













Na Parte 1, cobrimos vários tópicos importantes. Recomendo que você leia, pois esta próxima parte se baseia nela.
Como uma revisão rápida, na parte 1, consideramos nossos dados sob uma perspectiva ampla e diferenciamos entre dados internos e dados externos. Também discutimos esquemas e contratos de dados e como eles fornecem os meios para negociar, alterar e evoluir nossos fluxos ao longo do tempo. Finalmente, cobrimos os tipos de eventos Fato (Estado) e Delta. Eventos de Fato são os melhores para comunicar estado e desacoplar sistemas, enquanto eventos Delta tendem a ser usados mais para dados internos, como em sourcing de eventos e outros casos de uso fortemente acoplados.
Tabelas Normalizadas Fazem Fluxos Normalizados
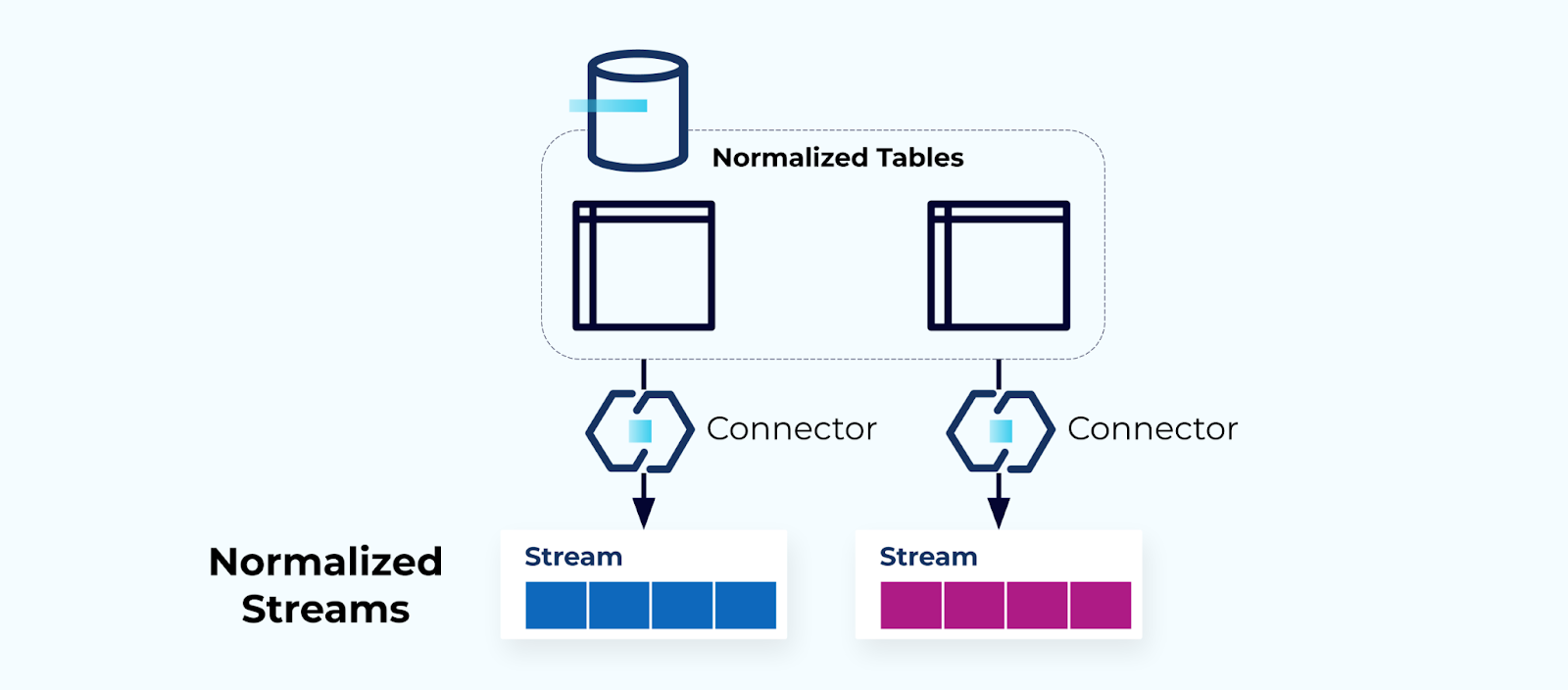
Tabelas normalizadas levam a fluxos de eventos normalizados. Conectores (por exemplo, CDC) puxam dados diretamente do banco de dados para um conjunto espelhado de fluxos de eventos. Isso não é ideal, pois cria um acoplamento forte entre as tabelas internas do banco de dados e os fluxos de eventos externos.
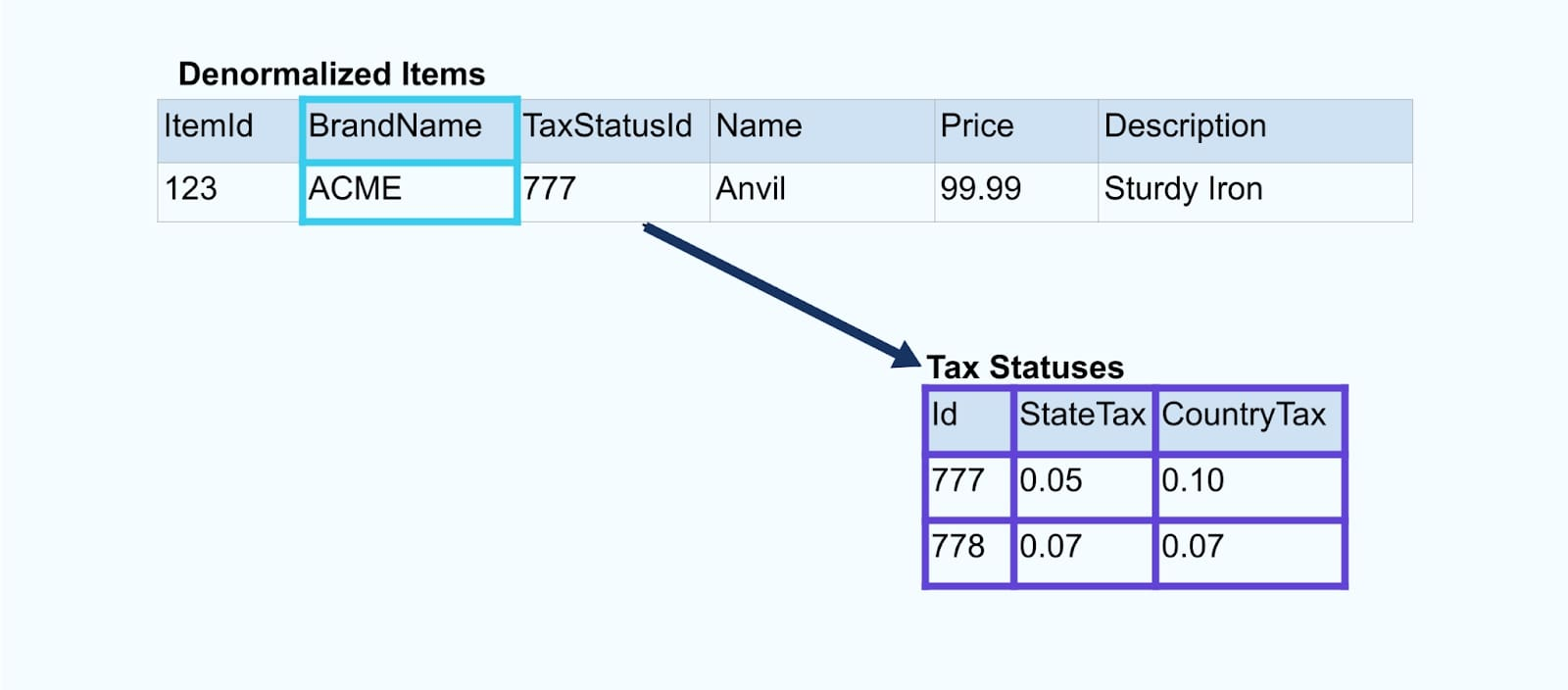
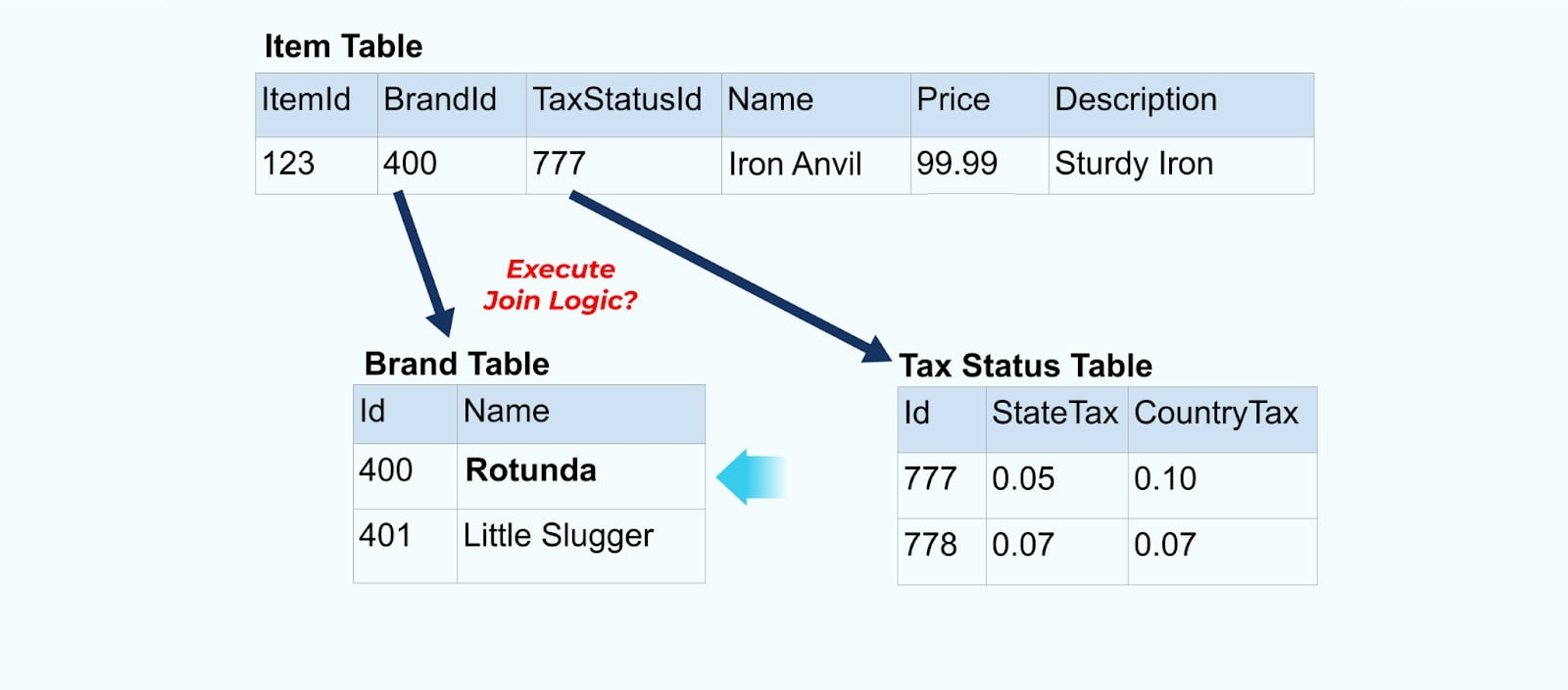
Considere um simples Item de e-commerce e suas tabelas associadas de Marca e Status Fiscal.
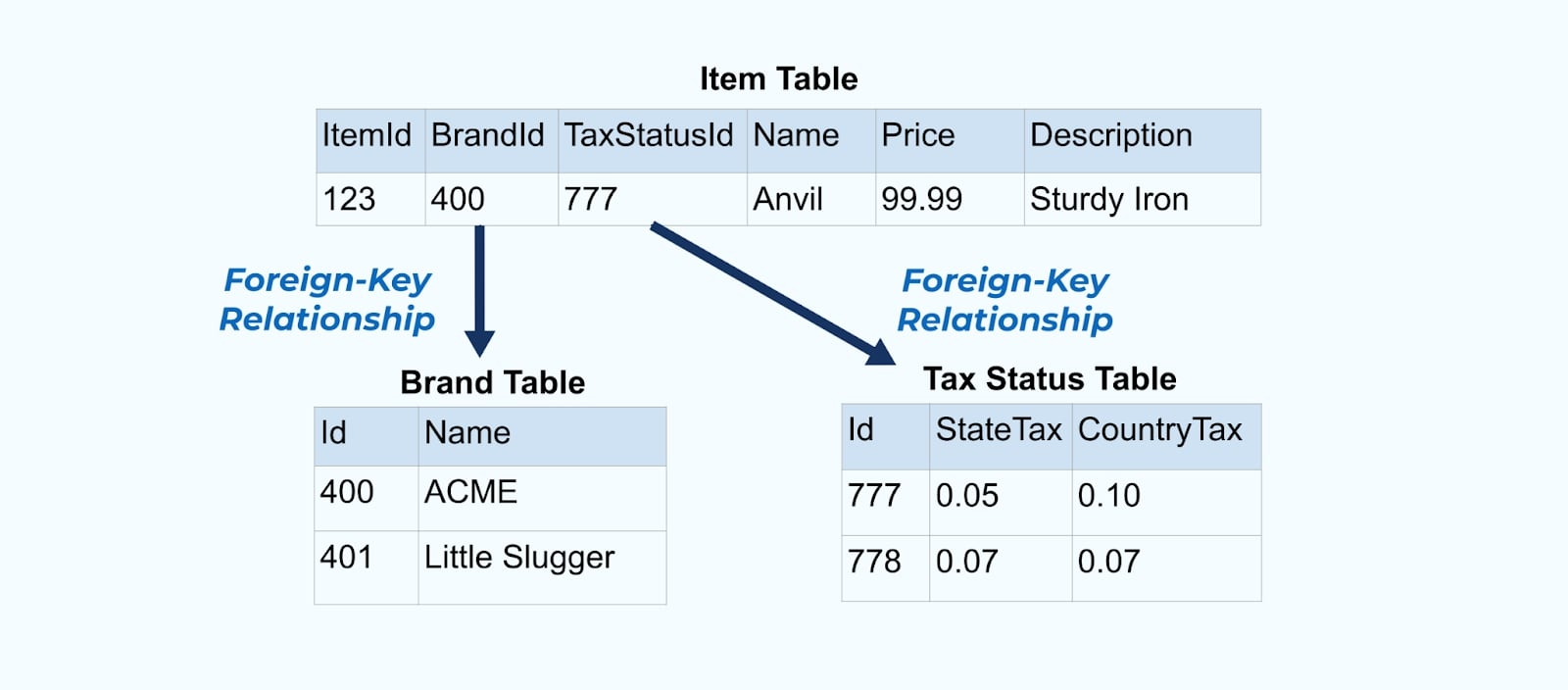
As tabelas de Marca e Status Fiscal se relacionam com a tabela de Item através de relações de chave estrangeira. Embora mostremos apenas um item na tabela, você provavelmente terá milhares (ou milhões), dependendo dos produtos que vende.
É comum configurar um conector para cada tabela, extrair os dados da tabela, compor em eventos e escrever cada tabela em um fluxo de eventos dedicado.
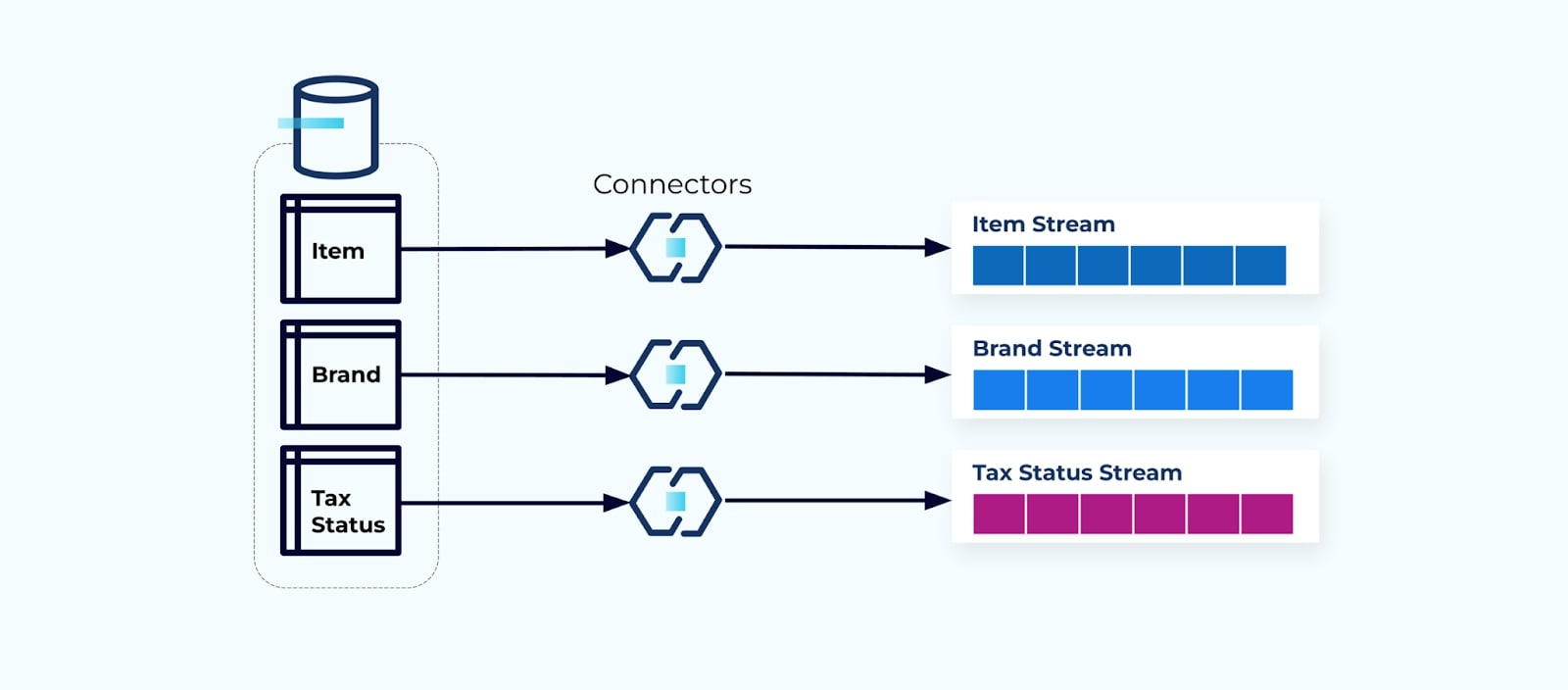
Expor as tabelas subjacentes no banco de dados leva a um fluxo de eventos correspondente por tabela. Embora seja fácil começar dessa forma, isso leva a vários problemas, que podem ser resumidos como um problema de acoplamento problema ou um custo problema. Vamos examinar cada um.
Problema: Consumidores Acoplam-se ao Modelo Interno
Expor a tabela de origem Item como está força os consumidores a acoplarem-se diretamente a ela. Mudanças no modelo de dados do sistema de origem afetarão os consumidores downstream.
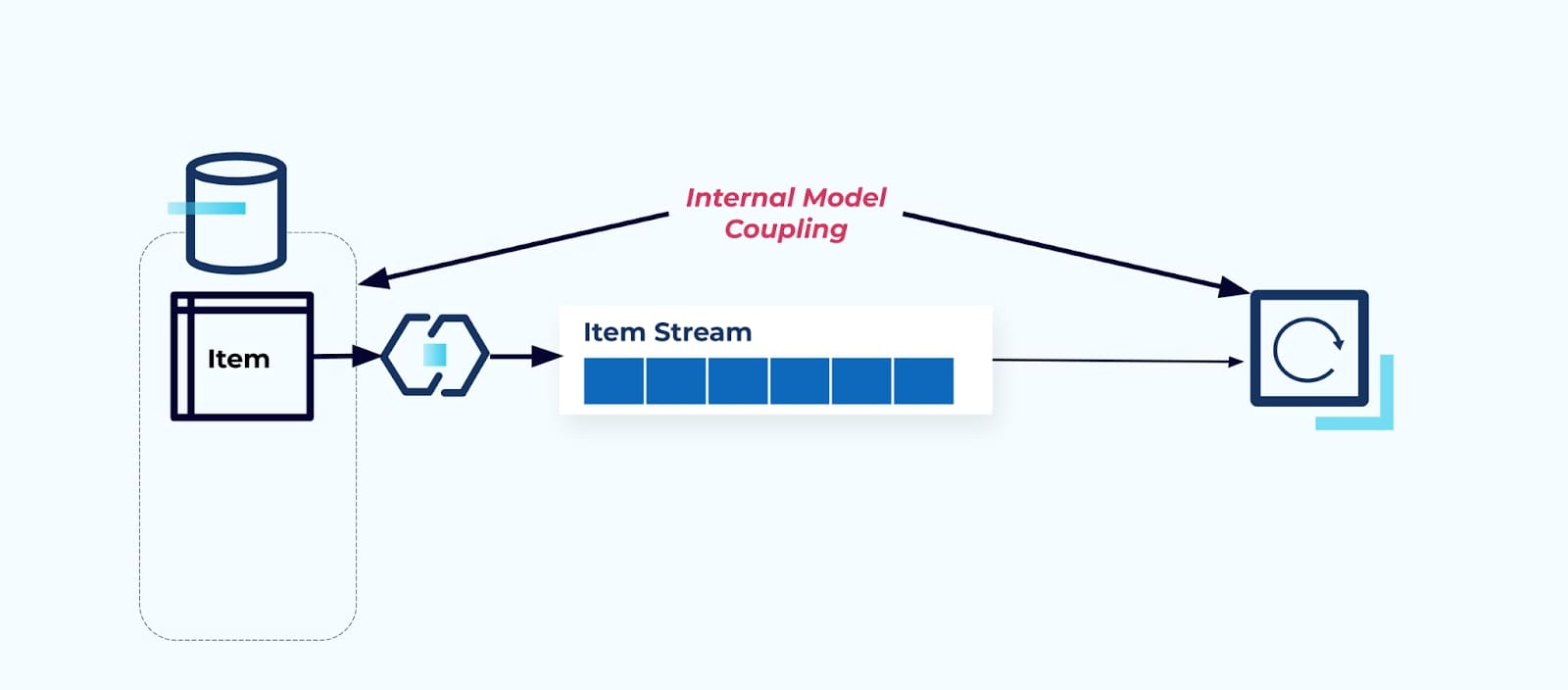
Digamos que refatoramos a tabela Item para extrair Precificação em sua própria tabela.
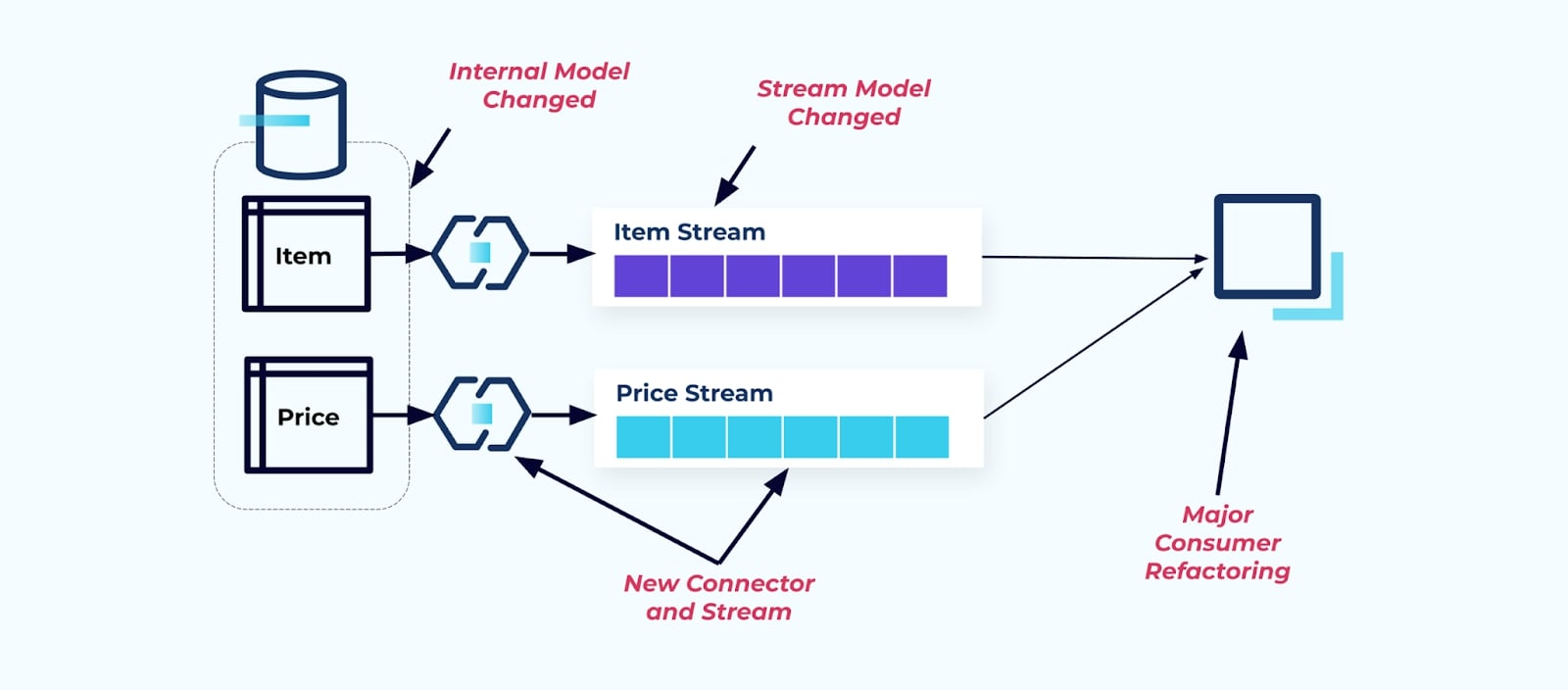
Refatorar as tabelas de origem resulta em um contrato de dados quebrado para o fluxo de itens. O consumidor não recebe mais os mesmos dados de item que originalmente esperava. Também precisamos criar um novo conector — um novo Preço de fluxo — e, finalmente, refatorar nossa lógica de consumidor para fazê-lo funcionar novamente. Renomear colunas, alterar valores padrão e mudar tipos de colunas são outras formas de mudanças quebradas introduzidas pelo acoplamento rígido no modelo de dados interno.
Problema: Junções de Streaming São (Normalmente) Caras
Bancos de dados relacionais são projetados para resolver junções rapidamente e com baixo custo. Junções de streaming, infelizmente, não são.
Considere dois serviços que querem acessar um Item, seu Imposto e suas informações de Marca. Se os dados já foram escritos em seu fluxo correspondente, então cada consumidor (à direita na imagem abaixo) terá que calcular as mesmas junções para denormalizar Item, Marca e Imposto.
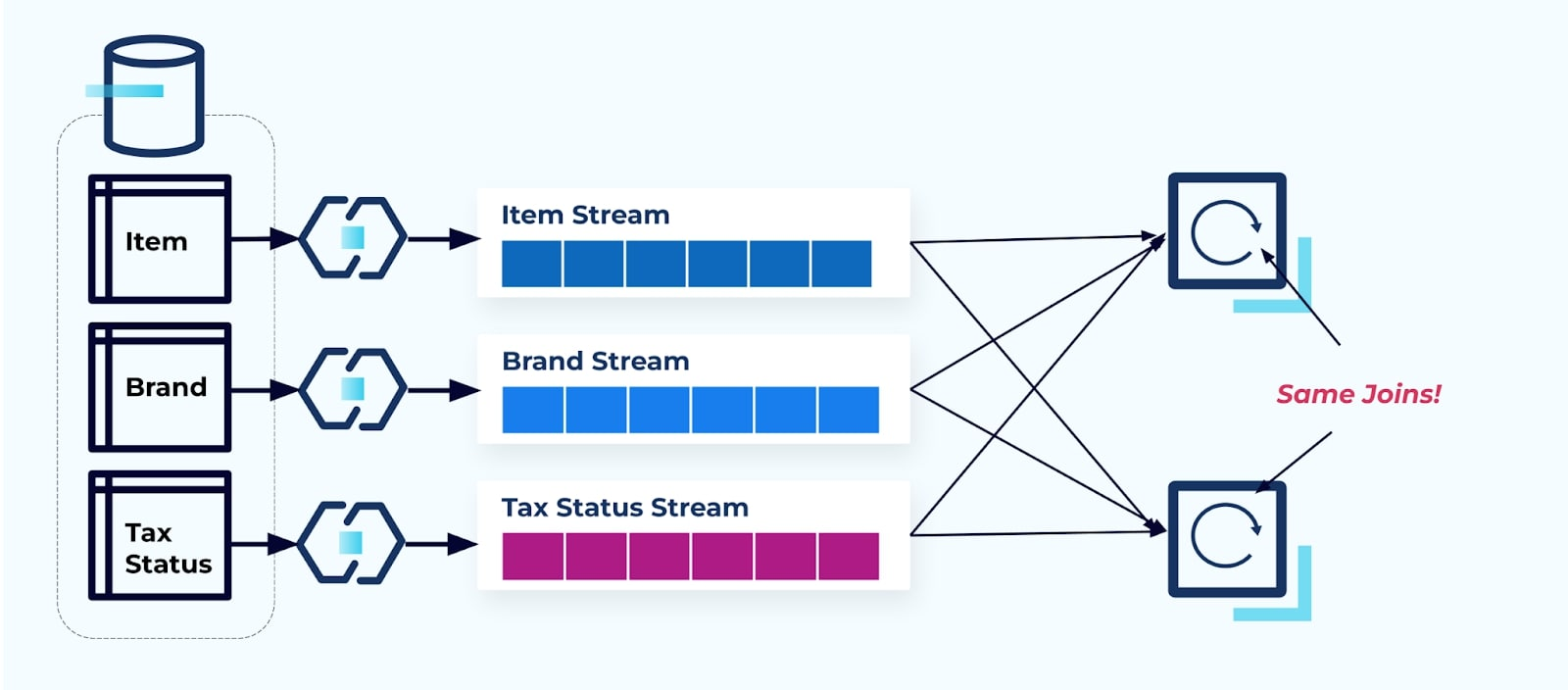
Essa estratégia pode incorrer em altos custos, tanto em horas-dev para escrever os aplicativos quanto em custos de servidor para calcular os joins. Resolver joins de streaming em larga escala pode resultar em muito rearranjo de dados, o que acarreta custos de poder de processamento, rede e armazenamento. Além disso, nem todas as frameworks de processamento de stream suportam joins, especialmente em chaves estrangeiras. Dessas que suportam, como Flink, Spark, KSQL ou Kafka Streams (por exemplo), você se encontrará limitado a um subconjunto de linguagens de programação (Java, Scala, Python).
Solução: Servir Dados Desnormalizados é o Melhor
Como princípio, torne os fluxos de eventos fáceis para seus consumidores usarem. Desnormalize os dados antes de disponibilizá-los aos consumidores usando uma camada de abstração e crie um modelo externo explícito contrato de dados (dados no exterior) para os consumidores se acoplarem.
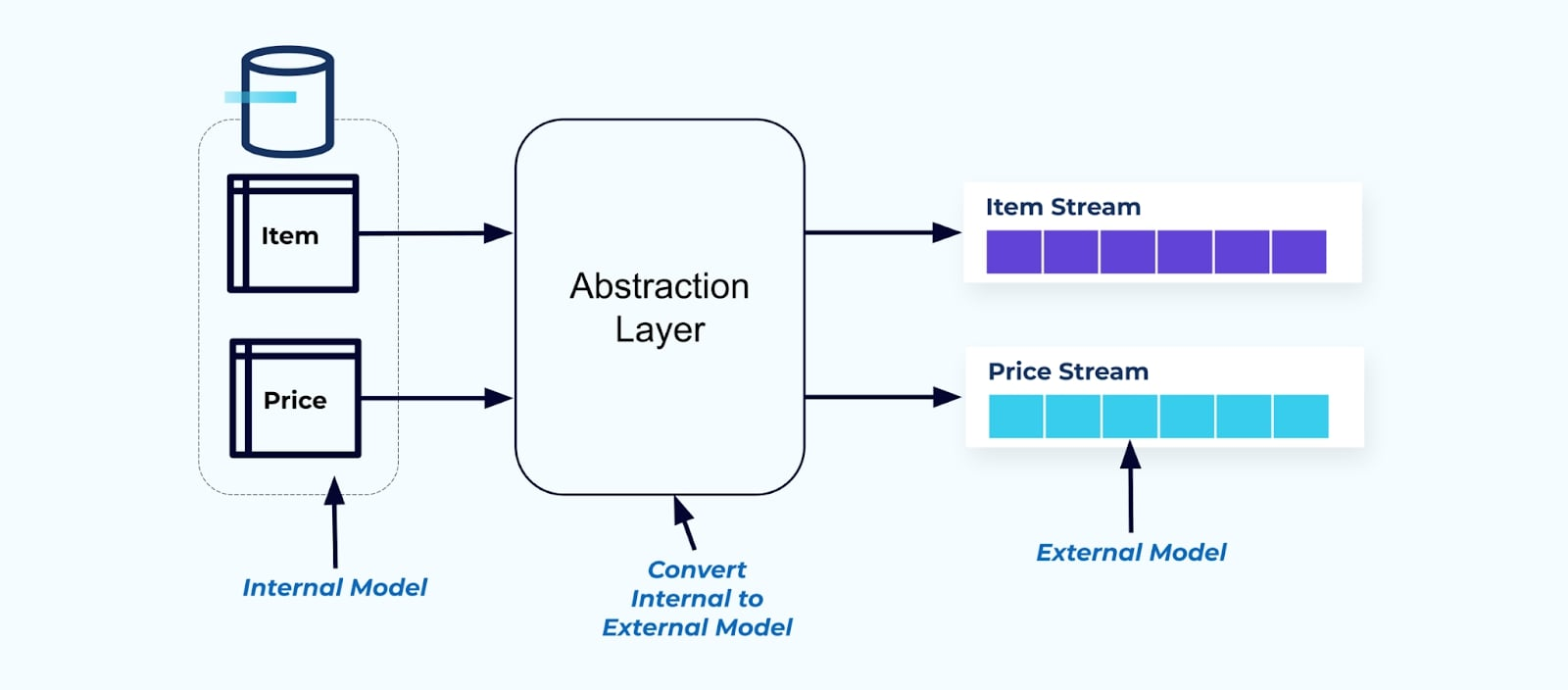
As mudanças no modelo interno permanecem isoladas nos sistemas de origem. Os consumidores obtêm um contrato de dados bem definido para se acoplarem. As mudanças feitas no modelo de origem podem prosseguir sem impedimentos, desde que o sistema de origem mantenha o contrato de dados para os consumidores.
Mas onde desnormalizamos? Duas opções:
- Reconstruir fora do sistema de origem via um serviço de joiner dedicado.
- Durante a criação do evento no sistema de origem usando o padrão Transactional Outbox.
Vamos dar uma olhada em cada solução por vez.
Opção 1: Desnormalizar Usando um Serviço de Joiner Dedicado
Neste exemplo, os streams à esquerda refletem as tabelas de onde vieram no banco de dados.
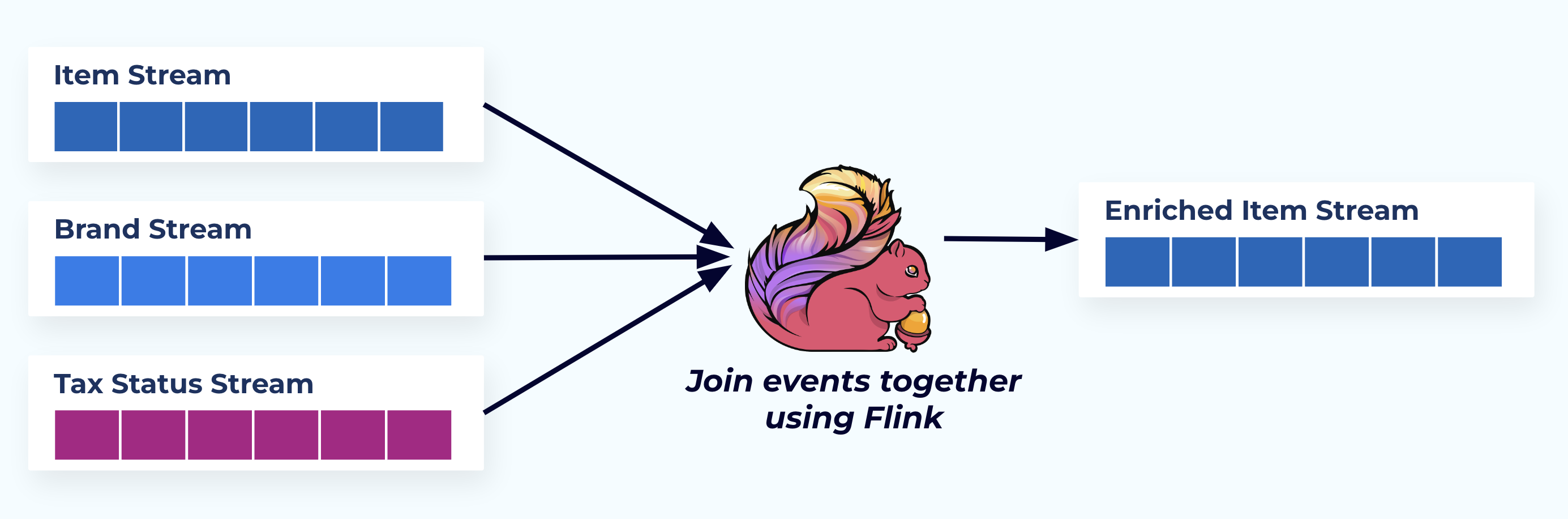
Nós unimos os eventos usando um aplicativo construído para propósito específico (ou consulta SQL em streaming) baseado nas relações de chave estrangeira e emitimos um único fluxo de item enriquecido.

Logicamente, estamos resolvendo as relações e compactando os dados em uma única linha denormalizada.
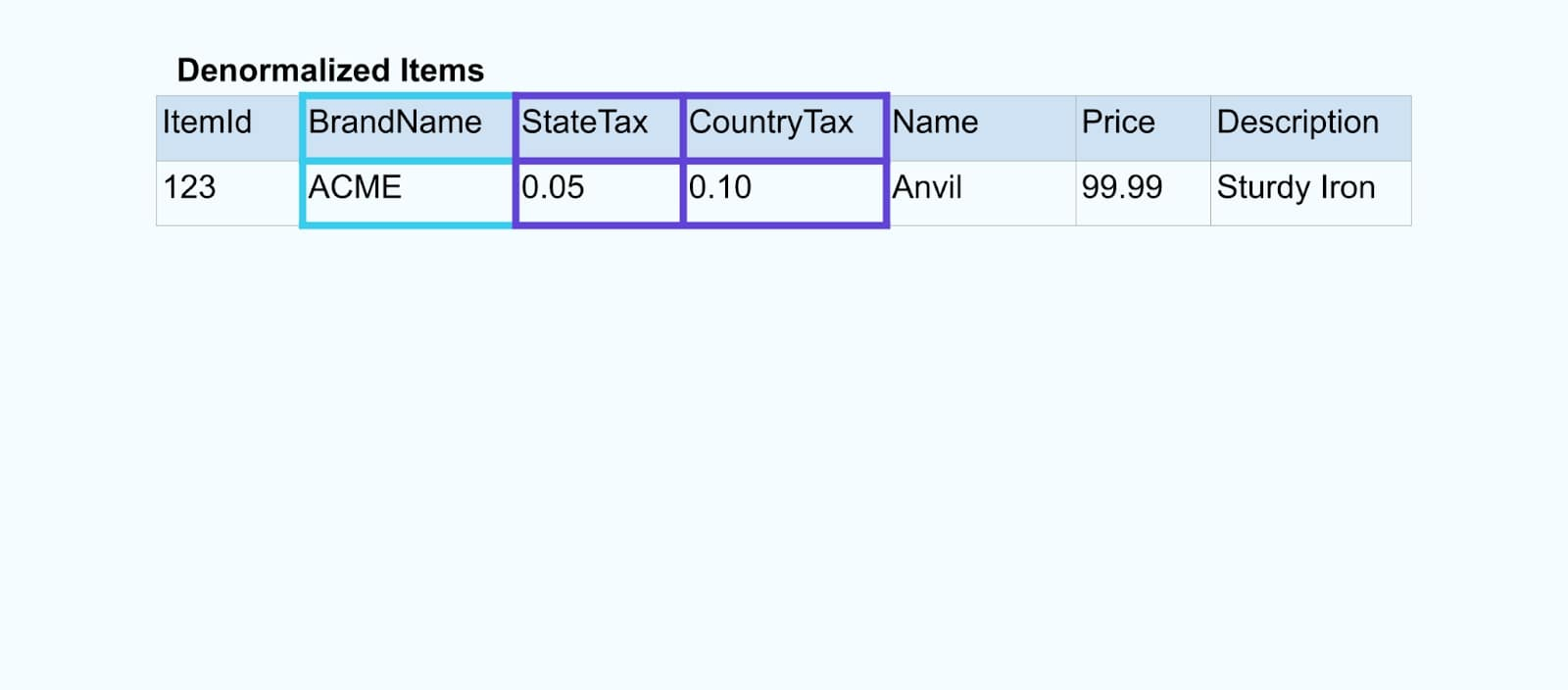
Unificadores construídos para propósito específico dependem de frameworks de processamento de fluxo como Apache Kafka Streams e Apache Flink para resolver tanto junções de chave primária quanto de chave estrangeira. Eles materializam os dados do fluxo em formatos de tabela interna duráveis, permitindo que o aplicativo unificador junte eventos em qualquer período – não apenas aqueles limitados por uma janela de tempo.
Unificadores usando Flink ou Kafka Streams também são notavelmente escaláveis — eles podem escalar para cima e para baixo conforme a carga e lidar com volumes massivos de tráfego.
Uma dica: Não coloque nenhuma lógica de negócios no unificador. Para ter sucesso neste padrão, os dados unificados devem representar accuramente a origem, simplesmente como um resultado denormalizado. Deixe que os consumidores downstream apliquem sua própria lógica de negócios, usando os dados denormalizados como uma única fonte de verdade.
Se você não quiser usar um unificador downstream, há outras opções. Vamos dar uma olhada no padrão de saída transacional em seguida.
Opção 2: Padrão de Saída Transacional
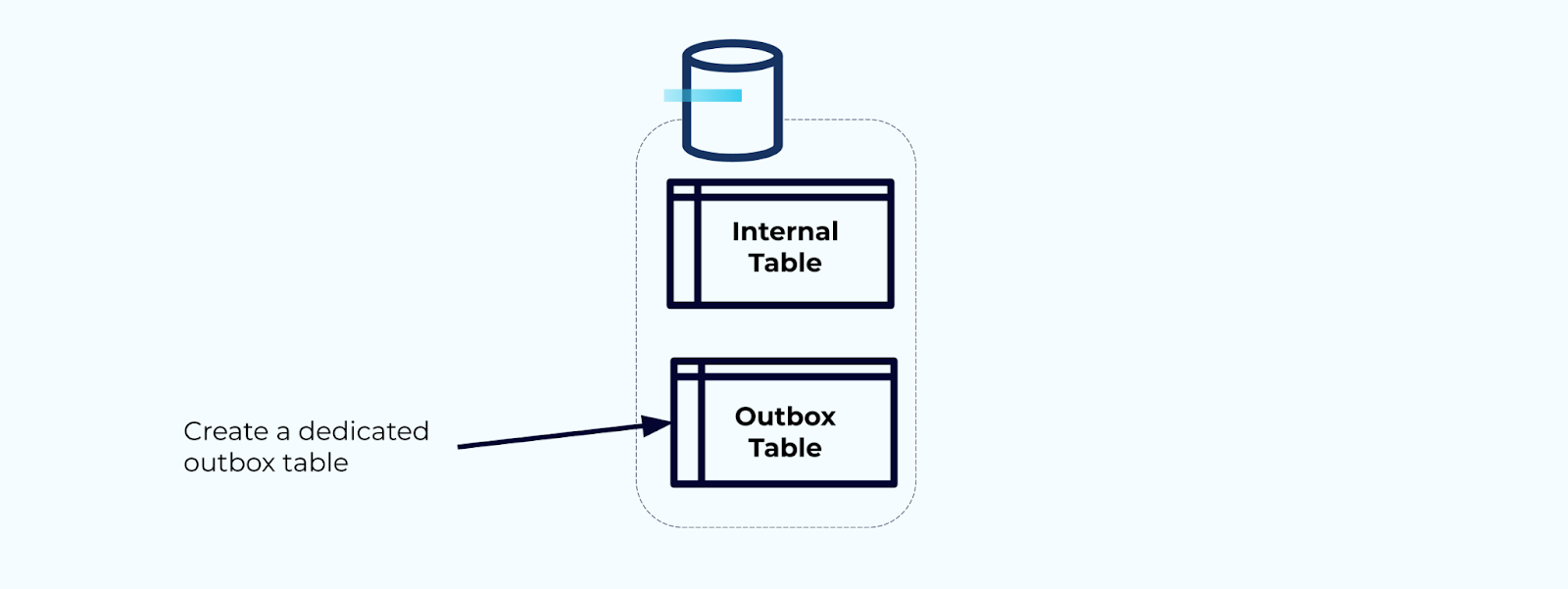
Primeiro, crie uma tabela de saída dedicada para escrever eventos no fluxo.
Primeiro, envolva todas as atualizações necessárias na tabela interna dentro de uma transação. Transações garantem que quaisquer atualizações feitas na tabela interna também serão gravadas na tabela de saída.
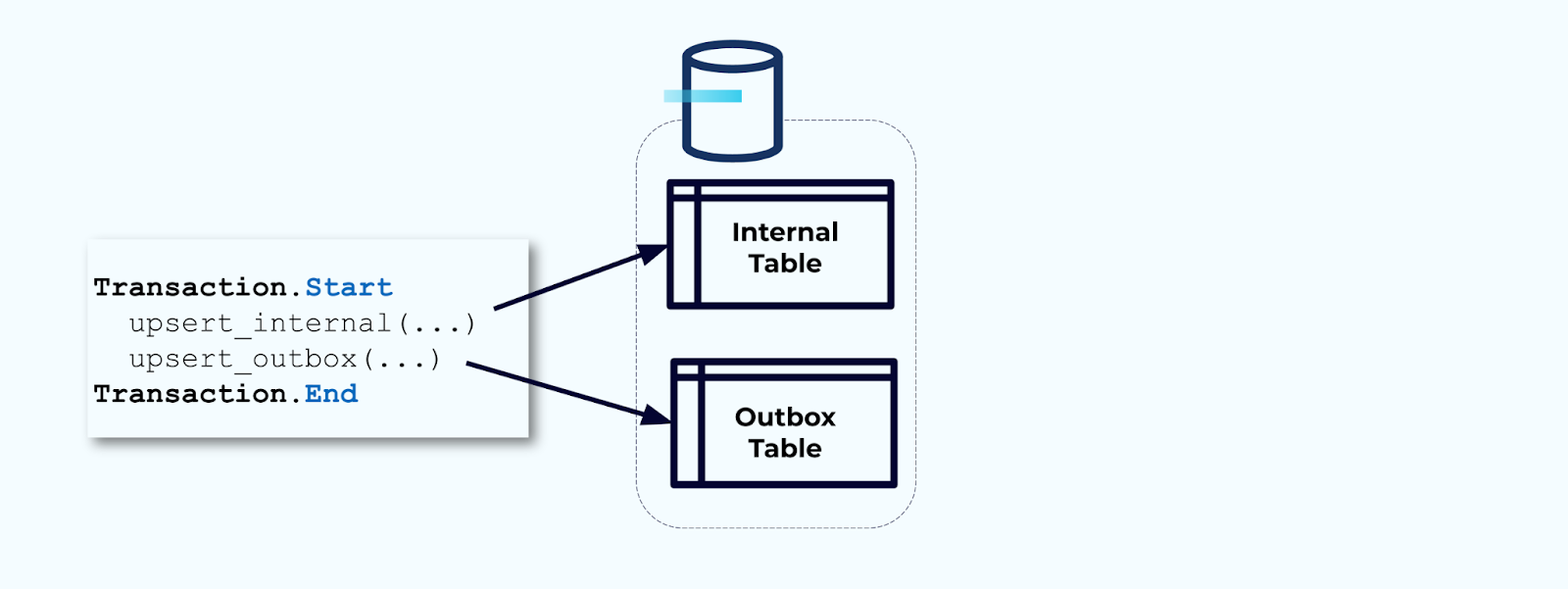
A tabela de saída permite isolar o modelo de dados interno, pois você pode unir e transformar os dados antes de gravá-los na sua tabela de saída. A tabela de saída atua como uma camada de abstração entre seus dados internos e dados externos, funcionando como um contrato de dados para seus consumidores.
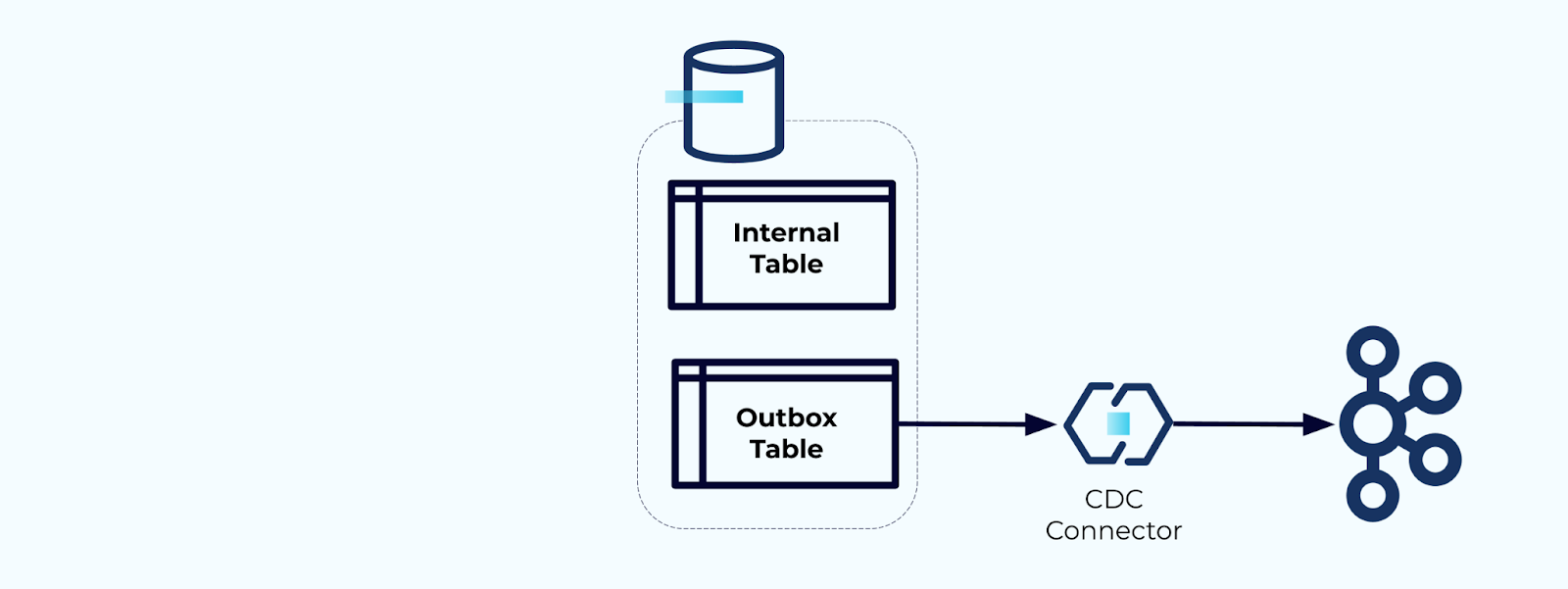
Finalmente, você pode usar um conector para transferir os dados da tabela de saída para o Kafka.
Você deve garantir que a tabela de saída não cresça indefinidamente — exclua os dados após serem capturados pelo CDC ou periodicamente com um trabalho agendado.
Exemplo: Desnormalizando Eventos de Rastreamento de Comportamento do Usuário
Rastrear o comportamento do usuário em suas páginas da web e aplicativos é uma fonte comum de eventos normalizados – pense no Google Analytics ou em opções de primeira parte internas. Mas não incluímos todas as informações no evento; em vez disso, limitamo-nos a identificadores (mais rápidos, menores, mais baratos), desnormalizando após a criação dos fatos.
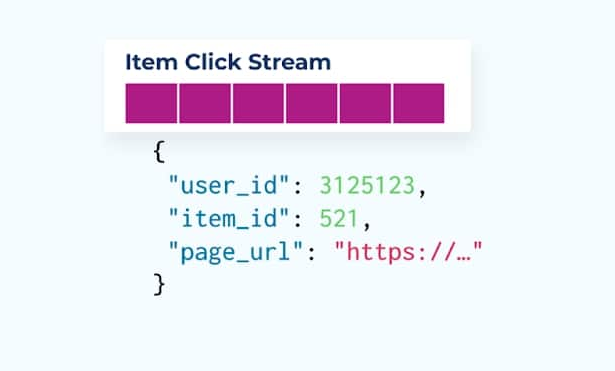
Considere um fluxo de eventos de cliques em itens detalhando quando um usuário clicou em um item enquanto navegava por itens de comércio eletrônico. Note que esse evento de clique no item não contém informações mais ricas sobre o item, como nome, preço e descrição, apenas ids básicos.
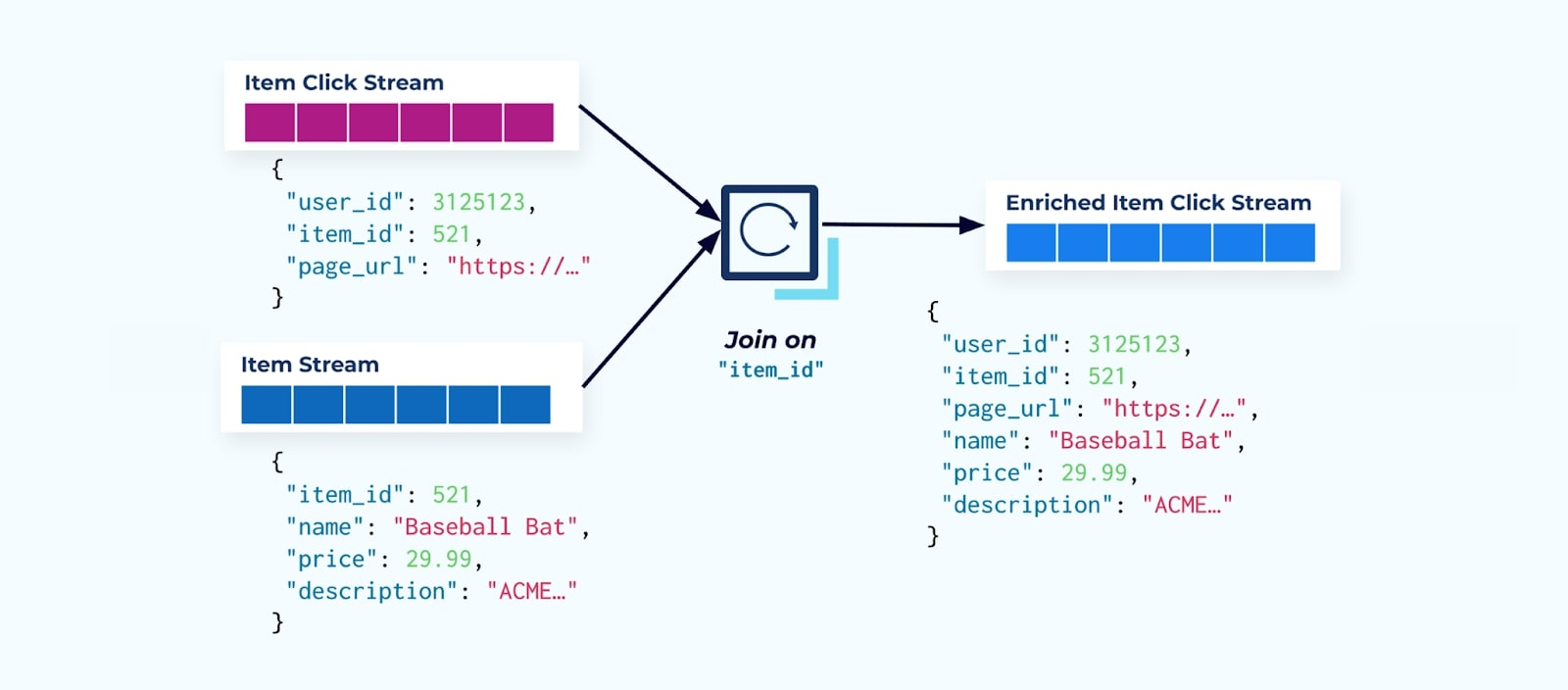
A primeira coisa que muitos consumidores de fluxo de cliques fazem é unir isso ao fluxo de fatos do item. E, como você está lidando com muitos eventos de clique, descobre que isso acaba usando uma grande quantidade de recursos de computação. Uma aplicação Flink construída para um propósito específico pode unir os cliques no item com os dados detalhados do item e emiti-los para um fluxo de cliques no item enriquecido.
Empresas maiores com múltiplas divisões (e sistemas) provavelmente verão seus dados provenientes de diferentes fontes, e unir posteriormente usando um unificador de fluxo é o resultado mais provável.
Considerações sobre Dimensões Lentamente Mutáveis
Já discutimos as considerações de desempenho de escrever eventos contendo grandes conjuntos de dados (por exemplo, grandes blobs de texto) e domínios de dados que mudam frequentemente (por exemplo, inventário de itens). Agora, vamos olhar para dimensões lentamente mutáveis (SCDs), frequentemente indicadas por uma relação de chave estrangeira, pois essas podem ser outra fonte de volumes significativos de dados.
Vamos voltar ao nosso exemplo de item novamente. Digamos que você tenha uma operação que atualiza a Tabela de Itens. Vamos renomear o item de Bigorna para Bigorna de Ferro.
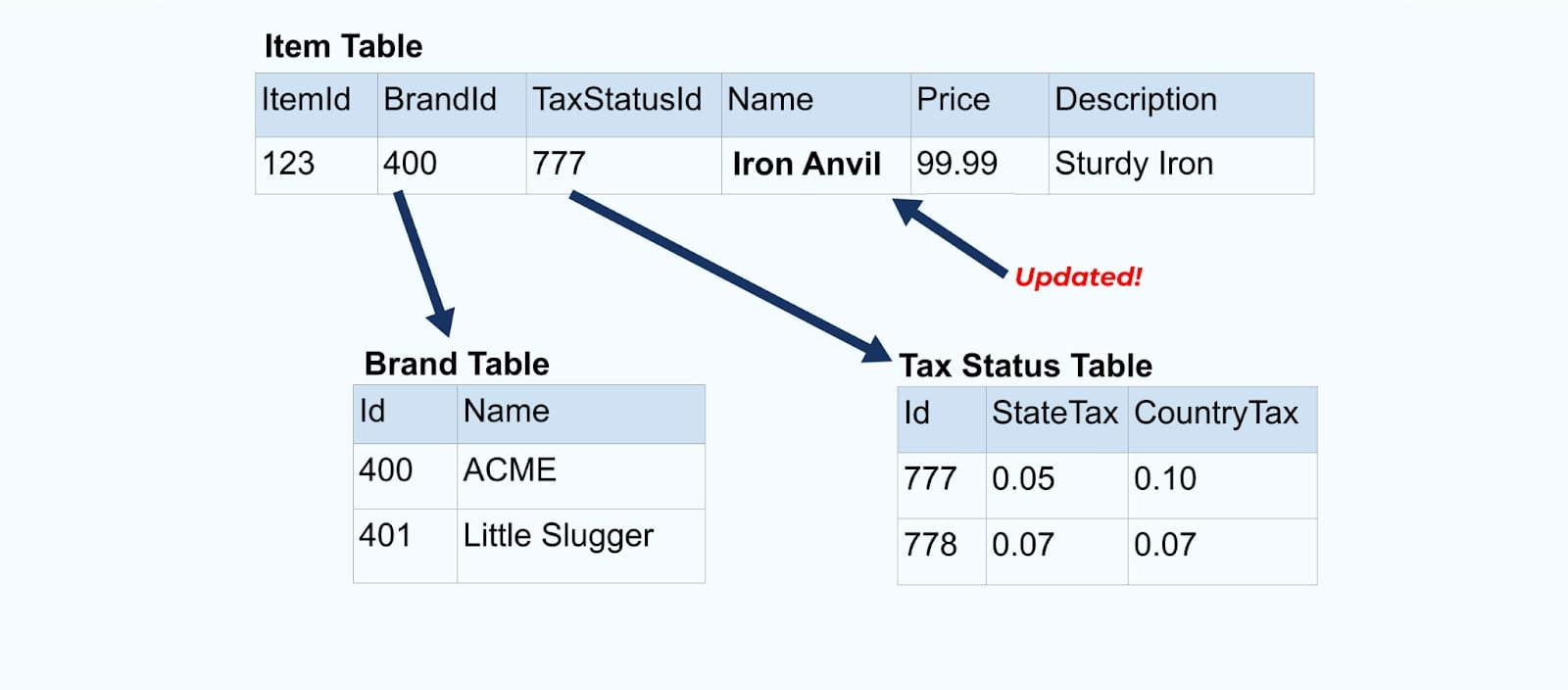
Ao atualizar os dados no banco de dados, também emitimos o item atualizado (digamos, via padrão de saída), completo com o status fiscal desnormalizado e a tabela de marca.
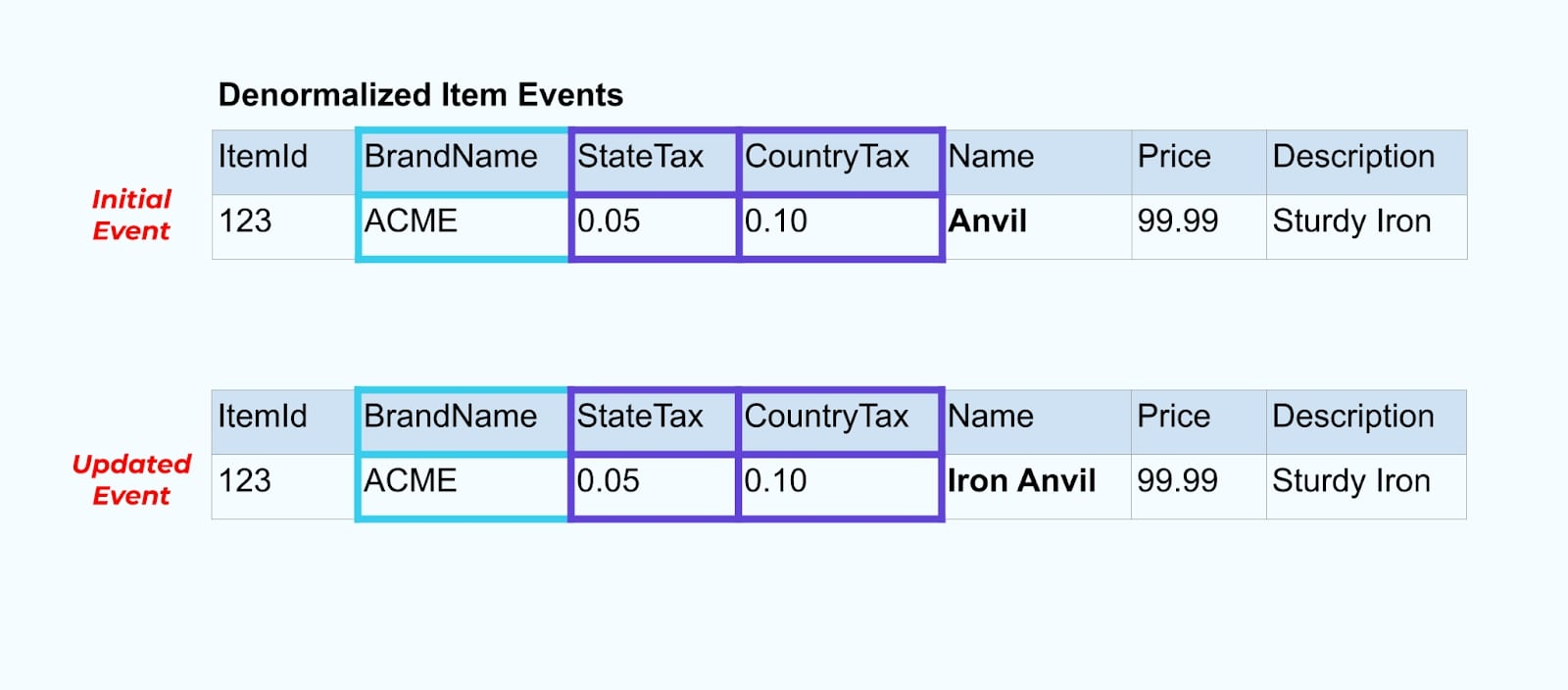
No entanto, também precisamos considerar o que acontece quando alteramos valores nas tabelas de marca ou imposto. Atualizar uma dessas dimensões lentamente mutáveis pode resultar em um número significativamente grande de atualizações para todos os itens afetados.
Por exemplo, a empresa ACME passa por um rebranding e cria um novo nome de marca, mudando de ACME para Rotunda. Produzimos outro evento para ItemId=123.
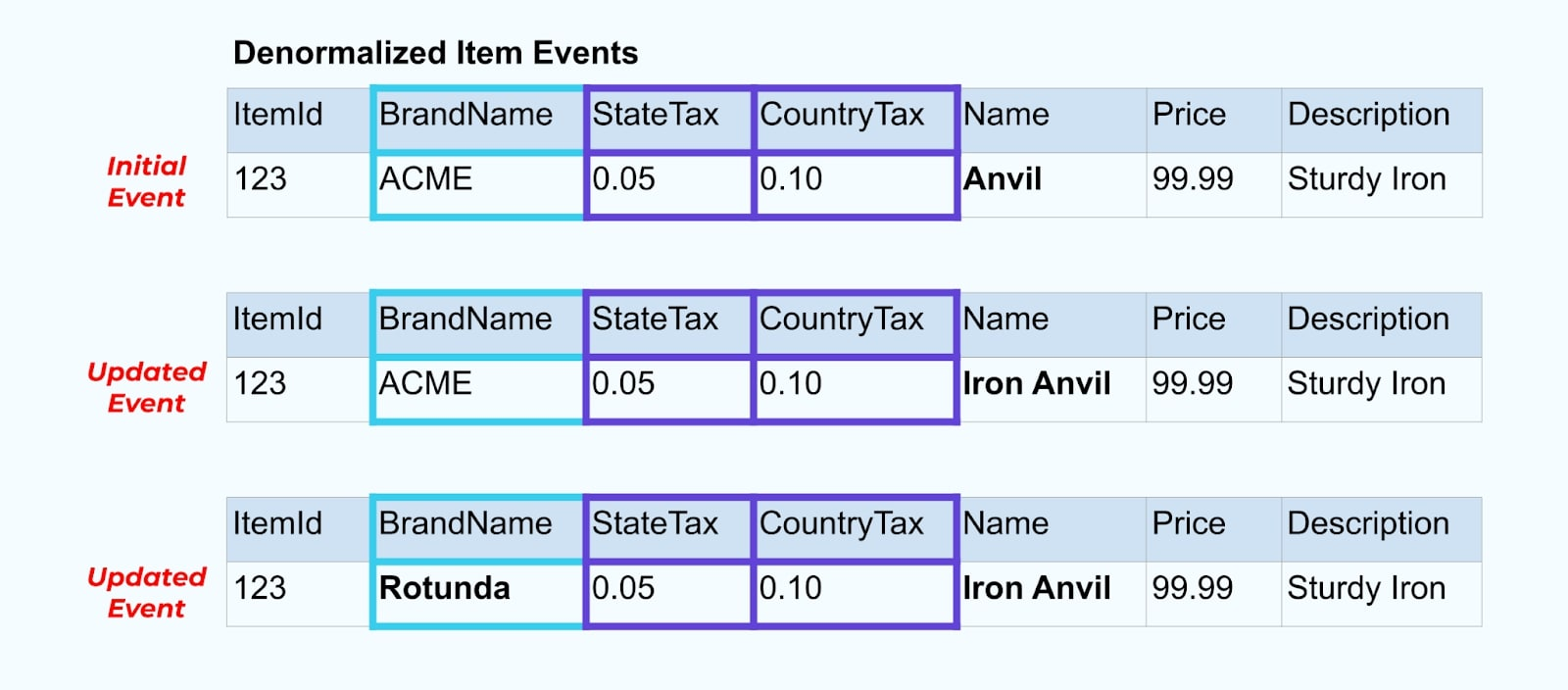
No entanto, Rotunda (antiga ACME) provavelmente tem muitas centenas (ou milhares) de itens que também são atualizados por essa mudança, resultando em um número correspondente de eventos de itens enriquecidos atualizados.
Ao desnormalizar SCDs e relacionamentos de chave estrangeira, tenha em mente o impacto que uma mudança no SCD pode ter no fluxo de eventos como um todo. Você pode decidir abrir mão da desnormalização e deixar isso a cargo do consumidor no caso de a mudança no SCD resultar em milhões ou bilhões de eventos atualizados.
Resumo
A desnormalização facilita o uso dos dados pelos consumidores, mas vem à custa de mais processamento upstream e uma seleção cuidadosa dos dados a incluir. Os consumidores podem ter mais facilidade para construir aplicativos e podem escolher entre uma ampla gama de tecnologias, incluindo aquelas que não suportam nativamente junções de streaming.
Normalizar dados upstream funciona bem quando os dados são pequenos e atualizados com pouca frequência. Tamanhos maiores de eventos, atualizações frequentes e SCDs são todos fatores a serem observados ao determinar o que desnormalizar upstream e o que deixar para seus consumidores fazerem por conta própria.
Finalmente, escolher quais dados incluir em um evento e quais deixar fora é um equilíbrio entre as necessidades dos consumidores, as capacidades dos produtores e as relações únicas do modelo de dados. Mas o melhor lugar para começar é entendendo as necessidades dos seus consumidores e a isolamento do modelo de dados interno do seu sistema de origem.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2