













In een tijdperk gekenmerkt door een exponentiële toename van datageneratie, moeten organisaties deze rijkdom aan informatie effectief benutten om hun concurrentievoordeel te behouden. Efficiënt zoeken en analyseren van klantgegevens — zoals het identificeren van gebruikersvoorkeuren voor filmaanbevelingen of sentimentanalyse — speelt een cruciale rol in het stimuleren van weloverwogen besluitvorming en het verbeteren van gebruikerservaringen. Een streamingdienst kan bijvoorbeeld vectorsearch gebruiken om films aan te bevelen die zijn afgestemd op individuele kijkgeschiedenissen en beoordelingen, terwijl een retailmerk klantensentimenten kan analyseren om marketingstrategieën te verfijnen.
Als data-engineers zijn we verantwoordelijk voor het implementeren van deze geavanceerde oplossingen, zodat organisaties bruikbare inzichten kunnen halen uit enorme datasets. Dit artikel verkent de complexiteit van vectorsearch met behulp van Elasticsearch, met de focus op effectieve technieken en best practices om de prestaties te optimaliseren. Door casestudy’s te onderzoeken over afbeeldingsherstel voor gepersonaliseerde marketing en tekstanalyse voor clustering van klantensentiment, laten we zien hoe het optimaliseren van vectorsearch kan leiden tot verbeterde klantinteracties en significante bedrijfs groei.
Wat is Vectorsearch?
Vectorsearch is een krachtige methode om overeenkomsten tussen datapunten te identificeren door ze voor te stellen als vectoren in een hoog-dimensionale ruimte. Deze aanpak is bijzonder nuttig voor toepassingen die snelle terughaling van vergelijkbare items op basis van hun attributen vereisen.
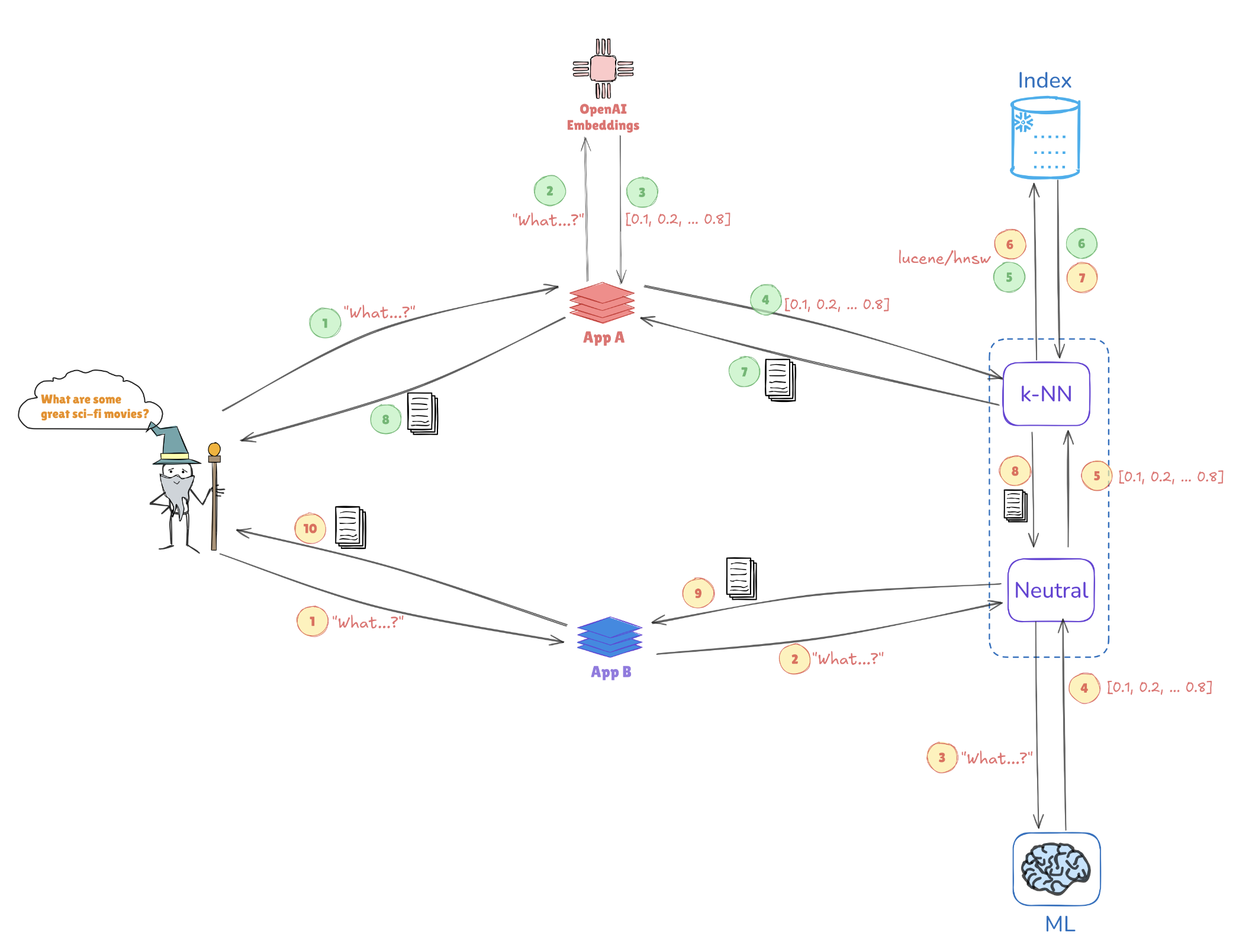
Illustratie van Vectorsearch
Overweeg de onderstaande illustratie, die toont hoe vectorrepresentaties gelijktijdige zoekopdrachten mogelijk maken:
- Query-embeddings: De query “Wat zijn enkele geweldige sci-fi films?” wordt omgezet in een vectorrepresentatie, zoals [0.1, 0.2, …, 0.4].
- Indexeren: Deze vector wordt vergeleken met vooraf geïndexeerde vectoren die zijn opgeslagen in Elasticsearch (bijv. van toepassingen zoals AppA en AppB) om vergelijkbare queries of datapunten te vinden.
- k-NN Zoekopdracht: Met algoritmes zoals k-Nearest Neighbors (k-NN) haalt Elasticsearch efficiënt de beste overeenkomsten op uit de geïndexeerde vectoren, wat helpt om de meest relevante informatie snel te identificeren.
Dit mechanisme stelt Elasticsearch in staat om uit te blinken in gebruikssituaties zoals aanbevelingssystemen, afbeeldingzoekopdrachten en natuurlijke taalverwerking, waar begrip van context en overeenkomst cruciaal is.
Belangrijkste Voordelen van Vectorsearch met Elasticsearch
Ondersteuning voor Hoge Dimensionaliteit
Elasticsearch blinkt uit in het beheren van complexe datastructuren, essentieel voor AI en machine learning toepassingen. Deze capaciteit is cruciaal bij het omgaan met veelzijdige datatypes, zoals beelden of tekstuele gegevens.
Schaling
De architectuur ondersteunt horizontale schaling, waardoor organisaties in staat zijn om steeds groeiende datasets te beheren zonder in te boeten op prestaties. Dit is van vitaal belang aangezien de datavolumes blijven toenemen.
Integratie
Elasticsearch werkt naadloos samen met de Elastic stack, waardoor een uitgebreide oplossing voor data-invoer, analyse en visualisatie wordt geboden. Deze integratie zorgt ervoor dat data-ingenieurs kunnen profiteren van een uniform platform voor verschillende dataverwerkings taken.
Best Practices voor het Optimaliseren van Vector Zoekprestaties
1. Verminder Vector Dimensies
Het verlagen van de dimensionaliteit van uw vectoren kan de zoekprestaties aanzienlijk verbeteren. Technieken zoals PCA (Hoofcomponentenanalyse) of UMAP (Uniforme Manifold Benadering en Projectie) helpen om essentiële kenmerken te behouden terwijl de datastructuur wordt vereenvoudigd.
Voorbeeld: Dimensionaliteitsreductie met PCA
Hier is hoe je PCA kunt implementeren in Python met Scikit-learn:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. Indexeer Efficiënt
Het benutten van Approximate Nearest Neighbor (ANN) algoritmen kan de zoektijden aanzienlijk versnellen. Overweeg om te gebruiken:
- HNSW (Hiërarchisch Navigeerbare Kleine Wereld): Bekend om zijn balans tussen prestaties en nauwkeurigheid.
- FAISS (Facebook AI Similarity Search): Geoptimaliseerd voor grote datasets en in staat om GPU-versnelling te benutten.
Voorbeeld: HNSW implementeren in Elasticsearch
Je kunt je indexinstellingen in Elasticsearch definiëren om HNSW als volgt te gebruiken:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. Batchquery’s
Om de efficiëntie te verbeteren, minimaliseert batchverwerking van meerdere query’s in één verzoek overhead. Dit is vooral nuttig voor toepassingen met veel gebruikersverkeer.
Voorbeeld: Batchverwerking in Elasticsearch
Je kunt de _msearch endpoint gebruiken voor batchquery’s:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. Gebruik Caching
Implementeer cachingstrategieën voor vaak geraadpleegde query’s om de rekentijd te verlagen en de responstijden te verbeteren.
5. Monitor Prestaties
Regelmatig analyseren van prestatiemetingen is cruciaal voor het identificeren van knelpunten. Tools zoals Kibana kunnen helpen deze gegevens te visualiseren, waardoor geïnformeerde aanpassingen aan je Elasticsearch-configuratie mogelijk worden.
Parameters afstemmen in HNSW voor verbeterde prestaties
Het optimaliseren van HNSW houdt in dat bepaalde parameters worden aangepast om betere prestaties op grote datasets te bereiken:
M(maximaal aantal verbindingen): Het verhogen van deze waarde verbetert de recall, maar kan meer geheugen vereisen.EfConstruction(dynamische lijstgrootte tijdens de constructie): Een hogere waarde leidt tot een nauwkeuriger grafiek, maar kan de indexeringstijd verhogen.EfSearch(dynamische lijstgrootte tijdens zoeken): Het aanpassen hiervan beïnvloedt de snelheid-nauwkeurigheid afweging; een grotere waarde levert een betere herinnering op maar duurt langer om te berekenen.
Voorbeeld: Aanpassen van HNSW Parameters
U kunt HNSW parameters aanpassen in uw indexcreatie als volgt:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
Case Study: Impact van Dimensionaliteitsvermindering op HNSW Prestaties in Klantgegevens Toepassingen
Beeldterugvinding voor Gepersonaliseerde Marketing
Dimensionaliteitsverminderings technieken spelen een cruciale rol bij het optimaliseren van beeldterugvindingssystemen binnen klantgegevens toepassingen. In een studie paste onderzoekers Principal Component Analysis (PCA) toe om de dimensionaliteit te verminderen voordat ze beelden indexeerden met Hierarchical Navigable Small World (HNSW) netwerken. PCA zorgde voor een opmerkelijke boost in terugvindingssnelheid – essentieel voor toepassingen die grote hoeveelheden klantgegevens verwerken – hoewel dit gepaard ging met een kleine precisieverlies als gevolg van informatievermindering. Om dit aan te pakken, onderzochten onderzoekers ook Uniform Manifold Approximation and Projection (UMAP) als alternatief. UMAP behield lokale datastructuren effectiever, met behoud van de complexe details die nodig zijn voor gepersonaliseerde marketingaanbevelingen. Hoewel UMAP meer rekenkracht vereiste dan PCA, balanceerde het zoeksnelheid met hoge precisie, waardoor het een levensvatbare keuze is voor nauwkeurigheid-kritieke taken.
Tekstanalyse voor Klanttevredenheid Clustering
In het domein van klantsentimentanalyse vond een andere studie dat UMAP beter presteert dan PCA bij het clusteren van vergelijkbare tekstdata. UMAP stelde het HNSW-model in staat om klantsentimenten met hogere nauwkeurigheid te clusteren — een voordeel bij het begrijpen van klantfeedback en het leveren van meer gepersonaliseerde antwoorden. Het gebruik van UMAP vergemakkelijkte kleinere EfSearch-waarden in HNSW, wat de zoek snelheid en precisie verbeterde. Deze verbeterde clustering efficiëntie maakte een snellere identificatie van relevante klantsentimenten mogelijk, wat de gerichte marketinginspanningen en sentiment-gebaseerde klantsegmentatie verbeterde.
Automatische optimalisatietechnieken integreren
Het optimaliseren van dimensionaliteitsreductie en HNSW-parameters is essentieel voor het maximaliseren van de prestaties van klantdatasystemen. Automatische optimalisatietechnieken stroomlijnen dit afstemmingsproces, waardoor ervoor wordt gezorgd dat geselecteerde configuraties effectief zijn in verschillende toepassingen:
- Grid- en random search: Deze methoden bieden een brede en systematische parameterverkenning, waarbij geschikte configuraties efficiënt worden geïdentificeerd.
- Bayesiaanse optimalisatie: Deze techniek richt zich op optimale parameters met minder evaluaties, waardoor computermiddelen worden bespaard.
- Kruisvalidering: Kruisvalidering helpt om parameters te valideren over verschillende datasets, waardoor hun generalisatie naar verschillende klantdatacontexten wordt gewaarborgd.
Uitdagingen in automatisering aanpakken
Het integreren van automatisering binnen dimensionaliteitsvermindering en HNSW-workflows kan uitdagingen met zich meebrengen, met name op het gebied van het beheren van rekenkundige eisen en het vermijden van overpassing. Strategieën om deze uitdagingen te overwinnen zijn onder andere:
- Verlagen van rekenkundige overhead: Door parallelle verwerking te gebruiken om de werklast te verdelen wordt de optimalisatietijd verkort, wat de efficiëntie van de workflow verbetert.
- Modulaire integratie: Een modulaire aanpak vergemakkelijkt de naadloze integratie van geautomatiseerde systemen in bestaande workflows, waardoor de complexiteit wordt verminderd.
- Overpassing voorkomen: Robuuste validatie door middel van cross-validatie zorgt ervoor dat geoptimaliseerde parameters consistent presteren over datasets, waardoor overpassing wordt geminimaliseerd en de schaalbaarheid in toepassingen voor klantgegevens wordt verbeterd.
Conclusie
Om volledig te profiteren van de vectorzoekprestaties in Elasticsearch, is het essentieel om een strategie te omarmen die dimensionaliteitsvermindering, efficiënte indexering en doordachte parameterafstemming combineert. Door deze technieken te integreren, kunnen data-engineers een zeer responsief en nauwkeurig gegevensophaalsysteem creëren. Geautomatiseerde optimalisatiemethoden tillen dit proces verder op, waardoor continue verfijning van zoekparameters en indexatiestrategieën mogelijk is. Aangezien organisaties steeds meer vertrouwen op real-time inzichten uit uitgebreide datasets, kunnen deze optimalisaties aanzienlijk bijdragen aan het verbeteren van besluitvormingscapaciteiten, met snellere en relevantere zoekresultaten. Het omarmen van deze aanpak legt de basis voor toekomstige schaalbaarheid en verbeterde responsiviteit, waarbij zoekmogelijkheden worden afgestemd op evoluerende zakelijke eisen en gegevensgroei.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch