













Na era da transformação digital, as empresas necessitam de soluções de banco de dados que ofereçam escalabilidade e confiabilidade. O AWS Aurora, um banco de dados relacional que suporta MySQL e PostgreSQL, tornou-se uma escolha popular para empresas à procura de performance alta, durabilidade e eficiência de custo. Este artigo explora os benefícios do AWS Aurora e apresenta um exemplo real de como ele é usado em um plataforma de mídia social online.
Comparação do AWS Aurora: Benefícios vs. Desafios
| Key Benefits | Description | Challenges | Description |
|---|---|---|---|
| High Performance and Scalability |
O design do Aurora separa as funções de armazenamento e computação, entregando um bandwidth cinco vezes maior do que o MySQL e duas vezes o de PostgreSQL. Ele garante um desempenho consistente mesmo durante períodos de tráfego máximo, utilizando as capacidades de auto-escalamento. |
Financial Implications | The complex pricing structure can lead to high costs due to charges for instance, storage, replicas, and support. |
| Durability and Availability | Data in Aurora is distributed across multiple Availability Zones (AZs), with six copies stored across three AZs to ensure data availability and resilience. Failover mechanisms are automated to facilitate durable writes, incorporating retry logic for transactional integrity. | Dependency Risks | A significant dependence on AWS services may lead to vendor lock-in, making it more challenging and costly to migrate to alternative platforms in the future. |
| Security | Aurora offers robust security with encryption for data at rest and in transit, network isolation via Amazon VPC, and precise access control through AWS IAM. | Migration Challenges | Data transfer can be lengthy and may involve downtime. Compatibility issues might require modifications to existing code. |
| Cost Efficiency | Aurora’s flexible pricing structure enables businesses to reduce database costs. The automatic scaling feature guarantees that you are charged based on the actual resources utilized, resulting in a cost-effective solution for varying workloads. | Training Requirements | Teams need to dedicate a significant amount of time and resources to acquiring the necessary knowledge of AWS-specific tools and optimal practices to effectively manage Aurora. |
| Performance Optimization | Auto-scaling and read replicas help optimize performance by dynamically adjusting resources and distributing read traffic. | Performance Impacts | Latency may be introduced due to abstraction layers and networking between Aurora instances and other AWS services, impacting latency-sensitive applications. |
Passos de Implementação
1. Configurar Cluster Aurora
- Acesse o console de gerenciamento do AWS.
- Escolha a Amazon Aurora e selecione “Criar Banco de Dados”.
- Selecione o motor apropriado (MySQL ou PostgreSQL) e configure as configurações da instância.
2. Ativar Auto Escalamento
- Configure políticas de auto-escalamento para computação e armazenamento.
- Defina limites para escalonamento ascendente e descendente baseados em padrões de tráfego.
3. Configurar Implantação Multi-AZ
- Ative a implantação Multi-AZ para garantir alta disponibilidade.
- Configure cópias de backup e snapshots automáticos para proteção de dados.
4. Crie Cópias de Leitura de Replicação
- Adicione cópias de leitura de replicação para distribuir o tráfego de leitura.
- Configure os pontos de extremidade do aplicativo para equilibrar as solicitações de leitura entre as réplicas.
Exemplo funcional: Plataforma de Media Social Online
Uma plataforma de media social online, “SocialBuzz,” conecta milhões de usuários globalmente. Para atender aos requisitos de tratamento de volume de tráfego alto, fornecendo respostas de baixa latência e garantindo a durabilidade dos dados, SocialBuzz precisa de uma solução de banco de dados confiável. O Aurora AWS é a escolha ideal para atingir esses necessidades:
- Visão de arquitetura: SocialBuzz usa o Aurora para suas necessidades de banco de dados principal, aproveitando os motores MySQL e PostgreSQL para diferentes componentes. Perfis de usuários, posts, comentários e interações são armazenados em Aurora, aproveitando sua alta performance eescalabilidade.
- Escalação em ação: Durante altos momentos de uso, como quando um post viral é compartilhado, SocialBuzz Experiencia uma explosão de tráfego. A funcionalidade de auto-escalamento de Aurora ajusta os recursos de computação para lidar com a carga aumentada, garantindo experiências de usuário sem degradação de desempenho.
- Alta disponibilidade: Para garantir serviço ininterrompido, SocialBuzz configura o Aurora em um setup Multi-AZ. Isso garante que mesmo se uma AZ experienciar um problema, o banco de dados permaneça disponível, fornecendo um mecanismo robusto de recuperação. As cópias de backup e snapshots automatizadas de Aurora ainda melhoram a proteção dos dados.
- Otimização de desempenho: SocialBuzz implementa réplicas de leitura em Aurora para distribuir o tráfego de leitura, reduzindo a carga na instância primária. Essa configuração permite a rápida recuperação de dados, permitindo funcionalidades como notificações em tempo real e atualizações de mensagens instantâneas.
- Gerenciamento de custos: Ao utilizar o modelo de pagamento conforme uso de Aurora, SocialBuzz gerencia seus custos operacionais de forma eficiente. Durante as horas de pico, os recursos são dimensionados para baixo, reduzindo gastos. Além disso, a opção sem servidor de Aurora permite que SocialBuzz abraçhe cargas de trabalho impredecíveis sem sobreprovisionar recursos.
Visão geral
Vamos mergulhar mais fundo em como uma plataforma social online, SocialBuzz, aproveita o AWS Aurora para gerenciamento de banco de dados escalável e confiável. Incluiremos um exemplo de código para implementação, um conjunto de dados de exemplo e um diagrama de fluxo para ilustrar o processo.
Visão geral da arquitetura
SocialBuzz utiliza o AWS Aurora para o armazenamento e gerenciamento de perfil de usuários, posts, comentários e interações. A arquitetura do sistema é composta pelos seguintes elementos:
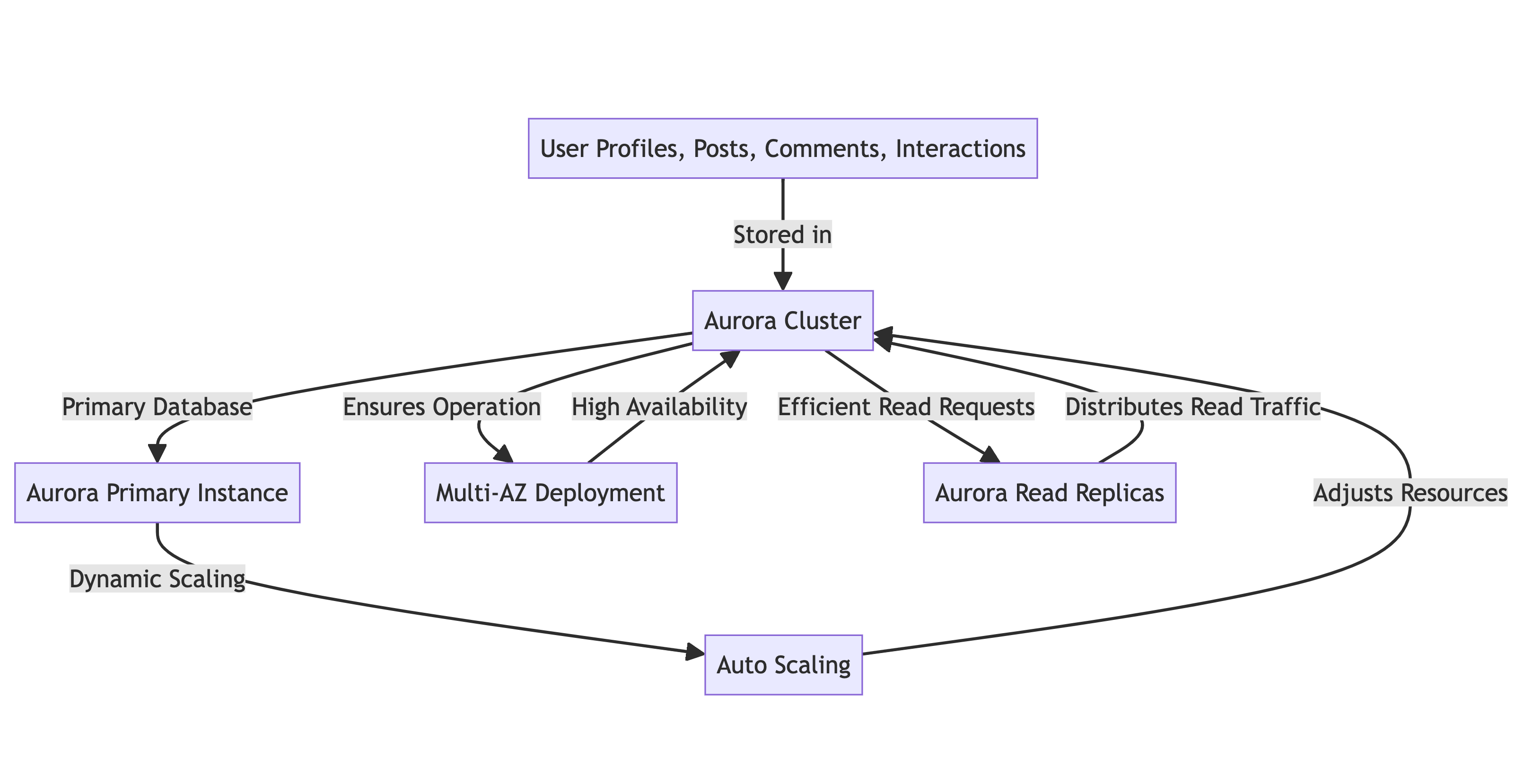
- Banco de dados primário: Cluster Aurora
- Ajuste de recursos: Funcionalidade de Auto Scaling que dimensiona os recursos de forma dinâmica de acordo com a demanda
- Alta disponibilidade: Implantação Multi-AZ para garantir operação contínua
- Distribuição de tráfego de leitura: Réplicas de Leitura para distribuição eficiente de pedidos de leitura
Diagrama de fluxo
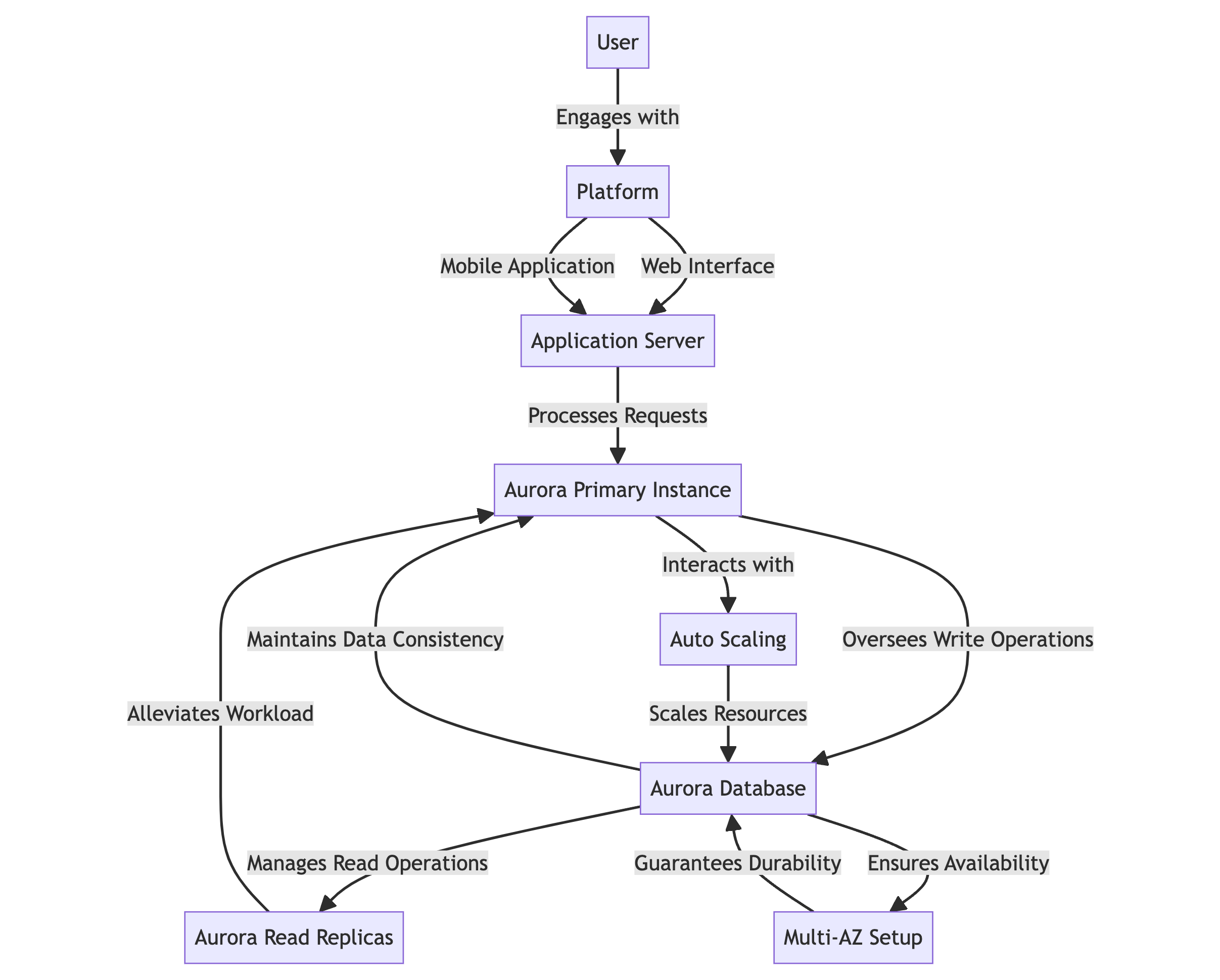
- O usuário se compromete com a plataforma através da interface web ou da aplicação móvel.
- O servidor de aplicação processa pedidos e interage com o banco de dados Aurora.
- A Instância Primária Aurora supervisiona as operações de gravação e mantém a consistência dos dados.
- As Replicas de Leitura Aurora gerenciam as operações de leitura, aliviando a carga na instância primária.
- O Auto-escalamento ajusta automaticamente recursos em resposta a níveis de tráfego variáveis.
- A configuração Multi-AZ garante a disponibilidade e a durabilidade dos dados em várias zonas de disponibilidade.
Instância AWS
- Escolha o Padrão para criar um cluster Aurora (MySQL).

- Escolha um modelo, credenciais e configurações de nome de base de dados.
- A configuração da instância, disponibilidade e conectividade são fatores importantes a serem considerados. Decidi não conectar o EC2 de acordo com os requisitos.
- Configurações de VPC: Habilite as réplicas de leitura e as tags para identificar o banco de dados.
- Selecione as autorizações de banco de dados e a vigilância, e finalmente, você receberá a estimativa de custo mensal do banco de dados.
Exemplo de Código
Nós prosseguiremos com a configuração do cluster Aurora para SocialBuzz.
Configuração de Cluster Aurora
import boto3
# Iniciar uma sessão usando o Amazon RDS
client = boto3.client('rds', region_name='us-west-2')Criar Cluster de Banco de Dados Aurora
response = client.create_db_cluster(
DBClusterIdentifier='socialbuzz-cluster',
Engine='aurora-mysql',
MasterUsername='admin',
MasterUserPassword='password',
BackupRetentionPeriod=7,
VpcSecurityGroupIds=['sg-0a1b2c3d4e5f6g7h'],
DBSubnetGroupName='default'
)
print(response)
Criando Instância Aurora
response = client.create_db_instance(
DBInstanceIdentifier='socialbuzz-instance',
DBClusterIdentifier='socialbuzz-cluster',
DBInstanceClass='db.r5.large',
Engine='aurora-mysql',
PubliclyAccessible=True
)
print(response)
Conjunto de Dados de Amostra
Aqui está um simples conjunto de dados para representar usuários, posts e comentários:
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE posts (
post_id INT PRIMARY KEY,
user_id INT,
content TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
CREATE TABLE comments (
comment_id INT PRIMARY KEY,
post_id INT,
user_id INT,
comment TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(post_id),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- Inserir dados de amostra
INSERT INTO users (user_id, username, email) VALUES
(1, 'john_doe', '[email protected]'),
(2, 'jane_doe', '[email protected]');
INSERT INTO posts (post_id, user_id, content) VALUES
(1, 1, 'Hello World!'),
(2, 2, 'This is my first post.');
INSERT INTO comments (comment_id, post_id, user_id, comment) VALUES
(1, 1, 2, 'Nice post!'),
(2, 2, 1, 'Welcome to the platform!');Lógica de Aplicação para Operações de Leitura/Escrita
import pymysql
# Conexão de Banco de Dados
connection = pymysql.connect(
host='socialbuzz-cluster.cluster-xyz.us-west-2.rds.amazonaws.com',
user='admin',
password='password',
database='socialbuzz'
)
# Operação de Escrita
def create_post(user_id, content):
with connection.cursor() as cursor:
sql = "INSERT INTO posts (user_id, content) VALUES (%s, %s)"
cursor.execute(sql, (user_id, content))
connection.commit()
# Operação de Leitura
def get_posts():
with connection.cursor() as cursor:
sql = "SELECT * FROM posts"
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
# Exemplo de Uso
create_post(1, 'Exploring AWS Aurora!')
get_posts()Conclusão
AWS Aurora oferece uma solução de gerenciamento de banco de dados robusta, escalável e confiável. O caso de estudo da SocialBuzz demonstra como empresas podem usar as capacidades inovadoras de Aurora para gerenciar tráfego intenso, garantir integridade dos dados e melhorar eficiência. Atendendo a métodos recomendados e deployando infraestrutura apropriada, as empresas podem usar plenamente as capacidades do AWS Aurora para fomentar desenvolvimento e criatividade.
Source:
https://dzone.com/articles/aws-aurora-for-scalable-and-reliable-databases