













Disclaimer: Alle opvattingen en meningen die in de blog worden geuit, behoren uitsluitend tot de auteur en niet noodzakelijkerwijs tot de werkgever van de auteur of enige andere groep of individu. Dit artikel is geen promotie voor een cloud-/databeheerplatform. Alle afbeeldingen en API’s zijn openbaar beschikbaar op de Azure/Databricks-website..
Wat Is Databricks Lakehouse Monitoring?
In mijn andere artikelen heb ik beschreven wat Databricks en Unity Catalog zijn, en hoe je een catalogus vanaf nul kunt maken met behulp van een script. In dit artikel zal ik de Lakehouse Monitoring-functie beschrijven die beschikbaar is als onderdeel van het Databricks-platform en hoe je de functie kunt inschakelen met behulp van scripts.
Lakehouse Monitoring biedt gegevensprofilering en gegevenskwaliteitsgerelateerde statistieken voor de Delta Live Tables in Lakehouse. Databricks Lakehouse Monitoring biedt een uitgebreid inzicht in de gegevens, zoals veranderingen in het datavolume, veranderingen in de numerieke verdeling, % nullen en nullen in de kolommen, en detectie van categorische anomalieën in de tijd.
Waarom Lakehouse Monitoring gebruiken?
Het monitoren van uw gegevens en ML-modelprestaties biedt kwantitatieve maatregelen die u helpen bijhouden en bevestigen van de kwaliteit en consistentie van uw gegevens en modelprestaties in de loop van de tijd.
Hier is een overzicht van de belangrijkste kenmerken:
- Gegevenskwaliteit en gegevensintegriteitscontrole: Traceert de stroom van gegevens over pijplijnen, zorgt voor gegevensintegriteit en biedt inzicht in hoe de gegevens in de loop van de tijd zijn veranderd, 90e percentiel van een numerieke kolom, % van nul- en nulkolommen, enz.
- Gegevensdrift in de loop van de tijd: Biedt statistieken om gegevensdrift te detecteren tussen de huidige gegevens en een bekende basislijn, of tussen opeenvolgende tijdsvensters van de gegevens
- Statistische verdeling van gegevens: Biedt numerieke veranderende verdeling van gegevens in de loop van de tijd die antwoord geeft op wat de verdeling van waarden in een categoriekolom is en hoe deze verschilt van het verleden
- ML-modelprestaties en voorspellingsdrift: ML-modelinputs, voorspellingen en prestatietrends in de loop van de tijd
Hoe het werkt
Databricks Lakehouse Monitoring biedt de volgende soorten analyses: tijdreeksen, momentopname en inferentie.
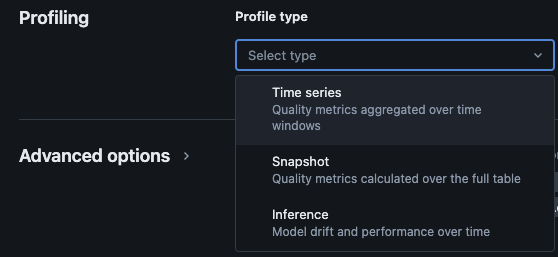
Profieltypes voor monitoring
Wanneer u Lakehouse-monitoring inschakelt voor een tabel in Unity Catalog, worden er twee tabellen aangemaakt in het gespecificeerde monitoringsschema. U kunt query’s uitvoeren en dashboards maken (Databricks biedt standaard een configureerbaar dashboard out-of-the-box) en meldingen instellen op de tabellen om uitgebreide statistische en profielinformatie over uw gegevens in de loop van de tijd te verkrijgen.
- Afwijsmetriektabel: De afwijsmetriektabel bevat statistieken met betrekking tot de afwijking van de gegevens in de loop van de tijd. Het legt informatie vast zoals verschillen in tellen, het verschil in gemiddelde, het verschil in % nullen en nullen, enz.
- Profielmetriektabel: De profielmetriektabel bevat samenvattende statistieken voor elke kolom en voor elke combinatie van tijdsvenster, segment en groeperingskolommen. Voor InferenceLog-analyse bevat de analyse tabel ook modelnauwkeurigheidsstatistieken.
Hoe u Lakehouse-monitoring inschakelt via scripts
Vereisten
- Unity Catalog, schema en Delta Live Tables zijn aanwezig.
- De gebruiker is de eigenaar van de Delta Live Table.
- Voor privé-Azure Databricks-clusters is privéconnectiviteit van serverloze berekening geconfigureerd.
Stap 1: Maak een notebook aan en installeer Databricks SDK
Maak een notebook in de Databricks-werkruimte. Klik op het “+” Nieuw in de zijbalk om een notebook in uw werkruimte te maken, en kies vervolgens Notebook.
Er wordt een leeg notebook geopend in de werkruimte. Zorg ervoor dat Python is geselecteerd als de programmeertaal voor het notebook.
Kopieer en plak de onderstaande codefragment in de notebookcel en voer de cel uit.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
Stap 2: Variabelen maken
Kopieer en plak de onderstaande codefragment in de notebookcel en voer de cel uit.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
Stap 3: Monitoringsschema maken
Kopieer en plak de onderstaande codefragment in de notebookcel en voer de cel uit. Dit fragment zal het monitoringschema maken als het nog niet bestaat.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
Stap 4: Monitor maken
Kopieer en plak de onderstaande codefragment in de notebookcel en voer de cel uit. Dit fragment zal Lakehouse Monitoring creëren voor alle tabellen binnen het schema.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
Validatie
Na succesvolle uitvoering van het script, kunt u naar catalogus -> schema -> tabel navigeren en naar het tabblad “Kwaliteit” in de tabel gaan om de details van de monitoring te bekijken.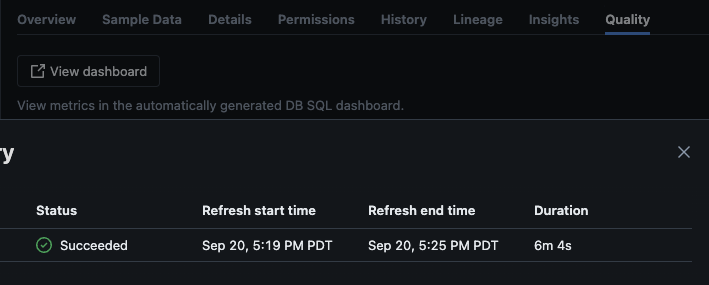
Als je op de “Bekijk dashboard” knop in de linkerbovenhoek van de Monitoring pagina klikt, opent het standaard monitoringdashboard. Aanvankelijk zullen de gegevens leeg zijn. Naarmate de monitoring volgens schema draait, zullen in de loop van de tijd alle statistische, profiel- en datakwaliteitswaarden worden ingevuld.
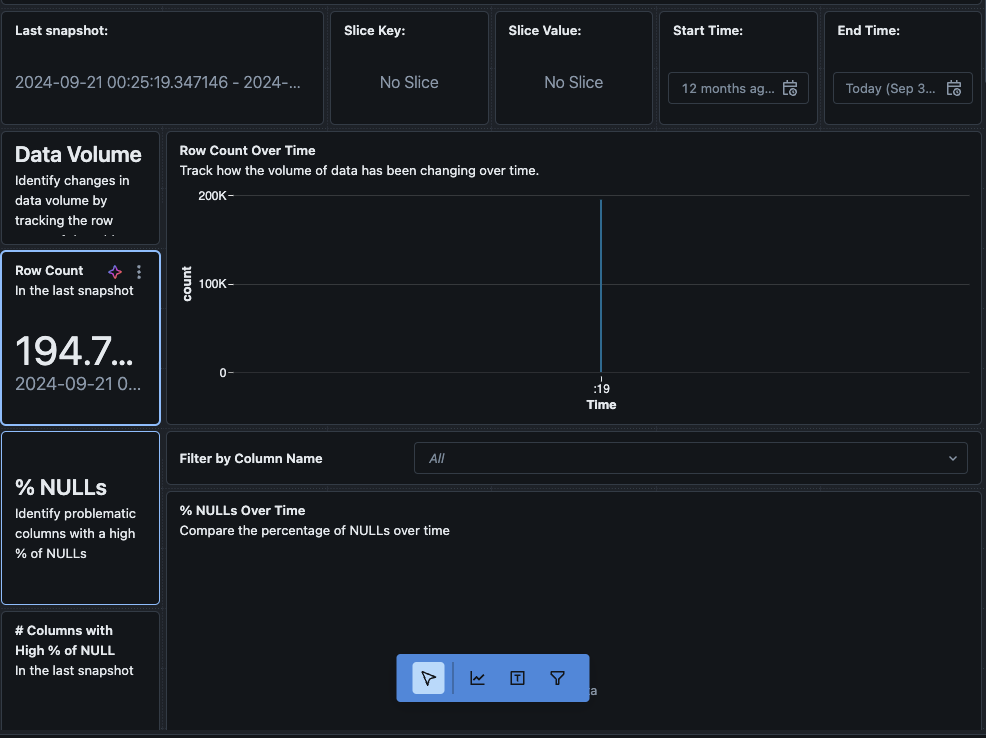
Je kunt ook navigeren naar het “Gegevens” tabblad in het dashboard. Databricks biedt standaard een lijst met queries om de drift en andere profielinformatie te verkrijgen. Je kunt ook je eigen queries maken op basis van je behoeften om een uitgebreid overzicht van je gegevens in de loop van de tijd te krijgen.
Conclusie
Databricks Lakehouse Monitoring biedt een gestructureerde manier om datakwaliteit, profielmetingen en het detecteren van datadrifts in de loop van de tijd te volgen. Door deze functie via scripts in te schakelen, kunnen teams inzicht krijgen in het datagedrag en de betrouwbaarheid van hun datapijpleidingen waarborgen. Het installatieproces dat in dit artikel wordt beschreven, biedt een basis voor het behouden van dataintegriteit en het ondersteunen van voortdurende data-analyse-inspanningen.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring