













Shift-left is een aanpak voor softwareontwikkeling en -bediening die nadruk legt op testen, controle en automatisering vroeger in de levenscyclus van softwareontwikkeling. Het doel van de shift-left aanpak is problemen te voorkomen voordat ze ontstaan door ze vroeg te detecteren en snel aan te pakken.
Wanneer je een schaalbaarheidsprobleem of een bug vroeg identificeert, is het sneller en kosteneffectiever om het op te lossen. Het verplaatsen van inefficiënte code naar cloudcontainers kan duur zijn, aangezien het mogelijk automatisch schalen activeert en je maandelijkse rekening verhoogt. Bovendien zul je in een staat van nood verkeren totdat je het probleem kunt identificeren, isoleren en oplossen.
Het Probleem Onderwerp
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
Dit is de tijdlijn van de gebeurtenissen.
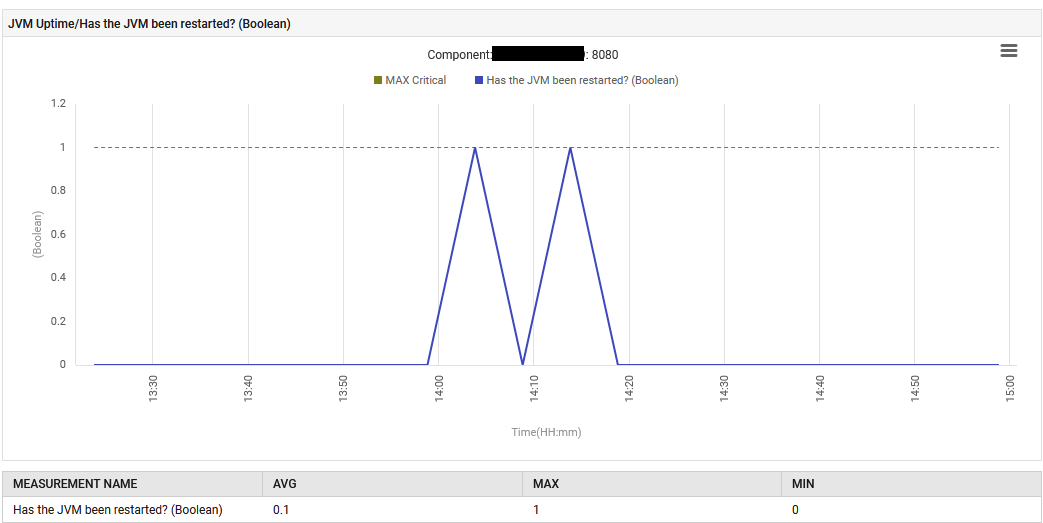
Op 6 augustus om 14:13, is de applicatie opnieuw opgestart met een nieuwe Spring Boot jar-bestand met ingebouwde Tomcat.
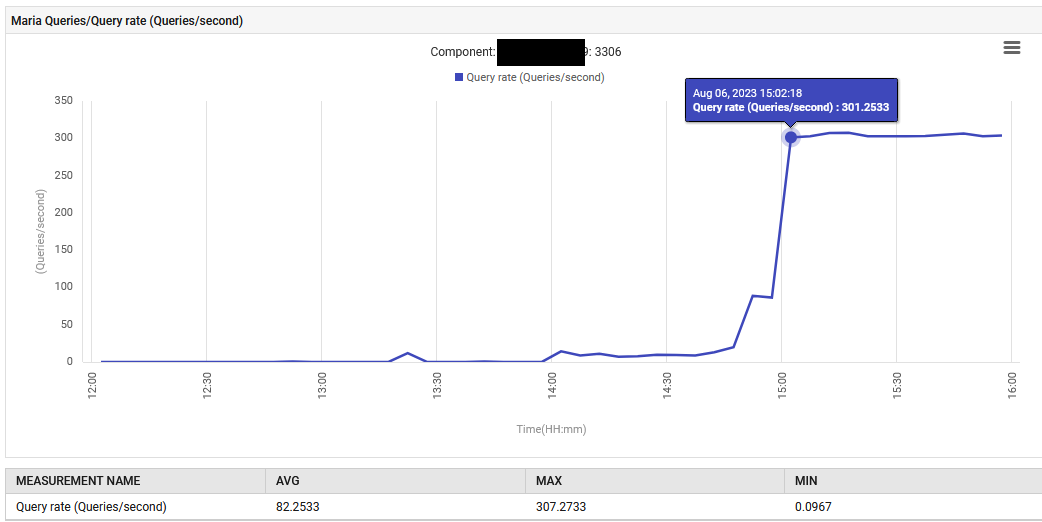
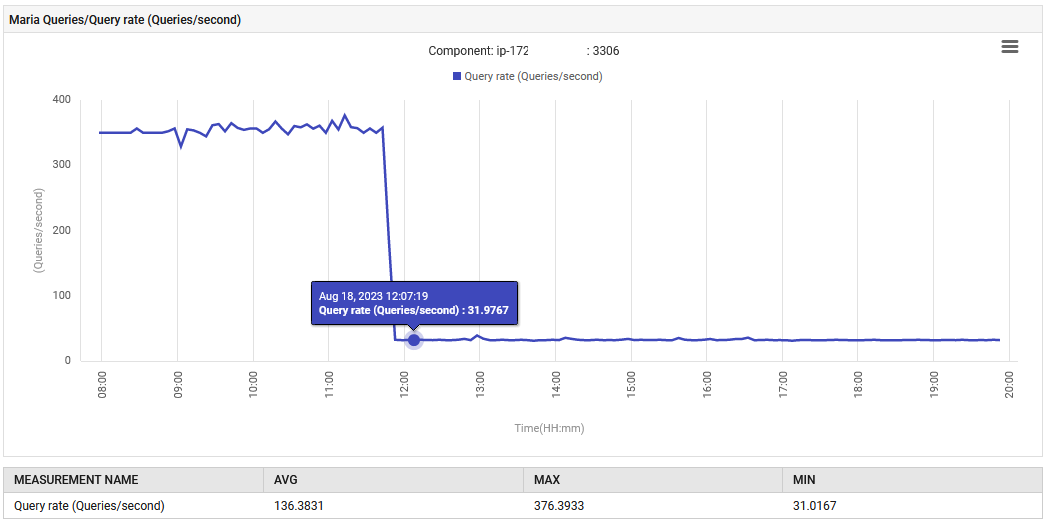
Om 14:52, steeg de queryverwerkingssnelheid voor MariaDB van 0,1 naar 88 queries per seconde en vervolgens naar 301 queries per seconde.
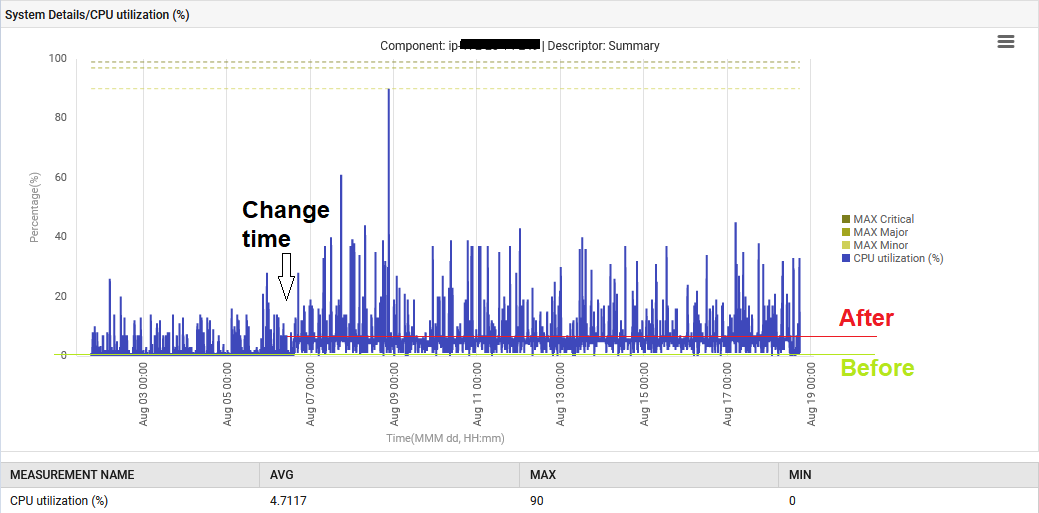
Daarnaast steeg de systeem CPU van 1% naar 6%.
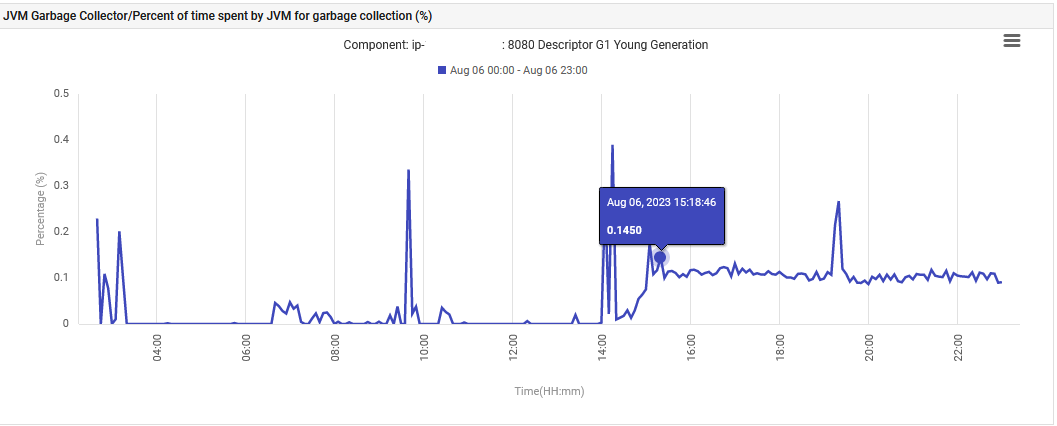
Tenslotte, de JVM tijd die wordt besteed aan de G1 Young Generation Garbage Collection steeg van 0% naar 0,1% en bleef op dat niveau.
De applicatie, in haar UAT-fase, geeft abnormaal 300 query’s per seconde uit, wat ver buiten wat het ontworpen was om te doen. De nieuwe functie heeft geleid tot een toename van databaseverbindingen, waardoor de toename van query’s zo drastisch is. Echter, het controlepaneel toonde dat de problematische metingen normaal waren voordat de nieuwe versie werd geïmplementeerd.
De Oplossing
Het is een Spring Boot-applicatie die JPA gebruikt om een MariaDB te raadplegen. De applicatie is ontworpen om op twee containers te draaien voor minimale belasting, maar is verwacht te schalen tot tien.
Als een enkele container 300 query’s per seconde kan genereren, kan deze 3000 query’s per seconde aan als alle tien containers operationeel zijn? Kan de database voldoende verbindingen hebben om aan de behoeften van de andere delen van de applicatie te voldoen?
We hadden geen andere keuze dan terug te gaan naar de ontwikkelaarstafel om de wijzigingen in Git te inspecteren.
De nieuwe wijziging zal een paar records uit een tabel halen en deze verwerken. Dit is wat we in de serviceklasse waarnamen.
List<X> findAll = this.xRepository.findAll();
Nee, het gebruik van de findAll() methode zonder paginering in Spring’s CrudRepository is niet efficiënt. Paginering helpt om de hoeveelheid tijd te verminderen die nodig is om gegevens uit de database op te halen door de hoeveelheid opgehaalde gegevens te beperken. Dit is wat onze primaire RDBMS-opleiding ons geleerd heeft. Bovendien helpt paginering om het geheugengebruik laag te houden om te voorkomen dat de applicatie crasht door een overbelasting van gegevens, evenals het verminderen van de inspanning voor Garbage Collection van de Java Virtual Machine, zoals vermeld in de probleemstelling hierboven.
Deze test is uitgevoerd met slechts 2.000 records in één container. Als deze code in productie zou worden gebracht, waar er ongeveer 200.000 records in maximaal 10 containers zijn, zou het het team veel stress en zorgen die dag hebben kunnen veroorzaken.
De applicatie is opnieuw opgebouwd met de toevoeging van een WHERE clausule aan de methode.
List<X> findAll = this.xRepository.findAllByY(Y);
De normale werking werd hersteld. Het aantal queries per seconde daalde van 300 naar 30, en de inspanning die in garbage collection werd gestopt, keerde terug naar zijn oorspronkelijke niveau. Bovendien daalde het CPU-gebruik van het systeem.
Leer en Samenvatting
Iedereen die werkt in Site Reliability Engineering (SRE) zal de betekenis van deze ontdekking appreciëren. We konden erop reageren zonder een Severity 1-vlag hoeven te laten. Als deze gebrekkige pakketten in productie waren geïmplementeerd, zou het de auto-scaler drempel van de klant kunnen activeren, waardoor nieuwe containers zonder extra gebruikersbelasting worden gestart.
Er zijn drie belangrijke lessen uit dit verhaal te trekken.
Ten eerste is het een beste praktijk om vanaf het begin een observability-oplossing aan te zetten, aangezien het een geschiedenis van gebeurtenissen kan bieden die kunnen worden gebruikt om potentiële problemen te identificeren. Zonder deze geschiedenis had ik misschien niet serieus genomen dat er 0,1% Garbage Collection en 6% CPU-verbruik was, en kon het code zichzelf in productie hebben vrijgegeven met desastreuze gevolgen. Het uitbreiden van het omvang van de bewakingsoplossing naar UAT-servers hielp het team om potentiële oorzaken te identificeren en problemen te voorkomen voordat ze zich voordoen.
Ten tweede zouden prestatiegerelateerde testgevallen in het testproces moeten bestaan en deze moeten worden beoordeeld door iemand met ervaring in observability. Dit zal ervoor zorgen dat de functionaliteit van de code wordt getest, evenals de prestaties.
Ten derde zijn cloud-native prestatievolgsystemen goed voor het ontvangen van waarschuwingen over hoog gebruik, beschikbaarheid, enz. Om observability te bereiken, moet je misschien de juiste tools en expertise in huis hebben. Happy Coding!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c