













Wanneer je werkt met Amazon S3 (Simple Storage Service), gebruik je waarschijnlijk de S3 webconsole om bestanden te downloaden, kopiëren of uploaden naar S3-buckets. Het gebruik van de console is helemaal prima, daar is het immers voor ontworpen.
Vooral voor beheerders die meer gewend zijn aan muisklikken dan toetsenbordcommando’s, is de webconsole waarschijnlijk het gemakkelijkst. Beheerders zullen echter uiteindelijk behoefte hebben aan het uitvoeren van bulkbestandsbewerkingen met Amazon S3, zoals een onbeheerde bestandsupload. De GUI is daar niet het beste gereedschap voor.
Voor dergelijke automatiseringsvereisten met Amazon Web Services, inclusief Amazon S3, biedt de AWS CLI-tool beheerders opdrachtregelopties voor het beheren van Amazon S3-buckets en objecten.
In dit artikel leer je hoe je de AWS CLI-opdrachtregeltool kunt gebruiken om bestanden te uploaden, kopiëren, downloaden en synchroniseren met Amazon S3. Je leert ook de basisprincipes van het bieden van toegang tot je S3-bucket en het configureren van dat toegangsprofiel om te werken met de AWS CLI-tool.
Vereisten
Aangezien dit een how-to-artikel is, zullen er voorbeelden en demonstraties zijn in de volgende secties. Om succesvol mee te kunnen doen, moet je aan verschillende vereisten voldoen.
- Een AWS-account. Als je nog geen bestaand AWS-abonnement hebt, kun je je aanmelden voor een AWS Free Tier.
- Een AWS S3-bucket. Je kunt een bestaand bucket gebruiken als je dat liever hebt. Het wordt echter aanbevolen om in plaats daarvan een leeg bucket te maken. Raadpleeg alstublieft Het maken van een bucket.
- A Windows 10 computer with at least Windows PowerShell 5.1. In this article, PowerShell 7.0.2 will be used.
- De AWS CLI versie 2 tool moet geïnstalleerd zijn op je computer.
- Lokale mappen en bestanden die je wilt uploaden of synchroniseren met Amazon S3
Je AWS S3-toegang voorbereiden
Stel dat je al aan de vereisten hebt voldaan. Je zou denken dat je al aan de slag kunt gaan met AWS CLI met je S3-bucket. Ik bedoel, zou het niet fijn zijn als het zo simpel was?
Voor degenen onder jullie die net beginnen te werken met Amazon S3 of AWS in het algemeen, heeft dit gedeelte als doel om je te helpen toegang tot S3 in te stellen en een AWS CLI-profiel te configureren.
De volledige documentatie voor het maken van een IAM-gebruiker in AWS is te vinden in deze link hieronder. Het maken van een IAM-gebruiker in je AWS-account
Het maken van een IAM-gebruiker met S3-toegangsrechten
Wanneer je AWS gebruikt via de CLI, moet je een of meer IAM-gebruikers aanmaken met voldoende toegang tot de resources waarmee je van plan bent te werken. In dit gedeelte zul je een IAM-gebruiker aanmaken met toegang tot Amazon S3.
Om een IAM-gebruiker met toegang tot Amazon S3 te maken, moet je eerst inloggen op je AWS IAM-console. Onder de groep Toegangsbeheer, klik op Gebruikers. Klik vervolgens op Gebruiker toevoegen.
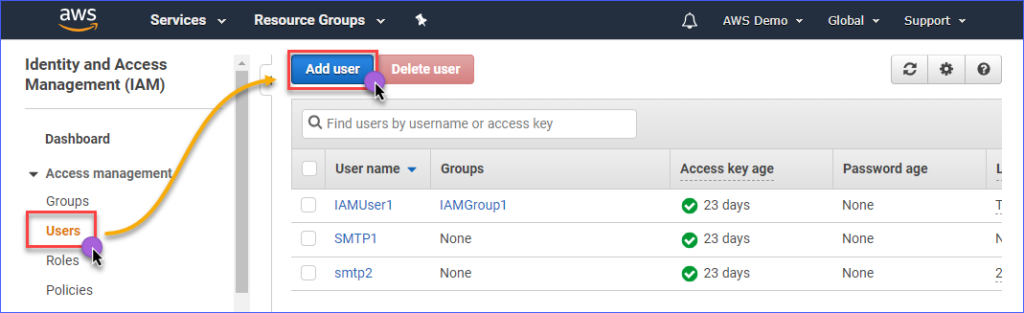
Vul de naam in van de IAM-gebruiker die je aanmaakt in het Gebruikersnaam* veld, zoals s3Admin. Bij de Toegangstype* selectie, vink Programmatische toegang aan. Klik vervolgens op de Volgende: Machtigingen knop.

Klik vervolgens op Bestaande beleidsregels rechtstreeks koppelen. Zoek vervolgens naar de beleidsnaam AmazonS3FullAccess en vink deze aan. Klik als je klaar bent op Volgende: Tags.

Het toevoegen van tags is optioneel op de pagina Tags toevoegen, je kunt dit overslaan en klikken op de Volgende: Review knop.
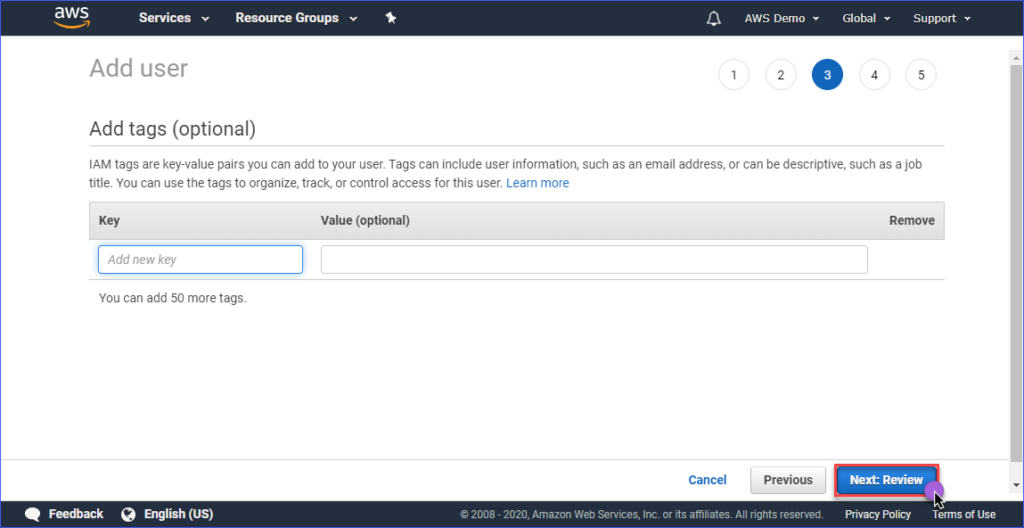
Op de Review pagina krijg je een samenvatting van het nieuwe account dat wordt aangemaakt. Klik op Gebruiker maken.
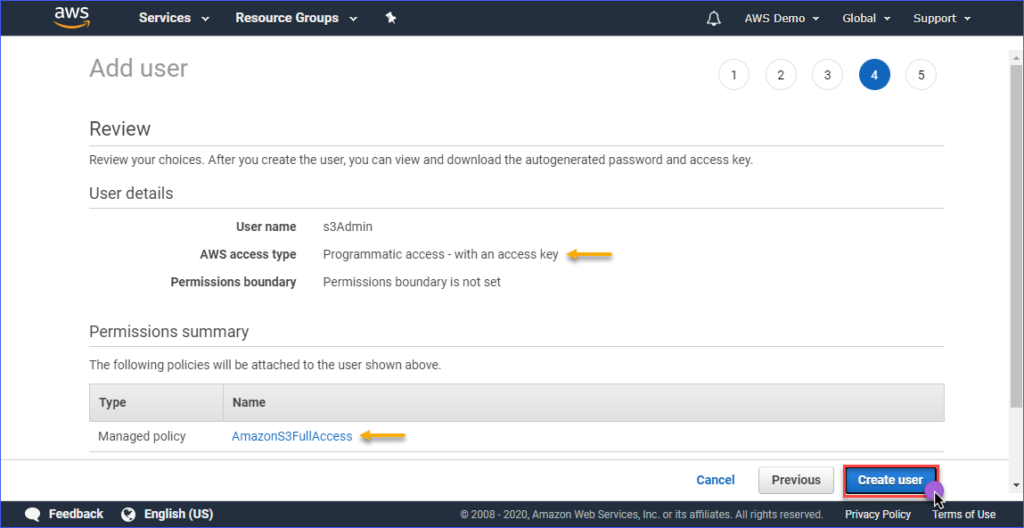
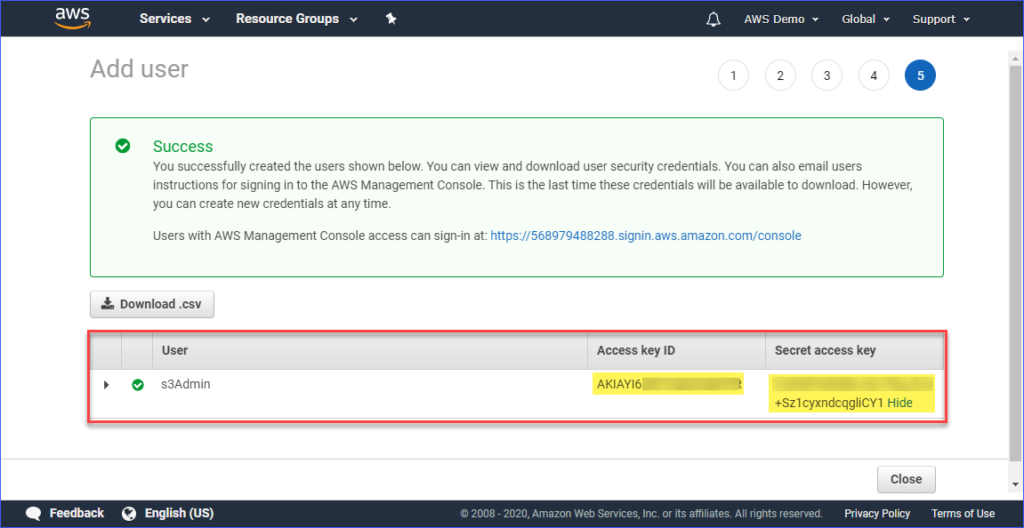
Tenslotte, nadat de gebruiker is aangemaakt, moet je de Toegangssleutel-ID en de Geheime toegangssleutel kopiëren en deze opslaan voor later gebruik. Let op dat dit de enige keer is dat je deze waarden kunt zien.
Het instellen van een AWS-profiel op je computer
Nu je de IAM-gebruiker met de juiste toegang tot Amazon S3 hebt aangemaakt, is de volgende stap het instellen van het AWS CLI-profiel op je computer.
Deze sectie gaat ervan uit dat u al de AWS CLI versie 2-tool hebt geïnstalleerd zoals vereist. Voor het maken van het profiel heeft u de volgende informatie nodig:
- De Toegangssleutel-ID van de IAM-gebruiker.
- De Geheime toegangssleutel die is gekoppeld aan de IAM-gebruiker.
- De Standaardregio-naam komt overeen met de locatie van uw AWS S3-bucket. U kunt de lijst met eindpunten bekijken via deze link. In dit artikel bevindt de AWS S3-bucket zich in de regio Azië-Pacific (Sydney), en het overeenkomstige eindpunt is ap-southeast-2.
- Het standaard-uitvoerformaat. Gebruik hiervoor JSON.
Om het profiel aan te maken, opent u PowerShell en typt u de onderstaande opdracht, gevolgd door de aanwijzingen.
Voer de Toegangssleutel-ID, Geheime toegangssleutel, Standaardregio-naam, en standaard-uitvoernaam in. Raadpleeg de onderstaande demonstratie.

Testen van AWS CLI-toegang
Nadat u het AWS CLI-profiel hebt geconfigureerd, kunt u bevestigen dat het profiel werkt door de onderstaande opdracht uit te voeren in PowerShell.
De bovenstaande opdracht moet de Amazon S3-buckets weergeven die u in uw account hebt. De demonstratie hieronder laat de opdracht in actie zien. Het resultaat toont aan dat de configuratie van het profiel succesvol was.

Om meer te weten te komen over de AWS CLI-commando’s specifiek voor Amazon S3, kun je de pagina AWS CLI Command Reference S3 bezoeken.
Beheer van Bestanden in S3
Met AWS CLI kunnen typische bestandsbeheeroperaties worden uitgevoerd, zoals het uploaden van bestanden naar S3, het downloaden van bestanden van S3, het verwijderen van objecten in S3 en het kopiëren van S3-objecten naar een andere S3-locatie. Het draait allemaal om het kennen van het juiste commando, de syntaxis, parameters en opties.
In de volgende secties bestaat de gebruikte omgeving uit het volgende.
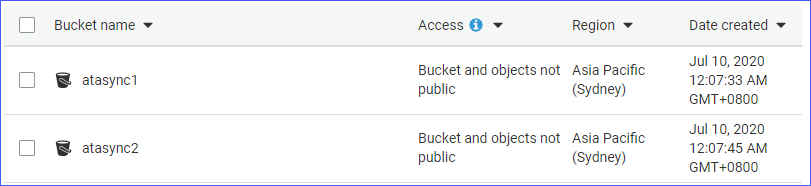
- Twee S3-buckets, namelijk atasync1 en atasync2. De onderstaande schermafbeelding toont de bestaande S3-buckets in de Amazon S3-console.
- Lokale directory en bestanden bevinden zich onder c:\sync.

Individuele Bestanden naar S3 Uploaden
Wanneer je bestanden naar S3 uploadt, kun je één bestand per keer uploaden, of door meerdere bestanden en mappen recursief te uploaden. Afhankelijk van je vereisten kun je degene kiezen die je het meest geschikt acht.
Om een bestand naar S3 te uploaden, moet je twee argumenten (bron en bestemming) verstrekken aan het aws s3 cp commando.
Bijvoorbeeld, om het bestand c:\sync\logs\log1.xml naar de hoofdmap van de atasync1 bucket te uploaden, kun je het onderstaande commando gebruiken.
Let op: S3-bucketnamen hebben altijd het voorvoegsel S3:// wanneer ze worden gebruikt met AWS CLI
Voer het bovenstaande commando uit in PowerShell, maar wijzig eerst de bron- en doellocaties die passen bij jouw omgeving. De uitvoer zou er vergelijkbaar uit moeten zien als de demonstratie hieronder.

De demo hierboven laat zien dat het bestand met de naam c:\sync\logs\log1.xml zonder fouten is geüpload naar de S3-bestemming s3://atasync1/.
Gebruik het onderstaande commando om de objecten in de hoofdmap van de S3-bucket op te lijsten.
Het uitvoeren van het bovenstaande commando in PowerShell zou resulteren in een vergelijkbare uitvoer, zoals getoond in de demo hieronder. Zoals je kunt zien in de onderstaande uitvoer, staat het bestand log1.xml in de hoofdmap van de S3-locatie.

Meerdere bestanden en mappen recursief uploaden naar S3
Het vorige gedeelte liet zien hoe je een enkel bestand naar een S3-locatie kunt kopiëren. Wat als je meerdere bestanden vanuit een map en submappen moet uploaden? Je zou toch niet telkens hetzelfde commando willen uitvoeren voor verschillende bestandsnamen, toch?
Het aws s3 cp-commando heeft een optie om bestanden en mappen recursief te verwerken, en dit is de --recursive-optie.
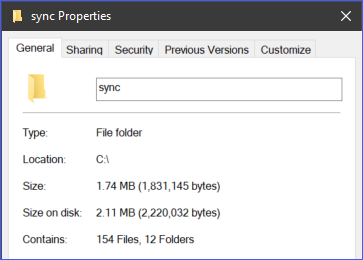
Als voorbeeld, de map c:\sync bevat 166 objecten (bestanden en submappen).
Met behulp van de --recursive-optie worden alle inhoud van de map c:\sync geüpload naar S3 terwijl ook de mappenstructuur behouden blijft. Om te testen, gebruik het onderstaande voorbeeldcode, maar zorg ervoor dat je de bron- en doellocaties aanpast aan jouw omgeving.
Je zult merken dat in de onderstaande code de bron c:\sync is en de bestemming s3://atasync1/sync is. De sleutel /sync die volgt op de naam van de S3-bucket geeft aan AWS CLI aan om de bestanden in de map /sync in S3 te uploaden. Als de map /sync niet bestaat in S3, wordt deze automatisch aangemaakt.
De bovenstaande code zal resulteren in de output, zoals getoond in de demonstratie hieronder.

Meerdere bestanden en mappen selectief uploaden naar S3
In sommige gevallen is het uploaden van ALLE soorten bestanden niet de beste optie. Bijvoorbeeld, wanneer je alleen bestanden met specifieke bestandsextensies wilt uploaden (bijv. *.ps1). Nog twee opties beschikbaar voor het cp-commando zijn --include en --exclude.
Terwijl het gebruik van het commando in de vorige sectie alle bestanden in de recursieve upload omvat, zal het commando hieronder alleen de bestanden opnemen die overeenkomen met de bestandsextensie *.ps1 en alle andere bestanden uitsluiten van de upload.
De demonstratie hieronder laat zien hoe de bovenstaande code werkt wanneer deze wordt uitgevoerd.

Een ander voorbeeld is als je meerdere verschillende bestandsextensies wilt opnemen, dan moet je de --include-optie meerdere keren specificeren.
Het voorbeeldcommando hieronder zal alleen de *.csv– en *.png-bestanden opnemen in het kopieercommando.
Het uitvoeren van de bovenstaande code in PowerShell zou je een vergelijkbaar resultaat opleveren, zoals hieronder getoond.

Objecten downloaden vanuit S3
Gebaseerd op de voorbeelden die je in dit gedeelte hebt geleerd, kun je ook kopieeroperaties in omgekeerde volgorde uitvoeren. Dit betekent dat je objecten van de S3-bucketlocatie naar de lokale machine kunt downloaden.
Het kopiëren van S3 naar lokaal vereist dat je de posities van de bron en de bestemming omwisselt. De bron is de S3-locatie en de bestemming is het lokale pad, zoals hieronder weergegeven.
Merk op dat dezelfde opties die worden gebruikt bij het uploaden van bestanden naar S3 ook van toepassing zijn bij het downloaden van objecten van S3 naar lokaal. Bijvoorbeeld het downloaden van alle objecten met de onderstaande opdracht met de --recursive-optie.
Objecten kopiëren tussen S3-locaties
Naast het uploaden en downloaden van bestanden en mappen kun je met AWS CLI ook bestanden kopiëren of verplaatsen tussen twee S3-bucketlocaties.
Je zult merken dat de onderstaande opdracht één S3-locatie als de bron gebruikt en een andere S3-locatie als de bestemming.
De demonstratie hieronder toont dat het bronbestand wordt gekopieerd naar een andere S3-locatie met behulp van de bovenstaande opdracht.

Bestanden en mappen synchroniseren met S3
Je hebt tot nu toe geleerd hoe je bestanden kunt uploaden, downloaden en kopiëren in S3 met behulp van AWS CLI-opdrachten. In dit gedeelte leer je over nog één bestandsbewerkingopdracht die beschikbaar is in AWS CLI voor S3, namelijk de sync-opdracht. De sync-opdracht verwerkt alleen bijgewerkte, nieuwe en verwijderde bestanden.
Er zijn gevallen waarin u de inhoud van een S3-bucket up-to-date en gesynchroniseerd moet houden met een lokale map op een server. Bijvoorbeeld, u kunt een vereiste hebben om transactielogs op een server gesynchroniseerd te houden met S3 op regelmatige tijdstippen.
Met behulp van de onderstaande opdracht worden *.XML-logbestanden die zich bevinden onder de map c:\sync op de lokale server gesynchroniseerd met de S3-locatie s3://atasync1.
De demonstratie hieronder toont aan dat na het uitvoeren van de bovenstaande opdracht in PowerShell, alle *.XML-bestanden zijn geüpload naar de S3-bestemming s3://atasync1/.

Synchroniseren van nieuwe en bijgewerkte bestanden met S3
In dit volgende voorbeeld wordt ervan uitgegaan dat de inhoud van het logbestand Log1.xml is gewijzigd. De sync-opdracht moet die wijziging oppikken en de wijzigingen aan het lokale bestand uploaden naar S3, zoals getoond in de demonstratie hieronder.
De opdracht die moet worden gebruikt is nog steeds hetzelfde als in het vorige voorbeeld.

Zoals u kunt zien aan de bovenstaande output, is alleen het bestand Log1.xml lokaal gewijzigd, en dus ook het enige bestand dat gesynchroniseerd is met S3.
Synchroniseren van verwijderingen met S3
Standaard verwerkt de sync-opdracht geen verwijderingen. Elk bestand dat wordt verwijderd vanaf de bronlocatie wordt niet verwijderd op de bestemming. Tenzij u natuurlijk de optie --delete gebruikt.
In dit volgende voorbeeld is het bestand met de naam Log5.xml verwijderd vanaf de bron. De opdracht om de bestanden te synchroniseren zal worden aangevuld met de optie --delete, zoals getoond in de code hieronder.
Wanneer u het bovenstaande commando uitvoert in PowerShell, moet het verwijderde bestand met de naam Log5.xml ook worden verwijderd op de bestemming S3-locatie. Het voorbeeldresultaat wordt hieronder weergegeven.

Samenvatting
Amazon S3 is een uitstekende bron voor het opslaan van bestanden in de cloud. Met het gebruik van de AWS CLI-tool wordt de manier waarop u Amazon S3 gebruikt verder uitgebreid en opent het de mogelijkheid om uw processen te automatiseren.
In dit artikel hebt u geleerd hoe u de AWS CLI-tool kunt gebruiken om bestanden en mappen tussen lokale locaties en S3-buckets te uploaden, downloaden en synchroniseren. U hebt ook geleerd dat de inhoud van S3-buckets ook naar andere S3-locaties kan worden gekopieerd of verplaatst.
Er kunnen veel meer gebruiksscenario’s zijn voor het gebruik van de AWS CLI-tool om bestandsbeheer te automatiseren met Amazon S3. U kunt zelfs proberen het te combineren met PowerShell-scripting en uw eigen tools of modules te bouwen die herbruikbaar zijn. Het is aan u om die kansen te vinden en uw vaardigheden te tonen.