













Whisper AI is een geavanceerd automatisch spraakherkenningsmodel (ASR) ontwikkeld door OpenAI dat audio kan transcriberen naar tekst met indrukwekkende nauwkeurigheid en ondersteuning biedt voor meerdere talen. Hoewel Whisper AI voornamelijk is ontworpen voor batchverwerking, kan het worden geconfigureerd voor realtime spraak-naar-teksttranscriptie op Linux.
In deze gids zullen we het stap-voor-stap proces doorlopen van het installeren, configureren en uitvoeren van Whisper AI voor live transcriptie op een Linux-systeem.
Wat is Whisper AI?
Whisper AI is een open-source spraakherkenningsmodel dat is getraind op een enorme dataset van audiorecordings en het is gebaseerd op een diepgaande leerarchitectuur die het mogelijk maakt om:
- Spraak in meerdere talen te transcriberen.
- Accenten en achtergrondgeluiden efficiënt te verwerken.
- Vertaling van gesproken taal naar het Engels uit te voeren.
Omdat het is ontworpen voor hoge-nauwkeurigheid transcription, wordt het veel gebruikt in:
- Live transcriptiediensten (bijv. voor toegankelijkheid).
- Stemassistenten en automatisering.
- Het transcriberen van opgenomen audiobestanden.
Standaard is Whisper AI niet geoptimaliseerd voor realtime verwerking. Echter, met enkele extra tools kan het live audiostreams verwerken voor directe transcriptie.
Whisper AI Systeemvereisten
Voor het uitvoeren van Whisper AI op Linux, zorg ervoor dat uw systeem voldoet aan de volgende vereisten:
Hardwarevereisten:
- CPU: Een multi-core processor (Intel/AMD).
- RAM: Minimaal 8GB (16GB of meer wordt aanbevolen).
- GPU: NVIDIA GPU met CUDA (optioneel maar versnelt de verwerking aanzienlijk).
- Opslag: Minimaal 10GB aan vrije schijfruimte voor modellen en afhankelijkheden.
Softwarevereisten:
- Een Linux distributie zoals Ubuntu, Debian, Arch, Fedora, enz.
- Python versie 3.8 of hoger.
- Pip pakketbeheerder voor het installeren van Python-pakketten.
- FFmpeg voor het verwerken van audiobestanden en streams.
Stap 1: Installeren van Vereiste Afhankelijkheden
Voordat u Whisper AI installeert, moet u uw pakketlijst bijwerken en bestaande pakketten upgraden.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
Vervolgens moet u Python 3.8 of hoger en de Pip pakketbeheerder installeren zoals getoond.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Als laatste moet u FFmpeg installeren, wat een multimediakader is dat wordt gebruikt om audiobestanden en videobestanden te verwerken.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Stap 2: Installeer Whisper AI in Linux
Zodra de vereiste afhankelijkheden zijn geïnstalleerd, kunt u doorgaan met het installeren van Whisper AI in een virtuele omgeving waarmee u Python-pakketten kunt installeren zonder de systeempakketten te beïnvloeden.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
Zodra de installatie is voltooid, controleer of Whisper AI correct is geïnstalleerd door het volgende uit te voeren.
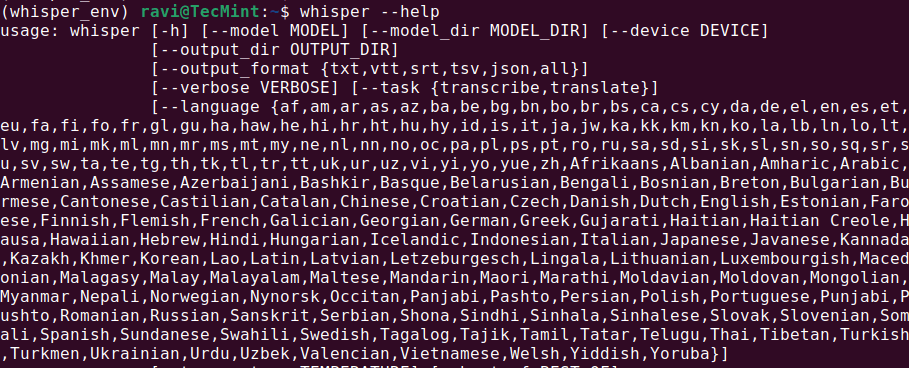
whisper --help
Dit zou een helpmenu met beschikbare commando’s en opties moeten weergeven, wat betekent dat Whisper AI is geïnstalleerd en klaar voor gebruik.
Stap 3: Whisper AI uitvoeren in Linux
Zodra Whisper AI is geïnstalleerd, kunt u audiobestanden transcriberen met verschillende commando’s.
Transcriberen van een audiobestand
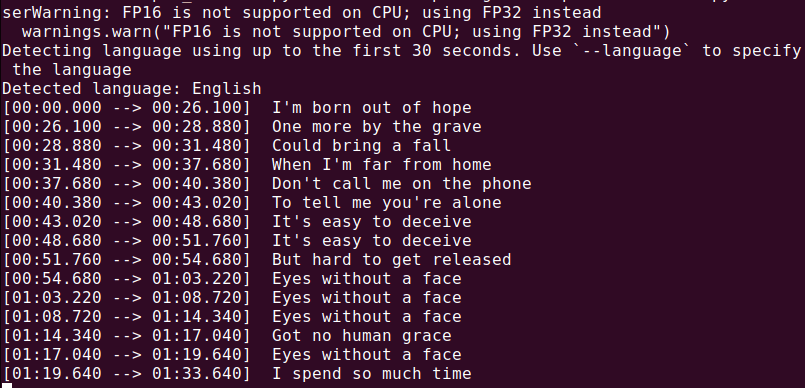
Om een audiobestand (audio.mp3) te transcriberen, voer het volgende uit:
whisper audio.mp3
Whisper zal het bestand verwerken en een transcript in tekstformaat genereren.
Nu alles is geïnstalleerd, laten we een Python-script maken om audio van uw microfoon vast te leggen en in realtime te transcriberen.
nano real_time_transcription.py
Kopieer en plak de volgende code in het bestand.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
Voer het script uit met Python, dat zal beginnen met het luisteren naar de invoer van uw microfoon en de getranscribeerde tekst in realtime weergeven. Spreek duidelijk in uw microfoon en u zou de resultaten op het terminalscherm moeten zien verschijnen.
python3 real_time_transcription.py
Conclusie
Whisper AI is een krachtige spraak-naar-tekst tool die kan worden aangepast voor real-time transcriptie op Linux. Voor de beste resultaten, gebruik een GPU en optimaliseer uw systeem voor real-time verwerking.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/