clientes.
Várias implementações do catálogo REST surgiram, cada uma atendendo a necessidades organizacionais específicas:
- Gravitino: Um serviço de catálogo REST Iceberg de código aberto que facilita a integração com Spark e outros motores de processamento, oferecendo uma configuração direta para gerenciar tabelas Iceberg.
- Tabular: Um serviço gerenciado que fornece uma interface de catálogo REST, permitindo que as organizações aproveitem as capacidades do Iceberg sem o ônus de gerenciar a infraestrutura de catálogo. Leia mais em Tabular.
- Apache Polaris: Um catálogo completo de código aberto para Apache Iceberg, implementando a API REST para garantir interoperabilidade multi-motor perfeita em plataformas como Apache Doris, Apache Flink, Apache Spark, StarRocks e Trino. Leia mais em GitHub.
Uma das minhas maneiras favoritas e simples de experimentar o catálogo REST com tabelas Iceberg é usando uma implementação REST Java simples. Por favor, verifique o link do GitHub aqui.
Conclusão
A seleção do catálogo Apache Iceberg apropriado é crucial para otimizar sua estratégia de gerenciamento de dados. Aqui está uma visão geral concisa para orientar sua decisão:
- Catálogo Hadoop: Melhor adequado para ambientes de desenvolvimento e testes devido à sua simplicidade. No entanto, podem surgir problemas de consistência em cenários de produção com gravações simultâneas.
- Catálogo Hive Metastore: Ideal para organizações com infraestrutura Hive existente. Oferece compatibilidade com uma ampla gama de ferramentas de big data e suporta operações de dados complexas. No entanto, manter um serviço Hive Metastore pode adicionar complexidade operacional.
- Catálogo AWS Glue: Ótimo para aqueles fortemente investidos no ecossistema AWS. Fornece integração perfeita com os serviços da AWS e reduz a necessidade de serviços de metadados auto-gerenciados. No entanto, é específico da AWS, o que pode limitar a flexibilidade entre nuvens.
- Catálogo JDBC: Adequado para ambientes que preferem bancos de dados relacionais para armazenamento de metadados, permitindo o uso de qualquer banco de dados compatível com JDBC. Isso oferece flexibilidade e alavanca a infraestrutura existente de RDBMS, mas pode introduzir dependências adicionais e exigir um gerenciamento cuidadoso das conexões de banco de dados.
- Catálogo REST: Ideal para cenários que requerem uma API padronizada para operações de catálogo, melhorando a interoperabilidade entre diversos mecanismos de processamento e idiomas. Desacopla os detalhes de implementação do catálogo dos clientes, mas requer a configuração de um serviço REST para lidar com operações de catálogo, o que pode adicionar complexidade na configuração inicial.
- Catálogo do Projeto Nessie: Este é perfeito para organizações que precisam de controle de versão sobre seus dados, semelhante ao Git. Ele suporta ramificação, marcação e transações multi-tabela. Ele fornece capacidades robustas de gerenciamento de dados, mas requer implantar e gerenciar o serviço Nessie, o que pode adicionar sobrecarga operacional.
Compreender essas opções de catálogo e suas configurações permitirá que você faça escolhas informadas e otimize a configuração do seu data lake ou lakehouse para atender às necessidades específicas da sua organização.
Source:
https://dzone.com/articles/iceberg-catalogs-a-guide-for-data-engineers