













Introdução
Todo sistema de computador se beneficia de uma administração e monitoramento adequados. Ficar de olho em como seu sistema está funcionando ajudará você a descobrir problemas e resolvê-los rapidamente.
Há muitos utilitários de linha de comando criados para esse fim. Este guia irá apresentar a você algumas das aplicações mais úteis para se ter em sua caixa de ferramentas.
Pré-requisitos
Para acompanhar este guia, você precisará de acesso a um computador executando um sistema operacional baseado em Linux. Isso pode ser um servidor virtual privado ao qual você se conectou com SSH ou sua máquina local. Observe que este tutorial foi validado usando um servidor Linux executando o Ubuntu 20.04, mas os exemplos dados devem funcionar em um computador executando qualquer versão de qualquer distribuição Linux.
Se você planeja usar um servidor remoto para seguir este guia, recomendamos que primeiro conclua nosso guia de Configuração Inicial do Servidor. Fazê-lo irá configurá-lo com um ambiente de servidor seguro, incluindo um usuário não-root com privilégios de sudo e um firewall configurado com UFW, que você pode usar para desenvolver suas habilidades em Linux.
Passo 1 – Como Visualizar Processos em Execução no Linux
Você pode ver todos os processos em execução no seu servidor usando o comando top:
Outputtop - 15:14:40 up 46 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 316576k used, 703024k free, 7652k buffers
Swap: 0k total, 0k used, 0k free, 258976k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.03 watchdog/0
8 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
As primeiras linhas de saída fornecem estatísticas do sistema, como carga de CPU/memória e o número total de tarefas em execução.
Você pode ver que há 1 processo em execução e 55 processos que estão considerados como dormindo porque não estão usando ativamente ciclos da CPU.
O restante da saída exibida mostra os processos em execução e suas estatísticas de uso. Por padrão, o top ordena automaticamente esses processos por uso de CPU, então você pode ver os processos mais ocupados primeiro. O top continuará em execução no seu terminal até que você o pare usando a combinação de teclas padrão Ctrl+C para sair de um processo em execução. Isso envia um sinal de kill, instruindo o processo a parar graciosamente, se for capaz.
Uma versão aprimorada do top, chamada htop, está disponível na maioria dos repositórios de pacotes. No Ubuntu 20.04, você pode instalá-lo com apt:
Depois disso, o comando htop estará disponível:
Output Mem[||||||||||| 49/995MB] Load average: 0.00 0.03 0.05
CPU[ 0.0%] Tasks: 21, 3 thr; 1 running
Swp[ 0/0MB] Uptime: 00:58:11
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
1259 root 20 0 25660 1880 1368 R 0.0 0.2 0:00.06 htop
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 /sbin/init
311 root 20 0 17224 636 440 S 0.0 0.1 0:00.07 upstart-udev-brid
314 root 20 0 21592 1280 760 S 0.0 0.1 0:00.06 /sbin/udevd --dae
389 messagebu 20 0 23808 688 444 S 0.0 0.1 0:00.01 dbus-daemon --sys
407 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.02 rsyslogd -c5
408 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
409 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
406 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.04 rsyslogd -c5
553 root 20 0 15180 400 204 S 0.0 0.0 0:00.01 upstart-socket-br
htop oferece melhor visualização de múltiplas threads de CPU, maior suporte de cores em terminais modernos e mais opções de ordenação, entre outros recursos. Ao contrário do top, nem sempre está instalado por padrão, mas pode ser considerado uma substituição direta. Você pode sair do htop pressionando Ctrl+C assim como com o top.
Aqui estão alguns atalhos de teclado que irão ajudá-lo a usar o htop de forma mais eficaz:
- M: Sort processes by memory usage
- P: Sort processes by processor usage
- ?: Acessar ajuda
- k: Kill current/tagged process
- F2: Configurar o htop. Você pode escolher opções de exibição aqui.
- /: Pesquisar processos
Há muitas outras opções que você pode acessar através da ajuda ou configuração. Estas devem ser suas primeiras paradas ao explorar a funcionalidade do htop. No próximo passo, você aprenderá como monitorar a largura de banda da sua rede.
Passo 2 – Como Monitorar a Largura de Banda da Sua Rede
Se a sua conexão de rede parece estar sobrecarregada e você não tem certeza de qual aplicativo é o culpado, um programa chamado nethogs é uma boa escolha para descobrir.
No Ubuntu, você pode instalar o nethogs com o seguinte comando:
Depois disso, o comando nethogs estará disponível:
OutputNetHogs version 0.8.0
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/sec
O nethogs associa cada aplicativo ao seu tráfego de rede.
Existem apenas alguns comandos que você pode usar para controlar nethogs:
- M: Change displays between “kb/s”, “kb”, “b”, and “mb”.
- R: Sort by traffic received.
- S: Sort by traffic sent.
- Q: quit
iptraf-ng é outra maneira de monitorar o tráfego de rede. Ele fornece vários interfaces de monitoramento interativos diferentes.
Nota: O IPTraf requer uma tela com pelo menos 80 colunas por 24 linhas.
No Ubuntu, você pode instalar iptraf-ng com o seguinte comando:
iptraf-ng precisa ser executado com privilégios de root, então você deve antecedê-lo com sudo:
Você será apresentado a um menu que usa um popular framework de interface de linha de comando chamado ncurses.
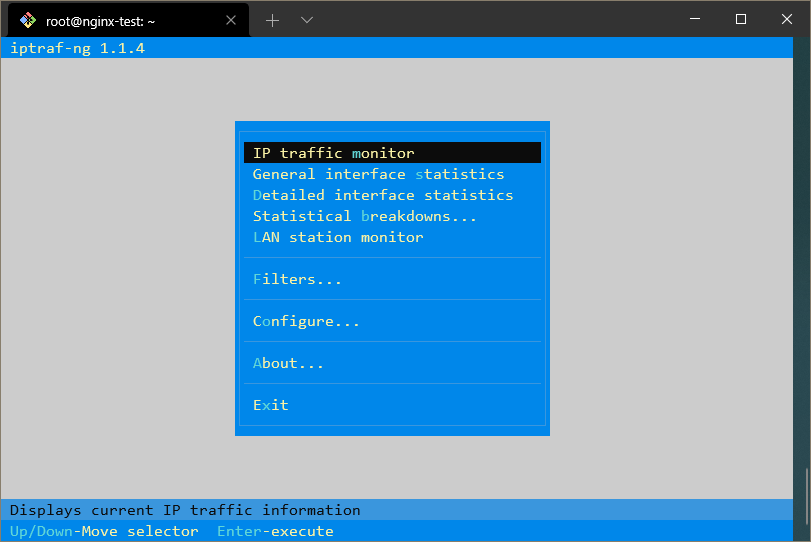
Com este menu, você pode selecionar qual interface gostaria de acessar.
Por exemplo, para obter uma visão geral de todo o tráfego de rede, você pode selecionar o primeiro menu e depois “Todas as interfaces”. Isso lhe dará uma tela que se parece com esta:
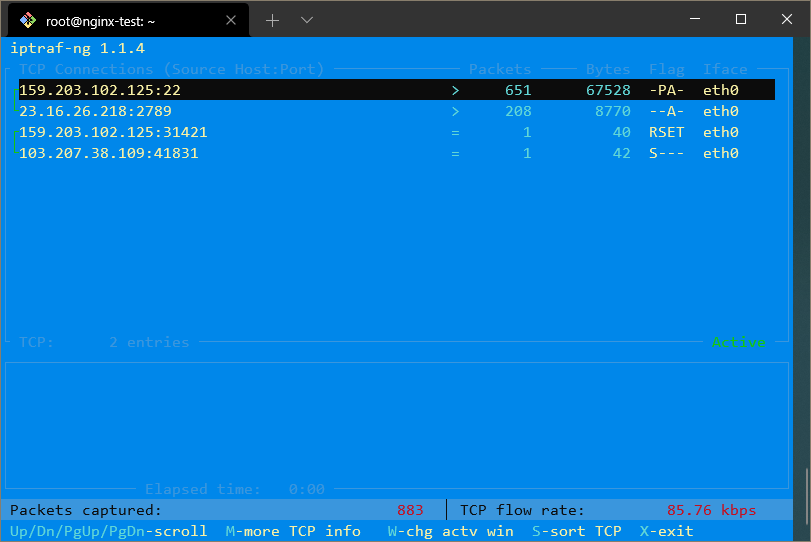
Aqui, você pode ver quais endereços IP está comunicando em todas as suas interfaces de rede.
Se você gostaria de ter esses endereços IP resolvidos em domínios, você pode habilitar a consulta de DNS reverso saindo da tela de tráfego, selecionando Configurar e então ativando Consulta de DNS reverso.
Você também pode habilitar Nomes de serviço TCP/UDP para ver os nomes dos serviços sendo executados em vez dos números de porta.
Com essas duas opções habilitadas, a exibição pode parecer assim:
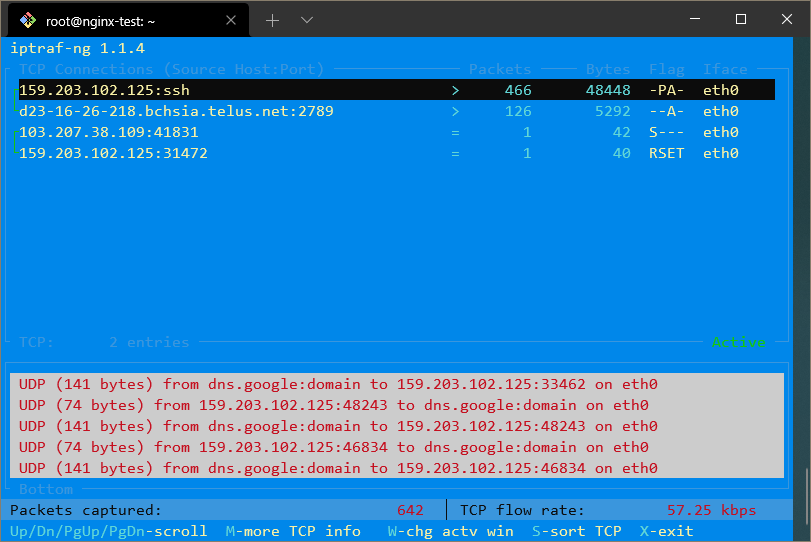
O comando netstat é outra ferramenta versátil para reunir informações de rede.
netstat é instalado por padrão na maioria dos sistemas modernos, mas você pode instalá-lo manualmente baixando-o dos repositórios de pacotes padrão do seu servidor. Na maioria dos sistemas Linux, incluindo o Ubuntu, o pacote que contém o netstat é net-tools:
Por padrão, o comando netstat por si só imprime uma lista de sockets abertos:
OutputActive Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .
Se você adicionar a opção -a, ele listará todas as portas, tanto as ouvindo quanto as não ouvindo:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .
Se você deseja filtrar para ver apenas conexões TCP ou UDP, use as flags -t ou -u respectivamente:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Veja estatísticas passando a flag “-s”:
OutputIp:
13500 total packets received
0 forwarded
0 incoming packets discarded
13500 incoming packets delivered
3078 requests sent out
16 dropped because of missing route
Icmp:
41 ICMP messages received
0 input ICMP message failed.
ICMP input histogram:
echo requests: 1
echo replies: 40
. . .
Se você deseja atualizar continuamente a saída, pode usar a flag -c. Existem muitas outras opções disponíveis para o netstat que você pode aprender revisando sua página de manual.
No próximo passo, você aprenderá algumas maneiras úteis de monitorar o uso do seu disco.
Passo 3 – Como Monitorar o Uso do Disco
Para uma rápida visão geral de quanto espaço em disco resta em seus drives conectados, você pode usar o programa df.
Sem nenhuma opção, sua saída parece assim:
OutputFilesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shm
Isso mostra o uso do disco em bytes, o que pode ser um pouco difícil de ler.
Para resolver esse problema, você pode especificar a saída em um formato legível para humanos:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
Se você quiser ver o espaço total em disco disponível em todos os sistemas de arquivos, pode passar a opção --total. Isso adicionará uma linha na parte inferior com informações de resumo:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
total 32G 1.2G 29G 4%
df pode fornecer uma visão geral útil. Outro comando, du, fornece uma análise por diretório.
du irá analisar o uso para o diretório atual e quaisquer subdiretórios. A saída padrão de du sendo executado em um diretório home quase vazio se parece com isso:
Output4 ./.cache
8 ./.ssh
28 .
Novamente, você pode especificar a saída legível para humanos passando -h:
Output4.0K ./.cache
8.0K ./.ssh
28K .
Para ver os tamanhos dos arquivos, assim como dos diretórios, digite o seguinte:
Output0 ./.cache/motd.legal-displayed
4 ./.cache
4 ./.ssh/authorized_keys
8 ./.ssh
4 ./.profile
4 ./.bashrc
4 ./.bash_history
28 .
Para um total na parte inferior, você pode adicionar a opção -c:
Output4 ./.cache
8 ./.ssh
28 .
28 total
Se você está interessado apenas no total e não nos detalhes, pode emitir:
Output28 .
Há também uma interface ncurses para du, apropriadamente chamada ncdu, que você pode instalar:
Isso representará graficamente o uso do seu disco:
Output--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_history
Você pode percorrer o sistema de arquivos usando as setas para cima e para baixo e pressionando Enter em qualquer entrada de diretório.
Na última seção, você aprenderá como monitorar o uso da memória.
Passo 4 – Como Monitorar o Uso da Memória
Você pode verificar o uso atual de memória em seu sistema usando o comando free.
Quando usado sem opções, a saída se parece com isto:
Output total used free shared buff/cache available
Mem: 1004896 390988 123484 3124 490424 313744
Swap: 0 0 0
Para exibir em um formato mais legível, você pode passar a opção -m para exibir a saída em megabytes:
Output total used free shared buff/cache available
Mem: 981 382 120 3 478 306
Swap: 0 0 0
A linha Mem inclui a memória usada para bufferização e armazenamento em cache, que é liberada assim que necessário para outros fins. Swap é a memória que foi escrita em um swapfile no disco para conservar memória ativa.
Por fim, o comando vmstat pode fornecer várias informações sobre seu sistema, incluindo memória, swap, E/S de disco e informações da CPU.
Você pode usar o comando para obter outra visão sobre o uso de memória:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 99340 123712 248296 0 0 0 1 9 3 0 0 100 0
Você pode ver isso em megabytes especificando unidades com a flag -S:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 96 120 242 0 0 0 1 9 3 0 0 100 0
Para obter algumas estatísticas gerais sobre o uso de memória, digite:
Output 495 M total memory
398 M used memory
252 M active memory
119 M inactive memory
96 M free memory
120 M buffer memory
242 M swap cache
0 M total swap
0 M used swap
0 M free swap
. . .
Para obter informações sobre o uso de cache de processos individuais do sistema, digite:
OutputCache Num Total Size Pages
ext4_groupinfo_4k 195 195 104 39
UDPLITEv6 0 0 768 10
UDPv6 10 10 768 10
tw_sock_TCPv6 0 0 256 16
TCPv6 11 11 1408 11
kcopyd_job 0 0 2344 13
dm_uevent 0 0 2464 13
bsg_cmd 0 0 288 14
. . .
Isso fornecerá detalhes sobre que tipo de informações são armazenadas no cache.
Conclusão
Usando essas ferramentas, você deverá começar a ser capaz de monitorar seu servidor a partir da linha de comando. Existem muitas outras utilidades de monitoramento que são usadas para diferentes propósitos, mas essas são um bom ponto de partida.
Em seguida, você pode querer aprender sobre gerenciamento de processos do Linux usando ps, kill e nice.