













Gebruikers merken vaak gemakkelijker een daling in de prestaties bij lage gelijktijdigheid, terwijl verbeteringen in de prestaties bij hoge gelijktijdigheid vaak moeilijker te perceiveren zijn. Daarom is het handhaven van de prestaties bij lage gelijktijdigheid cruciaal, aangezien dit een directe invloed heeft op de gebruikerservaring en de bereidheid om te upgraden [1].
Volgens uitgebreide gebruikersfeedback hebben gebruikers over het algemeen een daling in de prestaties waargenomen na de upgrade naar MySQL 8.0, met name bij batch-insert- en join-operaties. Deze neerwaartse trend is duidelijker zichtbaar geworden in hogere versies van MySQL. Bovendien hebben enkele MySQL-enthousiastelingen en testers prestatieverlies gerapporteerd in meerdere sysbench-tests na de upgrade.
Kunnen deze prestatieproblemen worden vermeden? Of, specifieker, hoe moeten we de voortdurende trend van prestatieverlies wetenschappelijk beoordelen? Dit zijn belangrijke vragen om te overwegen.
Hoewel het officiële team blijft optimaliseren, kan de geleidelijke verslechtering van de prestaties niet worden genegeerd. In bepaalde scenario’s lijken er verbeteringen te zijn, maar dit betekent niet dat de prestaties in alle scenario’s even goed zijn geoptimaliseerd. Bovendien is het ook gemakkelijk om de prestaties voor specifieke scenario’s te optimaliseren ten koste van het verminderen van de prestaties in andere gebieden.
De Oorzaken van de Daling in MySQL-prestaties
Over het algemeen, naarmate er meer functies worden toegevoegd, groeit de codebase, en met de continue uitbreiding van functionaliteit wordt het steeds moeilijker om de prestaties te beheersen.
MySQL-ontwikkelaars merken vaak niet de afname in prestaties op, aangezien elke toevoeging aan de codebase slechts een zeer kleine afname in prestaties tot gevolg heeft. Na verloop van tijd stapelen deze kleine afnames zich op, resulterend in een significante cumulatieve effect, waardoor gebruikers een merkbare prestatievermindering waarnemen in nieuwere versies van MySQL.
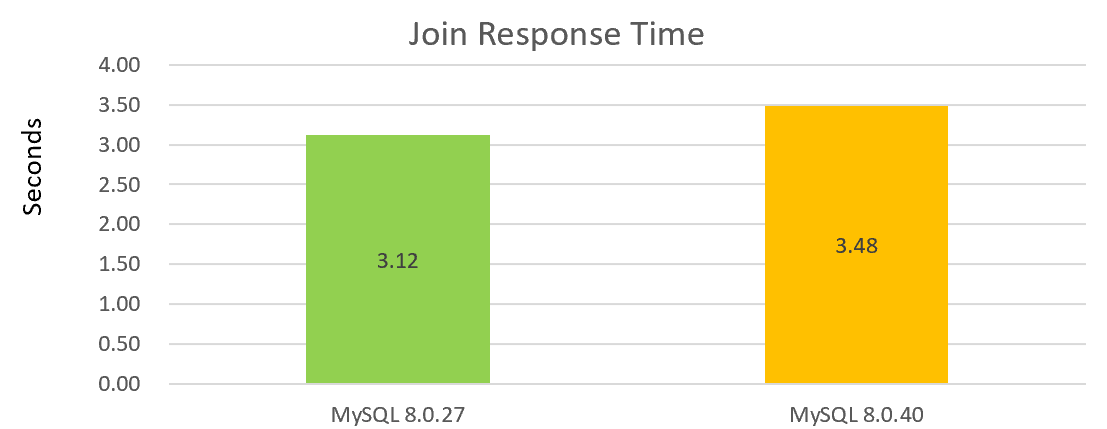
Als voorbeeld toont de volgende figuur de prestaties van een eenvoudige enkele join-operatie, waarbij MySQL 8.0.40 een prestatievermindering laat zien in vergelijking met MySQL 8.0.27:
De volgende figuur toont de prestatietest van batchinvoegingen onder enkele gelijktijdigheid, met de prestatievermindering van MySQL 8.0.40 in vergelijking met versie 5.7.44:
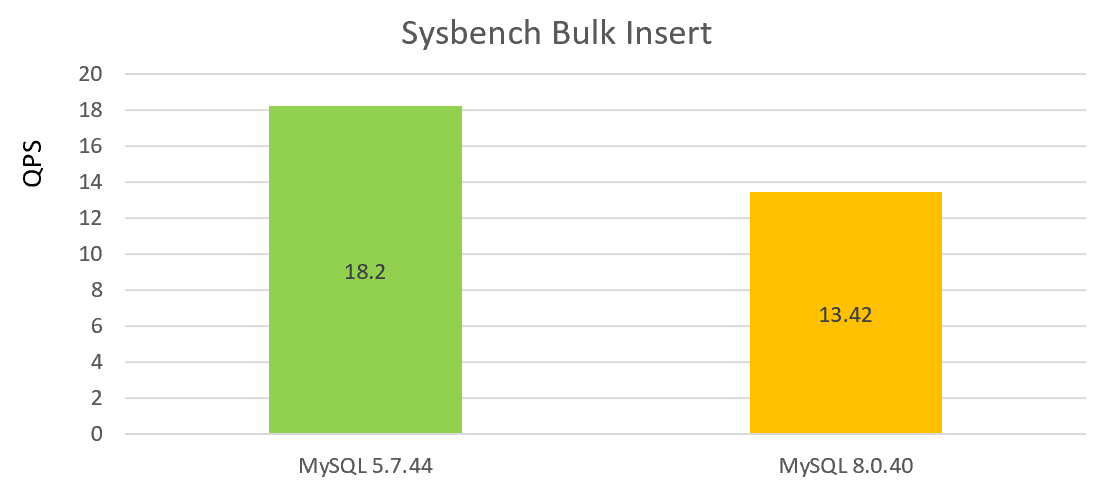
Uit de twee bovenstaande grafieken blijkt dat de prestaties van versie 8.0.40 niet goed zijn.
Laten we nu de oorzaak van de prestatievermindering in MySQL analyseren vanuit het code-niveau. Hieronder staat de functie PT_insert_values_list::contextualize in MySQL 8.0:
De overeenkomstige functie PT_insert_values_list::contextualize in MySQL 5.7 is als volgt:
Uit de codevergelijking lijkt MySQL 8.0 over elegantere code te beschikken en lijkt het vooruitgang te boeken.
Helaas leiden de motivaties achter deze codeverbeteringen vaak juist tot prestatievermindering. Het MySQL-officiële team heeft de vorige List-gegevensstructuur vervangen door een deque, wat een van de hoofdoorzaken is van de geleidelijke prestatievermindering. Laten we eens kijken naar de documentatie van deque:
std::deque (double-ended queue) is an indexed sequence container that allows fast insertion and deletion at both its
beginning and its end. In addition, insertion and deletion at either end of a deque never invalidates pointers or
references to the rest of the elements.
As opposed to std::vector, the elements of a deque are not stored contiguously: typical implementations use a sequence
of individually allocated fixed-size arrays, with additional bookkeeping, which means indexed access to deque must
perform two pointer dereferences, compared to vector's indexed access which performs only one.
The storage of a deque is automatically expanded and contracted as needed. Expansion of a deque is cheaper than the
expansion of a std::vector because it does not involve copying of the existing elements to a new memory location. On
the other hand, deques typically have large minimal memory cost; a deque holding just one element has to allocate its
full internal array (e.g. 8 times the object size on 64-bit libstdc++; 16 times the object size or 4096 bytes,
whichever is larger, on 64-bit libc++).
The complexity (efficiency) of common operations on deques is as follows:
Random access - constant O(1).
Insertion or removal of elements at the end or beginning - constant O(1).
Insertion or removal of elements - linear O(n).
Zoals in de bovenstaande beschrijving is aangetoond, vereist het behoud van een enkel element in extreme gevallen het toewijzen van de gehele array, wat resulteert in een zeer lage geheugenefficiëntie. Bijvoorbeeld, bij bulkinvoegen, waar een groot aantal records moet worden ingevoegd, slaat de officiële implementatie elk record op in een aparte deque. Zelfs als de inhoud van het record minimaal is, moet er toch een deque worden toegewezen. De MySQL deque-implementatie wijst 1KB geheugen toe voor elke deque om snelle opvragingen te ondersteunen.
The implementation is the same as classic std::deque: Elements are held in blocks of about 1 kB each.
De officiële implementatie gebruikt 1KB geheugen om indexinformatie op te slaan, en zelfs als de recordlengte niet groot is maar er veel records zijn, kunnen de geheugentoegang adressen niet aaneengeschakeld raken, wat leidt tot een slechte cachevriendelijkheid. Dit ontwerp was bedoeld om de cachevriendelijkheid te verbeteren, maar het is niet volledig effectief gebleken.
Het is vermeldenswaard dat de oorspronkelijke implementatie een List-gegevensstructuur gebruikte, waarbij geheugen werd toegewezen via een geheugenpool, wat een bepaald niveau van cachevriendelijkheid bood. Hoewel willekeurige toegang minder efficiënt is, verbetert het optimaliseren voor sequentiële toegang tot List-elementen de prestaties aanzienlijk.
Tijdens de upgrade naar MySQL 8.0 observeerden gebruikers een significante achteruitgang in de prestaties van batchinvoegen, en een van de belangrijkste oorzaken was de substantiële wijziging in de onderliggende gegevensstructuren.
Daarnaast, terwijl het officiële team het redo-logmechanisme verbeterde, leidde dit ook tot een afname van de efficiëntie van de MTR-commitoperatie. In vergelijking met MySQL 5.7 vermindert de toegevoegde code de prestaties van individuele commits aanzienlijk, ook al is de algehele schrijfsnelheid sterk verbeterd.
Laten we de kernoperatie execute van MTR-commit in MySQL 5.7.44 bekijken:
Laten we de kern execute operatie van MTR commit in MySQL 8.0.40 onderzoeken:
In vergelijking is het duidelijk dat in MySQL 8.0.40 de execute operatie in MTR commit veel complexer is geworden, met meer stappen. Deze complexiteit is een van de belangrijkste oorzaken van de afname in prestaties bij schrijfoperaties met lage gelijktijdigheid.
Met name de operaties m_impl->m_log.for_each_block(write_log) en log_wait_for_space_in_log_recent_closed(*log_sys, handle.start_lsn) hebben aanzienlijke overhead. Deze veranderingen werden doorgevoerd om de prestaties bij hoge gelijktijdigheid te verbeteren, maar dit ging ten koste van de prestaties bij lage gelijktijdigheid.
De prioritering van de redo log voor hoge gelijktijdigheid zorgt voor slechte prestaties bij werkbelastingen met lage gelijktijdigheid. Hoewel de introductie van innodb_log_writer_threads bedoeld was om prestatieproblemen bij lage gelijktijdigheid te verminderen, heeft dit geen invloed op de uitvoering van de bovenstaande functies. Aangezien deze operaties complexer zijn geworden en frequente MTR commits vereisen, is de prestatie aanzienlijk gedaald.
Laten we eens kijken naar de impact van de directe toevoeg/verwijder-functie op de prestaties. Hieronder staat de functie rec_init_offsets_comp_ordinary in MySQL 5.7:
De functie rec_init_offsets_comp_ordinary in MySQL 8.0.40 is als volgt:
Uit de bovenstaande code blijkt dat met de introductie van de instant add/drop kolomfunctie, de rec_init_offsets_comp_ordinary functie merkbaar complexer is geworden, met meer functie-aanroepen en een switch-statement dat een ernstige impact heeft op de cache-optimalisatie. Aangezien deze functie vaak wordt aangeroepen, heeft dit directe gevolgen voor de prestaties van de update-index, batch-inserts en joins, wat resulteert in een aanzienlijke prestatiedaling.
Bovendien is de prestatieafname in MySQL 8.0 niet beperkt tot het bovenstaande; er zijn veel andere gebieden die bijdragen aan de algehele prestatieafname, vooral de impact op de uitbreiding van inline functies. Bijvoorbeeld, de volgende code beïnvloedt de uitbreiding van inline functies:
Volgens onze tests verstoort de ib::fatal verklaring de inline optimalisatie ernstig. Voor vaak geraadpleegde functies is het raadzaam om uitspraken te vermijden die de inline optimalisatie verstoren.
Laten we nu een vergelijkbaar probleem bekijken. De row_sel_store_mysql_field functie wordt vaak aangeroepen, waarbij row_sel_field_store_in_mysql_format een hotspotfunctie binnenin is. De specifieke code is als volgt:
De row_sel_field_store_in_mysql_format functie roept uiteindelijk row_sel_field_store_in_mysql_format_func aan.
De row_sel_field_store_in_mysql_format_func functie kan niet inline worden uitgevoerd vanwege de aanwezigheid van de ib::fatal code.
Vaak aangeroepen inefficiënte functies, die tienduizenden keren per seconde worden uitgevoerd, kunnen een ernstige impact hebben op de prestatie van joins.
Laten we doorgaan met het verkennen van de redenen voor prestatievermindering. De volgende officiële prestatieoptimalisatie is eigenlijk een van de hoofdoorzaken van de afname van de prestaties bij het samenvoegen. Hoewel bepaalde query’s kunnen worden verbeterd, zijn ze nog steeds een aantal van de redenen voor de prestatievermindering van gewone samenvoegingsbewerkingen.
De problemen van MySQL gaan verder dan deze. Zoals blijkt uit de analyses hierboven, is de prestatievermindering in MySQL niet zonder reden. Een reeks kleine problemen, wanneer opgehoopt, kan leiden tot merkbare prestatievermindering die gebruikers ervaren. Deze problemen zijn echter vaak moeilijk te identificeren, waardoor ze nog moeilijker op te lossen zijn.
De zogenaamde ‘voortijdige optimalisatie’ is de oorzaak van alle kwaad, en dit geldt niet voor de ontwikkeling van MySQL. Databaseontwikkeling is een complex proces, en het verwaarlozen van prestaties in de loop van de tijd maakt latere prestatieverbeteringen aanzienlijk uitdagender.
Oplossingen om de prestatievermindering van MySQL te verminderen
De belangrijkste redenen voor de afname van de schrijfprestaties hebben te maken met MTR-commitproblemen, direct toevoegen/verwijderen van kolommen en enkele andere factoren. Deze zijn moeilijk te optimaliseren op traditionele manieren. Gebruikers kunnen echter de prestatiedaling compenseren door middel van PGO-optimalisatie. Met een goede strategie kan de prestatie over het algemeen stabiel worden gehouden.
Voor batch-insertieprestatievermindering vervangt onze open-source versie [2] de officiële deque door een verbeterde lijstimplementatie. Dit adresseert voornamelijk geheugenefficiëntieproblemen en kan gedeeltelijk prestatievermindering verlichten. Door PGO-optimalisatie te combineren met onze open-source versie, kan de batch-insertieprestatie vergelijkbaar worden met die van MySQL 5.7.

Gebruikers kunnen ook meerdere threads benutten voor gelijktijdige batchverwerking, waarbij volop gebruik wordt gemaakt van de verbeterde gelijktijdigheid van het redo-logboek, wat de batch-insertieprestaties aanzienlijk kan verbeteren.
Wat betreft update-indexproblemen, vanwege de onvermijdelijke toevoeging van nieuwe code, kan PGO-optimalisatie helpen dit probleem te verzachten. Onze PGO-versie [2] kan dit probleem aanzienlijk verlichten.
Voor leesprestaties, met name join-prestaties, hebben we aanzienlijke verbeteringen aangebracht, waaronder het oplossen van inlinekwesties en het doorvoeren van andere optimalisaties. Met de toevoeging van PGO kunnen join-prestaties met meer dan 30% worden verhoogd in vergelijking met de officiële versie.
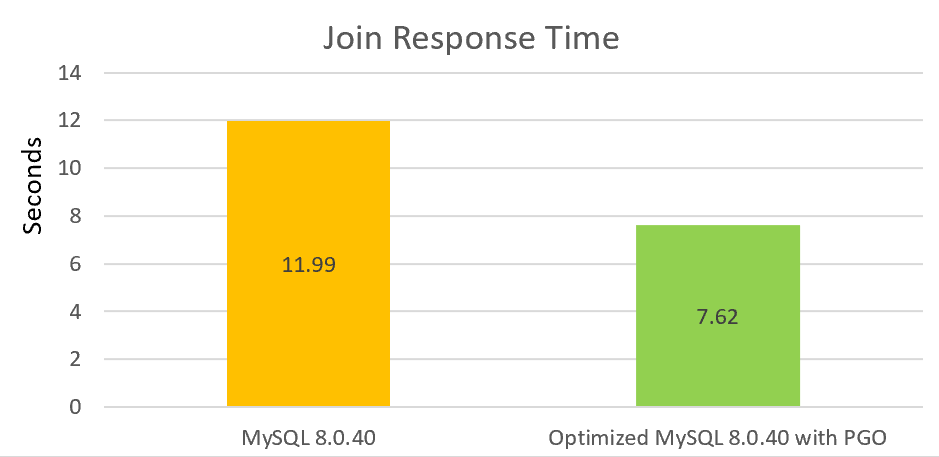
We zullen blijven investeren in het optimaliseren van prestaties bij lage gelijktijdigheid. Dit proces is lang maar omvat tal van gebieden die verbetering behoeven.
De open-source versie is beschikbaar voor testen en inspanningen zullen worden voortgezet om de prestaties van MySQL te verbeteren.MySQL-prestaties.
Referenties
[1] Bin Wang (2024). De Kunst van Probleemoplossing in Softwaretechniek: Hoe MySQL te Verbeteren.
Source:
https://dzone.com/articles/mysql-80-performance-degradation-analysis