













De auteur heeft het Free and Open Source Fund geselecteerd om een donatie te ontvangen als onderdeel van het Write for DOnations-programma.
Inleiding
Flask is een lichtgewicht Python-webframework dat handige tools en functies biedt voor het maken van webapplicaties in de Python-taal. SQLAlchemy is een SQL-toolkit die efficiënte en hoogpresterende toegang tot databases biedt voor relationele databases. Het biedt manieren om te communiceren met verschillende database-engines zoals SQLite, MySQL en PostgreSQL. Het geeft je toegang tot de SQL-functionaliteiten van de database. En het geeft je ook een Object Relational Mapper (ORM), waarmee je queries kunt maken en gegevens kunt verwerken met behulp van eenvoudige Python-objecten en methoden. Flask-SQLAlchemy is een Flask-extensie die het gebruik van SQLAlchemy met Flask vergemakkelijkt, waardoor je tools en methoden krijgt om met je database te communiceren in je Flask-applicaties via SQLAlchemy.
In deze zelfstudie maak je gebruik van Flask en Flask-SQLAlchemy om een werknemersbeheersysteem te maken met een database die een tabel voor werknemers heeft. Elke werknemer zal een uniek ID hebben, een voornaam, een achternaam, een uniek e-mailadres, een geheel getal voor hun leeftijd, een datum voor de dag waarop ze bij het bedrijf zijn gekomen, en een booleaanse waarde om te bepalen of een werknemer momenteel actief is of buiten kantoor is.
Je zult de Flask shell gebruiken om een tabel te bevragen en tabelrecords op te halen op basis van een kolomwaarde (bijvoorbeeld een e-mailadres). Je zult records van werknemers ophalen onder bepaalde voorwaarden, zoals het krijgen van alleen actieve werknemers of het krijgen van een lijst van werknemers die buiten kantoor zijn. Je zult de resultaten ordenen op basis van een kolomwaarde, en het aantal en de limiet van queryresultaten tellen. Ten slotte zul je paginering gebruiken om een bepaald aantal werknemers per pagina weer te geven in een webtoepassing.
Vereisten
-
Een lokale Python 3-programmeeromgeving. Volg de zelfstudie voor je distributie in Hoe een lokale programmeeromgeving voor Python 3 te installeren en in te stellen-serie. In deze zelfstudie noemen we onze projectmap
flask_app. -
Een begrip van basisconcepten van Flask, zoals routes, weergavefuncties en sjablonen. Als u niet bekend bent met Flask, bekijk dan Hoe u uw eerste webapplicatie maakt met Flask en Python en Hoe sjablonen te gebruiken in een Flask-toepassing.
-
Een begrip van basisconcepten van HTML. U kunt onze zelfstudie serie Hoe u een website bouwt met HTML bekijken voor achtergrondkennis.
-
Een begrip van de basisconcepten van Flask-SQLAlchemy, zoals het opzetten van een database, het maken van database modellen, en het invoegen van gegevens in de database. Zie Hoe Flask-SQLAlchemy te gebruiken om met databases te communiceren in een Flask-applicatie voor achtergrondkennis.
Stap 1 — Het opzetten van de database en het model
In deze stap installeer je de benodigde pakketten en zet je je Flask-applicatie op, de Flask-SQLAlchemy database, en het werknemer model dat de werknemer tabel vertegenwoordigt waar je je werknemersgegevens zult opslaan. Je voegt een paar werknemers toe aan de werknemer tabel, en voegt een route en een pagina toe waar alle werknemers worden weergegeven op de indexpagina van je applicatie.
Eerst, met je virtuele omgeving geactiveerd, installeer Flask en Flask-SQLAlchemy:
Zodra de installatie is voltooid, ontvang je output met de volgende regel aan het einde:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
Met de vereiste pakketten geïnstalleerd, opent u een nieuw bestand genaamd app.py in uw flask_app-map. Dit bestand bevat code voor het instellen van de database en uw Flask-routes:
Voeg de volgende code toe aan app.py. Deze code zal een SQLite-database instellen en een model voor de werknemersdatabase vertegenwoordigen, waarin de employee-tabel wordt gebruikt om uw werknemersgegevens op te slaan:
Sla het bestand op en sluit het.
Hier importeer je de os-module, die je toegang geeft tot diverse besturingssysteeminterfaces. Je zult het gebruiken om een bestandspad te construeren voor je database.db-databestand.
Vanuit het flask-pakket importeer je de hulpmiddelen die je nodig hebt voor je toepassing: de Flask-klasse om een instantie van een Flask-toepassing te maken, render_template() om sjablonen te renderen, het request-object om verzoeken af te handelen, url_for() om URL’s te construeren, en de redirect()-functie om gebruikers door te verwijzen. Voor meer informatie over routes en sjablonen, zie Hoe sjablonen te gebruiken in een Flask-toepassing.
Vervolgens importeer je de SQLAlchemy-klasse uit de Flask-SQLAlchemy-extensie, die je toegang geeft tot alle functies en klassen van SQLAlchemy, naast hulpmiddelen en functionaliteiten die Flask integreren met SQLAlchemy. Je zult het gebruiken om een database-object te maken dat verbinding maakt met je Flask-toepassing.
Om een pad te construeren voor je databasebestand, definieer je een basisdirectory als de huidige directory. Je gebruikt de os.path.abspath() functie om het absolute pad van de huidige map van het bestand te krijgen. De speciale __file__ variabele bevat het pad van het huidige app.py bestand. Je slaat het absolute pad van de basisdirectory op in een variabele genaamd basedir.
Vervolgens maak je een Flask applicatie-instantie genaamd app aan, die je gebruikt om twee Flask-SQLAlchemy configuratiesleutels te configureren:
-
SQLALCHEMY_DATABASE_URI: De database URI om de database aan te geven waarmee je een verbinding wilt tot stand brengen. In dit geval volgt de URI het formaatsqlite:///pad/naar/database.db. Je gebruikt deos.path.join()functie om intelligent de basisdirectory die je hebt geconstrueerd en opgeslagen in de variabelebasedirte combineren met de bestandsnaamdatabase.db. Hiermee maak je verbinding met eendatabase.dbdatabasebestand in jeflask_appdirectory. Het bestand wordt aangemaakt zodra je de database initieert. -
SQLALCHEMY_TRACK_MODIFICATIONS: Een configuratie om het bijhouden van wijzigingen aan objecten in- of uit te schakelen. U stelt het in opFalseom bijhouden uit te schakelen, wat minder geheugen gebruikt. Zie voor meer informatie de configuratiepagina in de Flask-SQLAlchemy documentatie.
Nadat u SQLAlchemy hebt geconfigureerd door een database-URI in te stellen en het bijhouden uit te schakelen, maakt u een database-object met behulp van de SQLAlchemy-klasse, waarbij u de toepassingsinstantie doorgeeft om uw Flask-toepassing te verbinden met SQLAlchemy. U slaat uw database-object op in een variabele genaamd db, die u zult gebruiken om met uw database te communiceren.
Na het instellen van de toepassingsinstantie en het database-object, erf je van de db.Model-klasse om een databasemodel genaamd Employee te maken. Dit model vertegenwoordigt de employee-tabel, en het heeft de volgende kolommen:
id: Het werknemers-ID, een integer primaire sleutel.voornaam: De voornaam van de werknemer, een tekenreeks met een maximale lengte van 100 tekens.nullable=Falsegeeft aan dat deze kolom niet leeg mag zijn.achternaam: De achternaam van de werknemer, een tekenreeks met een maximale lengte van 100 tekens.nullable=Falsegeeft aan dat deze kolom niet leeg mag zijn.e-mail: De e-mail van de werknemer, een tekenreeks met een maximale lengte van 100 tekens.unique=Truegeeft aan dat elke e-mail uniek moet zijn.nullable=Falsegeeft aan dat de waarde niet leeg mag zijn.leeftijd: De leeftijd van de werknemer, een integerwaarde.aanwervingsdatum: De datum waarop de werknemer in dienst is getreden. Je steltdb.Datein als het kolomtype om aan te geven dat het een kolom is die datums bevat.actief: Een kolom die een booleaanse waarde zal bevatten om aan te geven of de werknemer momenteel actief is of niet op kantoor is.
De speciale __repr__-functie stelt je in staat om elk object een tekenreeksrepresentatie te geven om het te herkennen voor debugdoeleinden. In dit geval gebruik je de voornaam en achternaam van de werknemer om elk werknemersobject voor te stellen.
Nu je de databaseverbinding en het werknemersmodel hebt ingesteld, schrijf je een Python-programma om je database en de tabel employee aan te maken en de tabel te vullen met enkele werknemersgegevens.
Open een nieuw bestand genaamd init_db.py in je flask_app-directory:
Voeg de volgende code toe om bestaande databasetabellen te verwijderen om van een schone database te starten, de employee-tabel aan te maken en negen werknemers hieraan toe te voegen:
Hier importeer je de date()-klasse uit de datetime-module om het te gebruiken om de aanname-data van werknemers in te stellen.
Je importeert het database-object en het Employee-model. Je roept de db.drop_all()-functie aan om alle bestaande tabellen te verwijderen om de kans op een reeds gevulde employee-tabel in de database te vermijden, wat problemen kan veroorzaken. Dit verwijdert alle databasegegevens telkens wanneer je het programma init_db.py uitvoert. Voor meer informatie over het aanmaken, wijzigen en verwijderen van databasetabellen, zie Hoe je Flask-SQLAlchemy kunt gebruiken om met databases te communiceren in een Flask-applicatie.
Vervolgens maak je verschillende instanties van het Employee-model, die de werknemers vertegenwoordigen die je in deze tutorial zult opvragen, en voeg je ze toe aan de databasesessie met behulp van de db.session.add_all()-functie. Tenslotte bevestig je de transactie en pas je de wijzigingen toe op de database met behulp van de db.session.commit().
Sla het bestand op en sluit het.
Voer het programma init_db.py uit:
Om een blik te werpen op de gegevens die je aan je database hebt toegevoegd, zorg ervoor dat je virtuele omgeving is geactiveerd en open de Flask-shell om alle werknemers op te vragen en hun gegevens weer te geven:
Voer de volgende code uit om alle werknemers op te vragen en hun gegevens weer te geven:
Je gebruikt de all()-methode van het query-attribuut om alle werknemers te krijgen. Je loopt door de resultaten en geeft de werknemersinformatie weer. Voor de active-kolom gebruik je een voorwaardelijke verklaring om de huidige status van de werknemer weer te geven, ofwel 'Actief' of 'Afwezig'.
Je ontvangt de volgende uitvoer:
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
Je ziet dat alle werknemers die we aan de database hebben toegevoegd, correct worden weergegeven.
Verlaat de Flask-shell:
Vervolgens maak je een Flask-route om werknemers weer te geven. Open app.py om te bewerken:
Voeg de volgende route toe aan het einde van het bestand:
Sla het bestand op en sluit het.
Dit vraagt alle werknemers op, rendert een index.html-sjabloon en geeft de opgehaalde werknemers door.
Maak een sjablonenmap en een basissjabloon:
Voeg het volgende toe aan base.html:
Sla het bestand op en sluit het.
Hier gebruik je een titelblok en voeg je wat CSS-styling toe. Je voegt een navigatiebalk toe met twee items, een voor de indexpagina en een voor een inactieve Over-pagina. Deze navigatiebalk zal opnieuw worden gebruikt in de hele applicatie in de sjablonen die erven van dit basissjabloon. Het inhoudsblok wordt vervangen door de inhoud van elke pagina. Voor meer informatie over sjablonen, bekijk Hoe sjablonen te gebruiken in een Flask-applicatie.
Open vervolgens een nieuw index.html-sjabloon dat je hebt gerenderd in app.py:
Voeg de volgende code toe aan het bestand:
Hier loop je door medewerkers en toon je de informatie van elke medewerker. Als de medewerker actief is, voeg je een (Actief)-label toe, anders toon je een (Buiten kantoor)-label.
Sla het bestand op en sluit het.
Terwijl je in je flask_app directory bent met je geactiveerde virtuele omgeving, vertel Flask over de applicatie (app.py in dit geval) met behulp van de FLASK_APP omgevingsvariabele. Stel vervolgens de FLASK_ENV omgevingsvariabele in op development om de applicatie in ontwikkelingsmodus uit te voeren en toegang te krijgen tot de debugger. Voor meer informatie over de Flask debugger, zie How To Handle Errors in a Flask Application. Gebruik de volgende commando’s om dit te doen:
Voer vervolgens de applicatie uit:
Met de ontwikkelingsserver actief, bezoek de volgende URL met je browser:
http://127.0.0.1:5000/
Je zult de werknemers die je aan de database hebt toegevoegd zien op een pagina die lijkt op de volgende:
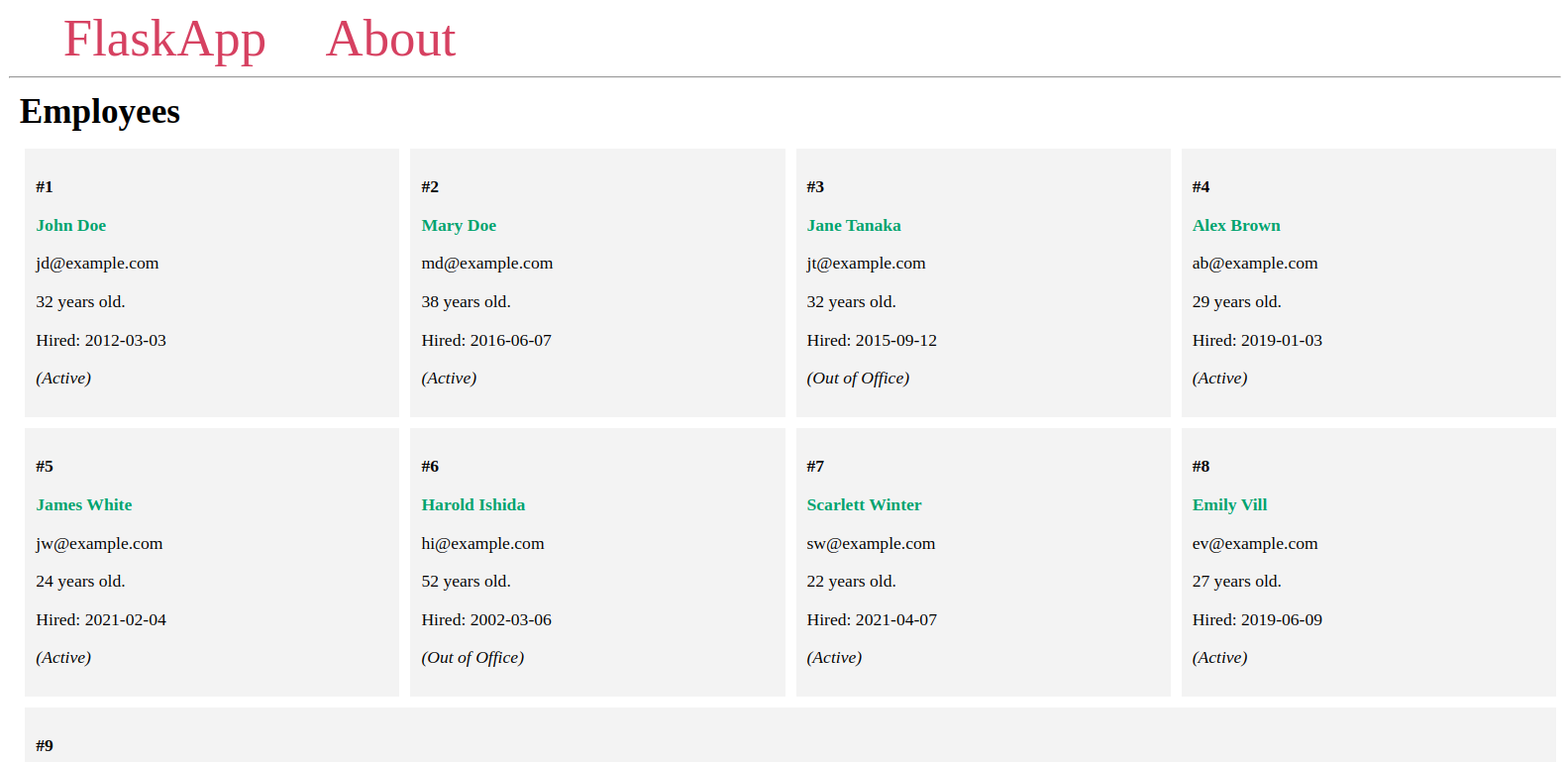
Laat de server draaien, open een andere terminal en ga verder naar de volgende stap.
Je hebt de werknemers die je in je database hebt weergegeven op de indexpagina. Vervolgens zul je de Flask shell gebruiken om werknemers te bevragen met behulp van verschillende methoden.
Stap 2 — Records Bevragen
In deze stap zul je de Flask shell gebruiken om records te bevragen, en resultaten te filteren en op te halen met behulp van meerdere methoden en voorwaarden.
Met je programmeeromgeving geactiveerd, stel de FLASK_APP en FLASK_ENV variabelen in, en open de Flask shell:
Importeer het db-object en het Employee-model:
Alle gegevens ophalen
Zoals je hebt gezien in de vorige stap, kun je de all()-methode gebruiken op het query-attribuut om alle gegevens in een tabel te krijgen:
De uitvoer zal een lijst van objecten zijn die alle werknemers vertegenwoordigen:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
Het eerste record ophalen
Vergelijkbaar, je kunt de first()-methode gebruiken om het eerste record te krijgen:
De uitvoer zal een object zijn dat de gegevens van de eerste werknemer bevat:
Output<Employee John Doe>
Een record ophalen op basis van ID
In de meeste database tabellen worden records geïdentificeerd met een unieke ID. Flask-SQLAlchemy stelt je in staat om een record op te halen met behulp van zijn ID met de get()-methode:
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
Het ophalen van een record of meerdere records op basis van een kolomwaarde
Om een record op te halen met behulp van de waarde van een van zijn kolommen, gebruikt u de methode filter_by(). Bijvoorbeeld, om een record op te halen met behulp van zijn ID-waarde, vergelijkbaar met de get()-methode:
Output<Employee John Doe>
U gebruikt first() omdat filter_by() meerdere resultaten kan retourneren.
Opmerking: Voor het ophalen van een record op basis van ID is het gebruik van de get()-methode een betere benadering.
Voor een ander voorbeeld kunt u een werknemer ophalen aan de hand van hun leeftijd:
Output<Employee Harold Ishida>
Voor een voorbeeld waarbij het queryresultaat meer dan één overeenkomend record bevat, gebruikt u de kolom firstname en de voornaam Mary, die een naam is die wordt gedeeld door twee werknemers:
Output[<Employee Mary Doe>, <Employee Mary Park>]
Hier gebruikt u all() om de volledige lijst te krijgen. U kunt ook first() gebruiken om alleen het eerste resultaat te krijgen:
Output<Employee Mary Doe>
U heeft records opgehaald via kolomwaarden. Vervolgens zult u uw tabel bevragen met behulp van logische voorwaarden.
Stap 3 — Records filteren met behulp van logische voorwaarden
In complexe, volledig uitgeruste webapplicaties moet je vaak records uit de database opvragen met ingewikkelde voorwaarden, zoals het ophalen van werknemers op basis van een combinatie van voorwaarden die rekening houden met hun locatie, beschikbaarheid, rol en verantwoordelijkheden. In deze stap krijg je oefening in het gebruik van conditionele operatoren. Je zult de filter()-methode op het query-attribuut gebruiken om queryresultaten te filteren met logische voorwaarden met verschillende operatoren. Bijvoorbeeld, je kunt logische operatoren gebruiken om een lijst op te halen van welke werknemers momenteel afwezig zijn, of werknemers die in aanmerking komen voor promotie, en misschien een kalender van de vakantietijd van werknemers verstrekken, enzovoort.
Is gelijk aan
De eenvoudigste logische operator die je kunt gebruiken is de gelijkheid operator ==, die zich op een vergelijkbare manier gedraagt als filter_by(). Bijvoorbeeld, om alle records te krijgen waar de waarde van de voornaam-kolom Mary is, kun je de filter()-methode als volgt gebruiken:
Hier gebruik je de syntaxis Model.kolom == w aarde als argument voor de filter()-methode. De filter_by()-methode is een snelkoppeling voor deze syntaxis.
Het resultaat is hetzelfde als het resultaat van de filter_by()-methode met dezelfde voorwaarde:
Output[<Employee Mary Doe>, <Employee Mary Park>]
Net als bij filter_by() kun je ook de first()-methode gebruiken om het eerste resultaat te krijgen:
Output<Employee Mary Doe>
Niet gelijk aan
De methode filter() maakt het mogelijk om de != Python-operator te gebruiken om records te verkrijgen. Bijvoorbeeld, om een lijst te krijgen van medewerkers die niet op kantoor zijn, kunt u de volgende aanpak gebruiken:
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
Hier gebruikt u de voorwaarde Employee.active != True om resultaten te filteren.
Kleiner dan
U kunt de < operator gebruiken om een record te verkrijgen waarbij de waarde van een gegeven kolom kleiner is dan de opgegeven waarde. Bijvoorbeeld, om een lijst te krijgen van medewerkers jonger dan 32 jaar:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
Gebruik de <= operator voor records die kleiner zijn dan of gelijk zijn aan de opgegeven waarde. Bijvoorbeeld, om medewerkers van 32 jaar in de vorige query op te nemen:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
Groter dan
Vergelijkbaar verkrijgt de > operator een record waarbij de waarde van een gegeven kolom groter is dan de opgegeven waarde. Bijvoorbeeld, om medewerkers ouder dan 32 jaar te verkrijgen:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
En de >= operator is voor records die groter zijn dan of gelijk zijn aan de opgegeven waarde. Bijvoorbeeld, u kunt opnieuw 32-jarige medewerkers opnemen in de vorige query:
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
In
SQLAlchemy biedt ook een manier om records te verkrijgen waarvan de waarde van een kolom overeenkomt met een waarde uit een gegeven lijst van waarden door de in_() methode op de kolom te gebruiken, zoals:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
Hier gebruik je een voorwaarde met de syntaxis Model.kolom.in_(iterable), waar iterable elk type object is waar je doorheen kunt itereren. Als ander voorbeeld kun je de Python-functie range() gebruiken om werknemers uit een bepaald leeftijdsbereik te verkrijgen. De volgende query krijgt alle werknemers die in de dertig zijn.
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
Niet In
Vergelijkbaar met de in_() methode, kun je de not_in() methode gebruiken om records te verkrijgen waarvan de waarde van een kolom niet in een gegeven iterable staat:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
Hier krijg je alle werknemers behalve die met een voornaam in de namen lijst.
En
Je kunt verschillende voorwaarden samenvoegen met behulp van de db.and_() functie, die werkt zoals de and operator in Python.
Bijvoorbeeld, laten we zeggen dat je alle werknemers wilt vinden die 32 jaar oud zijn en momenteel actief zijn. Ten eerste kun je controleren wie 32 is met behulp van de methode filter_by() (je kunt ook filter() gebruiken als je dat wilt):
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
Hier zie je dat John en Jane de werknemers zijn die 32 jaar oud zijn. John is actief en Jane is niet op kantoor.
Om de werknemers te krijgen die 32 zijn en actief, gebruik je twee voorwaarden met de methode filter():
Employee.age == 32Employee.active == True
Om deze twee voorwaarden samen te voegen, gebruik je de functie db.and_() als volgt:
Output[<Employee John Doe>]
Hier gebruik je de syntax filter(db.and_(voorwaarde1, voorwaarde2)).
Met all() op de query krijg je een lijst van alle records die voldoen aan de twee voorwaarden. Je kunt de methode first() gebruiken om het eerste resultaat te krijgen:
Output<Employee John Doe>
Voor een complexer voorbeeld kun je de functie db.and_() gebruiken met de functie date() om werknemers te krijgen die in een specifieke tijdsperiode zijn aangenomen. In dit voorbeeld krijg je alle werknemers die zijn aangenomen in het jaar 2019:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
Hier importeer je de functie date(), en je filtert resultaten met behulp van de functie db.and_() om de volgende twee voorwaarden te combineren:
Employee.hire_date >= date(year=2019, month=1, day=1): Dit isTruevoor werknemers die op 1 januari 2019 of later zijn aangenomen.Employee.hire_date < date(year=2020, month=1, day=1): Dit isTruevoor werknemers die vóór de eerste dag van januari 2020 zijn aangenomen.
Het combineren van de twee voorwaarden haalt werknemers op die vanaf de eerste dag van 2019 en vóór de eerste dag van 2020 zijn aangenomen.
Of
Vergelijkbaar met db.and_(), combineert de db.or_() functie twee voorwaarden en gedraagt zich als de or operator in Python. Het haalt alle records op die voldoen aan één van de twee voorwaarden. Bijvoorbeeld, om werknemers van 32 of 52 jaar oud te krijgen, kunt u twee voorwaarden combineren met de db.or_() functie als volgt:
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
U kunt ook de startswith() en endswith() methoden gebruiken op tekenreekswaarden in voorwaarden die u doorgeeft aan de filter() methode. Bijvoorbeeld, om alle werknemers te krijgen van wie de voornaam begint met de tekenreeks 'M' en die met een achternaam die eindigt met de tekenreeks 'e':
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
Hier combineer je de volgende twee voorwaarden:
Employee.firstname.startswith('M'): Komt overeen met werknemers met een voornaam die begint met'M'.Employee.lastname.endswith('e'): Komt overeen met werknemers met een achternaam die eindigt op'e'.
U kunt nu queryresultaten filteren met logische voorwaarden in uw Flask-SQLAlchemy-toepassingen. Vervolgens zult u de resultaten die u uit de database krijgt ordenen, beperken en tellen.
Stap 4 — Bestellen, Beperken en Resultaten Tellen
In webapplicaties moet je vaak je gegevens ordenen bij het weergeven ervan. Bijvoorbeeld, je kunt een pagina hebben om de nieuwste aanwinsten in elk departement weer te geven om de rest van het team op de hoogte te stellen van nieuwe aanwinsten, of je kunt werknemers ordenen door eerst de oudste aanwinsten weer te geven om lang dienende werknemers te erkennen. Je moet ook je resultaten in bepaalde gevallen beperken, zoals bijvoorbeeld alleen de laatste drie aanwinsten weergeven op een kleine zijbalk. En je moet vaak het aantal resultaten van een query tellen, bijvoorbeeld om het aantal werknemers weer te geven dat momenteel actief is. In deze stap leer je hoe je resultaten kunt ordenen, beperken en tellen.
Resultaten Ordenen
Om resultaten te ordenen op basis van de waarden van een specifieke kolom, gebruik je de methode order_by(). Bijvoorbeeld, om resultaten te ordenen op de voornaam van de werknemers:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
Zoals de uitvoer laat zien, worden de resultaten alfabetisch geordend op de voornaam van de werknemer.
Je kunt ook ordenen op andere kolommen. Bijvoorbeeld, je kunt de achternaam gebruiken om werknemers te ordenen:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
Je kunt werknemers ook ordenen op hun aanstellingsdatum:
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
Zoals de output laat zien, ordent dit de resultaten vanaf de vroegste aanwerving tot de laatste aanwerving. Om de volgorde om te keren en het aflopend te maken van de laatste aanwerving tot de vroegste, gebruik de desc() methode als volgt:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
U kunt ook de order_by() methode combineren met de filter() methode om gefilterde resultaten te ordenen. Het volgende voorbeeld haalt alle werknemers die in 2021 zijn aangenomen en ordent ze op leeftijd:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
Hier gebruikt u de db.and_() functie met twee voorwaarden: Employee.hire_date >= date(year=2021, month=1, day=1) voor werknemers die op de eerste dag van 2021 of later zijn aangenomen, en Employee.hire_date < date(year=2022, month=1, day=1) voor werknemers die voor de eerste dag van 2022 zijn aangenomen. Vervolgens gebruikt u de order_by() methode om de resulterende werknemers te ordenen op hun leeftijd.
Resultaten beperken
In de meeste gevallen in de echte wereld, bij het opvragen van een databasetabel, krijgt u mogelijk tot miljoenen overeenkomende resultaten, en het is soms noodzakelijk om de resultaten te beperken tot een bepaald aantal. Om resultaten te beperken in Flask-SQLAlchemy, kunt u de limit() methode gebruiken. Het volgende voorbeeld vraagt de werknemer tabel op en retourneert alleen de eerste drie overeenkomende resultaten:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
U kunt limit() gebruiken met andere methoden, zoals filter en order_by. Bijvoorbeeld, u kunt de laatste twee werknemers die in 2021 zijn aangenomen krijgen met behulp van de limit() methode als volgt:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Hier gebruik je dezelfde query als in de vorige sectie met een extra limit(2) methode-oproep.
Resultaten Tellen
Om het aantal resultaten van een query te tellen, kun je de count() methode gebruiken. Bijvoorbeeld, om het aantal werknemers dat momenteel in de database staat te krijgen:
Output9
Je kunt de count() methode combineren met andere querymethoden zoals limit(). Bijvoorbeeld, om het aantal werknemers die in 2021 zijn aangenomen te krijgen:
Output3
Hier gebruik je dezelfde query als eerder voor het ophalen van alle werknemers die in 2021 zijn aangenomen. En je gebruikt count() om het aantal items op te halen, wat 3 is.
Je hebt queryresultaten besteld, beperkt en geteld in Flask-SQLAlchemy. Vervolgens leer je hoe je queryresultaten kunt opsplitsen in meerdere pagina’s en hoe je een paginasysteem kunt maken in je Flask-applicaties.
Stap 5 — Weergeven van Lange Lijsten met Records op Meerdere Pagina’s
In deze stap ga je de hoofdroute aanpassen zodat de startpagina werknemers op meerdere pagina’s weergeeft om het navigeren door de werknemerslijst eenvoudiger te maken.
Eerst zul je de Flask-shell gebruiken om een demonstratie te zien van hoe je de pagineringfunctie in Flask-SQLAlchemy kunt gebruiken. Open de Flask-shell als je dat nog niet hebt gedaan:
Zeg dat je de werknemersrecords in je tabel wilt opsplitsen in meerdere pagina’s, met twee items per pagina. Dit kun je doen met behulp van de paginate()-querymethode als volgt:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
Je gebruikt de page-parameter van de paginate()-querymethode om de pagina te specificeren die je wilt openen, wat in dit geval de eerste pagina is. De per_page-parameter specificeert het aantal items dat elke pagina moet bevatten. In dit geval stel je het in op 2 om elke pagina twee items te laten hebben.
De variabele page1 hier is een paginatie-object, dat je toegang geeft tot attributen en methoden die je zult gebruiken om je paginering te beheren.
Je kunt de items van de pagina benaderen met behulp van het items-attribuut.
Om naar de volgende pagina te gaan, kun je de next()-methode van het paginatie-object gebruiken zoals hier, het geretourneerde resultaat is ook een paginatie-object:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
Je kunt een paginatie-object voor de vorige pagina krijgen met behulp van de prev()-methode. In het volgende voorbeeld benader je het paginatie-object voor de vierde pagina, vervolgens benader je het paginatie-object van de vorige pagina, dat pagina 3 is:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
Je kunt het huidige paginanummer benaderen met behulp van het page-attribuut zoals hier:
Output1
2
Om het totale aantal pagina’s te krijgen, gebruik de pages attribuut van het paginatie object. In het volgende voorbeeld, beide page1.pages en page2.pages geven dezelfde waarde terug omdat het totale aantal pagina’s constant is:
Output5
5
Voor het totale aantal items, gebruik de total attribuut van het paginatie object:
Output9
9
Hier, aangezien je alle werknemers opvraagt, is het totale aantal items in de paginatie 9, omdat er negen werknemers in de database zijn.
Hier zijn enkele van de andere attributen die paginatie objecten hebben:
prev_num: Het vorige pagina nummer.next_num: Het volgende pagina nummer.has_next:Trueals er een volgende pagina is.has_prev:Trueals er een vorige pagina is.per_page: Het aantal items per pagina.
Het paginatie object heeft ook een iter_pages() methode die je kunt doorlopen om pagina nummers te benaderen. Bijvoorbeeld, je kunt alle pagina nummers afdrukken als volgt:
Output1
2
3
4
5
Het volgende is een demonstratie van hoe je alle pagina’s en hun items kunt benaderen met behulp van een paginatie object en de iter_pages() methode:
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
Hier, maak je een paginatie object dat begint vanaf de eerste pagina. Je doorloopt pagina’s met een for loop met de iter_pages() paginatie methode. Je drukt het pagina nummer en pagina items af, en je stelt het pagination object in op het paginatie object van de volgende pagina met behulp van de next() methode.
U kunt ook de filter()– en order_by()-methoden gebruiken met de paginate()-methode om gefilterde en gesorteerde queryresultaten te pagineren. Bijvoorbeeld, u kunt werknemers ouder dan dertig krijgen en de resultaten ordenen op leeftijd en de resultaten pagineren zoals volgt:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
Nu u een goed begrip heeft van hoe paginering werkt in Flask-SQLAlchemy, zult u de indexpagina van uw toepassing bewerken om werknemers op meerdere pagina’s weer te geven voor gemakkelijkere navigatie.
Verlaat de Flask-shell:
Om verschillende pagina’s te openen, zult u URL-parameters gebruiken, ook wel URL-querystrings genoemd, die een manier zijn om informatie door te geven aan de toepassing via de URL. Parameters worden aan de toepassing doorgegeven in de URL na een ?-symbool. Bijvoorbeeld, om een page-parameter door te geven met verschillende waarden, kunt u de volgende URL’s gebruiken:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
Hier passeert de eerste URL de waarde 1 naar de URL-parameter page. De tweede URL geeft een waarde 3 door naar dezelfde parameter.
Open het bestand app.py:
Bewerk de indexroute om er als volgt uit te zien:
Hier krijgt u de waarde van de page-URL-parameter met behulp van het request.args-object en zijn get()-methode. Bijvoorbeeld /?page=1 zal de waarde 1 ophalen uit de page-URL-parameter. U geeft 1 door als standaardwaarde, en u geeft het Python-type int door als argument aan de type-parameter om ervoor te zorgen dat de waarde een geheel getal is.
Vervolgens maak je een paginatie-object aan, waarbij je de queryresultaten ordent op voornaam. Je geeft de waarde van de page-URL-parameter door aan de paginate()-methode, en je verdeelt de resultaten in twee items per pagina door de waarde 2 door te geven aan de per_page-parameter.
Tenslotte geef je het geconstrueerde paginatie-object door aan het weergegeven index.html-sjabloon.
Sla het bestand op en sluit het.
Vervolgens bewerk je het index.html-sjabloon om paginatie-items weer te geven:
Verander de inhoud van de div-tag door een h2-kop toe te voegen die de huidige pagina aangeeft, en verander de for-lus zodat deze door het pagination.items-object loopt in plaats van het employees-object, dat niet langer beschikbaar is:
Sla het bestand op en sluit het.
Als je dit nog niet hebt gedaan, stel dan de FLASK_APP– en FLASK_ENV-omgevingsvariabelen in en start de ontwikkelingsserver:
Navigeer nu naar de indexpagina met verschillende waarden voor de page-URL-parameter:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
Je zult verschillende pagina’s zien met telkens twee items, en verschillende items op elke pagina, zoals je eerder hebt gezien in de Flask-shell.
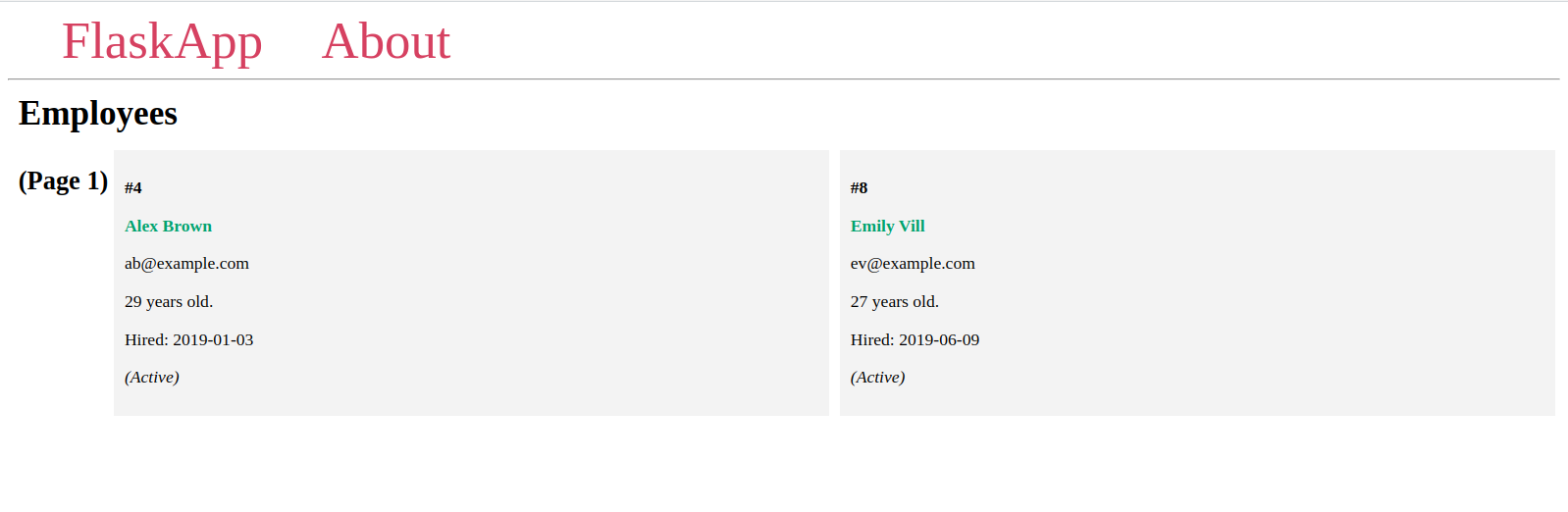
Als het opgegeven paginanummer niet bestaat, krijg je een HTTP-foutmelding 404 Not Found, wat het geval is bij de laatste URL in de voorgaande URL-lijst.
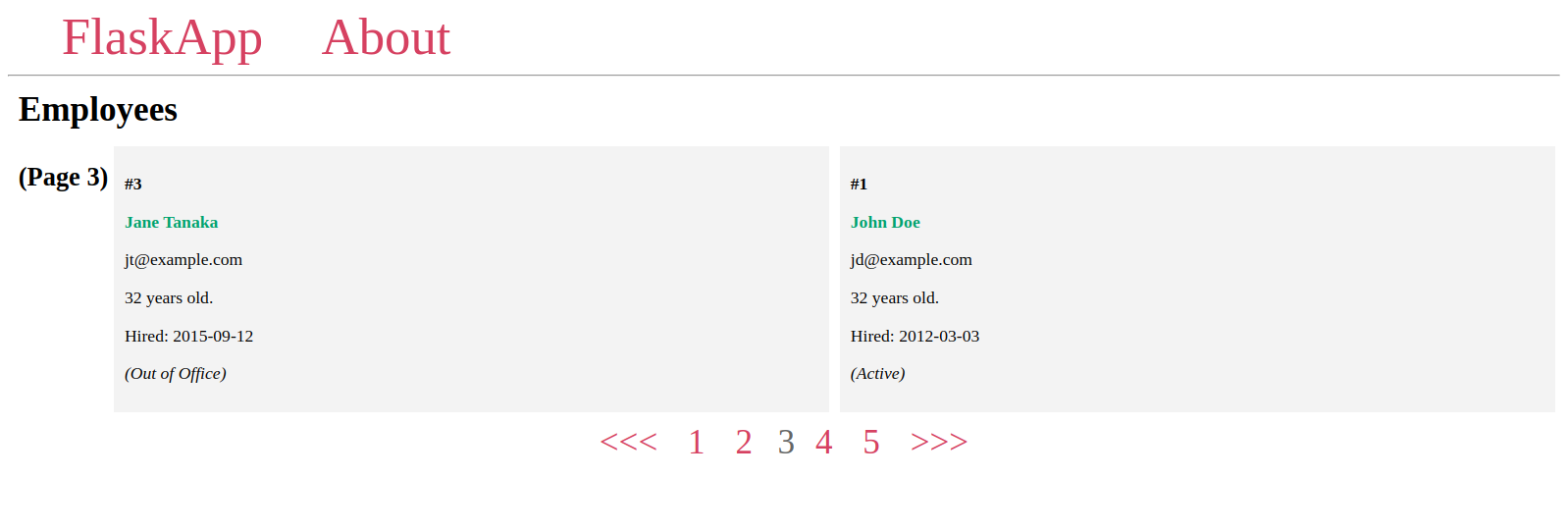
Vervolgens maak je een paginawidget om te navigeren tussen pagina’s, je zult een paar attributen en methoden van het paginab object gebruiken om alle paginanummers weer te geven, elk nummer linkt naar zijn toegewijde pagina, en een <<< knop om terug te gaan als de huidige pagina een vorige pagina heeft, en een >>> knop om naar de volgende pagina te gaan als die bestaat.
De paginawidget ziet er als volgt uit:

Om het toe te voegen, open index.html:
Bewerk het bestand door de volgende gemarkeerde div-tag toe te voegen onder de inhouds div-tag:
Sla het bestand op en sluit het.
Hier gebruik je de voorwaarde if pagination.has_prev om een <<< link toe te voegen naar de vorige pagina als de huidige pagina niet de eerste pagina is. Je linkt naar de vorige pagina met behulp van de functieaanroep url_for('index', page=pagination.prev_num), waarbij je naar de indexweergavefunctie linkt en de waarde pagination.prev_num doorgeeft aan de page URL-parameter.
Om links naar alle beschikbare paginanummers weer te geven, loop je door de items van de pagination.iter_pages()-methode die je een paginanummer geeft bij elke iteratie.
U gebruikt de if pagination.page != number voorwaarde om te controleren of het huidige paginanummer niet hetzelfde is als het nummer in de huidige lus. Als de voorwaarde waar is, koppelt u naar de pagina om de gebruiker in staat te stellen de huidige pagina naar een andere pagina te wijzigen. Als de huidige pagina echter hetzelfde is als het lusnummer, geeft u het nummer weer zonder een koppeling. Dit stelt gebruikers in staat om het huidige paginanummer in de paginaweergave te kennen.
Tenslotte gebruikt u de pagination.has_next voorwaarde om te zien of de huidige pagina een volgende pagina heeft, in welk geval u er naartoe linkt met de url_for('index', page=pagination.next_num) oproep en een >>> koppeling.
Navigeer naar de indexpagina in uw browser: http://127.0.0.1:5000/
U ziet dat de paginaweergave volledig functioneel is:
Hier gebruikt u >>> om naar de volgende pagina te gaan en <<< voor de vorige pagina, maar u kunt ook andere tekens gebruiken, zoals > en < of afbeeldingen in <img>-tags.
U heeft werknemers op meerdere pagina’s weergegeven en geleerd hoe u paginering kunt behandelen in Flask-SQLAlchemy. En u kunt nu uw paginaweergave op andere Flask-toepassingen gebruiken die u bouwt.
Conclusie
Je hebt Flask-SQLAlchemy gebruikt om een werknemersbeheersysteem te maken. Je hebt een tabel bevraagd en resultaten gefilterd op basis van kolomwaarden en eenvoudige en complexe logische voorwaarden. Je hebt queryresultaten gesorteerd, geteld en beperkt. En je hebt een pagineringssysteem gemaakt om een bepaald aantal records op elke pagina in je webtoepassing weer te geven en tussen pagina’s te navigeren.
Je kunt wat je hebt geleerd in deze tutorial gebruiken in combinatie met concepten die worden uitgelegd in enkele van onze andere Flask-SQLAlchemy-tutorials om meer functionaliteit toe te voegen aan je werknemersbeheersysteem:
- Hoe Flask-SQLAlchemy te gebruiken om met databases te communiceren in een Flask-toepassing om te leren hoe je werknemers kunt toevoegen, bewerken of verwijderen.
- Hoe één-tot-veel-database-relaties te gebruiken met Flask-SQLAlchemy om te leren hoe je één-tot-veel relaties kunt gebruiken om een afdelingstabel te maken om elke werknemer te koppelen aan de afdeling waar ze bij horen.
- Hoe u veel-op-veel database-relaties kunt gebruiken met Flask-SQLAlchemy om te leren hoe u veel-op-veel relaties kunt gebruiken om een
takentabel te maken en deze te koppelen aan dewerknemertabel, waarbij elke werknemer veel taken heeft en elke taak is toegewezen aan meerdere werknemers.
Als u meer wilt lezen over Flask, bekijk dan de andere tutorials in de Hoe u webapplicaties kunt bouwen met Flask serie.