













O surgimento da IA agente tem alimentado a empolgação em torno de agentes que realizam tarefas autonomamente, fazem recomendações e executam fluxos de trabalho complexos que misturam IA com computação tradicional. Mas criar tais agentes em ambientes do mundo real, orientados por produtos, apresenta desafios que vão além da própria IA.
Sem uma arquitetura cuidadosa, as dependências entre os componentes podem criar gargalos, limitar a escalabilidade e complicar a manutenção à medida que os sistemas evoluem. A solução está em desacoplar os fluxos de trabalho, onde os agentes, infraestrutura e outros componentes interagem fluidamente sem dependências rígidas.
Esse tipo de integração flexível e escalável requer uma “linguagem” compartilhada para a troca de dados – uma arquitetura robusta baseada em eventos (EDA) alimentada por fluxos de eventos. Ao organizar aplicativos em torno de eventos, os agentes podem operar em um sistema responsivo e desacoplado, onde cada parte realiza seu trabalho de forma independente. As equipes podem fazer escolhas tecnológicas livremente, gerenciar necessidades de escalabilidade separadamente e manter limites claros entre os componentes, permitindo uma verdadeira agilidade.
Para testar esses princípios, desenvolvi o PodPrep AI, um assistente de pesquisa com IA que me ajuda a me preparar para entrevistas de podcast no Software Engineering Daily e Software Huddle. Neste post, vou mergulhar no design e na arquitetura do PodPrep AI, mostrando como a EDA e os fluxos de dados em tempo real impulsionam um sistema agente eficaz.
Nota: Se você quiser apenas ver o código, acesse meu repositório no GitHub aqui.
Por que uma Arquitetura Baseada em Eventos para IA?
Em aplicações de IA do mundo real, um design monolítico e fortemente acoplado não se sustenta. Embora provas de conceito ou demonstrações frequentemente utilizem um único sistema unificado por simplicidade, essa abordagem rapidamente se torna impraticável em produção, especialmente em ambientes distribuídos. Sistemas fortemente acoplados criam gargalos, limitam a escalabilidade e desaceleram a iteração — todos desafios críticos a evitar à medida que as soluções de IA crescem.
Considere um agente de IA típico.
Ele pode precisar extrair dados de várias fontes, lidar com engenharia de prompts e fluxos de trabalho RAG, e interagir diretamente com várias ferramentas para executar fluxos de trabalho determinísticos. A orquestração necessária é complexa, com dependências em múltiplos sistemas. E se o agente precisar se comunicar com outros agentes, a complexidade só aumenta. Sem uma arquitetura flexível, essas dependências tornam a escalabilidade e a modificação quase impossíveis.

Em produção, diferentes equipes geralmente gerenciam diferentes partes da pilha: MLOps e engenharia de dados administram o pipeline RAG, ciência de dados seleciona modelos, e desenvolvedores de aplicações constroem a interface e o backend. Uma configuração fortemente acoplada força essas equipes a dependerem umas das outras, o que desacelera a entrega e dificulta a escalabilidade. Idealmente, as camadas da aplicação não deveriam precisar entender os internos da IA; elas deveriam simplesmente consumir resultados quando necessário.
Além disso, as aplicações de IA não podem operar de forma isolada. Para obter um valor real, as percepções da IA precisam fluir perfeitamente por meio de plataformas de dados do cliente (CDPs), CRMs, análises e muito mais. As interações com os clientes devem acionar atualizações em tempo real, alimentando diretamente outras ferramentas para ação e análise. Sem uma abordagem unificada, integrar percepções entre plataformas se torna um quebra-cabeça difícil de gerenciar e impossível de escalar.
A IA alimentada por EDA aborda esses desafios criando um “sistema nervoso central” para os dados. Com EDA, as aplicações transmitem eventos em vez de depender de comandos encadeados. Isso desacopla os componentes, permitindo que os dados fluam de forma assíncrona onde for necessário, possibilitando que cada equipe trabalhe de forma independente. O EDA promove integração de dados perfeita, crescimento escalável e resiliência, tornando-se uma base poderosa para sistemas modernos impulsionados por IA.
Projetando um Agente de Pesquisa Alimentado por IA Escalável
Ao longo dos últimos dois anos, conduzi centenas de podcasts em Software Engineering Daily, Software Huddle e Partially Redacted.
Para me preparar para cada podcast, realizo um processo de pesquisa detalhado para preparar um resumo do podcast que contém minhas reflexões, informações sobre o convidado e o tópico, e uma série de perguntas potenciais. Para construir esse resumo, geralmente pesquiso sobre o convidado e a empresa para a qual trabalham, ouço outros podcasts nos quais possam ter participado, leio postagens de blog que escreveram e me informo sobre o principal tópico que estaremos discutindo.
Eu tento fazer conexões com outros podcasts que eu já apresentei ou com a minha própria experiência relacionada ao tópico ou tópicos semelhantes. Todo esse processo leva tempo e esforço consideráveis. Grandes operações de podcasts têm pesquisadores dedicados e assistentes que fazem esse trabalho para o apresentador. Eu não estou comandando esse tipo de operação por aqui. Eu tenho que fazer tudo isso sozinho.
Para lidar com isso, eu quis construir um agente que pudesse fazer esse trabalho por mim. Em um nível mais alto, o agente se pareceria com a imagem abaixo.

Eu forneço materiais básicos de origem como o nome do convidado, empresa, tópicos nos quais quero focar, alguns URLs de referência como posts de blog e podcasts existentes, e então alguma mágica de IA acontece, e minha pesquisa está completa.
Essa ideia simples me levou a criar o PodPrep AI, meu assistente de pesquisa alimentado por IA que só me custa tokens.
O restante deste artigo discute o design do PodPrep AI, começando pela interface do usuário.
Construindo a Interface do Usuário do Agente
Eu projetei a interface do agente como um aplicativo web onde posso facilmente inserir material de origem para o processo de pesquisa. Isso inclui o nome do convidado, a empresa deles, o tópico da entrevista, qualquer contexto adicional e links para blogs relevantes, sites e entrevistas anteriores em podcasts.
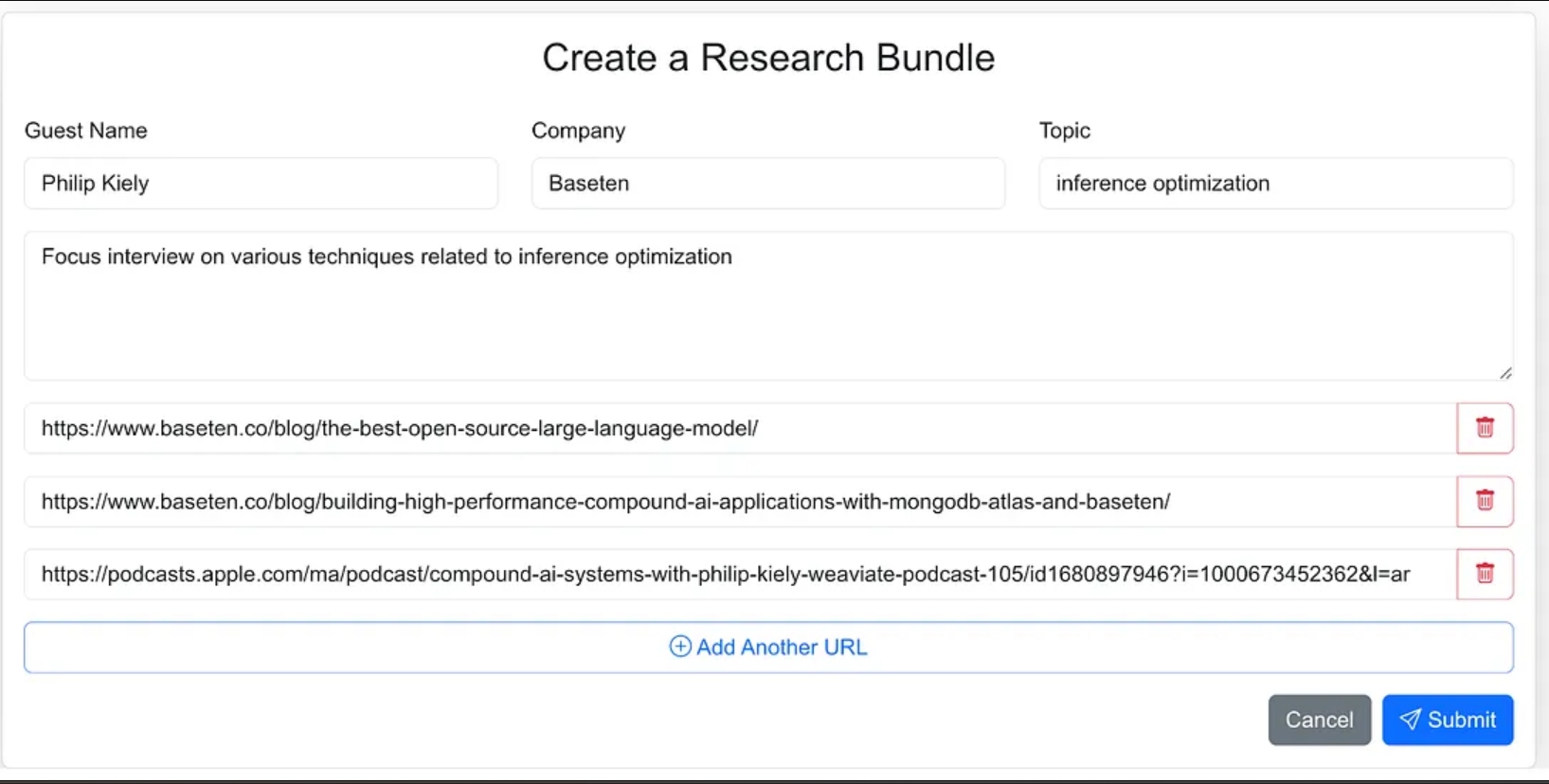
Eu poderia ter dado menos orientação ao agente e, como parte do fluxo de trabalho do agente, tê-lo buscado os materiais de origem, mas para a versão 1.0, eu decidi fornecer os URLs de origem.
A aplicação web é um aplicativo padrão de três camadas construído com Next.js e MongoDB para o banco de dados da aplicação. Ela não sabe nada sobre IA. Simplesmente permite que o usuário insira novos conjuntos de pesquisas e estes aparecem em estado de processamento até que o processo agente tenha concluído o fluxo de trabalho e populado um resumo de pesquisa no banco de dados da aplicação.
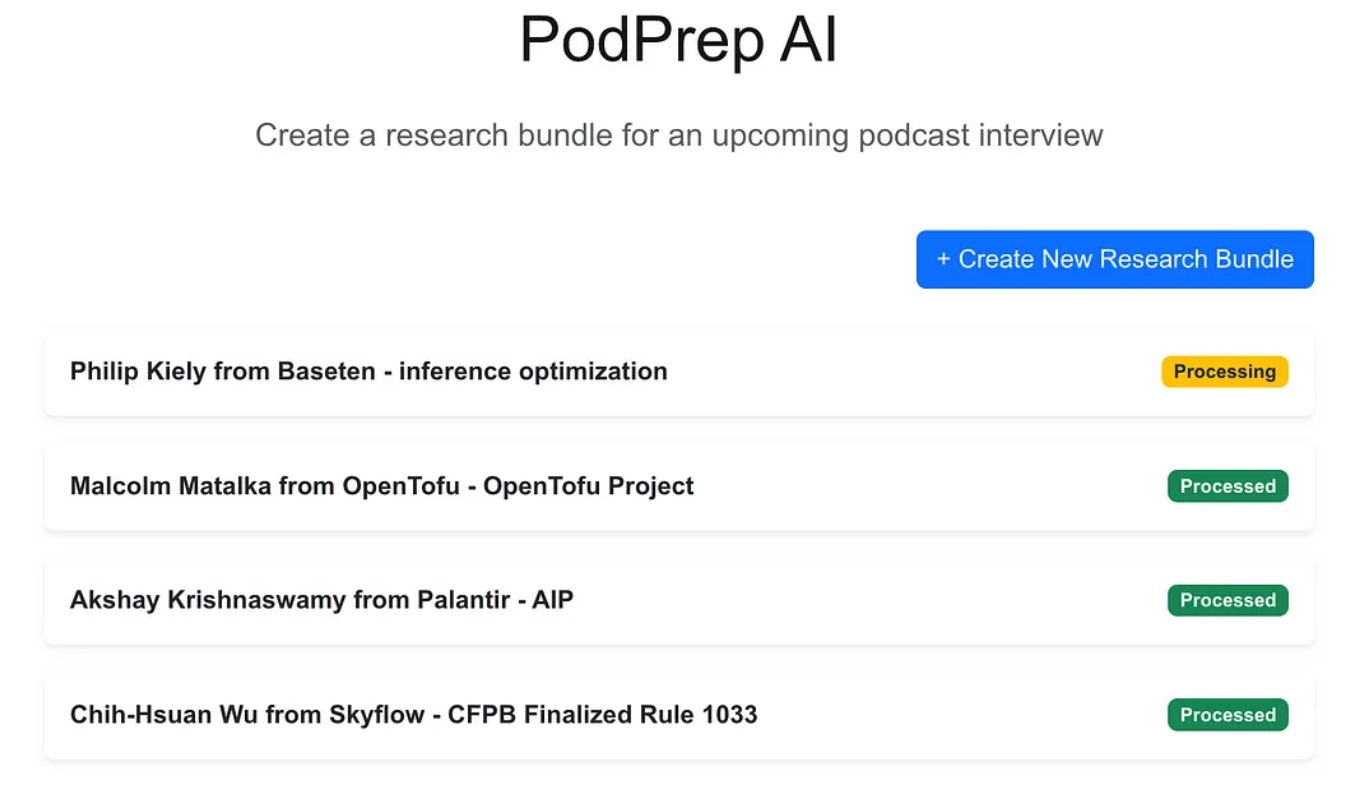
Assim que a magia da IA estiver completa, posso acessar um documento de resumo para a entrada conforme mostrado abaixo.

Criando o Fluxo de Trabalho Agente
Para a versão 1.0, eu queria ser capaz de realizar três ações principais para construir o resumo da pesquisa:
- Para qualquer URL de site, postagem de blog ou podcast, recuperar o texto ou resumo, dividir o texto em tamanhos razoáveis, gerar incorporações e armazenar a representação vetorial.
- Para todo o texto extraído das URLs de origem da pesquisa, extrair as perguntas mais interessantes e armazená-las.
- Gerar um resumo de pesquisa de podcast combinando o contexto mais relevante com base nas incorporações, melhores perguntas feitas anteriormente e quaisquer outras informações que fizeram parte da entrada do conjunto.
A imagem abaixo mostra a arquitetura da aplicação web para o fluxo de trabalho agente.
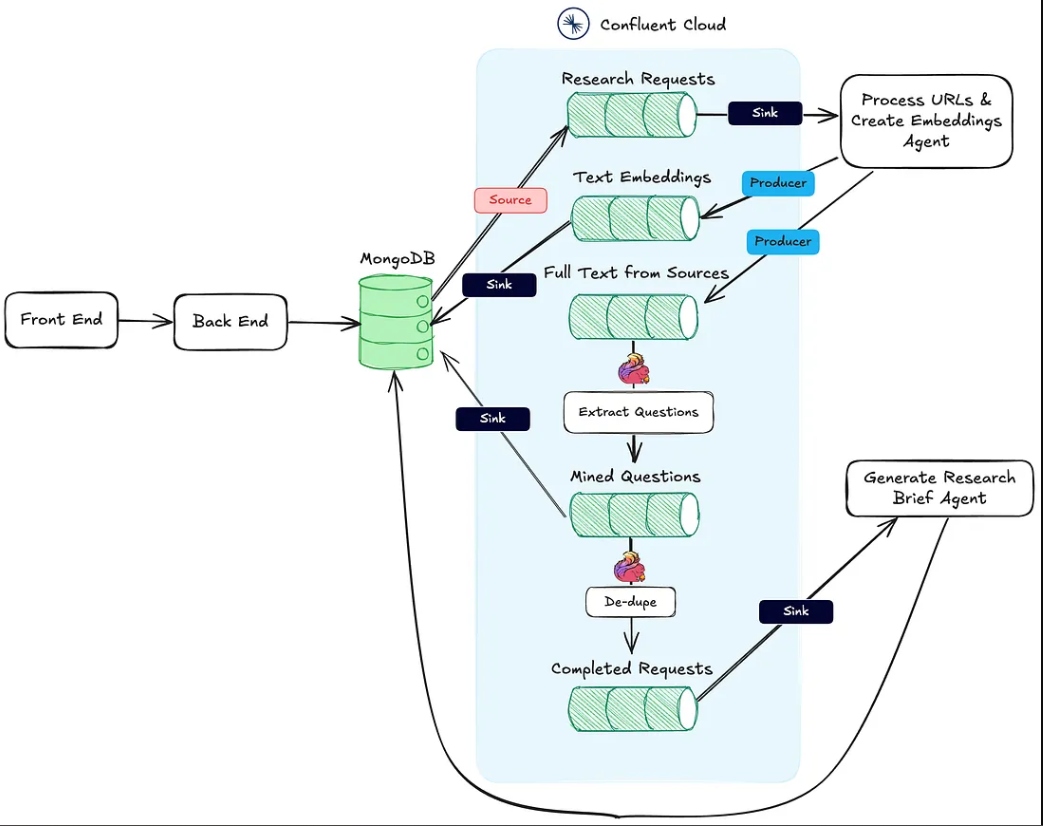
Ação #1 acima é suportada pelo endpoint de saída HTTP Processar URLs & Criar Agente de Incorporações.
A Ação #2 é realizada usando o Flink e o suporte ao modelo de IA integrado no Confluent Cloud.
Finalmente, a Ação #3 é executada pelo Agente de Geração de Resumo de Pesquisa, também um endpoint de saída HTTP, que é chamado após a conclusão das duas primeiras ações.
Nas seções seguintes, discuto cada uma dessas ações em detalhes.
O Agente de Processamento de URLs e Criação de Incorporações
Este agente é responsável por extrair texto das URLs de origem da pesquisa e do pipeline de incorporação de vetores. Abaixo está o fluxo de alto nível do que está acontecendo nos bastidores para processar os materiais de pesquisa.

Uma vez que um pacote de pesquisa é criado pelo usuário e salvo no MongoDB, um conector de origem do MongoDB produz mensagens para um tópico do Kafka chamado research-requests. Isso é o que inicia o fluxo de trabalho do agente.
Cada solicitação de post para o endpoint HTTP contém as URLs da solicitação de pesquisa e a chave primária na coleção de pacotes de pesquisa do MongoDB.
O agente percorre cada URL e, se não for um podcast da Apple, ele recupera o HTML da página inteira. Como não conheço a estrutura da página, não posso confiar em bibliotecas de análise HTML para encontrar o texto relevante. Em vez disso, envio o texto da página para o modelo gpt-4o-mini com uma temperatura de zero usando o prompt abaixo para obter o que preciso.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
Para podcasts, preciso fazer um pouco mais de trabalho.
Engenharia Reversa de URLs de Podcasts da Apple
Para extrair dados de episódios de podcast, primeiro precisamos converter o áudio em texto usando o modelo Whisper. Mas antes disso, precisamos localizar o arquivo MP3 real de cada episódio de podcast, baixá-lo e dividi-lo em pedaços de 25MB ou menos (o tamanho máximo para Whisper).
O desafio é que a Apple não fornece um link MP3 direto para os episódios de seu podcast. No entanto, o arquivo MP3 está disponível no feed RSS original do podcast, e podemos encontrar esse feed programaticamente usando o ID do podcast da Apple.
Por exemplo, no URL abaixo, a parte numérica após /id é o ID único do podcast:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
Usando a API da Apple, podemos procurar o ID do podcast e obter uma resposta JSON contendo o URL do feed RSS:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
Uma vez que temos o XML do feed RSS, procuramos nele o episódio específico. Como só temos o URL do episódio da Apple (e não o título real), usamos o slug do título do URL para localizar o episódio no feed e obter seu URL MP3.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
Agora, com o texto de postagens de blog, sites e arquivos MP3 disponíveis, o agente usa o divisor de texto de caracteres recursivo da LangChain para dividir o texto em pedaços e gerar os embeddings a partir desses pedaços. Os pedaços são publicados no tópico text-embeddings e direcionados para o MongoDB.
- Observação: Eu optei por usar o MongoDB tanto como banco de dados de aplicativos quanto como banco de vetores. No entanto, devido à abordagem EDA que adotei, esses sistemas podem ser facilmente separados, e é apenas uma questão de trocar o conector de destino do tópico de Text Embeddings.
Além de criar e publicar os embeddings, o agente também publica o texto das fontes em um tópico chamado full-text-from-sources. A publicação neste tópico inicia a Ação #2.
Extraindo Perguntas com Flink e OpenAI
O Apache Flink é um framework de processamento de stream de código aberto construído para lidar com grandes volumes de dados em tempo real, ideal para aplicações de alto rendimento e baixa latência. Ao combinar o Flink com o Confluent, podemos trazer LLMs como o GPT da OpenAI diretamente para fluxos de trabalho de streaming. Essa integração possibilita fluxos de trabalho RAG em tempo real, garantindo que o processo de extração de perguntas funcione com os dados mais recentes disponíveis.
Ter o texto original da fonte no fluxo também nos permite introduzir novos fluxos de trabalho posteriormente que usem os mesmos dados, aprimorando o processo de geração de resumos de pesquisa ou enviando-o para serviços downstream como um data warehouse. Essa configuração flexível nos permite adicionar gradualmente recursos adicionais de IA e não IA ao longo do tempo sem precisar revisar completamente o pipeline principal.
No PodPrep AI, eu uso o Flink para extrair perguntas do texto obtido a partir de URLs de origem.
Configurar o Flink para chamar um LLM envolve configurar uma conexão através da CLI do Confluent. Abaixo está um exemplo de comando para configurar uma conexão com a OpenAI, embora haja várias opções disponíveis.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
Uma vez que a conexão esteja estabelecida, posso criar um modelo tanto no Console do Cloud quanto no shell do Flink SQL. Para extração de questões, configuro o modelo adequadamente.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
Com o modelo pronto, utilizo a função ml_predict integrada ao Flink para gerar questões a partir do material de origem, escrevendo a saída em um fluxo chamado mined-questions, que sincroniza com o MongoDB para uso posterior.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
O Flink também ajuda a rastrear quando todos os materiais de pesquisa foram processados, acionando a geração do resumo da pesquisa. Isso é feito escrevendo em um fluxo completed-requests uma vez que os URLs em mined-questions correspondem aos da fonte de textos completos.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
À medida que as mensagens são escritas em completed-requests, o ID único do pacote de pesquisa é enviado para o Agente Gerador de Resumo de Pesquisa.
O Agente Gerador de Resumo de Pesquisa
Este agente reúne todos os materiais de pesquisa mais relevantes disponíveis e utiliza um LLM para criar um resumo da pesquisa. Abaixo está o fluxo de eventos de alto nível que ocorrem para criar um resumo da pesquisa.

Diagrama de fluxo para o Agente Gerador de Resumo de Pesquisa
Vamos analisar alguns desses passos. Para construir o prompt para o LLM, eu combino as questões extraídas, o tópico, o nome do convidado, o nome da empresa, um prompt do sistema para orientação e o contexto armazenado no banco de dados vetorial que é semanticamente mais similar ao tópico do podcast.
Porque o pacote de pesquisa tem informações contextuais limitadas, é desafiador extrair o contexto mais relevante diretamente do armazenamento de vetores. Para solucionar isso, tenho o LLM gerar uma consulta de pesquisa para localizar o conteúdo mais adequado, como mostrado no nó “Criar Consulta de Pesquisa” no diagrama.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
Usando a consulta gerada pelo LLM, crio uma incorporação e pesquiso o MongoDB por meio de um índice de vetor, filtrando pelo bundleId para limitar a pesquisa a materiais relevantes para o podcast específico.
Com as melhores informações de contexto identificadas, elaboro um prompt e gero o resumo da pesquisa, salvando o resultado no MongoDB para a aplicação web exibir.
Coisas a Observar na Implementação
Eu desenvolvi tanto a aplicação front-end para o PodPrep AI quanto os agentes em Javascript, mas em um cenário do mundo real, o agente provavelmente estaria em uma linguagem diferente como Python. Além disso, para simplicidade, tanto o Agente de Processamento de URLs e Criação de Incorporações quanto o Agente de Geração de Resumo de Pesquisa estão dentro do mesmo projeto sendo executados no mesmo servidor web. Em um sistema de produção real, esses poderiam ser funções serverless, executando de forma independente.
Pensamentos Finais
A construção do PodPrep AI destaca como uma arquitetura orientada a eventos permite que aplicações de IA do mundo real dimensionem e se adaptem suavemente. Com Flink e Confluent, criei um sistema que processa dados em tempo real, impulsionando um fluxo de trabalho orientado por IA sem dependências rígidas. Essa abordagem desacoplada permite que os componentes operem de forma independente, mas permaneçam conectados por meio de fluxos de eventos — essencial para aplicações complexas e distribuídas, onde diferentes equipes gerenciam várias partes do sistema.
No ambiente orientado por IA de hoje, acessar dados frescos em tempo real em diferentes sistemas é essencial. A EDA atua como um “sistema nervoso central” para os dados, permitindo integração e flexibilidade contínuas à medida que o sistema se expande.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink