













VAR-As-A-Service is een MLOps benadering voor de unificatie en hergebruik van statistische modellen en pijplijnen voor het implementeren van machine learning modellen. Het is het tweede artikel in een serie die op dat project is gebaseerd, met experimenten met verschillende statistische en machine learning modellen, geïmplementeerde gegevens pijplijnen met behulp van bestaande DAG tools, en opslagdiensten, zowel cloud-gebaseerd als alternatieve on-premises oplossingen. Dit artikel richt zich op het opslaan van modelbestanden met een aanpak die ook toepasbaar is en wordt gebruikt voor machine learning modellen. De geïmplementeerde opslag is gebaseerd op MinIO als een AWS S3-compatibel object storage service. Bovendien geeft het artikel een overzicht van alternatieve opslagoplossingen en beschrijft de voordelen van objectgebaseerde opslag.
Het eerste artikel in de serie (Tijdreeksanalyse: VARMAX-As-A-Service) vergelijkt statistische en machine learning modellen als zowel wiskundige modellen en biedt een end-to-end implementatie van een VARMAX-gebaseerd statistisch model voor macro-economische voorspelling met behulp van een Python bibliotheek genaamd statsmodels. Het model wordt geïmplementeerd als een REST service met behulp van Python Flask en Apache web server, verpakt in een docker container. Het hooglevel architectuur van de applicatie wordt weergegeven in de volgende afbeelding:
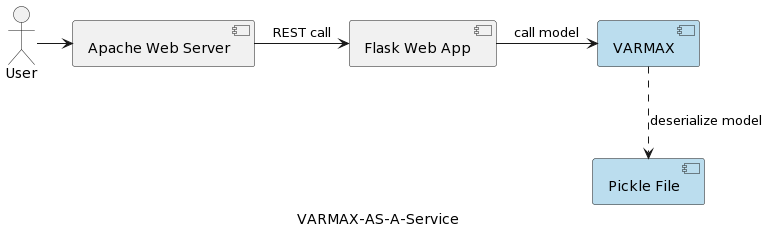
Het model wordt gedeserialiseerd als een pickle-bestand en geïmplementeerd op de webserver als onderdeel van de REST-servicepakket. In echte projecten worden modellen echter geverifieerd, vergezeld van metadata-informatie, en beveiligd, en moeten de trainingsexperimenten worden geregistreerd en reproduceerbaar bewaard. Bovendien, vanuit een architectonisch perspectief, strooit het opslaan van het model in het bestandssysteem naast de toepassing de eenduidige verantwoordelijkheidsbeginsel. Een goed voorbeeld is een microservices-gebaseerd architectuur. Het schalen van het modelservice horizontaal betekent dat elke microservice-instantie zijn eigen versie van het fysische pickle-bestand over alle service-instanties zal repliceren. Dat betekent ook dat de ondersteuning van meerdere versies van de modellen een nieuwe release en opnieuw implementeren van de REST-service en zijn infrastructuur vereist. Het doel van dit artikel is modellen te ontkoppelen van de web service-infrastructuur en de hergebruik van de web service-logica met verschillende versies van modellen mogelijk te maken.
Voordat we ons bezig gaan houden met de implementatie, laten we eerst wat woorden los over statistische modellen en het VAR-model dat in dat project wordt gebruikt. Statistische modellen zijn wiskundige modellen, net als machinaal leren modellen. Meer over het verschil tussen de twee is te vinden in het eerste artikel van de reeks. Een statistisch model wordt meestal gespecificeerd als een wiskundige relatie tussen één of meerdere stochastische variabelen en andere niet-stochastische variabelen. Vector autoregressie (VAR) is een statistisch model dat wordt gebruikt om de relatie tussen meerdere hoeveelheden te vangen zoals ze in de tijd veranderen. VAR-modellen generaliseren het enkelvoudige autoregressieve model (AR) door het toestaan van multivariate tijdreeksen. In het getoonde project wordt het model getraind om voorspellingen te doen voor twee variabelen. VAR-modellen worden vaak gebruikt in de economie en de natuurwetenschappen. Over het algemeen wordt het model weergegeven door een systeem van vergelijkingen, die in het project verborgen zitten achter de Python-bibliotheek statsmodels.
De architectuur van de VAR-model service applicatie is weergegeven in de volgende afbeelding:
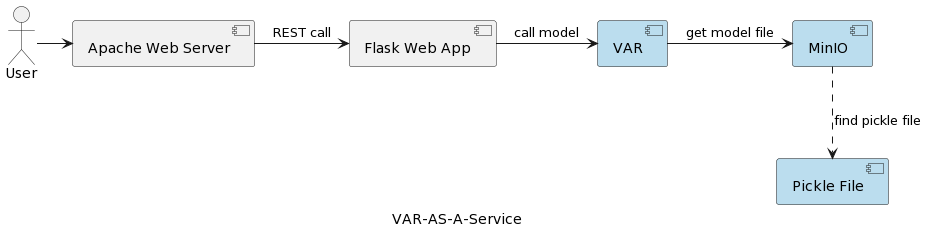
De VAR runtime component vertegenwoordigt de werkelijke modeluitvoering op basis van parameters die door de gebruiker worden verzonden. Het maakt verbinding met een MinIO-service via een REST-interface, laadt het model en voert de voorspelling uit. In tegenstelling tot de oplossing in het eerste artikel, waar het VARMAX-model wordt geladen en gedeserialiseerd bij de opstart van de applicatie, wordt het VAR-model bij elke voorspelling uitgevoerd gelezen van de MinIO server. Dit kost extra laden en gedeserialiseerde tijd, maar biedt ook het voordeel van het hebben van de meest recente versie van het geïmplementeerde model bij elke enkele run. Bovendien maakt het dynamische versiebeheer van modellen mogelijk, waardoor ze automatisch toegankelijk zijn voor externe systemen en eindgebruikers, zoals later in het artikel zal worden getoond. Merk op dat door die laadtijdoverhead, de prestaties van de geselecteerde opslagdienst van groot belang zijn.
Maar waarom MinIO en objectgebaseerde opslag in het algemeen?
MinIO is een hoogwaardige objectopslagoplossing met native ondersteuning voor Kubernetes-implementaties die een Amazon Web Services S3-compatibele API biedt en alle kern S3-functies ondersteunt. In het beschreven project is MinIO in Standalone Mode, bestaande uit één MinIO-server en één schijf of opslagvolume op Linux met behulp van Docker Compose. Voor uitgebreide ontwikkelings- of productieomgevingen is er de mogelijkheid voor een gedistribueerde modus, beschreven in het artikel Deploy MinIO in Distributed Mode.
Laten we snel kijken naar enkele opslagalternatieven terwijl een uitgebreide beschrijving te vinden is hier en hier:
- Lokale/gedistribueerde bestandsopslag: Lokale bestandsopslag is de oplossing die in het eerste artikel wordt geïmplementeerd, aangezien dit de eenvoudigste optie is. Berekening en opslag vinden plaats op hetzelfde systeem. Het is acceptabel tijdens de PoC-fase of voor zeer eenvoudige modellen die één versie van het model ondersteunen. Lokale bestandssystemen hebben een beperkte opslagcapaciteit en zijn ongeschikt voor grotere datasets als we aanvullende metadata zoals het gebruikte trainingsdataset willen opslaan. Omdat er geen replicatie of autoscaling is, kan een lokaal bestandssysteem niet functioneren in een beschikbare, betrouwbare en schaalbare vorm. Elke service die wordt geïmplementeerd voor horizontale schaal is geïmplementeerd met zijn eigen kopie van het model. Bovendien is de lokale opslag zo veilig als het host-systeem is. Alternatieven voor lokale bestandsopslag zijn NAS (Network-attached storage), SAN (Storage-area network), gedistribueerde bestandssystemen (Hadoop Distributed File System (HDFS), Google File System (GFS), Amazon Elastic File System (EFS) en Azure Files). Vergeleken met het lokale bestandssysteem, kenmerken deze oplossingen zich door beschikbaarheid, schaalbaarheid en weerbaarheid, maar brengen ze de kost van verhoogde complexiteit met zich mee.
- Relationele databases: Vanwege de binaire serialisatie van modellen bieden relationele databases de mogelijkheid om modellen als blob of binair te bewaren in kolommen van tabellen. Softwareontwikkelaars en veel datawetenschappers zijn vertrouwd met relationele databases, wat deze oplossing eenvoudig maakt. Modelversies kunnen als afzonderlijke tabelrijen worden opgeslagen met extra metadat
- Objectopslag: Objectopslag bestaat al enige tijd, maar werd revolutionair toen Amazon het in 2006 de eerste AWS-service maakte met Simple Storage Service (S3). Moderne objectopslag is native voor de cloud, en andere clouds brachten al snel hun aanbiedingen op de markt. Microsoft biedt Azure Blob Storage en Google heeft zijn Google Cloud Storage-service. De S3-API is de de-facto standaard voor ontwikkelaars om te communiceren met opslag in de cloud, en er zijn meerdere bedrijven die S3-compatibele opslag aanbieden voor de publieke cloud, private cloud en privé on-premises oplossingen. Ongeacht waar een objectstore zich bevindt, wordt deze geopend via een RESTful-interface. Hoewel objectopslag de noodzaak voor mappen, mappen en andere complexe hiërarchische organisatie elimineert, is het geen goede oplossing voor dynamische gegevens die voortdurend veranderen, aangezien u het hele object moet herschrijven om het te wijzigen, maar het is een goede keuze voor het opslaan van gedeserialiseerde modellen en de modellmetadata.
A summary of the main benefits of object storage are:
- Grote schaalbaarheid: De grootte van objectopslag is in wezen onbeperkt, zodat gegevens kunnen uitbreiden tot exabytes door eenvoudigweg nieuwe apparaten toe te voegen. Objectopslagoplossingen presteren ook het beste wanneer ze worden uitgevoerd als een gedistribueerde cluster.
- Verminderde complexiteit: Gegevens worden opgeslagen in een vlakke structuur. Het ontbreken van complexe bomen of partities (geen mappen of directories) vermindert de complexiteit van het ophalen van bestanden omdat men de exacte locatie niet hoeft te kennen.
- Zoekbaarheid: Metadaten zijn onderdeel van objecten, waardoor het gemakkelijk is om er doorheen te zoeken en te navigeren zonder de noodzaak van een aparte applicatie. Men kan objecten labelen met attributen en informatie, zoals verbruik, kosten en beleid voor geautomatiseerde verwijdering, retentie en tiering. Door de vlakke adresruimte van de onderliggende opslag (elk object bevindt zich in slechts één bucket en er zijn geen buckets binnen buckets), kunnen objectstores snel een object vinden onder miljarden objecten.
- Veerkracht: Objectopslag kan gegevens automatisch repliceren en opslaan op meerdere apparaten en geografische locaties. Dit kan helpen beschermen tegen storingen, zorgen voor bescherming tegen gegevensverlies en ondersteunen van rampenherstelstrategieën.
- Eenvoud: Het gebruik van een REST API voor het opslaan en ophalen van modellen betekent bijna geen leercurve en maakt de integratie in microservice-gebaseerde architectuur een natuurlijke keuze.
Het is tijd om na te denken over de implementatie van het VAR-model als een service en de integratie met MinIO. De implementatie van de voorgestelde oplossing wordt vereenvoudigd door het gebruik van Docker en Docker Compose. De organisatie van het hele project ziet er als volgt uit:

Zoals in het eerste artikel, bestaat de voorbereiding van het model uit een aantal stappen die zijn geschreven in een Python-script genaamd var_model.py gelegen in een gespecialiseerde GitHub repository :
- Gegevens laden
- Gegevens verdelen in trainings- en testdataset
- Endogene variabelen voorbereiden
- Optimaliseer modelparameter p (eerste p lags van elke variabele gebruikt als regressiepredictoren)
- Model instantiëren met de geïdentificeerde optimale parameters
- Het geïnstantieerde model serialiseren naar een pickle-bestand
- Het pickle-bestand opslaan als een geverifieerd object in een MinIO-bucket
Deze stappen kunnen ook worden geïmplementeerd als taken in een workflow-engine (bijv. Apache Airflow) die wordt geactiveerd door de behoefte om een nieuwe modelversie te trainen met recentere gegevens. DAG’s en hun toepassingen in MLOps zullen het onderwerp zijn van een ander artikel.
De laatste stap geïmplementeerd in var_model.py is het opslaan van het geserialiseerde model als een pickle-bestand in een bucket in S3. Vanwege de platte structuur van de objectopslag, is het gekozen formaat:
<bucket naam>/<file_naam>
Echter, voor bestandsnamen is het toegestaan om een schuine streep te gebruiken om een hiërarchische structuur na te bootsen, waarbij het voordeel van een snelle lineaire zoekopdracht behouden blijft. De conventie voor het opslaan van VAR-modellen is als volgt:
models/var/0_0_1/model.pkl
Hierbij is de bucketnaam models, en de bestandsnaam is var/0_0_1/model.pkl en in de MinIO UI ziet het er als volgt uit:

Dit is een zeer handige manier om verschillende soorten modellen en modelversies te structureren, terwijl je nog steeds de prestaties en eenvoud van vlakke bestandsopslag behoudt.
Let op dat de modelversieeringsimplementatie deel uitmaakt van de modelnaam. MinIO biedt ook versiebeheer van bestanden, maar de hier gekozen aanpak heeft enkele voordelen:
- Ondersteuning van snapshot-versies en overschrijven
- Gebruik van semantische versiebeheer (punten vervangen door ‘_’ vanwege beperkingen)
- Grotere controle over de versieeringsstrategie
- Ontkoppelen van de onderliggende opslagmechanismen in termen van specifieke versieeringsfuncties
Zodra het model is geïmplementeerd, is het tijd om het als een REST-service te exposeren met behulp van Flask en te implementeren met docker-compose dat MinIO en een Apache Webserver uitvoert. De Docker-afbeelding, evenals de modelcode, kan worden gevonden op een gespecialiseerde GitHub-repository.
En tot slot zijn de stappen die nodig zijn om de applicatie uit te voeren:
- Implementeer applicatie:
docker-compose up -d - Voer het model voorbereidingsalgoritme uit:
python var_model.py(vereist een draaiende MinIO-service) - Controleer of het model is geïmplementeerd: http://127.0.0.1:9101/browser
- Test het model:
http://127.0.0.1:80/apidocs
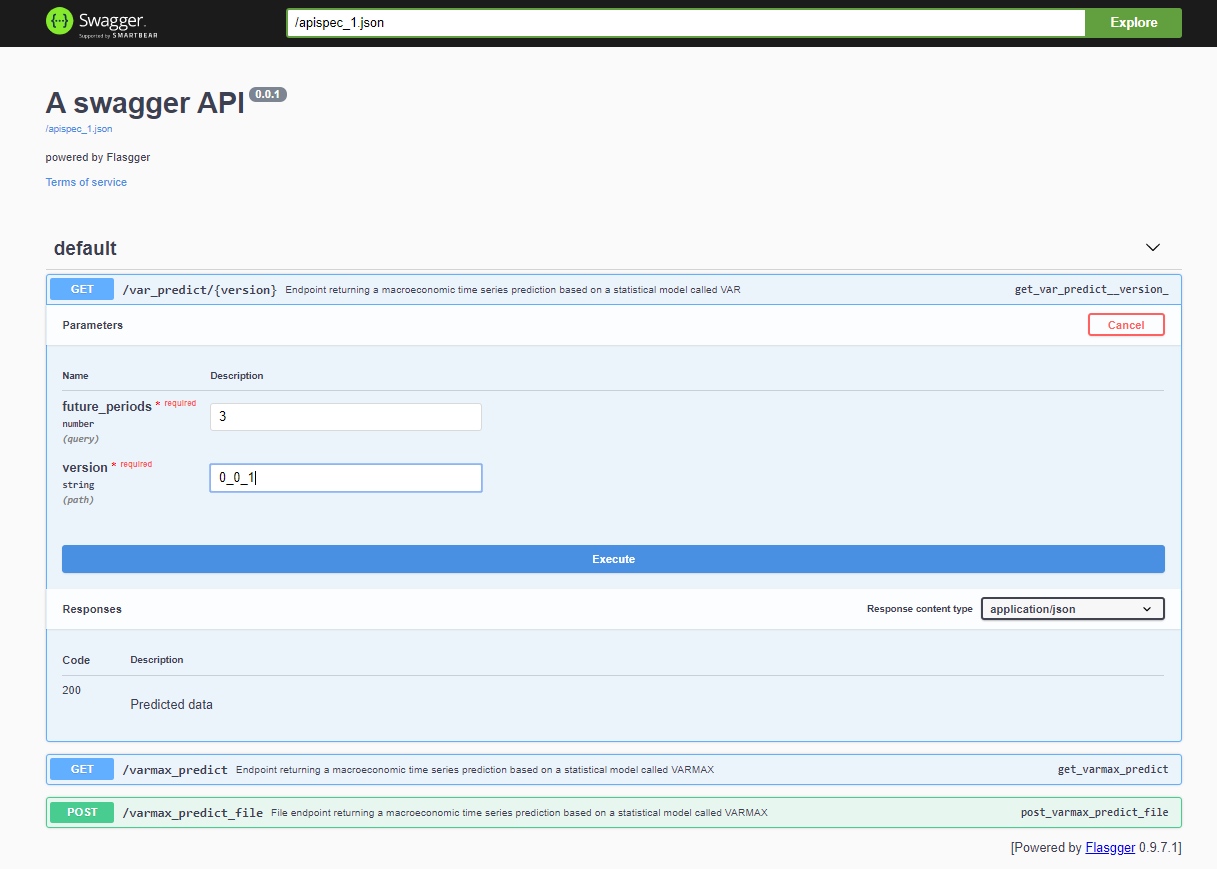
Na de implementatie van het project is de Swagger API toegankelijk via <host>:<port>/apidocs (bijvoorbeeld 127.0.0.1:80/apidocs). Er is één endpoint voor het VAR-model weergegeven naast de andere twee die een VARMAX-model onthullen:
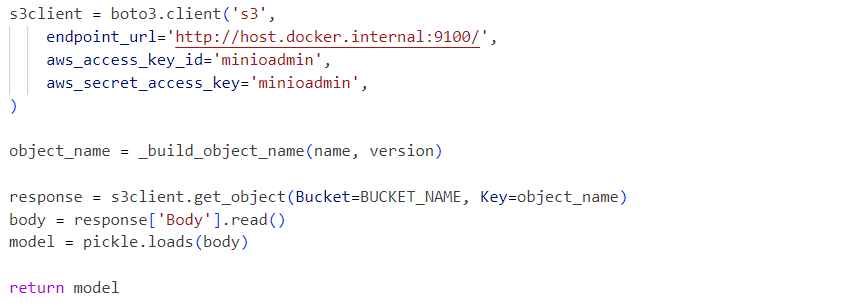
Interne, gebruikt de service het gedeserialiseerde model pickle-bestand geladen vanuit een MinIO-service:
Verzoeken worden verzonden naar het geïnitialiseerde model als volgt:

Het gepresenteerde project is een vereenvoudigd VAR-modelworkflow dat stap voor stap kan worden uitgebreid met extra functionaliteiten zoals:
- Verken standaard serialisatieformaten en vervang de pickle door een alternatief oplossing
- Integreer tijdreeksgegevensvisualisatietools zoals Kibana of Apache Superset
- Sla tijdreeksgegevens op in een tijdreeksdatabase zoals Prometheus, TimescaleDB, InfluxDB, of een Object Storage zoals S3
- Breid de pijplijn uit met gegevens laden en gegevensvoorbereidingsstappen
- Ingebed metrische rapporten als onderdeel van de pijplijnen
- Implementeer pijplijnen met specifieke tools zoals Apache Airflow of AWS Step Functions of meer standaard tools zoals Gitlab of GitHub
- Vergelijk de prestaties en nauwkeurigheid van statistische modellen met machinaal leren modellen
- Implementeer end-to-end, in de cloud geïntegreerde oplossingen, inclusief Infrastructure-As-Code
- Bespreek andere statistische en ML modellen als diensten
- Implementeer een Model Opslag API die het werkelijke opslag mechanisme en de versiebeheer van modellen abstracteert, slaat model metadata op en trainingsgegevens
Deze toekomstige verbeteringen zullen het onderwerp zijn van aankomende artikelen en projecten. Het doel van dit artikel is om een S3-compatibele opslag API te integreren en het opslaan van gedocumenteerde modellen mogelijk te maken. Die functionaliteit wordt snel in een aparte bibliotheek geëxtraheerd. De voorgestelde end-to-end infrastructuuroplossing kan in productie worden geïmplementeerd en door de tijd heen worden verbeterd als onderdeel van een CI/CD proces, ook gebruik makend van de gedistribueerde implementatie opties van MinIO of het vervangen door AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service