













Cada organização orientada por dados possui cargas operacionais e analíticas. Uma abordagem de melhor em sua classe surge com várias plataformas de dados, incluindo streaming de dados, lagos de dados, soluções de data warehouse e lakehouse, e serviços em nuvem. Um framework de formato de tabela aberto como Apache Iceberg é essencial na arquitetura empresarial para garantir a gestão e compartilhamento confiáveis de dados, evolução de esquema sem problemas, manuseio eficiente de grandes conjuntos de dados, armazenamento economicamente eficiente e fornecer forte suporte para transações ACID e consultas de viagem no tempo.
Este artigo explora tendências de mercado; adoção de frameworks de formato de tabela como Iceberg, Hudi, Paimon, Delta Lake e XTable; e a estratégia de produto de alguns dos principais fornecedores de plataformas de dados, como Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka/Flink), Amazon Athena e Google BigQuery.
O que é um Formato de Tabela Aberto para uma Plataforma de Dados?
Um formato de tabela aberto ajuda a manter a integridade dos dados, otimizar o desempenho de consultas e garantir uma compreensão clara dos dados armazenados dentro da plataforma.
O formato de tabela aberto para plataformas de dados geralmente inclui uma estrutura bem definida com componentes específicos que garantem que os dados estejam organizados, acessíveis e facilmente consultáveis. Um formato de tabela típico contém um nome de tabela, nomes de colunas, tipos de dados, chaves primárias e estrangeiras, índices e restrições.
Este não é um conceito novo. Seu banco de dados favorito de décadas — como Oracle, IBM DB2 (até em mainframe) ou PostgreSQL — usa os mesmos princípios. No entanto, as exigências e desafios mudaram um pouco para os data warehouses na nuvem, data lakes e lakehouses em termos de escalabilidade, desempenho e capacidades de consulta.
Vantagens de um “Formato de Tabela Lakehouse” Como Apache Iceberg
Toda parte de uma organização passa a ser movida a dados. A consequência são conjuntos de dados extensivos, compartilhamento de dados com produtos de dados entre unidades de negócios e novas exigências para processamento de dados em tempo quase real.
Apache Iceberg oferece muitos benefícios para a arquitetura corporativa:
- Armazenamento único: Os dados são armazenados uma vez (provenientes de várias fontes de dados), o que reduz custo e complexidade
- Interoperabilidade: Acesso sem esforços de integração de qualquer motor analítico
- Todos os dados: Unificar cargas de trabalho operacionais e analíticas (sistemas transacionais, logs de big data/IoT/clickstream, APIs móveis, interfaces B2B de terceiros, etc.)
- Independência de fornecedor: Trabalhar com qualquer motor de análise favorito (seja em tempo quase real, lote ou baseado em API)
Apache Hudi e Delta Lake fornecem as mesmas características. No entanto, o Delta Lake é principalmente impulsionado por Databricks como um único fornecedor.
Formato de Tabela e Interface de Catálogo
É importante entender que discussões sobre Apache Iceberg ou frameworks de formato de tabela semelhantes incluem dois conceitos: formato de tabela e interface de catálogo! Como usuário final da tecnologia, você precisa dos dois!
O projeto Apache Iceberg implementa o formato, mas somente fornece uma especificação (mas não implementação) para o catálogo:
- O formato de tabela define como os dados são organizados, armazenados e gerenciados dentro de uma tabela.
- A interface de catálogo gerencia os metadados das tabelas e fornece uma camada de abstração para acessar tabelas em um data lake.
A documentação do Apache Iceberg explora os conceitos em muito mais detalhes, com base neste diagrama:
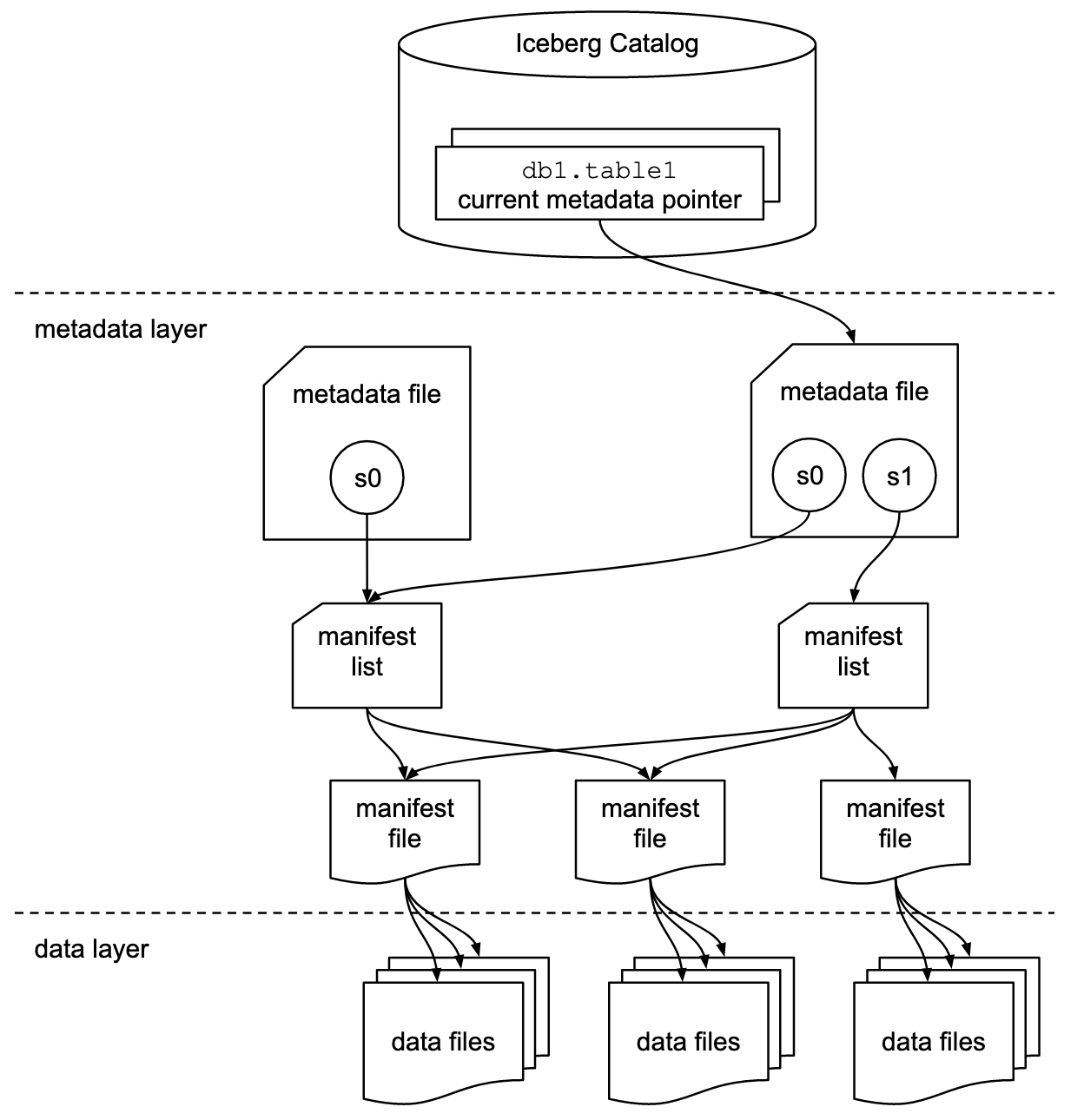
As organizações usam várias implementações para a interface de catálogo do Iceberg. Cada uma integra com diferentes armazenamentos e serviços de metadados. As principais implementações incluem:
- Catálogo Hadoop: Usa o Hadoop Distributed File System (HDFS) ou outros sistemas de arquivos compatíveis para armazenar metadados. Adequado para ambientes que já usam Hadoop.
- Catálogo Hive: Integra com o Apache Hive Metastore para gerenciar metadados de tabela. Ideal para usuários que utilizam Hive para sua gestão de metadados.
- Catálogo AWS Glue: Usa o AWS Glue Data Catalog para armazenamento de metadados. Projetado para usuários que operam dentro do ecossistema AWS.
- Catálogo REST: Fornece uma interface RESTful para operações de catálogo via HTTP. Permite a integração com serviços de metadados personalizados ou de terceiros.
- Catálogo Nessie: Utiliza o Projeto Nessie, que oferece uma experiência semelhante ao Git para gerenciar dados.
O momentum e a crescente adoção do Apache Iceberg motivam muitos fornecedores de plataformas de dados a implementarem seu próprio catálogo Iceberg. Discuto algumas estratégias na seção abaixo sobre estratégias de plataformas de dados e fornecedores de nuvem, incluindo o Polaris da Snowflake, o Unity da Databricks e o Tableflow da Confluent.
Suporte de Primeira Classe ao Iceberg vs. Conector Iceberg
Atente que suportar o Apache Iceberg (ou Hudi/Delta Lake) vai muito além de simplesmente fornecer um conector e integração com o formato de tabela via API. Fornecedores e serviços em nuvem se diferenciam por recursos avançados como mapeamento automático entre formatos de dados, SLAs críticos, viagem no tempo, interfaces intuitivas e outros.
Vamos olhar um exemplo: Integração entre Apache Kafka e Iceberg. Vários conectores Kafka Connect já foram implementados. No entanto, aqui estão os benefícios de usar uma integração de primeira classe com Iceberg (por exemplo, o Tableflow da Confluent) em comparação com usar apenas um conector Kafka Connect:
- Sem configuração de conector
- Sem consumo através de conector
- Manutenção integrada (compactação, coleta de lixo, gerenciamento de instantâneos)
- Evolução automática de esquema
- Sincronização de serviço de catálogo externo
- Operações mais simples (em uma solução SaaS gerenciada integralmente, é serverless e não requer qualquer escalonamento ou operações pelo usuário final)
Vantagens semelhantes se aplicam a outras plataformas de dados e à integração potencial de primeira classe em comparação com a fornecimento de conectores simples.
Formato Aberto de Tabela para um Data Lake/Lakehouse usando Apache Iceberg, Apache Hudi e Delta Lake
O objetivo geral dos frameworks de formato de tabela, como Apache Iceberg, Apache Hudi e Delta Lake, é melhorar a funcionalidade e a confiabilidade dos data lakes abordando desafios comuns associados à gestão de dados em larga escala. Esses frameworks ajudam a:
- Melhorar a gestão de dados
- Facilitar o manuseio mais fácil da ingestão, armazenamento e recuperação de dados em data lakes.
- Permitir uma organização e armazenamento de dados eficiente, suportando melhor desempenho e escalabilidade.
- Garantir a consistência dos dados
- Fornecer mecanismos para transações ACID, garantindo que os dados permaneçam consistentes e confiáveis mesmo durante operações de leitura e escrita concorrentes.
- Suportar isolamento de snapshot, permitindo que os usuários visualizem um estado consistente dos dados a qualquer ponto no tempo.
- Support schema evolution
- Permite mudanças no esquema de dados (como adicionar, renomear ou remover colunas) sem interromper dados existentes ou exigir migrações complexas.
- Optimize query performance
- Implementa estratégias avançadas de indexação e particionamento para melhorar a velocidade e eficiência das consultas de dados.
- Enhance data governance
- Fornece ferramentas para melhor rastreamento e gestão da linhagem de dados, versionamento e auditoria, que são cruciais para manter a qualidade e conformidade dos dados.
Ao abordar esses objetivos, frameworks de formato de tabela como Apache Iceberg, Apache Hudi e Delta Lake ajudam organizações a construir lagos de dados e lakehouses mais robustos, escaláveis e confiáveis. Engenheiros de dados, cientistas de dados e analistas de negócios utilizam ferramentas de análise, AI/ML ou relatórios/visualizações sobre o formato de tabela para gerenciar e analisar grandes volumes de dados.
Comparação de Apache Iceberg, Hudi, Paimon e Delta Lake
Não farei uma comparação dos frameworks de formato de tabela Apache Iceberg, Apache Hudi, Apache Paimon e Delta Lake aqui. Muitos experts já escreveram sobre isso. Cada framework de formato de tabela tem suas forças e benefícios únicos. Mas atualizações são necessárias a cada mês devido à evolução e inovação rápidas, adicionando novas melhorias e capacidades dentro desses frameworks.
Aqui está um resumo do que vejo em vários posts de blogs sobre as quatro opções:
- Apache Iceberg: Excelente em evolução de esquema e partição, gerenciamento eficiente de metadados e compatibilidade ampla com vários motores de processamento de dados.
- Apache Hudi: Mais indicado para ingestão de dados em tempo real e upserts, com fortes capacidades de captura de mudanças de dados e versionamento de dados.
- Apache Paimon: Um formato de lago que permite construir uma arquitetura de lakehouse em tempo real com Flink e Spark para operações de streaming e batch.
- Delta Lake: Fornece transações ACID robustas, imposição de esquema e recursos de viagem no tempo, tornando-o ideal para manter a qualidade e integridade dos dados.
Um ponto de decisão-chave pode ser que o Delta Lake não é impulsionado por uma comunidade ampla como Iceberg e Hudi, mas principalmente pela Databricks como um único fornecedor por trás disso.
Apache XTable como Framework de Interoperabilidade Cruzada de Tabelas Suportando Iceberg, Hudi e Delta Lake
Os usuários têm muitas escolhas. XTable, anteriormente conhecido como OneTable, é mais uma framework de tabelas incubando sob a licença open-source Apache para interoperar de forma transparente entre tabelas de Apache Hudi, Delta Lake e Apache Iceberg.
Apache XTable:
- Fornece interoperabilidade omnidirecional entre tabelas de formatos de data lakehouse.
- É não um novo ou formato separado. O Apache XTable fornece abstrações e ferramentas para a tradução de metadados de formatos de tabelas de data lakehouse.
Talvez o Apache XTable seja a resposta para fornecer opções para plataformas de dados específicas e fornecedores de nuvem, enquanto ainda fornece integração e interoperabilidade simples.
Mas seja cuidadoso: Um wrapper sobre diferentes tecnologias não é uma bala de prata. Vimos isso há anos quando o Apache Beam emergiu. Apache Beam é um modelo unificado de código aberto e um conjunto de SDKs específicos de linguagem para definir e executar workflows de ingestão e processamento de dados. Ele suporta uma variedade de motores de processamento de stream, como Flink, Spark e Samza. O principal impulsionador por trás do Apache Beam é o Google, que permite a migração de workflows no Google Cloud Dataflow. No entanto, as limitações são enormes, pois tal wrapper precisa encontrar o menor denominador comum de recursos suportados. E a principal vantagem da maioria dos frameworks é o 20% que não se encaixa em tal wrapper. Por esses motivos, por exemplo, Kafka Streams não suporta Apache Beam porque teria requerido muitas limitações de design.
Adoção de Mercado de Frameworks de Formato de Tabela
Primeiro de tudo, ainda estamos nas primeiras etapas. Estamos ainda no gatilho de inovação em termos do Ciclo Hype da Gartner, chegando ao pico das expectativas inflacionadas. A maioria das organizações está ainda avaliando, mas não adotando esses formatos de tabela em produção em toda a organização ainda.
Flashback: A Guerra dos Contêineres entre Kubernetes, Mesosphere e Cloud Foundry
O debate em torno do Apache Iceberg me lembra a guerra dos contêineres há alguns anos. O termo “Guerra dos Contêineres” se refere à competição e rivalidade entre diferentes tecnologias e plataformas de contêineres no domínio do desenvolvimento de software e infraestrutura de TI.
As três tecnologias concorrentes eram Kubernetes, Mesosphere e Cloud Foundry. Aqui está para onde isso foi:

Cloud Foundry e Mesosphere foram pioneiros, mas o Kubernetes ainda venceu a batalha. Por quê?Nunca entenderei todas as detalhes técnicos e diferenças. No final, se os três frameworks são bem parecidos, é tudo sobre:
- Adoção pela comunidade
- Tempo certo de lançamento de funcionalidades
- Bom marketing
- Sorte
- E alguns outros fatores
Mas é bom para a indústria de software ter um framework de código aberto líder para construir soluções e modelos de negócios em vez de três competindo.
Presente: A Guerra de Formatos de Tabela de Apache Iceberg vs. Hudi vs. Delta Lake
Obviamente, o Google Trends não é uma evidência estatística ou uma pesquisa sofisticada. Mas usei muito isso no passado como uma ferramenta intuitiva, simples e gratuita para analisar tendências de mercado. Portanto, também usei essa ferramenta para ver se as buscas no Google coincidem com minha experiência pessoal da adoção de mercado do Apache Iceberg, Hudi e Delta Lake (Apache XTable ainda é pequeno demais para ser adicionado):
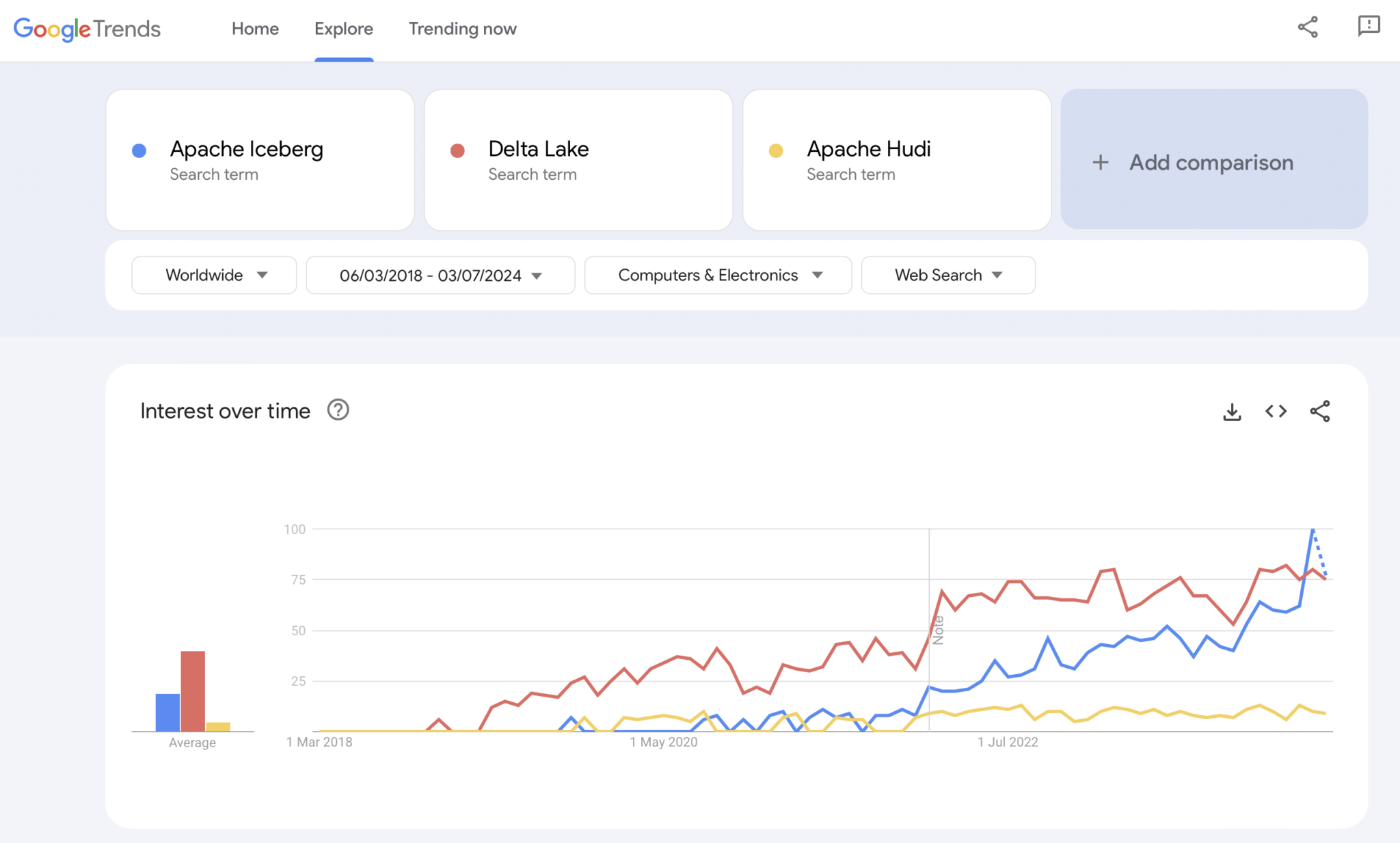
Nós obviamente vemos um padrão semelhante ao que as guerras de contêineres mostraram há alguns anos. Não tenho ideia para onde isso vai. E se uma tecnologia vence, ou se os frameworks se diferenciam o suficiente para provar que não há uma bala de prata, o futuro nos mostrará.
Minha opinião pessoal? Acho que o Apache Iceberg vai vencer a corrida. Por quê? Não posso discutir reasons técnicos. Apenas vejo muitos clientes em todas as indústrias falando sobre isso cada vez mais. E cada vez mais fornecedores começam a oferecer suporte. Mas vamos ver. Na verdade, eu não me importo com quem vence. No entanto, assim como nas guerras de contêineres, acho que é bom ter um único padrão e fornecedores se diferenciando com recursos ao redor disso, como é com o Kubernetes.
Com isso em mente, vamos explorar a estratégia atual das plataformas de dados líderes e provedores de nuvem em relação ao suporte ao formato de tabela em suas plataformas e serviços em nuvem.
Estratégias de Provedores de Plataforma de Dados e Nuvem para Apache Iceberg
Não farei nenhuma especulação nessa seção. A evolução dos frameworks de formato de tabela avança rapidamente, e as estratégias dos fornecedores mudam rapidamente. Por favor, consulte os sites dos fornecedores para obter as informações mais recentes. Mas aqui está o status quo sobre as estratégias das plataformas de dados e fornecedores de nuvem em relação ao suporte e integração do Apache Iceberg.
- Snowflake:
- Suporta Apache Iceberg há algum tempo já
- Adicionando melhorias em integrações e novos recursos regularmente
- Opções de armazenamento interno e externo (com trade-offs) como o armazenamento da Snowflake ou Amazon S3
- Anunciou o Polaris, uma implementação de catálogo open-source para Iceberg, com compromisso de suporte para integração bidirecional comunitária e independente de fornecedor
- Databricks:
-
Focando no Delta Lake como formato de tabela e (agora open sourced) Unity como catálogo
Adquiriu a Tabular, a principal empresa por trás do Apache Iceberg
Estratégia futura incerta de suporte à interface aberta do Iceberg (nos dois sentidos) ou apenas para alimentar dados em sua plataforma lakehouse e tecnologias como Delta Lake e Unity Catalog - Confluent:
-
Embutido Apache Iceberg como cidadão de primeira classe em sua plataforma de streaming de dados (o produto é chamado Tableflow)
Converte um Tópico Kafka e os metadados de esquema relacionados (ou seja, contrato de dados) em uma tabela Iceberg
- Mais plataformas de dados e mecanismos de análise de código aberto:
- A lista de tecnologias e serviços em nuvem que suportam Iceberg cresce a cada mês
- Alguns exemplos: Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst utilizando Trino (anteriormente PrestoSQL), Cloudera utilizando Impala, Imply utilizando Apache Druid, Fivetran
- Provedores de serviços em nuvem (AWS, Azure, Google Cloud, Alibaba):
- Estratégias e integrações diferentes, mas todos os provedores de nuvem aumentam o suporte ao Iceberg em seus serviços nos dias de hoje, por exemplo:
- Armazenamento de Objetos: Amazon S3, Azure Data Lake Storage (ALDS), Google Cloud Storage
- Catálogos: Específicos da nuvem como AWS Glue Catalog ou agnósticos a fornecedores como Project Nessie ou Hive Catalog
- Análise: Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
- Estratégias e integrações diferentes, mas todos os provedores de nuvem aumentam o suporte ao Iceberg em seus serviços nos dias de hoje, por exemplo:
Arquitetura Shift Left Com Kafka, Flink e Iceberg para Unificar Cargas de Trabalho Operacionais e Analíticas
A arquitetura shift left move o processamento de dados mais perto da fonte de dados, utilizando tecnologias de streaming de dados em tempo real como Apache Kafka e Flink para processar dados em movimento diretamente após sua ingestão. Esta abordagem reduz a latência e melhora a consistência e a qualidade dos dados.
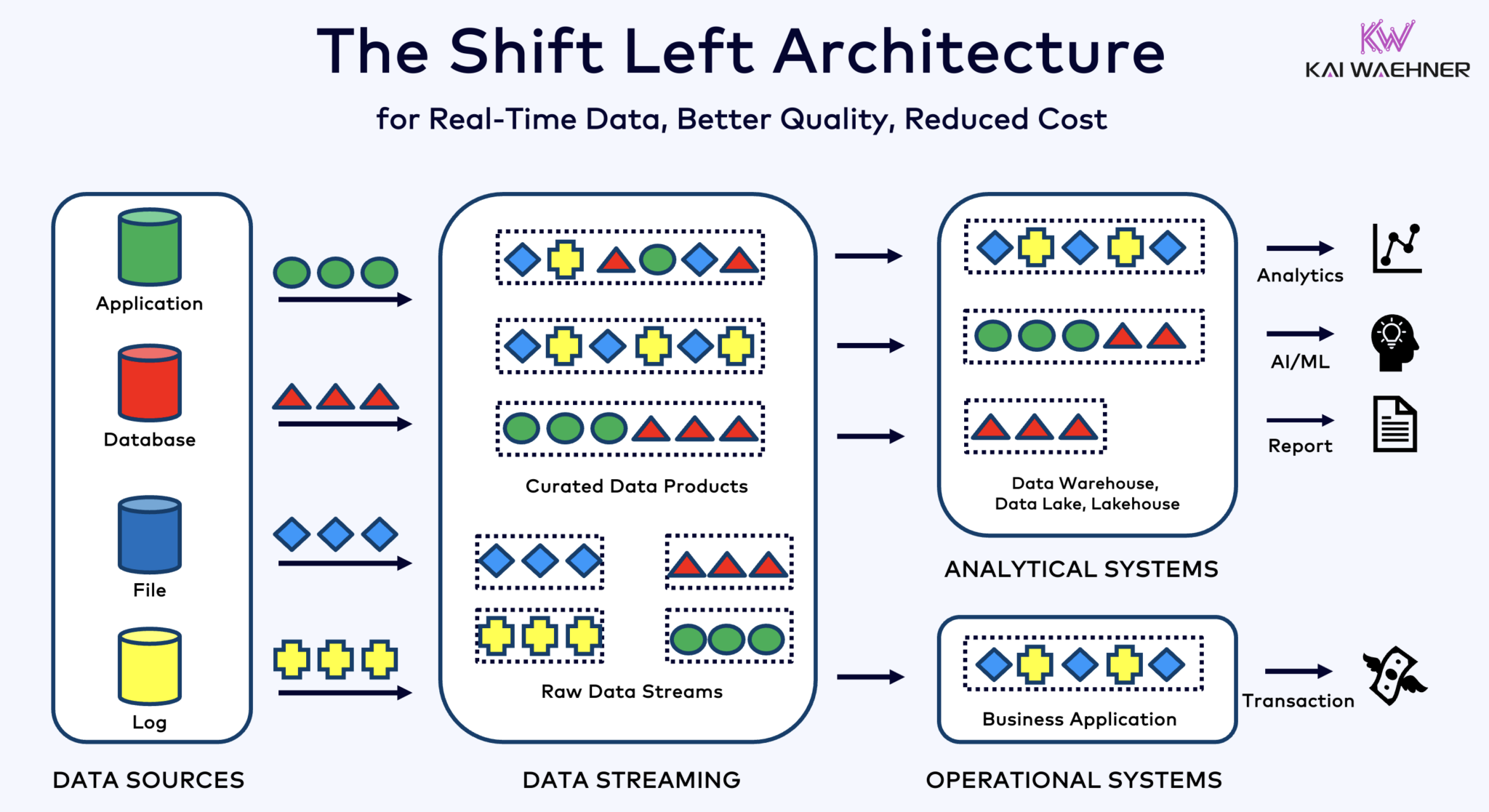
AO contrário de ETL e ELT, que envolvem processamento em lote com dados armazenados em repouso, a arquitetura shift left permite a captura e transformação de dados em tempo real. Alinha-se com o conceito zero-ETL ao tornar os dados imediatamente utilizáveis. Mas, em contraste ao zero-ETL, mover o processamento de dados para o lado esquerdo da arquitetura empresarial evita uma arquitetura complexa e difícil de manter, com muitas conexões ponto-a-ponto.
A arquitetura Shift Left também reduz a necessidade de ETL reverso, garantindo que os dados são ação em tempo real para sistemas operacionais e analíticos. No geral, essa arquitetura melhora a frescura dos dados, reduz custos e acelera o tempo de mercado para aplicativos驱动的 por dados. Saiba mais sobre esse conceito em meu post de blog sobre “A Arquitetura Shift Left.”
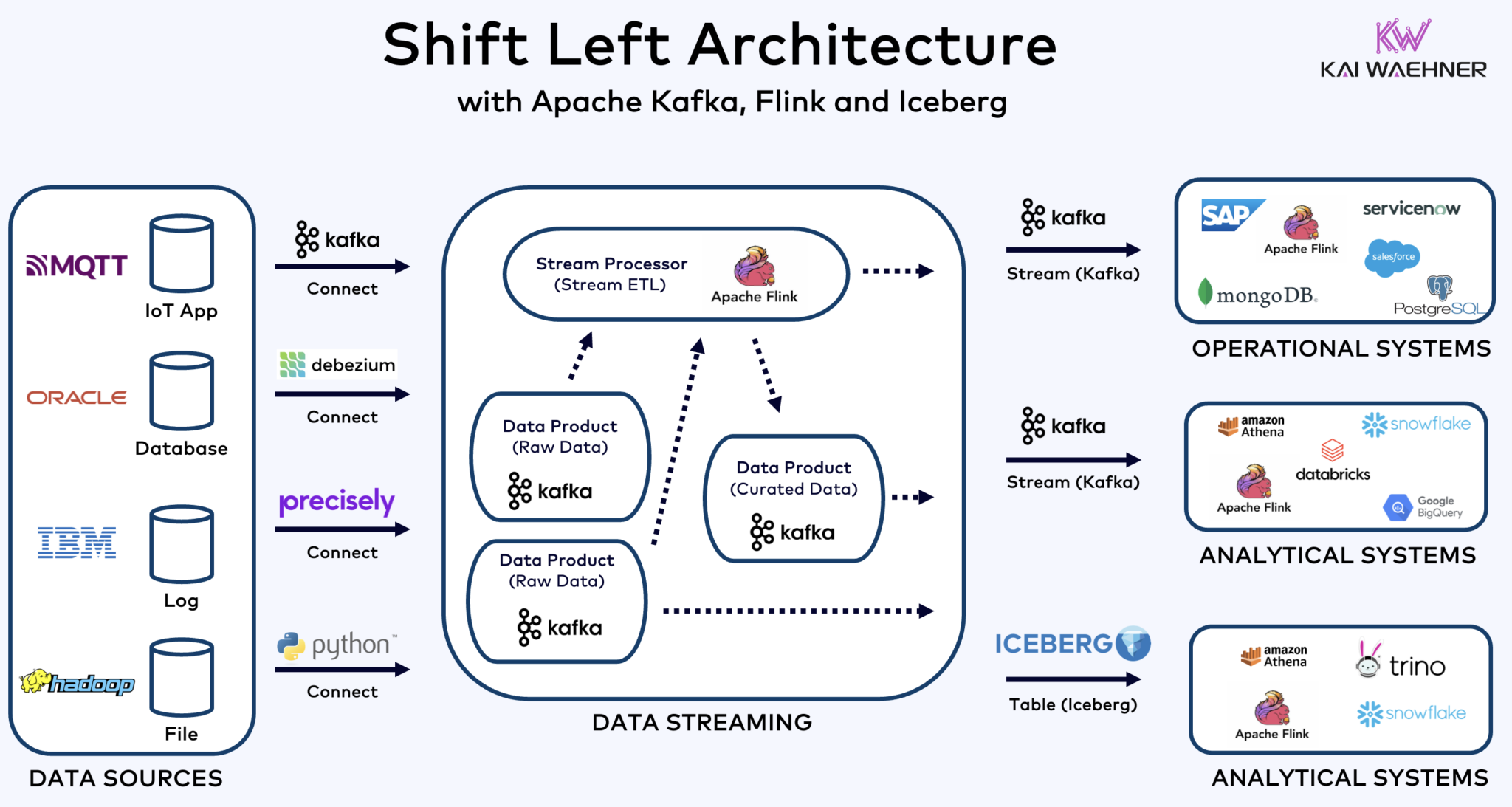
Apache Iceberg como Formato de Tabela Aberto e Catálogo para Compartilhamento de Dados Transparente Across Analytics Engines
Um formato de tabela aberto e catálogo introduz enormes benefícios na arquitetura da empresa:
- Interoperabilidade
- Liberdade de escolha de engines de analytics
- Tempo de mercado mais rápido
- Custo reduzido
Apache Iceberg parece estar se tornando o padrão de fato entre fornecedores e provedores de nuvem. No entanto, ainda está em estágio inicial e tecnologias concorrentes e de encapsulamento como Apache Hudi, Apache Paimon, Delta Lake e Apache XTable estão tentando ganhar tração também.
Iceberg e outros formatos de tabela aberta não são apenas uma grande vitória para o armazenamento único e a integração com várias plataformas de analytics/data/AI/ML, como Snowflake, Databricks, Google BigQuery, entre outros, mas também para a unificação das cargas de trabalho operacionais e analíticas usando streaming de dados com tecnologias como Apache Kafka e Flink. A arquitetura shift left é um benefício significativo para reduzir esforços, melhorar a qualidade e a consistência dos dados e permitir aplicativos e insights em tempo real em vez de em lote.
Finalmente, se ainda reste dúvida sobre quais são as diferenças entre o streaming de dados e os data lakes (e como eles se complementam), confira este vídeo de dez minutos:
Qual é sua estratégia de formato de tabela? Quais tecnologias e serviços em nuvem você conecta? Vamos conectar no LinkedIn e discutir isso!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming