













In deze praktische workshop van ScyllaDB University leer je hoe je de ScyllaDB CDC source connector kunt gebruiken om gebeurtenissen van rij-niveauwijzigingen in de tabellen van een ScyllaDB-cluster te pushen naar een Kafka-server.
Wat Is ScyllaDB CDC?
Ter herhaling, Change Data Capture (CDC) is een functie die je niet alleen in staat stelt om de huidige staat van een database-tabel te ondervragen, maar ook de geschiedenis van alle wijzigingen die aan de tabel zijn aangebracht. CDC is productieklaar (GA) vanaf ScyllaDB Enterprise 2021.1.1 en ScyllaDB Open Source 4.3.
In ScyllaDB is CDC optioneel en wordt per tabel ingeschakeld. De geschiedenis van wijzigingen die aan een tabel met ingeschakelde CDC zijn aangebracht, wordt opgeslagen in een aparte, hiermee geassocieerde tabel.
Je kunt CDC inschakelen bij het aanmaken of wijzigen van een tabel met behulp van de CDC-optie, bijvoorbeeld:
CREATE TABLE ks.t (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};ScyllaDB CDC Source Connector
De ScyllaDB CDC Source Connector is een bronconnector die rij-niveau wijzigingen in de tabellen van een ScyllaDB-cluster vastlegt. Het is een Debezium connector, compatibel met Kafka Connect (met Kafka 2.6.0+). De connector leest het CDC-logboek voor gespecificeerde tabellen en produceert Kafka-berichten voor elke rij-niveau INSERT, UPDATE of DELETE bewerking. De connector is fouttolerant en herhaalt het lezen van gegevens uit Scylla bij falen. Het slaat periodiek de huidige positie in het ScyllaDB CDC-logboek op met behulp van Kafka Connect offset tracking. Elk gegenereerd Kafka-bericht bevat informatie over de bron, zoals de tijdstip en de tabelnaam.
Opmerking: op het moment van schrijven, is er geen ondersteuning voor verzamelingstypen (LIST, SET, MAP) en UDTs—kolommen met deze typen worden overgeslagen in gegenereerde berichten. Blijf op de hoogte van dit verbeteringsverzoek en andere ontwikkelingen in het GitHub project.
Confluent en Kafka Connect
Confluent is een volledig uitgevoerde data streaming platform dat ervoor zorgt dat u gemakkelijk toegang krijgt, data opslaat en beheert als continue, realtime streams. Het breidt de voordelen van Apache Kafka uit met enterprise-grade functies. Confluent maakt het eenvoudig om moderne, event-driven applicaties te bouwen en een universele data pijplijn te verkrijgen, die ondersteuning biedt voor schaalbaarheid, prestaties en betrouwbaarheid.
Kafka Connect is een hulpmiddel voor schaalbaar en betrouwbaar streamen van data tussen Apache Kafka en andere data systemen. Het maakt het eenvoudig om connectors te definiëren die grote hoeveelheden data in en uit Kafka verplaatsen. Het kan gehele databases opnemen of metrische gegevens van applicatieservers verzamelen in Kafka topics, waardoor de data beschikbaar is voor streamverwerking met lage latentie.
Kafka Connect bevat twee soorten connectors:
- Bron connector: Bron connectors nemen gehele databases op en streamen tabelupdates naar Kafka topics. Bron connectors kunnen ook metrische gegevens van applicatieservers verzamelen en de data opslaan in Kafka topics, waardoor de data beschikbaar is voor streamverwerking met lage latentie.
- Sink connector: Sink connectors leveren data van Kafka topics naar secundaire indices, zoals Elasticsearch, of batch systemen, zoals Hadoop, voor offline analyse.
Service Setup With Docker
In deze lab, ga je Docker gebruiken.
Zorg er bij voorbaat voor dat je omgeving voldoet aan de volgende vereisten:
- Docker voor Linux, Mac of Windows.
- Opmerking: het draaien van ScyllaDB in Docker wordt enkel aanbevolen om ScyllaDB te evalueren en uit te proberen.
- ScyllaDB open source. Voor de beste prestaties wordt een reguliere installatie aanbevolen.
- 8 GB RAM of meer voor Kafka en ScyllaDB diensten.
- docker-compose
- Git
ScyllaDB Installatie en Init Table
Eerst start je een cluster van drie ScyllaDB-nodes en creëer je een tabel met ingeschakelde CDC.
Als je dat nog niet hebt gedaan, download dan het voorbeeld van git:
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/CDC_Kafka_LabDit is het docker-compose bestand dat je gaat gebruiken. Het start een cluster van drie ScyllaDB-nodes:
version: "3"
services:
scylla-node1:
container_name: scylla-node1
image: scylladb/scylla:5.0.0
ports:
- 9042:9042
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node2:
container_name: scylla-node2
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node3:
container_name: scylla-node3
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0Start de ScyllaDB-cluster:
docker-compose -f docker-compose-scylladb.yml up -dWacht een minuutje of zo, en controleer of de ScyllaDB-cluster up is en normaal werkt:
docker exec scylla-node1 nodetool statusVervolgens ga je cqlsh gebruiken om te communiceren met ScyllaDB. Creëer een keyspace, en een tabel met ingeschakelde CDC, en voeg een rij toe aan de tabel:
docker exec -ti scylla-node1 cqlsh
CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
exit[guy@fedora cdc_test]$ docker-compose -f docker-compose-scylladb.yml up -d
Creating scylla-node1 ... done
Creating scylla-node2 ... done
Creating scylla-node3 ... done
[guy@fedora cdc_test]$ docker exec scylla-node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Adres Belasting Tokens Eigenaamt Host ID Rack
UN 172.19.0.3 ? 256 ? 4d4eaad4-62a4-485b-9a05-61432516a737 rack1
UN 172.19.0.2 496 KB 256 ? bec834b5-b0de-4d55-b13d-a8aa6800f0b9 rack1
UN 172.19.0.4 ? 256 ? 2788324e-548a-49e2-8337-976897c61238 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
[guy@fedora cdc_test]$ docker exec -ti scylla-node1 cqlsh
Connected to at 172.19.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
cqlsh> CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
cqlsh> INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
cqlsh> exit
[guy@fedora cdc_test]$ Confluent Setup en Connector Configuratie
Om een Kafka-server te starten, gebruik je de Confluent-platform, die een gebruiksvriendelijke web-GUI biedt om onderwerpen en berichten bij te houden. Het Confluent-platform biedt een docker-compose.yml bestand om de diensten in te stellen.
Opmerking: dit is niet hoe je Apache Kafka in productie zou gebruiken. Het voorbeeld is alleen nuttig voor training en ontwikkeling. Download het bestand:
wget -O docker-compose-confluent.yml https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.3.0-post/cp-all-in-one/docker-compose.ymlVervolgens download je de ScyllaDB CDC connector:
wget -O scylla-cdc-plugin.jar https://github.com/scylladb/scylla-cdc-source-connector/releases/download/scylla-cdc-source-connector-1.0.1/scylla-cdc-source-connector-1.0.1-jar-with-dependencies.jarVoeg de ScyllaDB CDC connector toe aan de pluginmap van de Confluent connect service met behulp van een Docker-volume door docker-compose-confluent.yml aan te passen om de twee onderstaande regels toe te voegen, waarbij de directory wordt vervangen door de directory van uw scylla-cdc-plugin.jar bestand.
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
+ volumes:
+ - <directory>/scylla-cdc-plugin.jar:/usr/share/java/kafka/plugins/scylla-cdc-plugin.jar
depends_on:
- broker
- schema-registryStart de Confluent services:
docker-compose -f docker-compose-confluent.yml up -dWacht een minuutje of zo, vervolgens open http://localhost:9021 voor de Confluent web-GUI.
Voeg de ScyllaConnector toe via het Confluent dashboard:
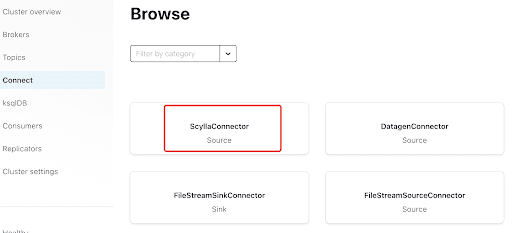
Voeg de Scylla Connector toe door op de plugin te klikken:
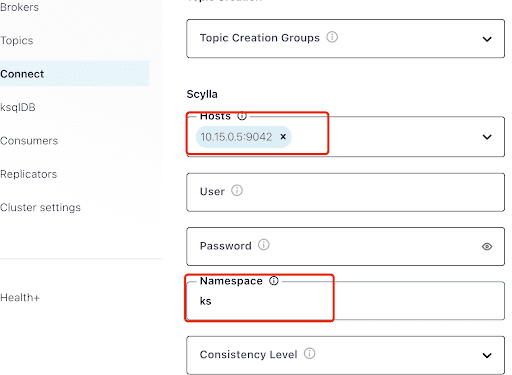
Vul de “Hosts” in met het IP-adres van een van de Scylla-nodes (dit kunt u zien in de uitvoer van de nodetool status command) en poort 9042, die wordt afgehandeld door de ScyllaDB service.
De “Namespace” is de keyspace die u eerder in ScyllaDB hebt gemaakt.
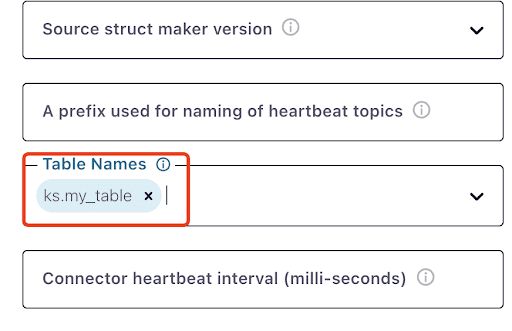
Let op dat het misschien een minuut of zo duurt voordat ks.my_table verschijnt:
Test Kafka Berichten
U kunt zien dat MyScyllaCluster.ks.my_table het onderwerp is dat is gemaakt door de ScyllaDB CDC connector.
Controleer nu op Kafka-berichten via het Topics-paneel:
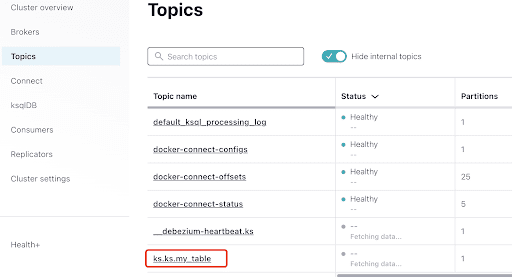
Selecteer het onderwerp, dat gelijkstaat aan de keyspace en tabelnaam die u in ScyllaDB hebt gemaakt:
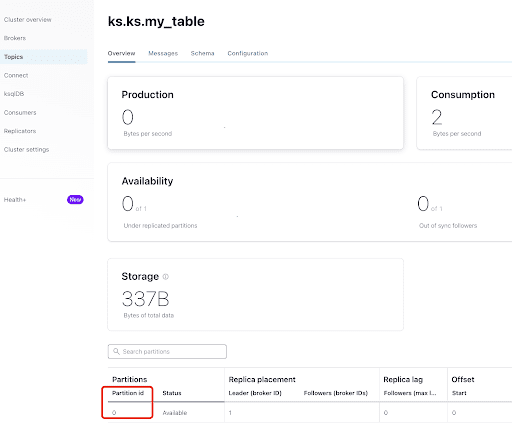
Via het tabblad “Overzicht” kunt u de onderwerpinfo zien. Onder aan de pagina wordt aangegeven dat dit onderwerp zich op partitie 0 bevindt.
A partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion. The records in the partitions are each assigned a sequential identifier called the offset, which is unique for each record within the partition. The offset is an incremental and immutable number maintained by Kafka.
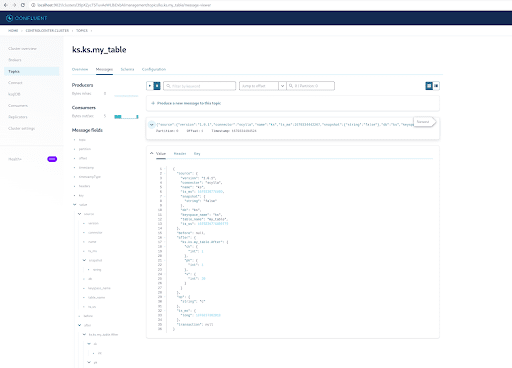
Zoals je al weet, worden de ScyllaDB CDC berichten verzonden naar het onderwerp ks.my_table en is de partitie-id van het onderwerp 0. Ga vervolgens naar het tabblad “Berichten” en voer partitie-id 0 in in het veld “offset”:
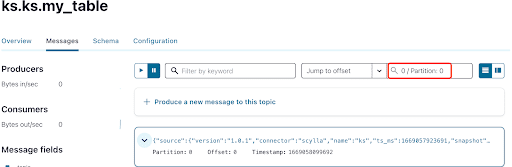
Je kunt zien dat uit de uitvoer van de Kafka onderwerp berichten dat het ScyllaDB tabel INSERT gebeurtenis en de gegevens werden overgedragen naar Kafka berichten door de Scylla CDC Source Connector. Klik op het bericht om de volledige bericht info te bekijken:
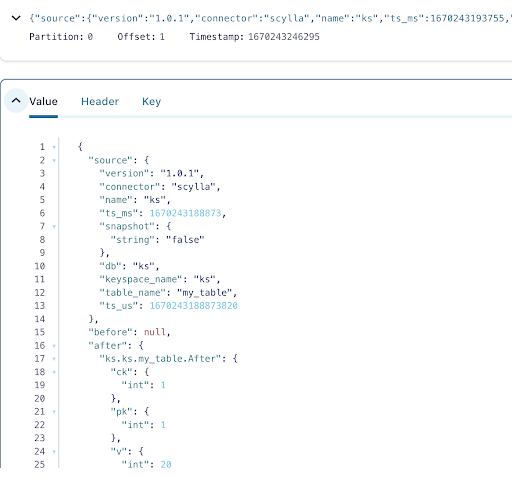
Het bericht bevat de ScyllaDB tabel naam en keyspace naam met de tijd, evenals de gegevens status vóór de actie en erna. Aangezien dit een insert operatie is, is de gegevens vóór de insert null.
Voeg vervolgens nog een rij toe aan de ScyllaDB tabel:
docker exec -ti scylla-node1 cqlsh
INSERT INTO ks.my_table(pk, ck, v) VALUES (200, 50, 70);Nu, in Kafka, wacht een paar seconden en je kunt de details van het nieuwe bericht zien:
Opruimen
Zodra je klaar bent met werken aan deze lab, kun je stoppen en verwijderen van de Docker containers en afbeeldingen.
Om een lijst van alle container IDs te bekijken:
docker container ls -aqDan kun je de containers stoppen en verwijderen die je niet langer gebruikt:
docker stop <ID_or_Name>
docker rm <ID_or_Name>Later, als je de lab opnieuw wilt uitvoeren, kun je de stappen volgen en docker-compose als voorheen gebruiken.
Samenvatting
Met de CDC source connector, een Kafka plugin compatibel met Kafka Connect, kun je alle ScyllaDB tabel rij-niveau veranderingen (INSERT, UPDATE, of DELETE) vastleggen en deze gebeurtenissen omzetten in Kafka berichten. Je kunt dan de gegevens consumeren vanuit andere toepassingen of elke andere operatie uitvoeren met Kafka.
Source:
https://dzone.com/articles/change-data-capture-apache-kafka-and-scylladb